
















 首页
首页AI变声器:实时改变你的声音
想知道用你最喜欢的YouTuber、动漫角色,甚至是名人的声音说话会是什么感觉吗?通过AI语音转换软件,你可以实时改变你的声音,为内容创作、游戏和在线互动开启无限可能。在这篇博客中,我们将深入探讨如何利用AI的力量将你的声音变成全新的、令人兴奋的声音。
关键要点
- AI语音转换软件支持实时语音转换。
- 像W-Okada的语音转换器这样的工具提供了多种语音模型供选择。
- 你可以从Hugging Face等平台下载语音模型。
- 虚拟音频线缆可以帮助将AI语音转换器与其他应用程序(如Discord)整合。
- 实验和微调是找到适合你独特声音的完美设置和模型的关键。
AI语音转换器入门
什么是AI语音转换器?
AI语音转换器是一种利用人工智能实时或近实时修改声音特征的软件工具。它可以改变音高、音调和音色,以模仿他人或创建全新的声音身份。这些工具利用先进的机器学习技术,如语音克隆和深度学习,来分析和处理音频信号。随着在线语音转换应用程序的兴起,它们的受欢迎程度正在飙升。

AI语音转换器用途广泛。游戏玩家用它们来保持匿名或扮演角色,内容创作者用它们进行配音和叙述,音乐家则用它们尝试独特的声音效果。随着技术的不断发展,潜在应用无穷无尽。
热门AI语音转换器:W-Okada的语音转换器
W-Okada的语音转换器是一款强大的工具,让你可以通过AI改变你的声音。它兼容Windows、Mac和Linux。下面我们来逐步了解如何开始使用这款软件。
下载W-Okada的语音转换器
- 访问下载链接:前往W-Okada的GitHub页面,向下滚动找到下载链接。你可以在下面的描述中找到它,点击即可——它是第一个链接。
- 选择正确的版本:滚动到页面底部的表格。如果你有独立显卡,选择Windows CUDA版本。也有Mac版本可用。
- 处理下载问题:这款软件很受欢迎,因此你可能需要从Hugging Face或Google Drive下载。它只是一个压缩文件,不用担心。
下载完成后,将文件解压到一个专门的文件夹中。保持文件整齐会让流程更顺畅。
下载软件:这是一个大文件,因为我已经安装了它,我会取消我的下载。但你需要让它下载完成——它很安全,我保证。
下载和配置语音模型
真正的乐趣从你可以使用的各种语音模型开始。以下是如何设置它们:
- 创建所需文件夹:在下载压缩文件时,创建一个新文件夹来存放所有AI语音转换器文件。下载完成后,将压缩文件移到这个文件夹中,并创建另一个名为“models”的文件夹。
- 从哪里获取这些语音模型:你需要语音模型才能使用。我们将在程序运行后展示如何下载它们。教程建议使用Discord服务器来获取。
- 创建所有文件夹后做什么:将压缩文件放入新文件夹后,解压它。你会看到里面有很多文件。
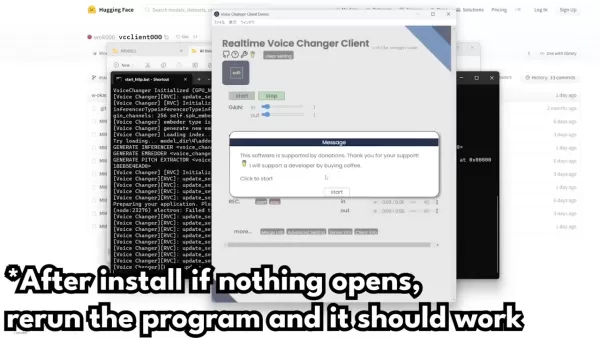
- 启动程序:你需要关注的主要文件在底部,名为“start_http.bat”。双击它即可启动程序,除非需要排错,否则无需再次进入该文件夹。
- 启动命令提示符:双击“start_http.bat”时,会打开一个命令提示符。让它加载,第一次可能较慢。
- 打开应用程序窗口:根据你的Python设置,可能需要一段时间安装所有内容。如果Windows尝试阻止,点击“更多信息”,然后选择“仍然运行”。出现提示时,还需允许通过防火墙访问。
- 如果应用程序无法打开怎么办:如果遇到问题,请记住该软件使用Pytorch。你可能需要查找如何安装Pytorch的教程。如果应用程序未打开,重新运行即可。
配置软件
界面基础:
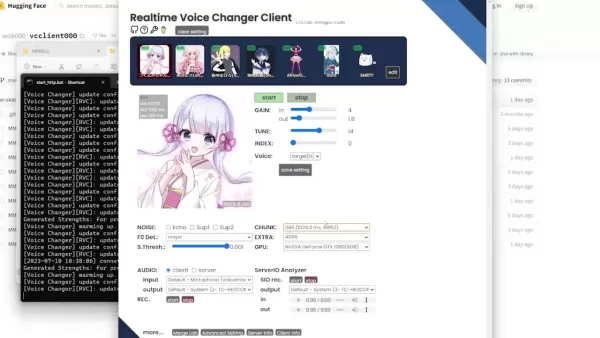
一旦进入实际的语音转换器,你会看到以下内容:
- 内置语音:顶部四个语音是预装的起始选项。
- 已导入的语音:这是我已经安装的三个语音。我将指导你逐步添加第四个语音。
模型设置:如果你的模型与软件兼容,太好了!如果不兼容,可能需要稍作调整。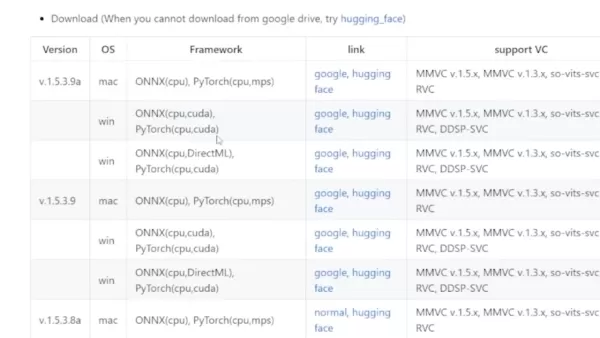
日语模型通常用日语听起来比英语好,但通常英语效果最佳。要正确设置单个角色,请按照以下步骤操作:
逐步调优指南:
- 检查设置:确保输入和输出设置为默认设置。输入应为你的麦克风,输出应为默认耳机或扬声器设置。
- 音频输出:此设置决定音频输出的秒数。我们稍后会介绍其他基本设置。现在保持其他设置不变,看看效果如何。
- 故障排除:你可能注意到启动需要几秒钟。从Harvest切换到Crepe可以改善声音,使切断不那么突兀。
- 断续的声音:为避免声音断续或效果不佳,调整音量。如果问题依然存在,使用显卡设置让程序运行更顺畅。
设置 描述 Gain 调整语音的输入和输出音量 Tune 修改音高以更好地适应个体声音 Index 尝试将语音与某人或个体匹配
记住,如果尚未检查GPU设置,请确保选择GPU而非CPU以获得更快性能。
相关文章
 海尔推出全球最轻的人工智能运动外骨骼机器人,重量仅为1.75公斤
海尔集团推出了全球最轻的运动型人工智能外骨骼机器人——海尔外骨骼机器人W3。此次发布创下了行业轻量化新纪录,标志着在轻量化设计和智能人体运动增强领域取得了重大突破。高端材料成就超轻量化设计W3采用创新的一体化制造工艺,融合全碳纤维与钛合金。这种航空级材料组合将总重量控制在仅1.75公斤,实现了轻量化与高强度的完美平衡,展现出极致的机械性能。为提升舒适度,该机器人融入了非牛顿流体材料,触感柔软亲肤,
耀科传媒首部AIGC剧集《秦岭青铜之谜》今日上线,主演均由AI生成
今日,耀科传媒的AIGC奇幻悬疑短剧《秦岭青铜秘闻》正式上线。该剧由公司签约的首批两位AI演员秦凌月和林西妍主演,故事背景设定在神秘的秦岭矿区。 剧中,退役情报官秦月率队深入该区域,揭开了一起尘封已久的矿难真相,以及跨越两代人的血祭之谜——这个真相就隐藏在受限的地下区域,那里是科学探索与古代巫术交汇之地。作为中国最早完全由AI数字人支撑的影视作品之一,该剧在筹备阶段便引发了业界热烈讨论,而关于其A
萨提亚·纳德拉准备利用与OpenAI的新合作关系
周三,一位华尔街分析师直接询问了微软首席执行官萨蒂亚·纳德拉,修订后的OpenAI合作关系将如何影响公司的财务状况。 纳德拉将这一新协议描述为对各方都有利的结果。“我们对与OpenAI的合作感到满意。我始终非常重视任何合作关系,并确保它能够实现双赢。只有这样,双方才能保持良好的合作伙伴关系。” 他强调,微软仍然可以使用OpenAI的知识产权,包括其模型和智能体产品,但不再需要为此向OpenAI支付费用。 谈到在2032年之前可以免费使用OpenAI最先进的人工智能技术,纳德拉表示:“
相关专题推荐
商业
海尔推出全球最轻的人工智能运动外骨骼机器人,重量仅为1.75公斤
海尔集团推出了全球最轻的运动型人工智能外骨骼机器人——海尔外骨骼机器人W3。此次发布创下了行业轻量化新纪录,标志着在轻量化设计和智能人体运动增强领域取得了重大突破。高端材料成就超轻量化设计W3采用创新的一体化制造工艺,融合全碳纤维与钛合金。这种航空级材料组合将总重量控制在仅1.75公斤,实现了轻量化与高强度的完美平衡,展现出极致的机械性能。为提升舒适度,该机器人融入了非牛顿流体材料,触感柔软亲肤,
耀科传媒首部AIGC剧集《秦岭青铜之谜》今日上线,主演均由AI生成
今日,耀科传媒的AIGC奇幻悬疑短剧《秦岭青铜秘闻》正式上线。该剧由公司签约的首批两位AI演员秦凌月和林西妍主演,故事背景设定在神秘的秦岭矿区。 剧中,退役情报官秦月率队深入该区域,揭开了一起尘封已久的矿难真相,以及跨越两代人的血祭之谜——这个真相就隐藏在受限的地下区域,那里是科学探索与古代巫术交汇之地。作为中国最早完全由AI数字人支撑的影视作品之一,该剧在筹备阶段便引发了业界热烈讨论,而关于其A
