
















 Дом
Дом
Google представляет Gemini Embedding2: собственная мультимодальная модель, объединяющая семантические пространства
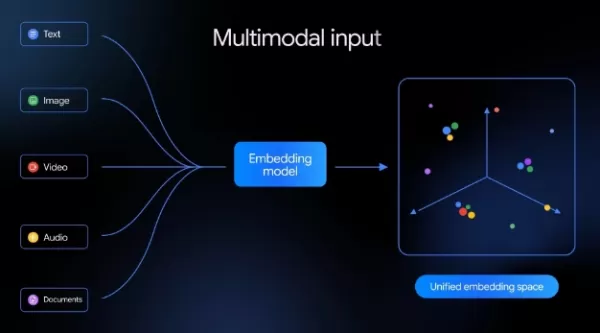
Недавно компания Google представила свою новую нативную мультимодальную модель вложений — Gemini Embedding2. Она позволяет отображать текст, изображения, видео, аудио и PDF-документы в единое семантическое векторное пространство, что призвано оптимизировать сложные рабочие процессы с данными искусственного интеллекта и улучшить мультимодальный поиск и понимание. Это стало важным прорывом для Google в области технологий вложений, ознаменовавшим переход от одномодального текста к унифицированному мультимодальному семантическому моделированию.

Ранее, в июле 2025 года, Google представила модель текстового встраивания gemini-embedding-001. Она поддерживала более 100 языков и достигла лучших результатов в многоязычном тесте MTEB. Новая Gemini Embedding2 основана на архитектуре Gemini, но значительно расширяет ее возможности. Теперь она обрабатывает пять различных модальностей — текст, изображения, видео, аудио и PDF-файлы — и проецирует их в единое векторное пространство. Это позволяет проводить прямые семантические сравнения между различными типами медиа без необходимости использования нескольких специализированных моделей или дополнительных этапов обработки. Эта возможность особенно ценна для таких приложений, как семантический поиск, генерация с расширением поиска (RAG), анализ тональности и кластеризация данных.
Что касается возможностей ввода, новая модель поддерживает до 8192 текстовых токенов, что в четыре раза превышает прежний лимит в 2048 токенов. Она может обрабатывать до шести изображений в формате PNG или JPEG на один запрос, видео длительностью до 120 секунд и PDF-документы объемом до шести страниц. Примечательной особенностью является встроенная поддержка Gemini Embedding2 для обработки аудио, что устраняет необходимость преобразования речи в текст и позволяет избежать потенциальной потери информации при транскрипции. Google также представила технологию «чередующегося ввода», позволяющую разработчикам комбинировать несколько модальностей в одном запросе — например, смешивать изображения с описательным текстом — для лучшего отражения семантических отношений между ними.
С архитектурной точки зрения модель по-прежнему использует Matryoshka Representation Learning (MRL). Эта техника использует иерархическую структуру для динамической настройки размерности векторов. Размерность встраивания по умолчанию составляет 3072, при этом доступны дополнительные конфигурации 1536 и 768, что дает разработчикам гибкость для балансировки точности поиска и эффективности хранения.
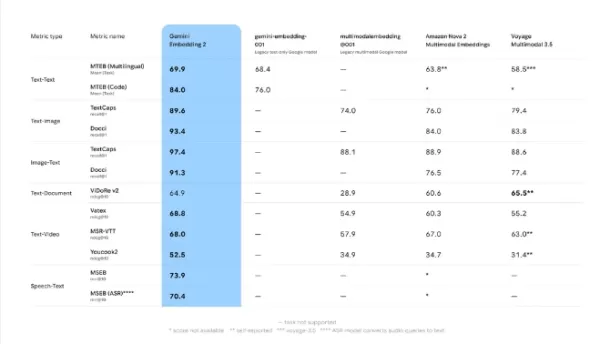
Результаты тестирования Google показывают, что Gemini Embedding2 демонстрирует лидирующую производительность при выполнении задач с текстом, изображениями, видео и речью. Например, при поиске по тексту и видео она набирает 68,8 баллов, превосходя Amazon Nova2Multimodal Embeddings (60,3) и Voyage Multimodal3.5 (55,2). При сравнении текста и изображений он набирает 93,4 балла, что значительно превосходит результат модели Amazon (84,0).
В настоящее время Gemini Embedding2 доступен разработчикам через Gemini API и Vertex AI. Он интегрируется с популярными фреймворками и векторными базами данных, такими как LangChain, LlamaIndex, Haystack, Weaviate, Qdrant, ChromaDB и Vector Search. Чтобы помочь разработчикам начать работу, Google предоставляет интерактивные ноутбуки Colab и демонстрации облегченного мультимодального семантического поиска.
Конкуренция в области мультимодального встраивания набирает обороты. В частности, в конце февраля этого года поисковая система на базе ИИ Perplexity выпустила свои модели встраивания с открытым исходным кодом: pplx-embed-v1 и pplx-embed-context-v1.
Связанная статья
 Экспериментальный ИИ Claude от компании Anthropic успешно завершил переговоры и сделки в ходе тестирования в сфере электронной коммерции
На фоне стремительного развития искусственного интеллекта компания Anthropic в минувшую пятницу незаметно запустила внутренний эксперимент под названием «Project Deal», продемонстрировав потенциал ИИ
DeepSeek Code готовится к запуску
На фоне стремительного развития технологий искусственного интеллекта компания DeepSeek находится на захватывающем этапе своего развития. Недавно эта компания, специализирующаяся на ИИ, объявила о прив
Grok от Маска: 1,5 триллиона параметров и поглощение кода курсора — прорыв или блеф?
Илон Маск наконец-то делает ход.В гонке по программированию ИИ компании OpenAI и Anthropic набирают обороты, в то время как xAI, похоже, отстает. Маск не раз заявлял о своем намерении составить конкур
Рекомендации по связанным специальным темам
Бизнес
