
















 Maison
Maison
Google dévoile Gemini Embedding2 : un modèle multimodal natif qui unifie les espaces sémantiques
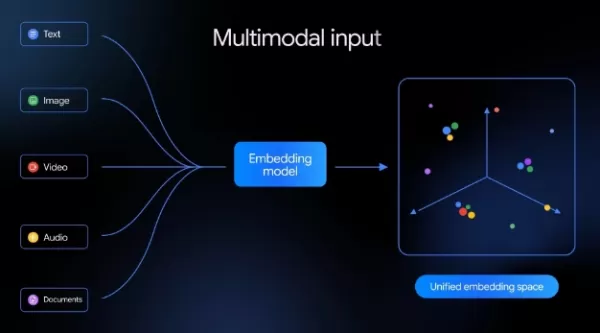
Google a récemment dévoilé son nouveau modèle d'encodage multimodal natif, Gemini Embedding2. Celui-ci permet de cartographier du texte, des images, des vidéos, des fichiers audio et des documents PDF dans un espace vectoriel sémantique commun, conçu pour rationaliser les flux de données complexes liés à l'IA et améliorer la recherche et la compréhension multimodales. Il s'agit d'une avancée majeure pour Google dans le domaine de la technologie d'encodage, marquant le passage d'un modèle textuel monomodal à une modélisation sémantique multimodale unifiée.

