




AIボイスチェンジャー:リアルタイムで音声変更
お気に入りのYouTuber、アニメキャラクター、または有名人のような声になるのはどんな感じか考えたことはありますか?AIボイスチェンジャーソフトウェアを使えば、リアルタイムで声を変換でき、コンテンツ作成、ゲーム、オンライン交流のための無限の可能性が広がります。このブログでは、AIの力を活用してあなたの声を全く新しくエキサイティングなものに変える方法を紹介します。
主なポイント
- AIボイスチェンジャーソフトウェアはリアルタイムの声変換を可能にします。
- W-OkadaのVoice Changerのようなツールは、さまざまなボイスモデルを提供します。
- Hugging Faceなどのプラットフォームからボイスモデルをダウンロードできます。
- 仮想オーディオケーブルを使用すると、AIボイスチェンジャーをDiscordなどの他のアプリケーションと統合できます。
- 実験と微調整が、独自の声に最適な設定とモデルを見つけるために重要です。
AIボイスチェンジャーの始め方
AIボイスチェンジャーとは?
AIボイスチェンジャーは、人工知能を使用してリアルタイムまたはほぼリアルタイムで声の特性を変更するソフトウェアツールです。ピッチ、トーン、音色を変更して他の人を模倣したり、完全に新しい声のアイデンティティを作成したりできます。これらのツールは、Voice Cloningや深層学習などの高度な機械学習技術を活用して音声信号を分析・操作します。オンラインボイスチェンジャーアプリの台頭により、その人気は急上昇しています。

AIボイスチェンジャーは非常に多用途です。ゲーマーは匿名性やキャラクターのロールプレイに使用し、コンテンツクリエイターはナレーションやボイスオーバーに、ミュージシャンはユニークなボーカルエフェクトの実験に使用します。技術が進化するにつれて、応用の可能性は無限です。
人気のAIボイスチェンジャー:W-OkadaのVoice Changer
W-OkadaのVoice Changerは、AIを使用して声を変換できる強力なツールです。Windows、Mac、Linuxに対応しています。このソフトウェアの始め方を説明します。
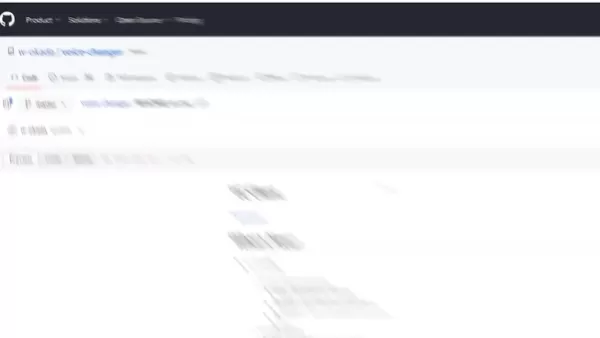
W-OkadaのVoice Changerのダウンロード
- ダウンロードリンクにアクセス: W-OkadaのGitHubページにアクセスし、ダウンロードリンクを探します。説明文の下にあり、トップリンクをクリックしてください。
- 正しいバージョンを選択: 下部の表を確認します。専用グラフィックカードがある場合は、Windows CUDAバージョンを選びます。Macバージョンもあります。
- ダウンロードの問題への対処: このソフトウェアは人気があるため、Hugging FaceやGoogle Driveからダウンロードする必要がある場合があります。zipファイルなので心配はいりません。
ファイルをダウンロードしたら、専用のフォルダに解凍します。整理しておくとプロセスがスムーズです。
ソフトウェアのダウンロード: ファイルは大きく、すでにインストール済みなので私はダウンロードをキャンセルしますが、完了まで待つことをおすすめします。安全です、約束します。
ボイスモデルのダウンロードと設定
さまざまなボイスモデルを使うのが本当の楽しみです。設定方法は以下の通りです:
- 必要なフォルダの作成: zipファイルのダウンロード中に、AIボイスチェンジャーのファイルをすべて保存する新しいフォルダを作成します。ダウンロードが完了したら、zipファイルをこのフォルダに移動し、「models」という名前の別のフォルダを作成します。
