




Künstliche Intelligenz Sprachveränderer: Stimme im Echtzeit ändern
Haben Sie sich jemals gefragt, wie es wäre, wie Ihr Lieblings-YouTuber, eine Anime-Figur oder sogar ein Promi zu klingen? Mit AI-Stimmenveränderer-Software können Sie Ihre Stimme in Echtzeit verändern und eröffnen damit eine Welt voller Möglichkeiten für Content-Erstellung, Gaming und Online-Interaktionen. In diesem Blog tauchen wir ein in die Möglichkeiten, wie Sie die Kraft der AI nutzen können, um Ihre Stimme in etwas völlig Neues und Aufregendes zu verwandeln.
Wichtige Punkte
- AI-Stimmenveränderer-Software ermöglicht die Stimmenveränderung in Echtzeit.
- Tools wie W-Okada's Voice Changer bieten eine Vielzahl von Stimmenmodellen zur Auswahl.
- Sie können Stimmenmodelle von Plattformen wie Hugging Face herunterladen.
- Ein virtuelles Audiokabel kann helfen, den AI-Stimmenveränderer mit anderen Anwendungen wie Discord zu integrieren.
- Experimentieren und Feinabstimmung sind entscheidend, um die perfekten Einstellungen und Modelle für Ihre einzigartige Stimme zu finden.
Erste Schritte mit AI-Stimmenveränderern
Was ist ein AI-Stimmenveränderer?
Ein AI-Stimmenveränderer ist ein Software-Tool, das künstliche Intelligenz nutzt, um die Eigenschaften Ihrer Stimme in Echtzeit oder nahezu in Echtzeit zu verändern. Es kann Tonhöhe, Klang und Klangfarbe ändern, um eine andere Person nachzuahmen oder eine völlig neue stimmliche Identität zu schaffen. Diese Tools nutzen fortschrittliche maschinelle Lerntechniken wie Voice Cloning und Deep Learning, um Audiosignale zu analysieren und zu manipulieren. Mit dem Aufstieg von Online-Stimmenveränderer-Apps wächst ihre Popularität rasant.

AI-Stimmenveränderer sind unglaublich vielseitig. Gamer nutzen sie für Anonymität oder um Charaktere zu spielen, Content-Creator verwenden sie für Voice-Overs und Erzählungen, und Musiker experimentieren mit einzigartigen Stimmeneffekten. Mit der Weiterentwicklung der Technologie sind die potenziellen Anwendungen grenzenlos.
Beliebter AI-Stimmenveränderer: W-Okada's Voice Changer
W-Okada's Voice Changer ist ein leistungsstarkes Tool, mit dem Sie Ihre Stimme mithilfe von AI verändern können. Es ist kompatibel mit Windows, Mac und Linux. Lassen Sie uns durchgehen, wie Sie mit dieser Software starten können.
W-Okada's Voice Changer herunterladen
- Zugang zum Download-Link: Besuchen Sie die GitHub-Seite von W-Okada und scrollen Sie nach unten, um den Download-Link zu finden. Sie finden ihn in der Beschreibung unten, klicken Sie einfach darauf – es ist der oberste Link.
- Die richtige Version auswählen: Scrollen Sie zur Tabelle am Ende. Wenn Sie eine dedizierte Grafikkarte haben, wählen Sie die Windows CUDA-Version. Es gibt auch eine Mac-Version.
- Umgang mit Download-Problemen: Diese Software ist beliebt, daher müssen Sie sie möglicherweise von Hugging Face oder Google Drive herunterladen. Es ist nur eine Zip-Datei, also keine Sorge.
Nachdem Sie die Datei heruntergeladen haben, entpacken Sie sie in einen speziellen Ordner auf Ihrem Computer. Eine geordnete Struktur erleichtert den Prozess.
Software herunterladen: Es ist eine große Datei, und da ich sie bereits installiert habe, breche ich meinen Download ab. Aber Sie sollten den Download abschließen lassen – es ist sicher, versprochen.
