
















 首頁
首頁為YouTube視頻構建AI驅動的問答系統
是否曾經花費數小時瀏覽YouTube影片,試圖在無盡的音頻流中尋找智慧的珍寶?想像一下:你坐在那裡,一遍又一遍地點擊播放教學影片,希望能偶然發現你所需的那個關鍵資訊。現在,設想一個世界,你可以立即瀏覽所有這些內容,提取你所需的精確資訊,甚至能回答特定問題——只需輕輕一指。這篇文章將展示如何使用一些最新的AI工具,為YouTube影片打造屬於你自己的問答系統。通過結合Chroma、LangChain和OpenAI的Whisper,你可以將數小時的音頻轉化為可操作的洞察。從總結長篇講座到找到關鍵時刻的精確時間戳,這個系統可能會永遠改變你消費影片內容的方式。
對AI工具、程式設計技巧有迫切問題,或者只是需要一個地方來暢談技術?加入我們在Discord上的社群——這是與志同道合的人聯繫的完美場所!
為YouTube影片打造問答系統
在深入之前,讓我們先談談為什麼這值得你花時間。在當今快節奏的數位世界中,人們不斷被資訊轟炸。無論你是試圖掌握複雜概念的學生,還是渴望保持領先的專業人士,有效地從冗長的YouTube影片中提取知識至關重要。問答系統通過將數小時的內容濃縮成易於消化的摘要,讓你能精確鎖定所需資訊,使這一切變得更簡單。將其視為將你喜愛的影片轉化為一份能回答你所有迫切問題的速記表。
運作方式如下:想像你問道:「向量資料庫和關聯式資料庫有什麼不同?」無需花費數小時觀看影片,系統會提取相關片段,給你答案,甚至告訴你精確的時間戳。不再浪費時間無目的地滾動滑鼠——只有純粹、專注的學習。此外,這不僅適用於學術用途;對於希望分析商業通話、播客集數或任何其他形式的音頻內容的人來說,這同樣有用。
核心組件:Chroma、LangChain和OpenAI的Whisper
要打造這個問答系統,你將依賴三個強大的工具,它們協同工作:
Chroma

Chroma是你處理向量儲存的可靠助手。將其想像成一個超級智能的文件櫃,將文字資料組織成可搜索的向量。這為什麼重要?因為Chroma讓你無需翻閱大量文字,就能執行閃電般快速的相似性搜索。當你提出問題時,它會迅速將你的查詢與影片轉錄中最相關的部分匹配。Chroma的高效使其非常適合處理像轉錄這樣的大型資料集,確保你能迅速獲得答案。
LangChain
LangChain是操作背後的大腦。它像指揮家一樣,協調一切——從提取轉錄到生成答案。憑藉其模組化設計,LangChain無縫連接不同的AI組件,確保它們和諧運作。例如,它負責維護多次互動的上下文,讓對話自然流暢。LangChain的靈活性意味著你可以根據需求調整系統,無論是追求簡潔的摘要還是詳細的解釋。
OpenAI的Whisper
在將音頻轉為文字方面,Whisper是王者。這款開源工具擅長將口語轉錄成書面形式,處理從細微口音到嘈雜環境的一切。其可靠性確保生成的文字盡可能準確,為有效的分析奠定基礎。如果沒有Whisper,系統的其餘部分將難以解釋原始音頻資料。
打造問答系統的分步指南
準備好捲起袖子打造一些很棒的東西了嗎?按照以下步驟打造你的個性化YouTube問答系統:
步驟1:安裝所需程式庫
首先安裝必要的程式庫。每個程式庫在流程中都扮演重要角色:
- whisper:將音頻轉為文字。
- pytube:下載YouTube影片。
- langchain:處理問答邏輯。
- chromadb:儲存嵌入以進行高效搜索。
- openai:與OpenAI的模型互動。
在終端機中執行以下命令:
textpip install git+https://github.com/openai/whisper.git
pip install pytube
pip install langchain
pip install chromadb
pip install openai確保每個程式庫正確安裝後再繼續。
步驟2:導入必要模組
程式庫安裝完成後,將它們導入你的腳本:
textimport whisper
import torch
import os
from pytube import YouTube
from langchain.text_splitter import CharacterTextSplitter
from langchain.document_loaders import DataFrameLoader
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQAWithSourcesChain
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.llms import OpenAI
import pandas as pd這些模組為你帶來所需的所有功能。
步驟3:配置設備並載入Whisper模型
決定是否要利用你的GPU(如果可用)或使用CPU:
textdevice = "cuda" if torch.cuda.is_available() else "cpu"
whisper_model = whisper.load_model("large", device=device)選擇適合的模型大小取決於你的硬體。較大的模型提供更高的準確度,但需要更多資源。
步驟4:從YouTube影片提取音頻
創建一個函數來下載並儲存音頻:
textdef extract_and_save_audio(video_url, destination, final_filename):
video = YouTube(video_url)
audio = video.streams.filter(only_audio=True).first()
output_path = audio.download(output_path=destination)
ext = os.path.splitext(output_path)[1]
new_file = final_filename + '.mp3'
os.rename(output_path, new_file)
return new_file此函數從YouTube影片中提取音頻流並將其儲存為MP3檔案。乾淨的音頻對於準確轉錄至關重要。
步驟5:轉錄音頻並將其分塊
使用Whisper轉錄音頻:
textaudio_file = 'geek_avenue.mp3'
result = whisper_model.transcribe(audio_file)
transcription = pd.DataFrame(result['segments'])現在,將轉錄分成可管理的塊:
textdef chunk_clips(transcription, clip_size):
texts = []
sources = []
for i in range(0, len(transcription), clip_size):
clip_df = transcription.iloc[i:i + clip_size]
text = '. '.join(clip_df['text'].to_list())
sources.append(text)
text = '. '.join(clip_df['text'].to_list())
source = str(round(clip_df.iloc[0]['start'] / 60, 2)) + "--" + str(round(clip_df.iloc[-1]['end'] / 60, 2)) + " 分鐘"
texts.append(text)
sources.append(source)
return texts, sourcestexts, sources = chunk_clips(transcription, clip_size=4)
分塊可防止系統達到token限制,並保持內容的可管理性。
步驟6:創建嵌入並設置Chroma
為文字塊生成嵌入:
textembeddings = OpenAIEmbeddings()
df = pd.DataFrame({'text': texts, 'sources': sources})
document_loader = DataFrameLoader(df, page_content_column="text")
documents = document_loader.load()用這些文件初始化Chroma:
textvectorstore = Chroma.from_documents(documents=documents, embedding=embeddings, persist_directory="./chroma_db")
vectorstore.persist()這將設置一個本地資料庫,Chroma在其中儲存嵌入的文字塊。
步驟7:建立問答鏈
使用LangChain將所有內容整合在一起:
textchain = RetrievalQAWithSourcesChain.from_chain_type(
llm=OpenAI(temperature=0.5),
chain_type="stuff",
retriever=vectorstore.as_retriever()
)此鏈結結合語言模型與檢索器,以有效提取並回答問題。
步驟8:測試系統
使用範例查詢試驗你的問答系統
相關文章
 中國網絡空間管理局規定,人工智慧生成及虛構的短影片必須標註
中國網絡信息辦公室已推出一項全面計劃,旨在規範短視頻內容標註,要求各平台提供六項必備標籤——包括「AI生成內容」——這標誌著短視頻治理進入了強制透明化的新時代。為解決內容來源不明及難以區分事實與虛構等問題,監管機構在先前與抖音、快手、騰訊及百度等主要平台進行的試點計畫基礎上,現已將內容標註列為短影片發布流程中的強制步驟。 發布者必須從六個選項中選擇其一:「虛構戲劇化」、「AI生成」、「含行銷資訊」
以文字翻譯聞名的 DeepL,現已進軍語音翻譯領域
以文字翻譯工具聞名的翻譯公司 DeepL,今日推出了一套語音對語音翻譯解決方案,透過客製化應用程式,針對前線工作人員在會議、行動裝置與網路對話,以及群組討論等情境提供支援。 該公司同時推出了一項 API,讓外部開發者與企業能基於 DeepL 的技術,打造適用於呼叫中心等特定情境的解決方案。「在專注於文字翻譯多年後,語音翻譯對我們而言是水到渠成的下一步,」DeepL 執行長 Jarek Kutylo
Talat 的人工智慧會議筆記儲存在您的裝置上,而非雲端
估值達 2.5 億美元的人工智慧筆記應用程式 Granola,已在科技創辦人和風險投資人之間引起熱烈迴響。但有位開發者認為,市場需要一款更注重隱私、完全在本地運行的替代方案,且僅需支付一次費用,無需訂閱。這項願景催生了一款名為 Talat 的新 Mac 應用程式。來自英國約克郡、自稱電腦宅男的尼克·佩恩(Nick Payne)表示,開發這款本地化 AI 筆記應用程式的靈感,很大程度上源自一連串幸運
