
















 Hogar
Hogar
Google presenta Gemini Embedding2: un modelo multimodal nativo que unifica los espacios semánticos
Google ha presentado recientemente su nuevo modelo de incrustación multimodal nativo, Gemini Embedding2. Este modelo permite mapear texto, imágenes, vídeos, audio y documentos PDF en un espacio vectorial semántico compartido, diseñado para optimizar los complejos flujos de trabajo de datos de IA y mejorar la recuperación y la comprensión multimodal. Esto supone un avance clave para Google en la tecnología de incrustación, al pasar de la incrustación de texto de una sola modalidad a un modelado semántico multimodal unificado.

Anteriormente, en julio de 2025, Google presentó el modelo de incrustación de texto gemini-embedding-001. Este modelo era compatible con más de 100 idiomas y obtuvo los mejores resultados en el banco de pruebas multilingüe MTEB. El nuevo Gemini Embedding2 se basa en la arquitectura Gemini, pero amplía significativamente su alcance. Ahora procesa cinco modalidades diferentes —texto, imágenes, vídeo, audio y PDF— y las proyecta en un único espacio vectorial. Esto permite realizar comparaciones semánticas directas entre diferentes tipos de medios sin necesidad de múltiples modelos especializados ni pasos de procesamiento adicionales. Esta capacidad resulta especialmente valiosa para aplicaciones como la búsqueda semántica, la generación aumentada por recuperación (RAG), el análisis de sentimientos y la agrupación de datos.
En cuanto a las capacidades de entrada, el nuevo modelo admite hasta 8192 tokens de texto, el cuádruple del límite anterior de 2048 tokens. Puede gestionar hasta seis imágenes PNG o JPEG por solicitud, vídeos de hasta 120 segundos de duración y documentos PDF de hasta seis páginas. Una característica destacable es la compatibilidad nativa de Gemini Embedding2 con el procesamiento de audio, lo que elimina la necesidad de conversión de voz a texto y evita la posible pérdida de información derivada de la transcripción. Google también ha introducido la tecnología de «entrada intercalada», que permite a los desarrolladores combinar múltiples modalidades en una sola solicitud —como mezclar imágenes con texto descriptivo— para captar mejor las relaciones semánticas entre ellas.
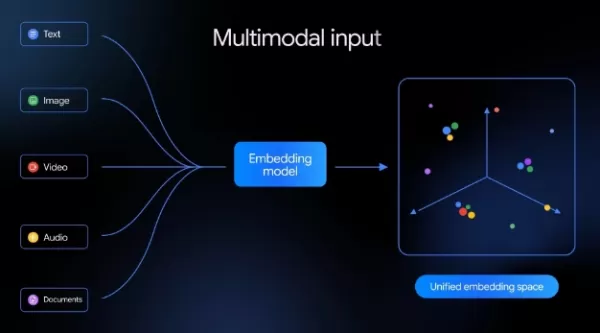
Desde el punto de vista arquitectónico, el modelo sigue empleando el Matryoshka Representation Learning (MRL). Esta técnica utiliza una estructura jerárquica para ajustar dinámicamente las dimensiones de los vectores. La dimensión de incrustación predeterminada es 3072, con configuraciones opcionales de 1536 y 768 disponibles, lo que ofrece a los desarrolladores flexibilidad para equilibrar la precisión de la recuperación con la eficiencia del almacenamiento.
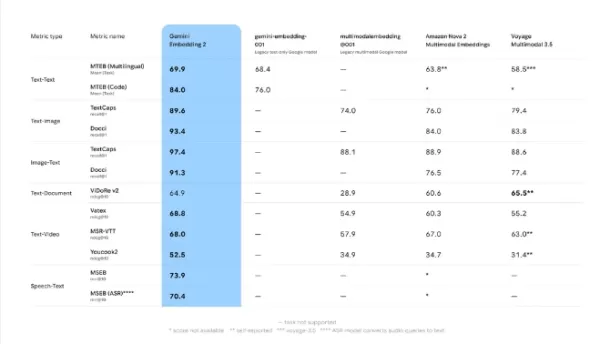
Los resultados de las pruebas comparativas de Google indican que Gemini Embedding2 ofrece un rendimiento líder en tareas de texto, imagen, vídeo y voz. Por ejemplo, en la recuperación de texto y vídeo, obtiene una puntuación de 68,8, superando a Amazon Nova2Multimodal Embeddings (60,3) y a Voyage Multimodal3.5 (55,2). En la comparación de texto e imagen, alcanza una puntuación de 93,4, muy por delante de la puntuación del modelo de Amazon, que es de 84,0.
Actualmente, los desarrolladores pueden acceder a Gemini Embedding2 a través de la API de Gemini y Vertex AI. Se integra con marcos de trabajo y bases de datos vectoriales populares como LangChain, LlamaIndex, Haystack, Weaviate, Qdrant, ChromaDB y Vector Search. Para ayudar a los desarrolladores a dar sus primeros pasos, Google ofrece cuadernos Colab interactivos y demostraciones de búsqueda semántica multimodal ligeras.
La competencia en el ámbito de la incrustación multimodal se está recrudeciendo. Cabe destacar que, a finales de febrero de este año, el motor de búsqueda de IA Perplexity lanzó sus modelos de incrustación de código abierto, pplx-embed-v1 y pplx-embed-context-v1.
Artículo relacionado
 Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
WordPress.com ya permite que los agentes de IA redacten y publiquen entradas, entre otras cosas
WordPress.com, la popular plataforma de alojamiento web y publicación, está incorporando ahora agentes de IA, una iniciativa que podría transformar el aspecto y la experiencia de la web. La empresa an
Claude, la IA experimental de Anthropic, lleva a cabo negociaciones y transacciones en una prueba de comercio electrónico
A medida que la inteligencia artificial avanza rápidamente, Anthropic puso en marcha discretamente el pasado viernes un experimento interno denominado «Project Deal», en el que se ponía de manifiesto
Recomendaciones de temas especiales relacionados
Negocio
Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
WordPress.com ya permite que los agentes de IA redacten y publiquen entradas, entre otras cosas
WordPress.com, la popular plataforma de alojamiento web y publicación, está incorporando ahora agentes de IA, una iniciativa que podría transformar el aspecto y la experiencia de la web. La empresa an
Claude, la IA experimental de Anthropic, lleva a cabo negociaciones y transacciones en una prueba de comercio electrónico
A medida que la inteligencia artificial avanza rápidamente, Anthropic puso en marcha discretamente el pasado viernes un experimento interno denominado «Project Deal», en el que se ponía de manifiesto
Recomendaciones de temas especiales relacionados
Negocio
 Las mejores herramientas de selección de personal basadas en IA: filtrar currículos y automatizar la programación de entrevistas con los candidatos
Las mejores herramientas de selección de personal basadas en IA: filtrar currículos y automatizar la programación de entrevistas con los candidatos
Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
 10 herramientas
10 herramientas
 xix.ai
Productividad
Entrenadores personales de bienestar y concentración basados en IA: controla el agotamiento y aumenta tus niveles de energía mental
xix.ai
Productividad
Entrenadores personales de bienestar y concentración basados en IA: controla el agotamiento y aumenta tus niveles de energía mental
Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai
chatbot
Los mejores chatbots románticos con IA: crea relaciones duraderas con personalidades coherentes
Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai
Educación y aprendizaje
Los mejores mentores en ciencia de datos y IA: dominan SQL, Pandas y flujos de trabajo de aprendizaje automático.
Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
10 herramientas
xix.ai
chatbot
Los mejores entrenadores de IA para ligar y conversar: mejora tu carisma social y tu confianza en tiempo real
Descubre los mejores cursos de 2026 sobre coqueteo y conversación con IA en XIX.AI. Nuestra selección, cuidadosamente seleccionada y con las mejores valoraciones, te ayuda a desarrollar tu carisma social y tu confianza en tiempo real. Explora herramientas imprescindibles y revolucionarias con comparativas entre versiones gratuitas y de pago, y clasificaciones que se actualizan semanalmente. Potencia hoy mismo tus habilidades sociales.
10 herramientas
xix.ai
código
Las mejores herramientas de IA para pruebas unitarias automatizadas: genera casos de prueba con Jest, PyTest y JUnit con un solo clic
Descubre las mejores herramientas de IA de 2026 para la automatización de pruebas unitarias. Nuestra selección incluye potentes soluciones revolucionarias que permiten generar casos de prueba para Jest, PyTest y JUnit al instante. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones actualizadas semanalmente en XIX.AI. Aprovecha las ventajas de la IA y aumenta la productividad de tu desarrollo hoy mismo.
10 herramientas
xix.ai