Stimmenmodelle herunterladen und konfigurieren
Der wahre Spaß beginnt mit der Vielfalt an Stimmenmodellen, die Sie verwenden können. So richten Sie sie ein:
- Erstellen der benötigten Ordner: Während die Zip-Datei herunterlädt, erstellen Sie einen neuen Ordner, um alle Ihre AI-Stimmenveränderer-Dateien zu speichern. Sobald der Download abgeschlossen ist, verschieben Sie die Zip-Datei in diesen Ordner und erstellen Sie einen weiteren Ordner namens "models."
- Woher Sie diese Stimmenmodelle bekommen: Sie benötigen Stimmenmodelle, damit dies funktioniert. Wir zeigen Ihnen, wie Sie sie herunterladen, sobald das Programm läuft. Das Tutorial empfiehlt die Nutzung eines Discord-Servers dafür.
- Was nach dem Erstellen aller Ordner zu tun ist: Nachdem Sie die Zip-Datei in Ihren neuen Ordner verschoben haben, entpacken Sie sie. Sie werden eine Reihe von Dateien darin sehen.
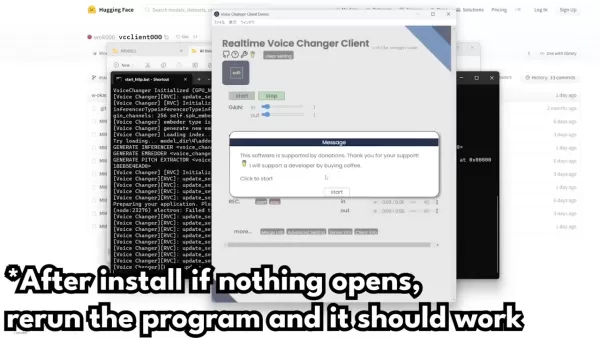
- Programm starten: Die Hauptdatei, auf die Sie sich konzentrieren müssen, befindet sich unten und heißt "start_http.bat." Doppelklicken Sie darauf, um das Programm zu starten, und Sie müssen diesen Ordner nicht erneut öffnen, es sei denn, Sie beheben Fehler.
- Eingabeaufforderungen starten: Wenn Sie auf "start_http.bat" doppelt klicken, öffnet sich eine Eingabeaufforderung. Lassen Sie sie laden; es kann anfangs langsam sein.
- App-Fenster öffnen: Je nach Ihrer Python-Konfiguration kann die Installation etwas dauern. Wenn Windows versucht, es zu blockieren, klicken Sie auf "Weitere Informationen" und dann auf "Trotzdem ausführen." Sie müssen auch den Zugriff durch Ihre Firewall erlauben, wenn Sie dazu aufgefordert werden.
- Was tun, wenn die App nicht öffnet: Wenn Probleme auftreten, denken Sie daran, dass die Software Pytorch verwendet. Möglicherweise müssen Sie Tutorials zur Installation von Pytorch nachschlagen. Wenn die App nicht öffnet, führen Sie sie erneut aus, um es noch einmal zu versuchen.
Die Software konfigurieren
Grundlagen der Benutzeroberfläche:
Sobald Sie im eigentlichen Stimmenveränderer sind, sehen Sie Folgendes:
- Integrierte Stimmen: Die vier Stimmen oben sind die vorinstallierten Startoptionen.
- Bereits importierte Stimmen: Dies sind drei Stimmen, die ich bereits installiert habe. Ich werde Sie durch das Hinzufügen einer vierten Stimme führen, während wir die Einstellungen durchgehen.
Modelleinstellung: Wenn das Modell, das Sie haben, mit der Software funktioniert, super! Wenn nicht, müssen Sie die Einstellungen möglicherweise etwas anpassen. 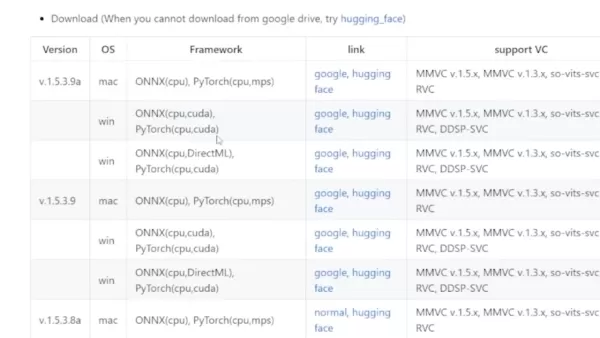
Die japanischen Modelle klingen oft besser auf Japanisch als auf Englisch, aber normalerweise funktioniert Englisch am besten. Um einen einzelnen Charakter richtig einzurichten, folgen Sie diesen Schritten:
Schritt-für-Schritt-Anleitung zur Feinabstimmung:
- Einstellungen überprüfen: Stellen Sie sicher, dass Ihre Ein- und Ausgabe auf die Standardeinstellungen gesetzt sind. Die Eingabe sollte Ihr Mikrofon sein, und die Ausgabe sollte Ihre Standard-Kopfhörer- oder Lautsprechereinstellung sein.