Auparavant, en juillet 2025, Google avait présenté le modèle d'intégration de texte gemini-embedding-001. Celui-ci prenait en charge plus de 100 langues et avait obtenu d'excellents résultats lors du benchmark multilingue MTEB. Le nouveau Gemini Embedding2 s'appuie sur l'architecture Gemini tout en élargissant considérablement son champ d'application. Il traite désormais cinq modalités différentes — texte, images, vidéo, audio et PDF — et les projette dans un espace vectoriel unique. Cela permet d'effectuer des comparaisons sémantiques directes entre différents types de médias sans avoir besoin de plusieurs modèles spécialisés ni d'étapes de traitement supplémentaires. Cette capacité est particulièrement utile pour des applications telles que la recherche sémantique, la génération augmentée par la recherche (RAG), l'analyse des sentiments et le regroupement de données.
En ce qui concerne les capacités d'entrée, le nouveau modèle prend en charge jusqu'à 8 192 tokens de texte, soit quatre fois la limite précédente de 2 048 tokens. Il peut traiter jusqu'à six images PNG ou JPEG par requête, des vidéos d'une durée maximale de 120 secondes et des documents PDF comptant jusqu'à six pages. Une fonctionnalité notable est la prise en charge native du traitement audio par Gemini Embedding2, qui élimine le besoin de conversion de la parole en texte et évite toute perte d'information potentielle due à la transcription. Google a également introduit la technologie « d'entrée entrelacée », permettant aux développeurs de combiner plusieurs modalités en une seule requête — comme mélanger des images avec du texte descriptif — afin de mieux saisir les relations sémantiques entre elles.
Sur le plan architectural, le modèle continue d'utiliser le Matryoshka Representation Learning (MRL). Cette technique utilise une structure hiérarchique pour ajuster dynamiquement les dimensions des vecteurs. La dimension d'intégration par défaut est de 3072, avec des configurations optionnelles de 1536 et 768 disponibles, offrant aux développeurs la flexibilité nécessaire pour trouver un équilibre entre la précision de la recherche et l'efficacité du stockage.
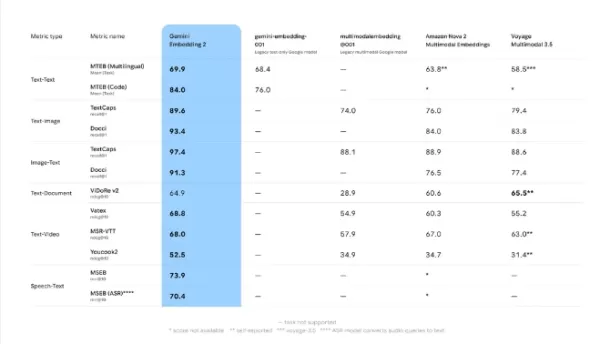
Les résultats des tests de performance de Google indiquent que Gemini Embedding2 offre des performances de pointe pour les tâches liées au texte, à l'image, à la vidéo et à la parole. Par exemple, en recherche texte-vidéo, il obtient un score de 68,8, surpassant Amazon Nova2Multimodal Embeddings (60,3) et Voyage Multimodal3.5 (55,2). En comparaison texte-image, il atteint un score de 93,4, nettement supérieur au score du modèle d'Amazon (84,0).
Gemini Embedding2 est actuellement accessible aux développeurs via l'API Gemini et Vertex AI. Il s'intègre aux frameworks et bases de données vectorielles populaires tels que LangChain, LlamaIndex, Haystack, Weaviate, Qdrant, ChromaDB et Vector Search. Pour aider les développeurs à se lancer, Google fournit des notebooks Colab interactifs et des démonstrations de recherche sémantique multimodale allégées.
La concurrence dans le domaine de l'intégration multimodale s'intensifie. Il convient notamment de noter qu'à la fin du mois de février de cette année, le moteur de recherche IA Perplexity a publié ses modèles d'intégration open source, pplx-embed-v1 et pplx-embed-context-v1.
Article connexe
 WordPress.com permet désormais à des agents IA de rédiger et de publier des articles, et bien plus encore
WordPress.com, la célèbre plateforme d'hébergement et de publication Web, se tourne désormais vers les agents IA, une initiative qui pourrait bien redéfinir l'apparence et l'ergonomie du Web. La socié
Claude, l'IA expérimentale d'Anthropic, mène à bien des négociations et des transactions dans le cadre d'un test de commerce électronique
Alors que l'intelligence artificielle progresse à grands pas, Anthropic a discrètement lancé vendredi dernier une expérience interne baptisée « Project Deal », visant à mettre en avant le potentiel de
DeepSeek Code s'apprête à être lancé
Alors que les technologies d'IA progressent à grands pas, DeepSeek se trouve à un tournant passionnant. L'entreprise spécialisée dans l'IA a récemment annoncé avoir levé plus de 70 milliards de yuans.
Recommandations de sujets spéciaux liés
Entreprise
WordPress.com permet désormais à des agents IA de rédiger et de publier des articles, et bien plus encore
WordPress.com, la célèbre plateforme d'hébergement et de publication Web, se tourne désormais vers les agents IA, une initiative qui pourrait bien redéfinir l'apparence et l'ergonomie du Web. La socié
Claude, l'IA expérimentale d'Anthropic, mène à bien des négociations et des transactions dans le cadre d'un test de commerce électronique
Alors que l'intelligence artificielle progresse à grands pas, Anthropic a discrètement lancé vendredi dernier une expérience interne baptisée « Project Deal », visant à mettre en avant le potentiel de
DeepSeek Code s'apprête à être lancé
Alors que les technologies d'IA progressent à grands pas, DeepSeek se trouve à un tournant passionnant. L'entreprise spécialisée dans l'IA a récemment annoncé avoir levé plus de 70 milliards de yuans.
Recommandations de sujets spéciaux liés
Entreprise
 Les meilleurs outils de recrutement basés sur l'IA : triez les CV et automatisez la planification des entretiens avec les candidats
Les meilleurs outils de recrutement basés sur l'IA : triez les CV et automatisez la planification des entretiens avec les candidats
Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
 10 outils
10 outils
 xix.ai
Productivité
Coaches IA dédiés au bien-être et à la concentration : gérer l'épuisement professionnel et booster son énergie mentale
xix.ai
Productivité
Coaches IA dédiés au bien-être et à la concentration : gérer l'épuisement professionnel et booster son énergie mentale
Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai
chatbot
Les meilleurs chatbots romantiques basés sur l'IA : nouez des relations durables grâce à des personnalités cohérentes
Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
10 outils
xix.ai
Éducation et apprentissage
Meilleurs mentors en science des données et intelligence artificielle : maîtrise de SQL, Pandas et des workflows d'apprentissage automatique
Découvrez les meilleurs mentors en sciences des données et en intelligence artificielle pour 2026 afin de maîtriser SQL, Pandas et les workflows d'apprentissage automatique. Explorez notre sélection soigneusement élaborée sur XIX.AI pour bénéficier d'une guidance puissante et révolutionnaire. Comparez les options gratuites et payantes en tenant compte de perspectives pratiques. Développez rapidement vos compétences en sciences des données.
10 outils
xix.ai
chatbot
Les meilleurs outils d'IA pour apprendre à flirter et à converser : renforcez votre charisme social et votre confiance en vous en temps réel
Découvrez les meilleurs outils d'entraînement au flirt et à la conversation basés sur l'IA de 2026 sur XIX.AI. Notre sélection triée sur le volet et très bien notée vous aide à développer votre charisme social et votre confiance en vous en temps réel. Découvrez des outils incontournables qui changent la donne, avec des comparaisons entre versions gratuites et payantes ainsi que des classements mis à jour chaque semaine. Développez dès aujourd'hui vos compétences sociales.
10 outils
xix.ai
code
Meilleurs outils d'IA pour les tests unitaires automatisés : générer des cas de test Jest, PyTest et JUnit en un clic
Découvrez les derniers outils d'IA hautement réputés de 2026 pour les tests unitaires automatisés. Notre sélection rigoureusement élaborée vous propose des solutions puissantes et révolutionnaires pour générer instantanément des cas de test Jest, PyTest et JUnit. Comparez les options gratuites et payantes à l'aide de tests réels et des classements mises à jour chaque semaine sur XIX.AI. Développez un avantage concurrentiel grâce à l'IA et améliorez rapidement votre productivité en développement.
10 outils
xix.ai

