
















 Maison
MaisonAnt Group dévoile F2LLM-v2 : un modèle d'intégration multilingue à grande échelle
Surmonter la limite dite « centrée sur l'anglais » dans la représentation sémantique est devenu un enjeu majeur dans l'évolution des grands modèles linguistiques.
Le 26 mars, l'équipe CodeFuse d'Ant Group et de l'université Jiao Tong de Shanghai a officiellement lancé la série de modèles d'embedding F2LLM-v2. Cette série a non seulement atteint des performances de pointe dans des benchmarks de référence, mais elle offre également une solution de représentation sémantique performante et efficace aux développeurs du monde entier grâce à une approche entièrement open source.

Des performances exceptionnelles : 11 résultats SOTA sur MTEB
Dans le benchmark MTEB de référence pour l'évaluation des modèles d'embedding, F2LLM-v2 a démontré des atouts globaux :
11 premières places : il s'est classé en tête de 11 classements spécifiques à des langues et à des domaines, notamment l'allemand, le français, le japonais et la recherche de code.
Un challenger redoutable : même ses variantes allégées ont systématiquement surpassé des modèles industriels bien connus de taille comparable.
Couverture étendue : l'évaluation a porté sur 430 sous-tâches diverses, telles que les questions-réponses médicales et la recherche de code, couvrant ainsi l'ensemble des scénarios.
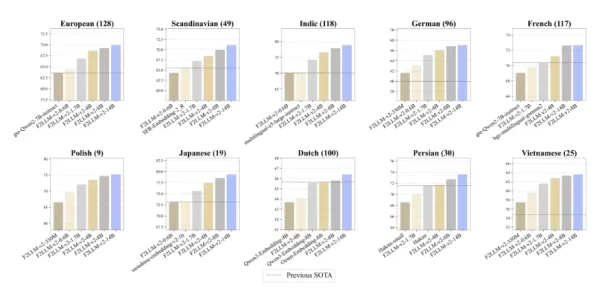
Une compréhension globale : maîtrise de 282 langues naturelles et de plus de 40 langages de programmation
La puissance de F2LLM-v2 découle de sa base d'entraînement hautement inclusive :
Amélioration multilingue : il offre une prise en charge renforcée des langues à ressources moyennes et faibles (telles que les familles de langues nordiques et d'Asie du Sud-Est), permettant une véritable couverture linguistique mondiale.
Expertise en programmation : grâce à sa compréhension approfondie de plus de 40 langages de programmation tels que Python, Java et Go, il constitue le choix idéal pour les développeurs qui créent des systèmes RAG (Retrieval-Augmented Generation) et des assistants de code.
Données de haute qualité : S'appuyant sur 60 millions d'échantillons publics méticuleusement nettoyés, il garantit à la fois la pureté et l'étendue de la base de connaissances du modèle.
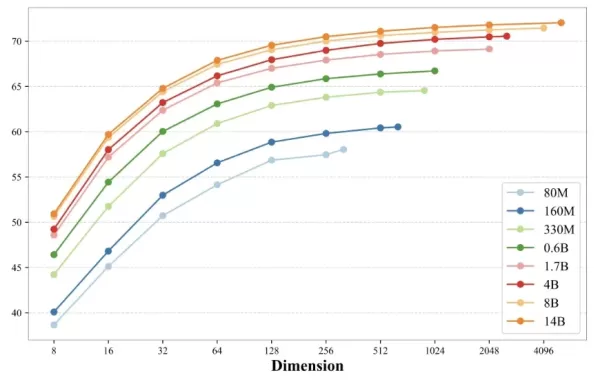
Une efficacité extrême : une famille complète de modèles allant de 80 millions à 14 milliards de paramètres
Pour répondre à des besoins allant des appareils mobiles au cloud computing, l'équipe CodeFuse a développé une matrice de modèles complète :
Optimisation pour les mobiles : des modèles compacts de 80 millions à 330 millions de paramètres utilisent des techniques de « model pruning » et de « knowledge distillation », permettant un fonctionnement fluide sur les plateformes mobiles.
Innovation « imbriquée » : elle prend en charge l'ajustement dynamique des dimensions, permettant aux utilisateurs de basculer de manière flexible entre 8 dimensions et toutes les dimensions, optimisant ainsi le compromis entre vitesse d'inférence et coût de stockage.
Entièrement open source : la transparence établit une nouvelle norme communautaire
Contrairement à de nombreux modèles de type « boîte noire », F2LLM-v2 s'engage dans une philosophie entièrement open source :
Publication complète : tous les poids du modèle pour chaque variante de taille sont disponibles au téléchargement.
Transparence détaillée : un rapport technique complet est publié, dévoilant l'intégralité de la méthodologie d'entraînement.
Reproductibilité totale : tous les codes et points de contrôle de l'entraînement sont publiés, permettant aux chercheurs du monde entier de s'appuyer sur ces travaux pour poursuivre le développement.
Conclusion : repousser les limites pour explorer le potentiel infini de l'IA
Nouvelle étape importante de la série CodeFuse Open Source, la publication de F2LLM-v2
Article connexe
 Xiaohongshu se restructure : Conan nommé président, création d'un département dédié à l'IA et d'une division internationale Rednote
Le 30 avril, Xiaohongshu a adressé une note interne à l'ensemble de ses employés pour annoncer le lancement d'une nouvelle restructuration organisationnelle. Au cœur de cette évolution figure l'intégr