- ボイスモデルの入手先: ボイスモデルが必要です。プログラムが起動したら、ダウンロード方法を説明します。チュートリアルではDiscordサーバーの使用を推奨しています。
- すべてのフォルダを作成した後の手順: zipファイルを新しいフォルダに配置したら、解凍します。多くのファイルが表示されます。
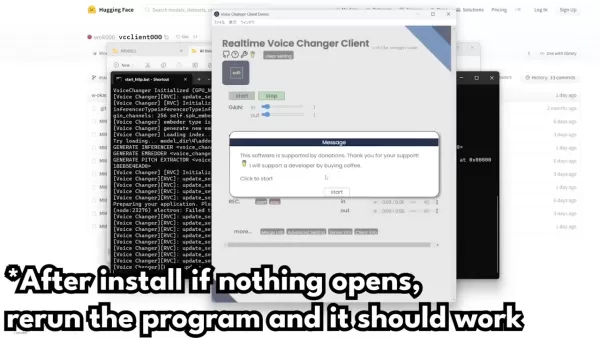
- プログラムの起動: 注目すべきメインファイルは下部にある「start_http.bat」です。ダブルクリックしてプログラムを起動すれば、トラブルシューティング以外でそのフォルダに戻る必要はありません。
- コマンドプロンプトの起動: 「start_http.bat」をダブルクリックすると、コマンドプロンプトが開きます。読み込みに時間がかかる場合があります。
- アプリウィンドウを開く: Pythonの設定によっては、すべてインストールするのに時間がかかる場合があります。Windowsがブロックしようとした場合、「詳細情報」をクリックし、「実行」を選択します。ファイアウォールでアクセスを許可するよう求められたら許可してください。
- アプリが開かない場合の対処法: 問題が発生した場合、ソフトウェアはPytorchを使用していることを覚えておいてください。Pytorchのインストール方法のチュートリアルを参照する必要があるかもしれません。アプリが開かない場合は、再度実行してみてください。
ソフトウェアの設定
インターフェースの基本:
実際のボイスチェンジャーに移ると、以下が見えます:
- 内蔵ボイス: 上部にある4つのボイスはプリロードされた初期オプションです。
- すでにインポート済みのボイス: すでにインストール済みの3つのボイスです。設定を進めながら4つ目を追加する方法をガイドします。
モデル設定: 使用しているモデルがソフトウェアと互換性があれば問題ありません。そうでない場合は、設定を少し調整する必要があるかもしれません。 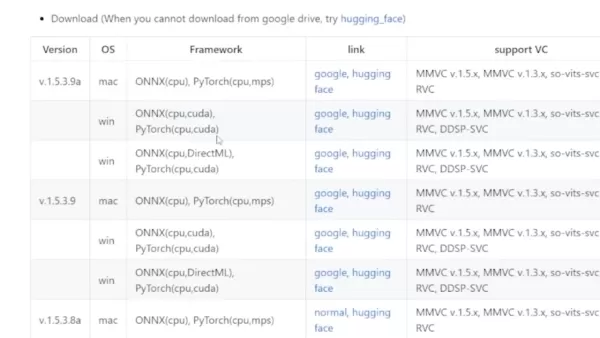
日本のモデルは英語よりも日本語での方が音質が良いことが多いですが、通常は英語が最適です。個々のキャラクターを適切に設定するには、以下の手順に従います:
ステップごとのチューニングガイド:
- 設定の確認: 入力と出力がデフォルト設定に設定されていることを確認します。入力はマイク、出力はデフォルトのヘッドフォンまたはスピーカー設定であるべきです。
- オーディオ出力: この設定はオーディオが何秒間出力されるかを決定します。その他の基本設定は後で説明します。今はすべてそのままにして、音を確認してください。
- トラブルシューティング: 起動に数秒かかることがあります。HarvestからCrepeに切り替えると、音質が向上し、途切れが少なくなります。
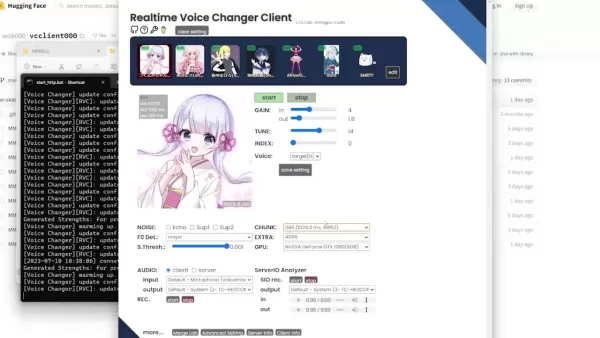
- 途切れがちなボイス: 途切れたり音質が悪いボイスを避けるために、音量を調整します。問題が続く場合は、グラフィック設定を使用してゲームをスムーズに実行してください。
設定 説明 Gain ボイスの入力および出力音量を調整 Tune 個々のボイスに合うようにピッチを変更 Index ボイスを特定の人や個々に一致させる試み
GPU設定を確認していない場合、パフォーマンスを向上させるためにCPUではなくGPUを選択してください。
関連記事
 AIの評価にはベンチマークを超えた実世界でのパフォーマンス評価が必要
AIの進歩を追跡していれば、間違いなく記録的なベンチマーク性能を発表する見出しに遭遇したことがあるだろう。コンピュータ・ビジョンのタスクから医療診断に至るまで、こうした標準化されたテストは長い間、AIの能力を測る決定的な尺度として機能してきた。しかし、このような印象的なスコアは、しばしば重大な制限を覆い隠してしまう。管理されたベンチマークでは優秀なモデルでも、実際のユースケースに導入されると劇的に