- Audioausgabe: Diese Einstellung bestimmt, wie viele Sekunden der Ton ausgegeben wird. Wir werden die restlichen Grundeinstellungen später behandeln. Lassen Sie vorerst alles andere unverändert und sehen Sie, wie es klingt.
- Fehlerbehebung: Sie werden möglicherweise feststellen, dass es ein paar Sekunden dauert, bis es startet. Ein Wechsel von Harvest zu Crepe kann den Klang verbessern und den Abschnitt weniger hart machen.
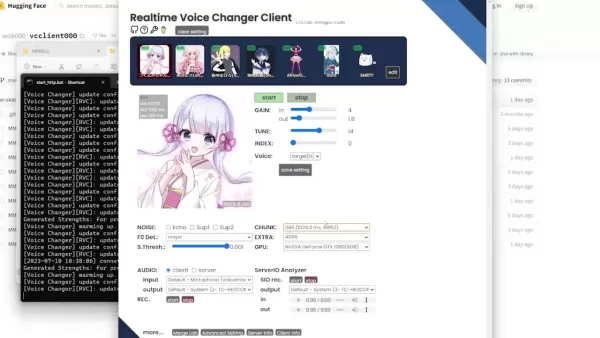
- Die abgehackte Stimme: Um abgehackte oder schlecht klingende Stimmen zu vermeiden, passen Sie Ihre Lautstärke an. Wenn das Problem weiterhin besteht, verwenden Sie Ihre Grafikeinstellungen, um das Spiel flüssiger laufen zu lassen.
Einstellung Beschreibung Verstärkung Passt die Eingangs- und Ausgangslautstärke der Stimme an Abstimmung Verändert die Tonhöhe, um besser zu individuellen Stimmen zu passen Index Versucht, die Stimme mit einer Person oder einem Individuum abzugleichen
Denken Sie daran, wenn Sie Ihre GPU-Einstellungen nicht überprüft haben, stellen Sie sicher, dass Sie Ihre GPU anstelle Ihrer CPU auswählen, um eine schnellere Leistung zu erzielen.
Verwandter Artikel
 Artifism Überprüfung: KI-gesteuerter Inhalts- & Bildgenerator SaaS Script
Im heutigen inhaltsgesteuerten digitalen Ökosystem stellt die konsistente Erstellung von qualitativ hochwertigem Material sowohl für Kreative als auch für Vermarkter eine große Herausforderung dar. Da
Google AI Ultra enthüllt: Premium-Abonnement für $249,99 pro Monat
Google stellt Premium AI Ultra-Abonnement vorAuf der Google I/O 2025 kündigte der Tech-Gigant seinen neuen umfassenden KI-Abonnementdienst an - Google AI Ultra. Zum Preis von 249,99 $ monatlich bietet
KI-generiertes Crossover vereint Arthur Morgan und Joshua Graham im Gaming-Multiversum
Wenn Spielwelten aufeinanderprallen: Arthur Morgan trifft auf den verbrannten MannStellen Sie sich eine Welt vor, in der legendäre Spielcharaktere über ihre eigenen Geschichten hinausgehen - was passi
Kommentare (2)
0/200
Artifism Überprüfung: KI-gesteuerter Inhalts- & Bildgenerator SaaS Script
Im heutigen inhaltsgesteuerten digitalen Ökosystem stellt die konsistente Erstellung von qualitativ hochwertigem Material sowohl für Kreative als auch für Vermarkter eine große Herausforderung dar. Da
Google AI Ultra enthüllt: Premium-Abonnement für $249,99 pro Monat
Google stellt Premium AI Ultra-Abonnement vorAuf der Google I/O 2025 kündigte der Tech-Gigant seinen neuen umfassenden KI-Abonnementdienst an - Google AI Ultra. Zum Preis von 249,99 $ monatlich bietet
KI-generiertes Crossover vereint Arthur Morgan und Joshua Graham im Gaming-Multiversum
Wenn Spielwelten aufeinanderprallen: Arthur Morgan trifft auf den verbrannten MannStellen Sie sich eine Welt vor, in der legendäre Spielcharaktere über ihre eigenen Geschichten hinausgehen - was passi
Kommentare (2)
0/200
![RyanGonzalez]() RyanGonzalez
RyanGonzalez
 27. August 2025 10:26:22 MESZ
27. August 2025 10:26:22 MESZ
This AI voice changer sounds like a game-changer for streamers! I can’t wait to troll my friends in Discord as a celebrity voice. 😎 But, is it easy to use or just overhyped tech?