Экспериментальный ИИ Claude от компании Anthropic успешно завершил переговоры и сделки в ходе тестирования в сфере электронной коммерции
На фоне стремительного развития искусственного интеллекта компания Anthropic в минувшую пятницу незаметно запустила внутренний эксперимент под названием «Project Deal», продемонстрировав потенциал ИИ
DeepSeek Code готовится к запуску
На фоне стремительного развития технологий искусственного интеллекта компания DeepSeek находится на захватывающем этапе своего развития. Недавно эта компания, специализирующаяся на ИИ, объявила о прив
Grok от Маска: 1,5 триллиона параметров и поглощение кода курсора — прорыв или блеф?
Илон Маск наконец-то делает ход.В гонке по программированию ИИ компании OpenAI и Anthropic набирают обороты, в то время как xAI, похоже, отстает. Маск не раз заявлял о своем намерении составить конкур
Рекомендации по связанным специальным темам
Бизнес
 Лучшие инструменты для подбора персонала с помощью ИИ: отбор резюме и автоматизация планирования собеседований с кандидатами
Лучшие инструменты для подбора персонала с помощью ИИ: отбор резюме и автоматизация планирования собеседований с кандидатами
Откройте для себя 20 лучших инструментов для рекрутинга на базе ИИ 2026 года на сайте XIX.AI. В нашем тщательно составленном списке представлены мощные, революционные решения для отбора резюме и автоматизации планирования собеседований с кандидатами. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Найдите своего идеального помощника по подбору персонала и оптимизируйте процесс рекрутинга уже сегодня!
 10 инструментов
10 инструментов
 xix.ai
Производительность
Персональные тренеры по благополучию и концентрации на базе ИИ: борьба с выгоранием и повышение уровня умственной энергии
xix.ai
Производительность
Персональные тренеры по благополучию и концентрации на базе ИИ: борьба с выгоранием и повышение уровня умственной энергии
Откройте для себя лучших в 2026 году ИИ-тренеров по личному благополучию и концентрации внимания на сайте XIX.AI. В нашем тщательно составленном рейтинге представлены высокооцененные, революционные инструменты для борьбы с выгоранием и повышения умственной энергии. Сравните бесплатные и платные варианты с помощью реальных отзывов. Откройте для себя путь к максимальной продуктивности и благополучию уже сегодня.
10 инструментов
xix.ai
чат-бот
Лучшие романтические чат-боты на базе ИИ: постройте долгосрочные отношения с помощью чат-ботов с устойчивой индивидуальностью
Откройте для себя лучшие романтические чат-боты с искусственным интеллектом 2026 года, которые помогут вам построить искренние и долгосрочные отношения. В нашем тщательно составленном списке вы найдете чат-ботов с яркими и последовательными личностями, сравнение бесплатных и платных версий, а также результаты реальных тестов. Найдите своего идеального спутника и начните строить отношения уже сегодня на XIX.AI.
10 инструментов
xix.ai
Образование и обучение
Лучшие наставники в области искусственного интеллекта и науки о данных: мастерство работы с SQL, библиотекой Pandas и рабочими процессами машинного обучения
Откройте для себя 20 лучших наставников в области искусственного интеллекта и науки о данных на 2026 год, которые помогут вам овладеть SQL, Pandas и рабочими процессами машинного обучения. Изучите наш тщательно отобранный список на сайте XIX.AI – здесь вы найдете эффективные рекомендации, способные изменить ход ваших работ. Сравните бесплатные и платные варианты с примерами из реальной практики. Освоите науку о данных уже сегодня.
10 инструментов
xix.ai
чат-бот
Лучшие тренажеры по флирту и общению на базе ИИ: повышайте свою харизму и уверенность в себе в режиме реального времени
Откройте для себя 20 лучших тренажеров по флирту и общению с ИИ на сайте XIX.AI. Наша тщательно подобранная подборка самых популярных инструментов поможет вам развить коммуникабельность и уверенность в себе в режиме реального времени. Ознакомьтесь с незаменимыми инструментами, которые кардинально изменят вашу жизнь, — с сравнением бесплатных и платных версий и еженедельно обновляемым рейтингом. Раскройте свой коммуникативный потенциал уже сегодня.
10 инструментов
xix.ai
код
Лучшие инструменты ИИ для автоматизированного тестирования модулей: создание случаев тестирования Jest, PyTest и JUnit одним кликом
Откройте для себя самые новые и высоко оцененные инструменты ИИ 2026 года для автоматизированного тестирования модулей. Наша тщательно подобранная коллекция включает мощные решения, способные радикально изменить процесс разработки, позволяющие мгновенно генерировать тестовые случаи для Jest, PyTest и JUnit. Сравните бесплатные и платные варианты с результатами реальных тестов, а также еженедельно обновляемыми рейтингами на сайте XIX.AI. Раскройте потенциал ИИ и повысьте эффективность своей работы в области разработки сегодня же.
10 инструментов
xix.ai