無神論者と信奉者のAIが道徳論争で激突
正反対の哲学的枠組みを持つ人工知能システムが倫理的な議論を交わしたとき、どのような洞察が生まれるのだろうか?この画期的な実験では、無神論者AIと信者AIの知的対決を演出し、神の存在に関する道徳的議論に焦点を当てた。読者は、洗練された哲学的言説に出会い、競合する論理的枠組みを分析し、15人の独立したAI裁判官が議論をどのように評価したかを観察する。単なる学問的演習にとどまらず、倫理システムの基礎と道
OpenAIがChatGPT Proをo3にアップグレード。
今週は、マイクロソフト、グーグル、Anthropicを含むハイテク大手から重要なAIの開発が目撃された。OpenAIは、コードネーム "io "と呼ばれる野心的なハードウェア構想のために、注目されたジョニー・アイブのデザイン会社を65億ドルで買収したことにとどまらず、独自の画期的なアップデートで発表の慌ただしさを締めくくった。同社は、ChatGPT内のOperator自律ウェブ・ナビゲーション・シ
コメント (2)
0/200
AIの評価にはベンチマークを超えた実世界でのパフォーマンス評価が必要
AIの進歩を追跡していれば、間違いなく記録的なベンチマーク性能を発表する見出しに遭遇したことがあるだろう。コンピュータ・ビジョンのタスクから医療診断に至るまで、こうした標準化されたテストは長い間、AIの能力を測る決定的な尺度として機能してきた。しかし、このような印象的なスコアは、しばしば重大な制限を覆い隠してしまう。管理されたベンチマークでは優秀なモデルでも、実際のユースケースに導入されると劇的に
無神論者と信奉者のAIが道徳論争で激突
正反対の哲学的枠組みを持つ人工知能システムが倫理的な議論を交わしたとき、どのような洞察が生まれるのだろうか?この画期的な実験では、無神論者AIと信者AIの知的対決を演出し、神の存在に関する道徳的議論に焦点を当てた。読者は、洗練された哲学的言説に出会い、競合する論理的枠組みを分析し、15人の独立したAI裁判官が議論をどのように評価したかを観察する。単なる学問的演習にとどまらず、倫理システムの基礎と道
OpenAIがChatGPT Proをo3にアップグレード。
今週は、マイクロソフト、グーグル、Anthropicを含むハイテク大手から重要なAIの開発が目撃された。OpenAIは、コードネーム "io "と呼ばれる野心的なハードウェア構想のために、注目されたジョニー・アイブのデザイン会社を65億ドルで買収したことにとどまらず、独自の画期的なアップデートで発表の慌ただしさを締めくくった。同社は、ChatGPT内のOperator自律ウェブ・ナビゲーション・シ
コメント (2)
0/200
![RyanGonzalez]() RyanGonzalez
RyanGonzalez
 2025年8月27日 17:26:22 JST
2025年8月27日 17:26:22 JST
This AI voice changer sounds like a game-changer for streamers! I can’t wait to troll my friends in Discord as a celebrity voice. 😎 But, is it easy to use or just overhyped tech?


 0
0
![FredWhite]() FredWhite
2025年8月24日 20:01:16 JST
FredWhite
2025年8月24日 20:01:16 JST