Le jeu « Xiaolongxia » de Tencent dépasse toutes les attentes ; l'équipe multiplie par dix sa capacité, présente ses excuses et offre des compensations
Tencent a officiellement lancé WorkBuddy, un agent intelligent basé sur l'IA et adapté à tous les contextes, marquant ainsi une nouvelle étape dans la course aux applications des grands modèles, carac
Principal investisseur de Suno : la suppression des publications ne comblera pas les lacunes en matière de poursuites pour violation du droit d'auteur
La plateforme de génération musicale par IA très attendue, Suno, est confrontée à une rude bataille en matière de droits d'auteur, et une remarque sans détours de son principal investisseur pourrait b
Recommandations de sujets spéciaux liés
Création de bande dessinée
Xiaohongshu se restructure : Conan nommé président, création d'un département dédié à l'IA et d'une division internationale Rednote
Le 30 avril, Xiaohongshu a adressé une note interne à l'ensemble de ses employés pour annoncer le lancement d'une nouvelle restructuration organisationnelle. Au cœur de cette évolution figure l'intégr
Le jeu « Xiaolongxia » de Tencent dépasse toutes les attentes ; l'équipe multiplie par dix sa capacité, présente ses excuses et offre des compensations
Tencent a officiellement lancé WorkBuddy, un agent intelligent basé sur l'IA et adapté à tous les contextes, marquant ainsi une nouvelle étape dans la course aux applications des grands modèles, carac
Principal investisseur de Suno : la suppression des publications ne comblera pas les lacunes en matière de poursuites pour violation du droit d'auteur
La plateforme de génération musicale par IA très attendue, Suno, est confrontée à une rude bataille en matière de droits d'auteur, et une remarque sans détours de son principal investisseur pourrait b
Recommandations de sujets spéciaux liés
Création de bande dessinée
 Les meilleurs générateurs IA pour les mangas shonen : créez des séquences d'action survoltées et des effets d'énergie
Les meilleurs générateurs IA pour les mangas shonen : créez des séquences d'action survoltées et des effets d'énergie
Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
 15 outils
15 outils
 xix.ai
Entreprise
Les meilleurs outils de suivi des dépenses basés sur l'IA : numérisez vos reçus et classez automatiquement les dépenses de l'entreprise
xix.ai
Entreprise
Les meilleurs outils de suivi des dépenses basés sur l'IA : numérisez vos reçus et classez automatiquement les dépenses de l'entreprise
Les meilleurs outils de gestion des dépenses basés sur l'IA en 2026 : les outils les mieux notés pour numériser vos reçus et classer automatiquement les dépenses de votre entreprise. Découvrez des solutions puissantes et révolutionnaires pour une gestion des dépenses sans effort, un suivi financier précis et une conformité simplifiée. Notre comparatif, mis à jour chaque semaine, qui oppose les options gratuites aux options payantes, vous aide à trouver la solution qui vous convient le mieux. Tirez pleinement parti de l'IA grâce aux recommandations d'experts de XIX.AI.
10 outils
xix.ai
Entreprise
Les meilleurs outils de recrutement basés sur l'IA : triez les CV et automatisez la planification des entretiens avec les candidats
Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
10 outils
xix.ai
Productivité
Coaches IA dédiés au bien-être et à la concentration : gérer l'épuisement professionnel et booster son énergie mentale
Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai
chatbot
Les meilleurs chatbots romantiques basés sur l'IA : nouez des relations durables grâce à des personnalités cohérentes
Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
10 outils
xix.ai
Éducation et apprentissage
Meilleurs mentors en science des données et intelligence artificielle : maîtrise de SQL, Pandas et des workflows d'apprentissage automatique
Découvrez les meilleurs mentors en sciences des données et en intelligence artificielle pour 2026 afin de maîtriser SQL, Pandas et les workflows d'apprentissage automatique. Explorez notre sélection soigneusement élaborée sur XIX.AI pour bénéficier d'une guidance puissante et révolutionnaire. Comparez les options gratuites et payantes en tenant compte de perspectives pratiques. Développez rapidement vos compétences en sciences des données.
10 outils
xix.ai