 commentaires (0)
commentaires (0)
Google a récemment dévoilé son nouveau modèle d'encodage multimodal natif, Gemini Embedding2. Celui-ci permet de cartographier du texte, des images, des vidéos, des fichiers audio et des documents PDF dans un espace vectoriel sémantique commun, conçu pour rationaliser les flux de données complexes liés à l'IA et améliorer la recherche et la compréhension multimodales. Il s'agit d'une avancée majeure pour Google dans le domaine de la technologie d'encodage, marquant le passage d'un modèle textuel monomodal à une modélisation sémantique multimodale unifiée.
Auparavant, en juillet 2025, Google avait présenté le modèle d'intégration de texte gemini-embedding-001. Celui-ci prenait en charge plus de 100 langues et avait obtenu d'excellents résultats lors du benchmark multilingue MTEB. Le nouveau Gemini Embedding2 s'appuie sur l'architecture Gemini tout en élargissant considérablement son champ d'application. Il traite désormais cinq modalités différentes — texte, images, vidéo, audio et PDF — et les projette dans un espace vectoriel unique. Cela permet d'effectuer des comparaisons sémantiques directes entre différents types de médias sans avoir besoin de plusieurs modèles spécialisés ni d'étapes de traitement supplémentaires. Cette capacité est particulièrement utile pour des applications telles que la recherche sémantique, la génération augmentée par la recherche (RAG), l'analyse des sentiments et le regroupement de données.
En ce qui concerne les capacités d'entrée, le nouveau modèle prend en charge jusqu'à 8 192 tokens de texte, soit quatre fois la limite précédente de 2 048 tokens. Il peut traiter jusqu'à six images PNG ou JPEG par requête, des vidéos d'une durée maximale de 120 secondes et des documents PDF comptant jusqu'à six pages. Une fonctionnalité notable est la prise en charge native du traitement audio par Gemini Embedding2, qui élimine le besoin de conversion de la parole en texte et évite toute perte d'information potentielle due à la transcription. Google a également introduit la technologie « d'entrée entrelacée », permettant aux développeurs de combiner plusieurs modalités en une seule requête — comme mélanger des images avec du texte descriptif — afin de mieux saisir les relations sémantiques entre elles.
Sur le plan architectural, le modèle continue d'utiliser le Matryoshka Representation Learning (MRL). Cette technique utilise une structure hiérarchique pour ajuster dynamiquement les dimensions des vecteurs. La dimension d'intégration par défaut est de 3072, avec des configurations optionnelles de 1536 et 768 disponibles, offrant aux développeurs la flexibilité nécessaire pour trouver un équilibre entre la précision de la recherche et l'efficacité du stockage.
Les résultats des tests de performance de Google indiquent que Gemini Embedding2 offre des performances de pointe pour les tâches liées au texte, à l'image, à la vidéo et à la parole. Par exemple, en recherche texte-vidéo, il obtient un score de 68,8, surpassant Amazon Nova2Multimodal Embeddings (60,3) et Voyage Multimodal3.5 (55,2). En comparaison texte-image, il atteint un score de 93,4, nettement supérieur au score du modèle d'Amazon (84,0).
Gemini Embedding2 est actuellement accessible aux développeurs via l'API Gemini et Vertex AI. Il s'intègre aux frameworks et bases de données vectorielles populaires tels que LangChain, LlamaIndex, Haystack, Weaviate, Qdrant, ChromaDB et Vector Search. Pour aider les développeurs à se lancer, Google fournit des notebooks Colab interactifs et des démonstrations de recherche sémantique multimodale allégées.
La concurrence dans le domaine de l'intégration multimodale s'intensifie. Il convient notamment de noter qu'à la fin du mois de février de cette année, le moteur de recherche IA Perplexity a publié ses modèles d'intégration open source, pplx-embed-v1 et pplx-embed-context-v1.