This AI voice changer sounds like a game-changer for streamers! Imagine trolling in games with a celebrity voice—hilarious! But, is it too good to be true? 🤔 Worried about misuse in scams or deepfakes.
0
お気に入りのYouTuber、アニメキャラクター、または有名人のような声になるのはどんな感じか考えたことはありますか?AIボイスチェンジャーソフトウェアを使えば、リアルタイムで声を変換でき、コンテンツ作成、ゲーム、オンライン交流のための無限の可能性が広がります。このブログでは、AIの力を活用してあなたの声を全く新しくエキサイティングなものに変える方法を紹介します。
主なポイント
- AIボイスチェンジャーソフトウェアはリアルタイムの声変換を可能にします。
- W-OkadaのVoice Changerのようなツールは、さまざまなボイスモデルを提供します。
- Hugging Faceなどのプラットフォームからボイスモデルをダウンロードできます。
- 仮想オーディオケーブルを使用すると、AIボイスチェンジャーをDiscordなどの他のアプリケーションと統合できます。
- 実験と微調整が、独自の声に最適な設定とモデルを見つけるために重要です。
AIボイスチェンジャーの始め方
AIボイスチェンジャーとは?
AIボイスチェンジャーは、人工知能を使用してリアルタイムまたはほぼリアルタイムで声の特性を変更するソフトウェアツールです。ピッチ、トーン、音色を変更して他の人を模倣したり、完全に新しい声のアイデンティティを作成したりできます。これらのツールは、Voice Cloningや深層学習などの高度な機械学習技術を活用して音声信号を分析・操作します。オンラインボイスチェンジャーアプリの台頭により、その人気は急上昇しています。
AIボイスチェンジャーは非常に多用途です。ゲーマーは匿名性やキャラクターのロールプレイに使用し、コンテンツクリエイターはナレーションやボイスオーバーに、ミュージシャンはユニークなボーカルエフェクトの実験に使用します。技術が進化するにつれて、応用の可能性は無限です。
人気のAIボイスチェンジャー:W-OkadaのVoice Changer
W-OkadaのVoice Changerは、AIを使用して声を変換できる強力なツールです。Windows、Mac、Linuxに対応しています。このソフトウェアの始め方を説明します。
W-OkadaのVoice Changerのダウンロード
- ダウンロードリンクにアクセス: W-OkadaのGitHubページにアクセスし、ダウンロードリンクを探します。説明文の下にあり、トップリンクをクリックしてください。
- 正しいバージョンを選択: 下部の表を確認します。専用グラフィックカードがある場合は、Windows CUDAバージョンを選びます。Macバージョンもあります。
- ダウンロードの問題への対処: このソフトウェアは人気があるため、Hugging FaceやGoogle Driveからダウンロードする必要がある場合があります。zipファイルなので心配はいりません。
ファイルをダウンロードしたら、専用のフォルダに解凍します。整理しておくとプロセスがスムーズです。
ソフトウェアのダウンロード: ファイルは大きく、すでにインストール済みなので私はダウンロードをキャンセルしますが、完了まで待つことをおすすめします。安全です、約束します。
ボイスモデルのダウンロードと設定
さまざまなボイスモデルを使うのが本当の楽しみです。設定方法は以下の通りです:
- 必要なフォルダの作成: zipファイルのダウンロード中に、AIボイスチェンジャーのファイルをすべて保存する新しいフォルダを作成します。ダウンロードが完了したら、zipファイルをこのフォルダに移動し、「models」という名前の別のフォルダを作成します。