 commentaires (0)
commentaires (0)
Surmonter la limite dite « centrée sur l'anglais » dans la représentation sémantique est devenu un enjeu majeur dans l'évolution des grands modèles linguistiques.
Le 26 mars, l'équipe CodeFuse d'Ant Group et de l'université Jiao Tong de Shanghai a officiellement lancé la série de modèles d'embedding F2LLM-v2. Cette série a non seulement atteint des performances de pointe dans des benchmarks de référence, mais elle offre également une solution de représentation sémantique performante et efficace aux développeurs du monde entier grâce à une approche entièrement open source.
Des performances exceptionnelles : 11 résultats SOTA sur MTEB
Dans le benchmark MTEB de référence pour l'évaluation des modèles d'embedding, F2LLM-v2 a démontré des atouts globaux :
11 premières places : il s'est classé en tête de 11 classements spécifiques à des langues et à des domaines, notamment l'allemand, le français, le japonais et la recherche de code.
Un challenger redoutable : même ses variantes allégées ont systématiquement surpassé des modèles industriels bien connus de taille comparable.
Couverture étendue : l'évaluation a porté sur 430 sous-tâches diverses, telles que les questions-réponses médicales et la recherche de code, couvrant ainsi l'ensemble des scénarios.
Une compréhension globale : maîtrise de 282 langues naturelles et de plus de 40 langages de programmation
La puissance de F2LLM-v2 découle de sa base d'entraînement hautement inclusive :
Amélioration multilingue : il offre une prise en charge renforcée des langues à ressources moyennes et faibles (telles que les familles de langues nordiques et d'Asie du Sud-Est), permettant une véritable couverture linguistique mondiale.
Expertise en programmation : grâce à sa compréhension approfondie de plus de 40 langages de programmation tels que Python, Java et Go, il constitue le choix idéal pour les développeurs qui créent des systèmes RAG (Retrieval-Augmented Generation) et des assistants de code.
Données de haute qualité : S'appuyant sur 60 millions d'échantillons publics méticuleusement nettoyés, il garantit à la fois la pureté et l'étendue de la base de connaissances du modèle.
Une efficacité extrême : une famille complète de modèles allant de 80 millions à 14 milliards de paramètres
Pour répondre à des besoins allant des appareils mobiles au cloud computing, l'équipe CodeFuse a développé une matrice de modèles complète :
Optimisation pour les mobiles : des modèles compacts de 80 millions à 330 millions de paramètres utilisent des techniques de « model pruning » et de « knowledge distillation », permettant un fonctionnement fluide sur les plateformes mobiles.
Innovation « imbriquée » : elle prend en charge l'ajustement dynamique des dimensions, permettant aux utilisateurs de basculer de manière flexible entre 8 dimensions et toutes les dimensions, optimisant ainsi le compromis entre vitesse d'inférence et coût de stockage.
Entièrement open source : la transparence établit une nouvelle norme communautaire
Contrairement à de nombreux modèles de type « boîte noire », F2LLM-v2 s'engage dans une philosophie entièrement open source :
Publication complète : tous les poids du modèle pour chaque variante de taille sont disponibles au téléchargement.
Transparence détaillée : un rapport technique complet est publié, dévoilant l'intégralité de la méthodologie d'entraînement.
Reproductibilité totale : tous les codes et points de contrôle de l'entraînement sont publiés, permettant aux chercheurs du monde entier de s'appuyer sur ces travaux pour poursuivre le développement.
Conclusion : repousser les limites pour explorer le potentiel infini de l'IA
Nouvelle étape importante de la série CodeFuse Open Source, la publication de F2LLM-v2