 comentario (0)
0/500
comentario (0)
0/500
Google ha presentado recientemente su nuevo modelo de incrustación multimodal nativo, Gemini Embedding2. Este modelo permite mapear texto, imágenes, vídeos, audio y documentos PDF en un espacio vectorial semántico compartido, diseñado para optimizar los complejos flujos de trabajo de datos de IA y mejorar la recuperación y la comprensión multimodal. Esto supone un avance clave para Google en la tecnología de incrustación, al pasar de la incrustación de texto de una sola modalidad a un modelado semántico multimodal unificado.
Anteriormente, en julio de 2025, Google presentó el modelo de incrustación de texto gemini-embedding-001. Este modelo era compatible con más de 100 idiomas y obtuvo los mejores resultados en el banco de pruebas multilingüe MTEB. El nuevo Gemini Embedding2 se basa en la arquitectura Gemini, pero amplía significativamente su alcance. Ahora procesa cinco modalidades diferentes —texto, imágenes, vídeo, audio y PDF— y las proyecta en un único espacio vectorial. Esto permite realizar comparaciones semánticas directas entre diferentes tipos de medios sin necesidad de múltiples modelos especializados ni pasos de procesamiento adicionales. Esta capacidad resulta especialmente valiosa para aplicaciones como la búsqueda semántica, la generación aumentada por recuperación (RAG), el análisis de sentimientos y la agrupación de datos.
En cuanto a las capacidades de entrada, el nuevo modelo admite hasta 8192 tokens de texto, el cuádruple del límite anterior de 2048 tokens. Puede gestionar hasta seis imágenes PNG o JPEG por solicitud, vídeos de hasta 120 segundos de duración y documentos PDF de hasta seis páginas. Una característica destacable es la compatibilidad nativa de Gemini Embedding2 con el procesamiento de audio, lo que elimina la necesidad de conversión de voz a texto y evita la posible pérdida de información derivada de la transcripción. Google también ha introducido la tecnología de «entrada intercalada», que permite a los desarrolladores combinar múltiples modalidades en una sola solicitud —como mezclar imágenes con texto descriptivo— para captar mejor las relaciones semánticas entre ellas.
Desde el punto de vista arquitectónico, el modelo sigue empleando el Matryoshka Representation Learning (MRL). Esta técnica utiliza una estructura jerárquica para ajustar dinámicamente las dimensiones de los vectores. La dimensión de incrustación predeterminada es 3072, con configuraciones opcionales de 1536 y 768 disponibles, lo que ofrece a los desarrolladores flexibilidad para equilibrar la precisión de la recuperación con la eficiencia del almacenamiento.
Los resultados de las pruebas comparativas de Google indican que Gemini Embedding2 ofrece un rendimiento líder en tareas de texto, imagen, vídeo y voz. Por ejemplo, en la recuperación de texto y vídeo, obtiene una puntuación de 68,8, superando a Amazon Nova2Multimodal Embeddings (60,3) y a Voyage Multimodal3.5 (55,2). En la comparación de texto e imagen, alcanza una puntuación de 93,4, muy por delante de la puntuación del modelo de Amazon, que es de 84,0.
Actualmente, los desarrolladores pueden acceder a Gemini Embedding2 a través de la API de Gemini y Vertex AI. Se integra con marcos de trabajo y bases de datos vectoriales populares como LangChain, LlamaIndex, Haystack, Weaviate, Qdrant, ChromaDB y Vector Search. Para ayudar a los desarrolladores a dar sus primeros pasos, Google ofrece cuadernos Colab interactivos y demostraciones de búsqueda semántica multimodal ligeras.
La competencia en el ámbito de la incrustación multimodal se está recrudeciendo. Cabe destacar que, a finales de febrero de este año, el motor de búsqueda de IA Perplexity lanzó sus modelos de incrustación de código abierto, pplx-embed-v1 y pplx-embed-context-v1.










 Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
 WordPress.com ya permite que los agentes de IA redacten y publiquen entradas, entre otras cosas
WordPress.com, la popular plataforma de alojamiento web y publicación, está incorporando ahora agentes de IA, una iniciativa que podría transformar el aspecto y la experiencia de la web. La empresa an
WordPress.com ya permite que los agentes de IA redacten y publiquen entradas, entre otras cosas
WordPress.com, la popular plataforma de alojamiento web y publicación, está incorporando ahora agentes de IA, una iniciativa que podría transformar el aspecto y la experiencia de la web. La empresa an
 Claude, la IA experimental de Anthropic, lleva a cabo negociaciones y transacciones en una prueba de comercio electrónico
A medida que la inteligencia artificial avanza rápidamente, Anthropic puso en marcha discretamente el pasado viernes un experimento interno denominado «Project Deal», en el que se ponía de manifiesto
Claude, la IA experimental de Anthropic, lleva a cabo negociaciones y transacciones en una prueba de comercio electrónico
A medida que la inteligencia artificial avanza rápidamente, Anthropic puso en marcha discretamente el pasado viernes un experimento interno denominado «Project Deal», en el que se ponía de manifiesto

Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai

Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai

Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai

Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
10 herramientas
xix.ai

Descubre los mejores cursos de 2026 sobre coqueteo y conversación con IA en XIX.AI. Nuestra selección, cuidadosamente seleccionada y con las mejores valoraciones, te ayuda a desarrollar tu carisma social y tu confianza en tiempo real. Explora herramientas imprescindibles y revolucionarias con comparativas entre versiones gratuitas y de pago, y clasificaciones que se actualizan semanalmente. Potencia hoy mismo tus habilidades sociales.
10 herramientas
xix.ai

Descubre las mejores herramientas de IA de 2026 para la automatización de pruebas unitarias. Nuestra selección incluye potentes soluciones revolucionarias que permiten generar casos de prueba para Jest, PyTest y JUnit al instante. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones actualizadas semanalmente en XIX.AI. Aprovecha las ventajas de la IA y aumenta la productividad de tu desarrollo hoy mismo.
10 herramientas
xix.ai