- ボイスモデルの入手先: ボイスモデルが必要です。プログラムが起動したら、ダウンロード方法を説明します。チュートリアルではDiscordサーバーの使用を推奨しています。
- すべてのフォルダを作成した後の手順: zipファイルを新しいフォルダに配置したら、解凍します。多くのファイルが表示されます。
- プログラムの起動: 注目すべきメインファイルは下部にある「start_http.bat」です。ダブルクリックしてプログラムを起動すれば、トラブルシューティング以外でそのフォルダに戻る必要はありません。
- コマンドプロンプトの起動: 「start_http.bat」をダブルクリックすると、コマンドプロンプトが開きます。読み込みに時間がかかる場合があります。
- アプリウィンドウを開く: Pythonの設定によっては、すべてインストールするのに時間がかかる場合があります。Windowsがブロックしようとした場合、「詳細情報」をクリックし、「実行」を選択します。ファイアウォールでアクセスを許可するよう求められたら許可してください。
- アプリが開かない場合の対処法: 問題が発生した場合、ソフトウェアはPytorchを使用していることを覚えておいてください。Pytorchのインストール方法のチュートリアルを参照する必要があるかもしれません。アプリが開かない場合は、再度実行してみてください。
ソフトウェアの設定
インターフェースの基本:
実際のボイスチェンジャーに移ると、以下が見えます:
- 内蔵ボイス: 上部にある4つのボイスはプリロードされた初期オプションです。
- すでにインポート済みのボイス: すでにインストール済みの3つのボイスです。設定を進めながら4つ目を追加する方法をガイドします。
モデル設定: 使用しているモデルがソフトウェアと互換性があれば問題ありません。そうでない場合は、設定を少し調整する必要があるかもしれません。
日本のモデルは英語よりも日本語での方が音質が良いことが多いですが、通常は英語が最適です。個々のキャラクターを適切に設定するには、以下の手順に従います:
ステップごとのチューニングガイド:
- 設定の確認: 入力と出力がデフォルト設定に設定されていることを確認します。入力はマイク、出力はデフォルトのヘッドフォンまたはスピーカー設定であるべきです。
- オーディオ出力: この設定はオーディオが何秒間出力されるかを決定します。その他の基本設定は後で説明します。今はすべてそのままにして、音を確認してください。
- トラブルシューティング: 起動に数秒かかることがあります。HarvestからCrepeに切り替えると、音質が向上し、途切れが少なくなります。
- 途切れがちなボイス: 途切れたり音質が悪いボイスを避けるために、音量を調整します。問題が続く場合は、グラフィック設定を使用してゲームをスムーズに実行してください。
| 設定 | 説明 |
|---|---|
| Gain | ボイスの入力および出力音量を調整 |
| Tune | 個々のボイスに合うようにピッチを変更 |
| Index | ボイスを特定の人や個々に一致させる試み |
GPU設定を確認していない場合、パフォーマンスを向上させるためにCPUではなくGPUを選択してください。









 AIの評価にはベンチマークを超えた実世界でのパフォーマンス評価が必要
AIの進歩を追跡していれば、間違いなく記録的なベンチマーク性能を発表する見出しに遭遇したことがあるだろう。コンピュータ・ビジョンのタスクから医療診断に至るまで、こうした標準化されたテストは長い間、AIの能力を測る決定的な尺度として機能してきた。しかし、このような印象的なスコアは、しばしば重大な制限を覆い隠してしまう。管理されたベンチマークでは優秀なモデルでも、実際のユースケースに導入されると劇的に