萨提亚·纳德拉准备利用与OpenAI的新合作关系
周三,一位华尔街分析师直接询问了微软首席执行官萨蒂亚·纳德拉,修订后的OpenAI合作关系将如何影响公司的财务状况。 纳德拉将这一新协议描述为对各方都有利的结果。“我们对与OpenAI的合作感到满意。我始终非常重视任何合作关系,并确保它能够实现双赢。只有这样,双方才能保持良好的合作伙伴关系。” 他强调,微软仍然可以使用OpenAI的知识产权,包括其模型和智能体产品,但不再需要为此向OpenAI支付费用。 谈到在2032年之前可以免费使用OpenAI最先进的人工智能技术,纳德拉表示:“
相关专题推荐
商业
 最佳 AI 费用追踪工具:扫描收据并自动分类企业开支
最佳 AI 费用追踪工具:扫描收据并自动分类企业开支
2026年最新最佳AI报销管理工具:广受好评的解决方案,可自动扫描收据并分类企业支出。探索这些功能强大、颠覆传统的解决方案,助您轻松管理报销、精准追踪财务并简化合规流程。我们精心整理并每周更新的免费与付费选项对比指南,助您找到最适合的工具。通过XIX.AI的专家精选,释放您的AI优势。
 10 个工具
10 个工具
 xix.ai
商业
最佳人工智能招聘工具:筛选简历并自动安排候选人面试
xix.ai
商业
最佳人工智能招聘工具:筛选简历并自动安排候选人面试
在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
10 个工具
xix.ai
生产率
AI个人健康与专注力教练:缓解倦怠,提升精神能量
立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai
聊天机器人
备受好评的AI浪漫聊天机器人:凭借稳定的个性建立长期关系
探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai
教育与学习
最佳AI数据科学导师:精通SQL、Pandas及机器学习工作流程
探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai
聊天机器人
最佳AI调情与对话训练工具:实时提升社交魅力与自信
在 XIX.AI 上探索 2026 年最优秀的 AI 调情与对话训练工具。我们精心挑选的高评分工具助您实时提升社交魅力与自信。探索这些必试的、颠覆性的工具,查看免费版与付费版的对比,并了解每周更新的排行榜。立即开启您的社交优势。
10 个工具
xix.ai

 评论 (4)
0/500
评论 (4)
0/500
![DavidMartínez]()
這技術太酷了吧!實時變聲讓直播和遊戲互動多了好多樂趣,不過要是被濫用來冒充他人就麻煩了... 大家覺得該怎麼防範這種風險呢?🤔
![KennethRoberts]()
Unglaublich, wie weit diese Technik schon ist! Aber mal ehrlich, gibt es nicht auch ein großes Missbrauchspotenzial? Stell dir vor, jemand imitiert die Stimme eines Politikers... 🧐
![RyanGonzalez]()
This AI voice changer sounds like a game-changer for streamers! I can’t wait to troll my friends in Discord as a celebrity voice. 😎 But, is it easy to use or just overhyped tech?