 0
0
![FredWhite]() FredWhite
24. August 2025 13:01:16 MESZ
FredWhite
24. August 2025 13:01:16 MESZ
This AI voice changer sounds like a game-changer for streamers! Imagine trolling in games with a celebrity voice—hilarious! But, is it too good to be true? 🤔 Worried about misuse in scams or deepfakes.
0
Haben Sie sich jemals gefragt, wie es wäre, wie Ihr Lieblings-YouTuber, eine Anime-Figur oder sogar ein Promi zu klingen? Mit AI-Stimmenveränderer-Software können Sie Ihre Stimme in Echtzeit verändern und eröffnen damit eine Welt voller Möglichkeiten für Content-Erstellung, Gaming und Online-Interaktionen. In diesem Blog tauchen wir ein in die Möglichkeiten, wie Sie die Kraft der AI nutzen können, um Ihre Stimme in etwas völlig Neues und Aufregendes zu verwandeln.
Wichtige Punkte
- AI-Stimmenveränderer-Software ermöglicht die Stimmenveränderung in Echtzeit.
- Tools wie W-Okada's Voice Changer bieten eine Vielzahl von Stimmenmodellen zur Auswahl.
- Sie können Stimmenmodelle von Plattformen wie Hugging Face herunterladen.
- Ein virtuelles Audiokabel kann helfen, den AI-Stimmenveränderer mit anderen Anwendungen wie Discord zu integrieren.
- Experimentieren und Feinabstimmung sind entscheidend, um die perfekten Einstellungen und Modelle für Ihre einzigartige Stimme zu finden.
Erste Schritte mit AI-Stimmenveränderern
Was ist ein AI-Stimmenveränderer?
Ein AI-Stimmenveränderer ist ein Software-Tool, das künstliche Intelligenz nutzt, um die Eigenschaften Ihrer Stimme in Echtzeit oder nahezu in Echtzeit zu verändern. Es kann Tonhöhe, Klang und Klangfarbe ändern, um eine andere Person nachzuahmen oder eine völlig neue stimmliche Identität zu schaffen. Diese Tools nutzen fortschrittliche maschinelle Lerntechniken wie Voice Cloning und Deep Learning, um Audiosignale zu analysieren und zu manipulieren. Mit dem Aufstieg von Online-Stimmenveränderer-Apps wächst ihre Popularität rasant.
AI-Stimmenveränderer sind unglaublich vielseitig. Gamer nutzen sie für Anonymität oder um Charaktere zu spielen, Content-Creator verwenden sie für Voice-Overs und Erzählungen, und Musiker experimentieren mit einzigartigen Stimmeneffekten. Mit der Weiterentwicklung der Technologie sind die potenziellen Anwendungen grenzenlos.
Beliebter AI-Stimmenveränderer: W-Okada's Voice Changer
W-Okada's Voice Changer ist ein leistungsstarkes Tool, mit dem Sie Ihre Stimme mithilfe von AI verändern können. Es ist kompatibel mit Windows, Mac und Linux. Lassen Sie uns durchgehen, wie Sie mit dieser Software starten können.
W-Okada's Voice Changer herunterladen
- Zugang zum Download-Link: Besuchen Sie die GitHub-Seite von W-Okada und scrollen Sie nach unten, um den Download-Link zu finden. Sie finden ihn in der Beschreibung unten, klicken Sie einfach darauf – es ist der oberste Link.