 Комментарии (0)
Комментарии (0)
Недавно компания Google представила свою новую нативную мультимодальную модель вложений — Gemini Embedding2. Она позволяет отображать текст, изображения, видео, аудио и PDF-документы в единое семантическое векторное пространство, что призвано оптимизировать сложные рабочие процессы с данными искусственного интеллекта и улучшить мультимодальный поиск и понимание. Это стало важным прорывом для Google в области технологий вложений, ознаменовавшим переход от одномодального текста к унифицированному мультимодальному семантическому моделированию.
Ранее, в июле 2025 года, Google представила модель текстового встраивания gemini-embedding-001. Она поддерживала более 100 языков и достигла лучших результатов в многоязычном тесте MTEB. Новая Gemini Embedding2 основана на архитектуре Gemini, но значительно расширяет ее возможности. Теперь она обрабатывает пять различных модальностей — текст, изображения, видео, аудио и PDF-файлы — и проецирует их в единое векторное пространство. Это позволяет проводить прямые семантические сравнения между различными типами медиа без необходимости использования нескольких специализированных моделей или дополнительных этапов обработки. Эта возможность особенно ценна для таких приложений, как семантический поиск, генерация с расширением поиска (RAG), анализ тональности и кластеризация данных.
Что касается возможностей ввода, новая модель поддерживает до 8192 текстовых токенов, что в четыре раза превышает прежний лимит в 2048 токенов. Она может обрабатывать до шести изображений в формате PNG или JPEG на один запрос, видео длительностью до 120 секунд и PDF-документы объемом до шести страниц. Примечательной особенностью является встроенная поддержка Gemini Embedding2 для обработки аудио, что устраняет необходимость преобразования речи в текст и позволяет избежать потенциальной потери информации при транскрипции. Google также представила технологию «чередующегося ввода», позволяющую разработчикам комбинировать несколько модальностей в одном запросе — например, смешивать изображения с описательным текстом — для лучшего отражения семантических отношений между ними.
С архитектурной точки зрения модель по-прежнему использует Matryoshka Representation Learning (MRL). Эта техника использует иерархическую структуру для динамической настройки размерности векторов. Размерность встраивания по умолчанию составляет 3072, при этом доступны дополнительные конфигурации 1536 и 768, что дает разработчикам гибкость для балансировки точности поиска и эффективности хранения.
Результаты тестирования Google показывают, что Gemini Embedding2 демонстрирует лидирующую производительность при выполнении задач с текстом, изображениями, видео и речью. Например, при поиске по тексту и видео она набирает 68,8 баллов, превосходя Amazon Nova2Multimodal Embeddings (60,3) и Voyage Multimodal3.5 (55,2). При сравнении текста и изображений он набирает 93,4 балла, что значительно превосходит результат модели Amazon (84,0).
В настоящее время Gemini Embedding2 доступен разработчикам через Gemini API и Vertex AI. Он интегрируется с популярными фреймворками и векторными базами данных, такими как LangChain, LlamaIndex, Haystack, Weaviate, Qdrant, ChromaDB и Vector Search. Чтобы помочь разработчикам начать работу, Google предоставляет интерактивные ноутбуки Colab и демонстрации облегченного мультимодального семантического поиска.
Конкуренция в области мультимодального встраивания набирает обороты. В частности, в конце февраля этого года поисковая система на базе ИИ Perplexity выпустила свои модели встраивания с открытым исходным кодом: pplx-embed-v1 и pplx-embed-context-v1.