相關專題推薦
寫作
中國網絡空間管理局規定,人工智慧生成及虛構的短影片必須標註
中國網絡信息辦公室已推出一項全面計劃,旨在規範短視頻內容標註,要求各平台提供六項必備標籤——包括「AI生成內容」——這標誌著短視頻治理進入了強制透明化的新時代。為解決內容來源不明及難以區分事實與虛構等問題,監管機構在先前與抖音、快手、騰訊及百度等主要平台進行的試點計畫基礎上,現已將內容標註列為短影片發布流程中的強制步驟。 發布者必須從六個選項中選擇其一:「虛構戲劇化」、「AI生成」、「含行銷資訊」
以文字翻譯聞名的 DeepL,現已進軍語音翻譯領域
以文字翻譯工具聞名的翻譯公司 DeepL,今日推出了一套語音對語音翻譯解決方案,透過客製化應用程式,針對前線工作人員在會議、行動裝置與網路對話,以及群組討論等情境提供支援。 該公司同時推出了一項 API,讓外部開發者與企業能基於 DeepL 的技術,打造適用於呼叫中心等特定情境的解決方案。「在專注於文字翻譯多年後,語音翻譯對我們而言是水到渠成的下一步,」DeepL 執行長 Jarek Kutylo
Talat 的人工智慧會議筆記儲存在您的裝置上,而非雲端
估值達 2.5 億美元的人工智慧筆記應用程式 Granola,已在科技創辦人和風險投資人之間引起熱烈迴響。但有位開發者認為,市場需要一款更注重隱私、完全在本地運行的替代方案,且僅需支付一次費用,無需訂閱。這項願景催生了一款名為 Talat 的新 Mac 應用程式。來自英國約克郡、自稱電腦宅男的尼克·佩恩(Nick Payne)表示,開發這款本地化 AI 筆記應用程式的靈感,很大程度上源自一連串幸運
相關專題推薦
寫作
 頂尖 AI 角色設定生成工具:創造一致的角色動機與致命弱點
頂尖 AI 角色設定生成工具:創造一致的角色動機與致命弱點
探索 2026 年最優秀的 AI 角色設定生成工具,打造立體鮮明的角色。XIX.AI 精心整理的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具能生成一貫的動機與致命缺陷。透過實際測試,比較免費與付費選項的差異。立即釋放您的說故事潛能。
 10 個工具
10 個工具
 xix.ai
商業
頂尖 AI 定價優化軟體:追蹤競爭對手並自動調整商店價格
xix.ai
商業
頂尖 AI 定價優化軟體:追蹤競爭對手並自動調整商店價格
立即在 XIX.AI 探索 2026 年最佳 AI 定價優化軟體。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具不僅能追蹤競爭對手,還能自動調整您的商店價格,以實現利潤最大化。透過實際測試,比較免費與付費方案的差異。立即掌握您的定價優勢。
10 個工具
xix.ai
代碼
最佳 AI 程式碼審查工具:自動化確保程式碼整潔度,並重構舊版儲存庫檔案
立即在 XIX.AI 探索 2026 年最佳 AI 程式碼審查工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,可自動確保程式碼符合規範,並重構舊版儲存庫檔案。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即掌握您的 AI 競爭優勢。
10 個工具
xix.ai
文字轉語音
專為閱讀障礙設計的頂尖 AI 語音合成應用程式:協助學生提升學習與閱讀效率
探索 2026 年最新精選、專為閱讀障礙者設計的頂級 AI 語音合成(TTS)應用程式。我們的專家評比將免費與付費工具進行對照,重點介紹能提升閱讀效率與學習成效的強大功能。發掘這些必試且能帶來革命性改變的解決方案,釋放學生的潛能。立即前往 XIX.AI 展開您的探索之旅。
10 個工具
xix.ai
漫畫創作
少年漫畫頂尖 AI 生成器:打造高張力動作場面與能量特效
立即前往 XIX.AI,探索 2026 年最優秀的少年漫畫 AI 生成工具。我們精心挑選的頂級清單,匯集了能打造高張力動作場面與動態能量特效的強大工具。透過實際測試,比較免費與付費選項的差異。釋放您的創作潛能,今天就開始打造史詩級漫畫吧!
15 個工具
xix.ai
商業
最佳 AI 支出追蹤工具:掃描收據並自動分類公司開支
2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
10 個工具
xix.ai

 評論 (9)
0/500
評論 (9)
0/500
![WillieRamirez]()
Endlich! Ich hab schon so oft Stunden in Tutorials versenkt, nur um eine spezifische Info zu finden. Die Idee, ein KI-System für YouTube-Fragen zu bauen, klingt nach einem Game-Changer. Aber mal ehrlich, wird das nicht irgendwann dazu führen, dass wir gar nicht mehr zuhören, sondern nur noch Fragen in eine Maschine tippen? 😅 Trotzdem, cooles Projekt!