- Die richtige Version auswählen: Scrollen Sie zur Tabelle am Ende. Wenn Sie eine dedizierte Grafikkarte haben, wählen Sie die Windows CUDA-Version. Es gibt auch eine Mac-Version.
- Umgang mit Download-Problemen: Diese Software ist beliebt, daher müssen Sie sie möglicherweise von Hugging Face oder Google Drive herunterladen. Es ist nur eine Zip-Datei, also keine Sorge.
Nachdem Sie die Datei heruntergeladen haben, entpacken Sie sie in einen speziellen Ordner auf Ihrem Computer. Eine geordnete Struktur erleichtert den Prozess.
Software herunterladen: Es ist eine große Datei, und da ich sie bereits installiert habe, breche ich meinen Download ab. Aber Sie sollten den Download abschließen lassen – es ist sicher, versprochen.
Stimmenmodelle herunterladen und konfigurieren
Der wahre Spaß beginnt mit der Vielfalt an Stimmenmodellen, die Sie verwenden können. So richten Sie sie ein:
- Erstellen der benötigten Ordner: Während die Zip-Datei herunterlädt, erstellen Sie einen neuen Ordner, um alle Ihre AI-Stimmenveränderer-Dateien zu speichern. Sobald der Download abgeschlossen ist, verschieben Sie die Zip-Datei in diesen Ordner und erstellen Sie einen weiteren Ordner namens "models."
- Woher Sie diese Stimmenmodelle bekommen: Sie benötigen Stimmenmodelle, damit dies funktioniert. Wir zeigen Ihnen, wie Sie sie herunterladen, sobald das Programm läuft. Das Tutorial empfiehlt die Nutzung eines Discord-Servers dafür.
- Was nach dem Erstellen aller Ordner zu tun ist: Nachdem Sie die Zip-Datei in Ihren neuen Ordner verschoben haben, entpacken Sie sie. Sie werden eine Reihe von Dateien darin sehen.
- Programm starten: Die Hauptdatei, auf die Sie sich konzentrieren müssen, befindet sich unten und heißt "start_http.bat." Doppelklicken Sie darauf, um das Programm zu starten, und Sie müssen diesen Ordner nicht erneut öffnen, es sei denn, Sie beheben Fehler.
- Eingabeaufforderungen starten: Wenn Sie auf "start_http.bat" doppelt klicken, öffnet sich eine Eingabeaufforderung. Lassen Sie sie laden; es kann anfangs langsam sein.
- App-Fenster öffnen: Je nach Ihrer Python-Konfiguration kann die Installation etwas dauern. Wenn Windows versucht, es zu blockieren, klicken Sie auf "Weitere Informationen" und dann auf "Trotzdem ausführen." Sie müssen auch den Zugriff durch Ihre Firewall erlauben, wenn Sie dazu aufgefordert werden.
- Was tun, wenn die App nicht öffnet: Wenn Probleme auftreten, denken Sie daran, dass die Software Pytorch verwendet. Möglicherweise müssen Sie Tutorials zur Installation von Pytorch nachschlagen. Wenn die App nicht öffnet, führen Sie sie erneut aus, um es noch einmal zu versuchen.
Die Software konfigurieren
Grundlagen der Benutzeroberfläche:
Sobald Sie im eigentlichen Stimmenveränderer sind, sehen Sie Folgendes:
- Integrierte Stimmen: Die vier Stimmen oben sind die vorinstallierten Startoptionen.
- Bereits importierte Stimmen: Dies sind drei Stimmen, die ich bereits installiert habe. Ich werde Sie durch das Hinzufügen einer vierten Stimme führen, während wir die Einstellungen durchgehen.
Modelleinstellung: Wenn das Modell, das Sie haben, mit der Software funktioniert, super! Wenn nicht, müssen Sie die Einstellungen möglicherweise etwas anpassen.
Die japanischen Modelle klingen oft besser auf Japanisch als auf Englisch, aber normalerweise funktioniert Englisch am besten. Um einen einzelnen Charakter richtig einzurichten, folgen Sie diesen Schritten:
Schritt-für-Schritt-Anleitung zur Feinabstimmung:
- Einstellungen überprüfen: Stellen Sie sicher, dass Ihre Ein- und Ausgabe auf die Standardeinstellungen gesetzt sind. Die Eingabe sollte Ihr Mikrofon sein, und die Ausgabe sollte Ihre Standard-Kopfhörer- oder Lautsprechereinstellung sein.