 Xiaohongshu se restructure : Conan nommé président, création d'un département dédié à l'IA et d'une division internationale Rednote
Le 30 avril, Xiaohongshu a adressé une note interne à l'ensemble de ses employés pour annoncer le lancement d'une nouvelle restructuration organisationnelle. Au cœur de cette évolution figure l'intégr
Xiaohongshu se restructure : Conan nommé président, création d'un département dédié à l'IA et d'une division internationale Rednote
Le 30 avril, Xiaohongshu a adressé une note interne à l'ensemble de ses employés pour annoncer le lancement d'une nouvelle restructuration organisationnelle. Au cœur de cette évolution figure l'intégr
 Le jeu « Xiaolongxia » de Tencent dépasse toutes les attentes ; l'équipe multiplie par dix sa capacité, présente ses excuses et offre des compensations
Tencent a officiellement lancé WorkBuddy, un agent intelligent basé sur l'IA et adapté à tous les contextes, marquant ainsi une nouvelle étape dans la course aux applications des grands modèles, carac
Le jeu « Xiaolongxia » de Tencent dépasse toutes les attentes ; l'équipe multiplie par dix sa capacité, présente ses excuses et offre des compensations
Tencent a officiellement lancé WorkBuddy, un agent intelligent basé sur l'IA et adapté à tous les contextes, marquant ainsi une nouvelle étape dans la course aux applications des grands modèles, carac
 Principal investisseur de Suno : la suppression des publications ne comblera pas les lacunes en matière de poursuites pour violation du droit d'auteur
La plateforme de génération musicale par IA très attendue, Suno, est confrontée à une rude bataille en matière de droits d'auteur, et une remarque sans détours de son principal investisseur pourrait b
Principal investisseur de Suno : la suppression des publications ne comblera pas les lacunes en matière de poursuites pour violation du droit d'auteur
La plateforme de génération musicale par IA très attendue, Suno, est confrontée à une rude bataille en matière de droits d'auteur, et une remarque sans détours de son principal investisseur pourrait b

Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
15 outils
xix.ai

Les meilleurs outils de gestion des dépenses basés sur l'IA en 2026 : les outils les mieux notés pour numériser vos reçus et classer automatiquement les dépenses de votre entreprise. Découvrez des solutions puissantes et révolutionnaires pour une gestion des dépenses sans effort, un suivi financier précis et une conformité simplifiée. Notre comparatif, mis à jour chaque semaine, qui oppose les options gratuites aux options payantes, vous aide à trouver la solution qui vous convient le mieux. Tirez pleinement parti de l'IA grâce aux recommandations d'experts de XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
10 outils
xix.ai

Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai

Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs mentors en sciences des données et en intelligence artificielle pour 2026 afin de maîtriser SQL, Pandas et les workflows d'apprentissage automatique. Explorez notre sélection soigneusement élaborée sur XIX.AI pour bénéficier d'une guidance puissante et révolutionnaire. Comparez les options gratuites et payantes en tenant compte de perspectives pratiques. Développez rapidement vos compétences en sciences des données.
10 outils
xix.ai