![FredWhite]()
This AI voice changer sounds like a game-changer for streamers! Imagine trolling in games with a celebrity voice—hilarious! But, is it too good to be true? 🤔 Worried about misuse in scams or deepfakes.
想知道用你最喜欢的YouTuber、动漫角色,甚至是名人的声音说话会是什么感觉吗?通过AI语音转换软件,你可以实时改变你的声音,为内容创作、游戏和在线互动开启无限可能。在这篇博客中,我们将深入探讨如何利用AI的力量将你的声音变成全新的、令人兴奋的声音。
关键要点
- AI语音转换软件支持实时语音转换。
- 像W-Okada的语音转换器这样的工具提供了多种语音模型供选择。
- 你可以从Hugging Face等平台下载语音模型。
- 虚拟音频线缆可以帮助将AI语音转换器与其他应用程序(如Discord)整合。
- 实验和微调是找到适合你独特声音的完美设置和模型的关键。
AI语音转换器入门
什么是AI语音转换器?
AI语音转换器是一种利用人工智能实时或近实时修改声音特征的软件工具。它可以改变音高、音调和音色,以模仿他人或创建全新的声音身份。这些工具利用先进的机器学习技术,如语音克隆和深度学习,来分析和处理音频信号。随着在线语音转换应用程序的兴起,它们的受欢迎程度正在飙升。
AI语音转换器用途广泛。游戏玩家用它们来保持匿名或扮演角色,内容创作者用它们进行配音和叙述,音乐家则用它们尝试独特的声音效果。随着技术的不断发展,潜在应用无穷无尽。
热门AI语音转换器:W-Okada的语音转换器
W-Okada的语音转换器是一款强大的工具,让你可以通过AI改变你的声音。它兼容Windows、Mac和Linux。下面我们来逐步了解如何开始使用这款软件。
下载W-Okada的语音转换器
- 访问下载链接:前往W-Okada的GitHub页面,向下滚动找到下载链接。你可以在下面的描述中找到它,点击即可——它是第一个链接。
- 选择正确的版本:滚动到页面底部的表格。如果你有独立显卡,选择Windows CUDA版本。也有Mac版本可用。
- 处理下载问题:这款软件很受欢迎,因此你可能需要从Hugging Face或Google Drive下载。它只是一个压缩文件,不用担心。
下载完成后,将文件解压到一个专门的文件夹中。保持文件整齐会让流程更顺畅。
下载软件:这是一个大文件,因为我已经安装了它,我会取消我的下载。但你需要让它下载完成——它很安全,我保证。
下载和配置语音模型
真正的乐趣从你可以使用的各种语音模型开始。以下是如何设置它们:
- 创建所需文件夹:在下载压缩文件时,创建一个新文件夹来存放所有AI语音转换器文件。下载完成后,将压缩文件移到这个文件夹中,并创建另一个名为“models”的文件夹。
- 从哪里获取这些语音模型:你需要语音模型才能使用。我们将在程序运行后展示如何下载它们。教程建议使用Discord服务器来获取。
- 创建所有文件夹后做什么:将压缩文件放入新文件夹后,解压它。你会看到里面有很多文件。
- 启动程序:你需要关注的主要文件在底部,名为“start_http.bat”。双击它即可启动程序,除非需要排错,否则无需再次进入该文件夹。
- 启动命令提示符:双击“start_http.bat”时,会打开一个命令提示符。让它加载,第一次可能较慢。
- 打开应用程序窗口:根据你的Python设置,可能需要一段时间安装所有内容。如果Windows尝试阻止,点击“更多信息”,然后选择“仍然运行”。出现提示时,还需允许通过防火墙访问。