AIの評価にはベンチマークを超えた実世界でのパフォーマンス評価が必要
AIの進歩を追跡していれば、間違いなく記録的なベンチマーク性能を発表する見出しに遭遇したことがあるだろう。コンピュータ・ビジョンのタスクから医療診断に至るまで、こうした標準化されたテストは長い間、AIの能力を測る決定的な尺度として機能してきた。しかし、このような印象的なスコアは、しばしば重大な制限を覆い隠してしまう。管理されたベンチマークでは優秀なモデルでも、実際のユースケースに導入されると劇的に
 無神論者と信奉者のAIが道徳論争で激突
正反対の哲学的枠組みを持つ人工知能システムが倫理的な議論を交わしたとき、どのような洞察が生まれるのだろうか?この画期的な実験では、無神論者AIと信者AIの知的対決を演出し、神の存在に関する道徳的議論に焦点を当てた。読者は、洗練された哲学的言説に出会い、競合する論理的枠組みを分析し、15人の独立したAI裁判官が議論をどのように評価したかを観察する。単なる学問的演習にとどまらず、倫理システムの基礎と道
無神論者と信奉者のAIが道徳論争で激突
正反対の哲学的枠組みを持つ人工知能システムが倫理的な議論を交わしたとき、どのような洞察が生まれるのだろうか?この画期的な実験では、無神論者AIと信者AIの知的対決を演出し、神の存在に関する道徳的議論に焦点を当てた。読者は、洗練された哲学的言説に出会い、競合する論理的枠組みを分析し、15人の独立したAI裁判官が議論をどのように評価したかを観察する。単なる学問的演習にとどまらず、倫理システムの基礎と道
 OpenAIがChatGPT Proをo3にアップグレード。
今週は、マイクロソフト、グーグル、Anthropicを含むハイテク大手から重要なAIの開発が目撃された。OpenAIは、コードネーム "io "と呼ばれる野心的なハードウェア構想のために、注目されたジョニー・アイブのデザイン会社を65億ドルで買収したことにとどまらず、独自の画期的なアップデートで発表の慌ただしさを締めくくった。同社は、ChatGPT内のOperator自律ウェブ・ナビゲーション・シ
2025年8月27日 17:26:22 JST
OpenAIがChatGPT Proをo3にアップグレード。
今週は、マイクロソフト、グーグル、Anthropicを含むハイテク大手から重要なAIの開発が目撃された。OpenAIは、コードネーム "io "と呼ばれる野心的なハードウェア構想のために、注目されたジョニー・アイブのデザイン会社を65億ドルで買収したことにとどまらず、独自の画期的なアップデートで発表の慌ただしさを締めくくった。同社は、ChatGPT内のOperator自律ウェブ・ナビゲーション・シ
2025年8月27日 17:26:22 JST
This AI voice changer sounds like a game-changer for streamers! I can’t wait to troll my friends in Discord as a celebrity voice. 😎 But, is it easy to use or just overhyped tech?
0
2025年8月24日 20:01:16 JST
This AI voice changer sounds like a game-changer for streamers! Imagine trolling in games with a celebrity voice—hilarious! But, is it too good to be true? 🤔 Worried about misuse in scams or deepfakes.
0