 WordPress.com permet désormais à des agents IA de rédiger et de publier des articles, et bien plus encore
WordPress.com, la célèbre plateforme d'hébergement et de publication Web, se tourne désormais vers les agents IA, une initiative qui pourrait bien redéfinir l'apparence et l'ergonomie du Web. La socié
WordPress.com permet désormais à des agents IA de rédiger et de publier des articles, et bien plus encore
WordPress.com, la célèbre plateforme d'hébergement et de publication Web, se tourne désormais vers les agents IA, une initiative qui pourrait bien redéfinir l'apparence et l'ergonomie du Web. La socié
 Claude, l'IA expérimentale d'Anthropic, mène à bien des négociations et des transactions dans le cadre d'un test de commerce électronique
Alors que l'intelligence artificielle progresse à grands pas, Anthropic a discrètement lancé vendredi dernier une expérience interne baptisée « Project Deal », visant à mettre en avant le potentiel de
Claude, l'IA expérimentale d'Anthropic, mène à bien des négociations et des transactions dans le cadre d'un test de commerce électronique
Alors que l'intelligence artificielle progresse à grands pas, Anthropic a discrètement lancé vendredi dernier une expérience interne baptisée « Project Deal », visant à mettre en avant le potentiel de
 DeepSeek Code s'apprête à être lancé
Alors que les technologies d'IA progressent à grands pas, DeepSeek se trouve à un tournant passionnant. L'entreprise spécialisée dans l'IA a récemment annoncé avoir levé plus de 70 milliards de yuans.
DeepSeek Code s'apprête à être lancé
Alors que les technologies d'IA progressent à grands pas, DeepSeek se trouve à un tournant passionnant. L'entreprise spécialisée dans l'IA a récemment annoncé avoir levé plus de 70 milliards de yuans.

Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
10 outils
xix.ai

Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai

Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs mentors en sciences des données et en intelligence artificielle pour 2026 afin de maîtriser SQL, Pandas et les workflows d'apprentissage automatique. Explorez notre sélection soigneusement élaborée sur XIX.AI pour bénéficier d'une guidance puissante et révolutionnaire. Comparez les options gratuites et payantes en tenant compte de perspectives pratiques. Développez rapidement vos compétences en sciences des données.
10 outils
xix.ai

Découvrez les meilleurs outils d'entraînement au flirt et à la conversation basés sur l'IA de 2026 sur XIX.AI. Notre sélection triée sur le volet et très bien notée vous aide à développer votre charisme social et votre confiance en vous en temps réel. Découvrez des outils incontournables qui changent la donne, avec des comparaisons entre versions gratuites et payantes ainsi que des classements mis à jour chaque semaine. Développez dès aujourd'hui vos compétences sociales.
10 outils
xix.ai

Découvrez les derniers outils d'IA hautement réputés de 2026 pour les tests unitaires automatisés. Notre sélection rigoureusement élaborée vous propose des solutions puissantes et révolutionnaires pour générer instantanément des cas de test Jest, PyTest et JUnit. Comparez les options gratuites et payantes à l'aide de tests réels et des classements mises à jour chaque semaine sur XIX.AI. Développez un avantage concurrentiel grâce à l'IA et améliorez rapidement votre productivité en développement.
10 outils
xix.ai