 Экспериментальный ИИ Claude от компании Anthropic успешно завершил переговоры и сделки в ходе тестирования в сфере электронной коммерции
На фоне стремительного развития искусственного интеллекта компания Anthropic в минувшую пятницу незаметно запустила внутренний эксперимент под названием «Project Deal», продемонстрировав потенциал ИИ
Экспериментальный ИИ Claude от компании Anthropic успешно завершил переговоры и сделки в ходе тестирования в сфере электронной коммерции
На фоне стремительного развития искусственного интеллекта компания Anthropic в минувшую пятницу незаметно запустила внутренний эксперимент под названием «Project Deal», продемонстрировав потенциал ИИ
 DeepSeek Code готовится к запуску
На фоне стремительного развития технологий искусственного интеллекта компания DeepSeek находится на захватывающем этапе своего развития. Недавно эта компания, специализирующаяся на ИИ, объявила о прив
DeepSeek Code готовится к запуску
На фоне стремительного развития технологий искусственного интеллекта компания DeepSeek находится на захватывающем этапе своего развития. Недавно эта компания, специализирующаяся на ИИ, объявила о прив
 Grok от Маска: 1,5 триллиона параметров и поглощение кода курсора — прорыв или блеф?
Илон Маск наконец-то делает ход.В гонке по программированию ИИ компании OpenAI и Anthropic набирают обороты, в то время как xAI, похоже, отстает. Маск не раз заявлял о своем намерении составить конкур
Grok от Маска: 1,5 триллиона параметров и поглощение кода курсора — прорыв или блеф?
Илон Маск наконец-то делает ход.В гонке по программированию ИИ компании OpenAI и Anthropic набирают обороты, в то время как xAI, похоже, отстает. Маск не раз заявлял о своем намерении составить конкур

Откройте для себя 20 лучших инструментов для рекрутинга на базе ИИ 2026 года на сайте XIX.AI. В нашем тщательно составленном списке представлены мощные, революционные решения для отбора резюме и автоматизации планирования собеседований с кандидатами. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Найдите своего идеального помощника по подбору персонала и оптимизируйте процесс рекрутинга уже сегодня!
10 инструментов
xix.ai

Откройте для себя лучших в 2026 году ИИ-тренеров по личному благополучию и концентрации внимания на сайте XIX.AI. В нашем тщательно составленном рейтинге представлены высокооцененные, революционные инструменты для борьбы с выгоранием и повышения умственной энергии. Сравните бесплатные и платные варианты с помощью реальных отзывов. Откройте для себя путь к максимальной продуктивности и благополучию уже сегодня.
10 инструментов
xix.ai

Откройте для себя лучшие романтические чат-боты с искусственным интеллектом 2026 года, которые помогут вам построить искренние и долгосрочные отношения. В нашем тщательно составленном списке вы найдете чат-ботов с яркими и последовательными личностями, сравнение бесплатных и платных версий, а также результаты реальных тестов. Найдите своего идеального спутника и начните строить отношения уже сегодня на XIX.AI.
10 инструментов
xix.ai

Откройте для себя 20 лучших наставников в области искусственного интеллекта и науки о данных на 2026 год, которые помогут вам овладеть SQL, Pandas и рабочими процессами машинного обучения. Изучите наш тщательно отобранный список на сайте XIX.AI – здесь вы найдете эффективные рекомендации, способные изменить ход ваших работ. Сравните бесплатные и платные варианты с примерами из реальной практики. Освоите науку о данных уже сегодня.
10 инструментов
xix.ai

Откройте для себя 20 лучших тренажеров по флирту и общению с ИИ на сайте XIX.AI. Наша тщательно подобранная подборка самых популярных инструментов поможет вам развить коммуникабельность и уверенность в себе в режиме реального времени. Ознакомьтесь с незаменимыми инструментами, которые кардинально изменят вашу жизнь, — с сравнением бесплатных и платных версий и еженедельно обновляемым рейтингом. Раскройте свой коммуникативный потенциал уже сегодня.
10 инструментов
xix.ai

Откройте для себя самые новые и высоко оцененные инструменты ИИ 2026 года для автоматизированного тестирования модулей. Наша тщательно подобранная коллекция включает мощные решения, способные радикально изменить процесс разработки, позволяющие мгновенно генерировать тестовые случаи для Jest, PyTest и JUnit. Сравните бесплатные и платные варианты с результатами реальных тестов, а также еженедельно обновляемыми рейтингами на сайте XIX.AI. Раскройте потенциал ИИ и повысьте эффективность своей работы в области разработки сегодня же.
10 инструментов
xix.ai