- 如果应用程序无法打开怎么办:如果遇到问题,请记住该软件使用Pytorch。你可能需要查找如何安装Pytorch的教程。如果应用程序未打开,重新运行即可。
配置软件
界面基础:
一旦进入实际的语音转换器,你会看到以下内容:
- 内置语音:顶部四个语音是预装的起始选项。
- 已导入的语音:这是我已经安装的三个语音。我将指导你逐步添加第四个语音。
模型设置:如果你的模型与软件兼容,太好了!如果不兼容,可能需要稍作调整。
日语模型通常用日语听起来比英语好,但通常英语效果最佳。要正确设置单个角色,请按照以下步骤操作:
逐步调优指南:
- 检查设置:确保输入和输出设置为默认设置。输入应为你的麦克风,输出应为默认耳机或扬声器设置。
- 音频输出:此设置决定音频输出的秒数。我们稍后会介绍其他基本设置。现在保持其他设置不变,看看效果如何。
- 故障排除:你可能注意到启动需要几秒钟。从Harvest切换到Crepe可以改善声音,使切断不那么突兀。
- 断续的声音:为避免声音断续或效果不佳,调整音量。如果问题依然存在,使用显卡设置让程序运行更顺畅。
| 设置 | 描述 |
|---|---|
| Gain | 调整语音的输入和输出音量 |
| Tune | 修改音高以更好地适应个体声音 |
| Index | 尝试将语音与某人或个体匹配 |
记住,如果尚未检查GPU设置,请确保选择GPU而非CPU以获得更快性能。










 海尔推出全球最轻的人工智能运动外骨骼机器人,重量仅为1.75公斤
海尔集团推出了全球最轻的运动型人工智能外骨骼机器人——海尔外骨骼机器人W3。此次发布创下了行业轻量化新纪录,标志着在轻量化设计和智能人体运动增强领域取得了重大突破。高端材料成就超轻量化设计W3采用创新的一体化制造工艺,融合全碳纤维与钛合金。这种航空级材料组合将总重量控制在仅1.75公斤,实现了轻量化与高强度的完美平衡,展现出极致的机械性能。为提升舒适度,该机器人融入了非牛顿流体材料,触感柔软亲肤,
海尔推出全球最轻的人工智能运动外骨骼机器人,重量仅为1.75公斤
海尔集团推出了全球最轻的运动型人工智能外骨骼机器人——海尔外骨骼机器人W3。此次发布创下了行业轻量化新纪录,标志着在轻量化设计和智能人体运动增强领域取得了重大突破。高端材料成就超轻量化设计W3采用创新的一体化制造工艺,融合全碳纤维与钛合金。这种航空级材料组合将总重量控制在仅1.75公斤,实现了轻量化与高强度的完美平衡,展现出极致的机械性能。为提升舒适度,该机器人融入了非牛顿流体材料,触感柔软亲肤,
 耀科传媒首部AIGC剧集《秦岭青铜之谜》今日上线,主演均由AI生成
今日,耀科传媒的AIGC奇幻悬疑短剧《秦岭青铜秘闻》正式上线。该剧由公司签约的首批两位AI演员秦凌月和林西妍主演,故事背景设定在神秘的秦岭矿区。 剧中,退役情报官秦月率队深入该区域,揭开了一起尘封已久的矿难真相,以及跨越两代人的血祭之谜——这个真相就隐藏在受限的地下区域,那里是科学探索与古代巫术交汇之地。作为中国最早完全由AI数字人支撑的影视作品之一,该剧在筹备阶段便引发了业界热烈讨论,而关于其A
耀科传媒首部AIGC剧集《秦岭青铜之谜》今日上线,主演均由AI生成
今日,耀科传媒的AIGC奇幻悬疑短剧《秦岭青铜秘闻》正式上线。该剧由公司签约的首批两位AI演员秦凌月和林西妍主演,故事背景设定在神秘的秦岭矿区。 剧中,退役情报官秦月率队深入该区域,揭开了一起尘封已久的矿难真相,以及跨越两代人的血祭之谜——这个真相就隐藏在受限的地下区域,那里是科学探索与古代巫术交汇之地。作为中国最早完全由AI数字人支撑的影视作品之一,该剧在筹备阶段便引发了业界热烈讨论,而关于其A
 萨提亚·纳德拉准备利用与OpenAI的新合作关系