- Audioausgabe: Diese Einstellung bestimmt, wie viele Sekunden der Ton ausgegeben wird. Wir werden die restlichen Grundeinstellungen später behandeln. Lassen Sie vorerst alles andere unverändert und sehen Sie, wie es klingt.
- Fehlerbehebung: Sie werden möglicherweise feststellen, dass es ein paar Sekunden dauert, bis es startet. Ein Wechsel von Harvest zu Crepe kann den Klang verbessern und den Abschnitt weniger hart machen.
- Die abgehackte Stimme: Um abgehackte oder schlecht klingende Stimmen zu vermeiden, passen Sie Ihre Lautstärke an. Wenn das Problem weiterhin besteht, verwenden Sie Ihre Grafikeinstellungen, um das Spiel flüssiger laufen zu lassen.
| Einstellung | Beschreibung |
|---|---|
| Verstärkung | Passt die Eingangs- und Ausgangslautstärke der Stimme an |
| Abstimmung | Verändert die Tonhöhe, um besser zu individuellen Stimmen zu passen |
| Index | Versucht, die Stimme mit einer Person oder einem Individuum abzugleichen |
Denken Sie daran, wenn Sie Ihre GPU-Einstellungen nicht überprüft haben, stellen Sie sicher, dass Sie Ihre GPU anstelle Ihrer CPU auswählen, um eine schnellere Leistung zu erzielen.










 Artifism Überprüfung: KI-gesteuerter Inhalts- & Bildgenerator SaaS Script
Im heutigen inhaltsgesteuerten digitalen Ökosystem stellt die konsistente Erstellung von qualitativ hochwertigem Material sowohl für Kreative als auch für Vermarkter eine große Herausforderung dar. Da
Artifism Überprüfung: KI-gesteuerter Inhalts- & Bildgenerator SaaS Script
Im heutigen inhaltsgesteuerten digitalen Ökosystem stellt die konsistente Erstellung von qualitativ hochwertigem Material sowohl für Kreative als auch für Vermarkter eine große Herausforderung dar. Da
 Google AI Ultra enthüllt: Premium-Abonnement für $249,99 pro Monat
Google stellt Premium AI Ultra-Abonnement vorAuf der Google I/O 2025 kündigte der Tech-Gigant seinen neuen umfassenden KI-Abonnementdienst an - Google AI Ultra. Zum Preis von 249,99 $ monatlich bietet
Google AI Ultra enthüllt: Premium-Abonnement für $249,99 pro Monat
Google stellt Premium AI Ultra-Abonnement vorAuf der Google I/O 2025 kündigte der Tech-Gigant seinen neuen umfassenden KI-Abonnementdienst an - Google AI Ultra. Zum Preis von 249,99 $ monatlich bietet
 KI-generiertes Crossover vereint Arthur Morgan und Joshua Graham im Gaming-Multiversum
Wenn Spielwelten aufeinanderprallen: Arthur Morgan trifft auf den verbrannten MannStellen Sie sich eine Welt vor, in der legendäre Spielcharaktere über ihre eigenen Geschichten hinausgehen - was passi
27. August 2025 10:26:22 MESZ
KI-generiertes Crossover vereint Arthur Morgan und Joshua Graham im Gaming-Multiversum
Wenn Spielwelten aufeinanderprallen: Arthur Morgan trifft auf den verbrannten MannStellen Sie sich eine Welt vor, in der legendäre Spielcharaktere über ihre eigenen Geschichten hinausgehen - was passi
27. August 2025 10:26:22 MESZ
This AI voice changer sounds like a game-changer for streamers! I can’t wait to troll my friends in Discord as a celebrity voice. 😎 But, is it easy to use or just overhyped tech?
0
24. August 2025 13:01:16 MESZ
This AI voice changer sounds like a game-changer for streamers! Imagine trolling in games with a celebrity voice—hilarious! But, is it too good to be true? 🤔 Worried about misuse in scams or deepfakes.
0