周三,一位华尔街分析师直接询问了微软首席执行官萨蒂亚·纳德拉,修订后的OpenAI合作关系将如何影响公司的财务状况。 纳德拉将这一新协议描述为对各方都有利的结果。“我们对与OpenAI的合作感到满意。我始终非常重视任何合作关系,并确保它能够实现双赢。只有这样,双方才能保持良好的合作伙伴关系。” 他强调,微软仍然可以使用OpenAI的知识产权,包括其模型和智能体产品,但不再需要为此向OpenAI支付费用。 谈到在2032年之前可以免费使用OpenAI最先进的人工智能技术,纳德拉表示:“
萨提亚·纳德拉准备利用与OpenAI的新合作关系
周三,一位华尔街分析师直接询问了微软首席执行官萨蒂亚·纳德拉,修订后的OpenAI合作关系将如何影响公司的财务状况。 纳德拉将这一新协议描述为对各方都有利的结果。“我们对与OpenAI的合作感到满意。我始终非常重视任何合作关系,并确保它能够实现双赢。只有这样,双方才能保持良好的合作伙伴关系。” 他强调,微软仍然可以使用OpenAI的知识产权,包括其模型和智能体产品,但不再需要为此向OpenAI支付费用。 谈到在2032年之前可以免费使用OpenAI最先进的人工智能技术,纳德拉表示:“

2026年最新最佳AI报销管理工具:广受好评的解决方案,可自动扫描收据并分类企业支出。探索这些功能强大、颠覆传统的解决方案,助您轻松管理报销、精准追踪财务并简化合规流程。我们精心整理并每周更新的免费与付费选项对比指南,助您找到最适合的工具。通过XIX.AI的专家精选,释放您的AI优势。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
10 个工具
xix.ai

立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai

探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai

探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最优秀的 AI 调情与对话训练工具。我们精心挑选的高评分工具助您实时提升社交魅力与自信。探索这些必试的、颠覆性的工具,查看免费版与付费版的对比,并了解每周更新的排行榜。立即开启您的社交优势。
10 个工具
xix.ai

這技術太酷了吧!實時變聲讓直播和遊戲互動多了好多樂趣,不過要是被濫用來冒充他人就麻煩了... 大家覺得該怎麼防範這種風險呢?🤔
Unglaublich, wie weit diese Technik schon ist! Aber mal ehrlich, gibt es nicht auch ein großes Missbrauchspotenzial? Stell dir vor, jemand imitiert die Stimme eines Politikers... 🧐
This AI voice changer sounds like a game-changer for streamers! I can’t wait to troll my friends in Discord as a celebrity voice. 😎 But, is it easy to use or just overhyped tech?
This AI voice changer sounds like a game-changer for streamers! Imagine trolling in games with a celebrity voice—hilarious! But, is it too good to be true? 🤔 Worried about misuse in scams or deepfakes.