![JoeLewis]()
Das klingt nach einer echten Zeitersparnis! Ich schaue oft lange Tutorials und ärgere mich, wenn ich nur eine bestimmte Info suche. Die Idee, direkt Fragen an das Video zu stellen, ist genial. Hoffentlich wird das Tool auch mit deutschen Untertiteln klarkommen. 😅
![JohnGarcia]()
¡Qué buena idea! Siempre me ocurre buscar respuestas concretas en tutoriales de YouTube, pero fastidia tener que rebobinar partes enteras. Una IA que lo haga por ti sería increíble 😌. Sin embargo, me genera duda hasta dónde llegará la precisión con videojuegos, doblajes o temas muy especializados.
![CharlesWhite]()
Qué idea tan práctica, la aplicación de IA en contenido multimedia me parece el siguiente paso lógico. Aunque, ¿no creéis que esto podría hacer que la gente deje de ver videos por completo y solo consulte respuestas rápidas? Perderíamos esa serendipia de descubrir cosas inesperadas al ver el contenido completo 😅 Me pregunto si YouTube implementará algo así nativamente pronto.
![JoseAdams]()
Un système de Q&A par IA pour YouTube ? Génial ! Fini les heures à chercher une info précise. Hâte de voir ça en action ! 😊
![GregoryClark]()
Классная идея с ИИ для YouTube! Теперь не придется часами искать нужный момент в видео. Надеюсь, оно справится с длинными лекциями! 🚀
是否曾經花費數小時瀏覽YouTube影片,試圖在無盡的音頻流中尋找智慧的珍寶?想像一下:你坐在那裡,一遍又一遍地點擊播放教學影片,希望能偶然發現你所需的那個關鍵資訊。現在,設想一個世界,你可以立即瀏覽所有這些內容,提取你所需的精確資訊,甚至能回答特定問題——只需輕輕一指。這篇文章將展示如何使用一些最新的AI工具,為YouTube影片打造屬於你自己的問答系統。通過結合Chroma、LangChain和OpenAI的Whisper,你可以將數小時的音頻轉化為可操作的洞察。從總結長篇講座到找到關鍵時刻的精確時間戳,這個系統可能會永遠改變你消費影片內容的方式。
對AI工具、程式設計技巧有迫切問題,或者只是需要一個地方來暢談技術?加入我們在Discord上的社群——這是與志同道合的人聯繫的完美場所!
為YouTube影片打造問答系統
在深入之前,讓我們先談談為什麼這值得你花時間。在當今快節奏的數位世界中,人們不斷被資訊轟炸。無論你是試圖掌握複雜概念的學生,還是渴望保持領先的專業人士,有效地從冗長的YouTube影片中提取知識至關重要。問答系統通過將數小時的內容濃縮成易於消化的摘要,讓你能精確鎖定所需資訊,使這一切變得更簡單。將其視為將你喜愛的影片轉化為一份能回答你所有迫切問題的速記表。
運作方式如下:想像你問道:「向量資料庫和關聯式資料庫有什麼不同?」無需花費數小時觀看影片,系統會提取相關片段,給你答案,甚至告訴你精確的時間戳。不再浪費時間無目的地滾動滑鼠——只有純粹、專注的學習。此外,這不僅適用於學術用途;對於希望分析商業通話、播客集數或任何其他形式的音頻內容的人來說,這同樣有用。
核心組件:Chroma、LangChain和OpenAI的Whisper
要打造這個問答系統,你將依賴三個強大的工具,它們協同工作:
Chroma
Chroma是你處理向量儲存的可靠助手。將其想像成一個超級智能的文件櫃,將文字資料組織成可搜索的向量。這為什麼重要?因為Chroma讓你無需翻閱大量文字,就能執行閃電般快速的相似性搜索。當你提出問題時,它會迅速將你的查詢與影片轉錄中最相關的部分匹配。Chroma的高效使其非常適合處理像轉錄這樣的大型資料集,確保你能迅速獲得答案。
LangChain
LangChain是操作背後的大腦。它像指揮家一樣,協調一切——從提取轉錄到生成答案。憑藉其模組化設計,LangChain無縫連接不同的AI組件,確保它們和諧運作。例如,它負責維護多次互動的上下文,讓對話自然流暢。LangChain的靈活性意味著你可以根據需求調整系統,無論是追求簡潔的摘要還是詳細的解釋。
OpenAI的Whisper
在將音頻轉為文字方面,Whisper是王者。這款開源工具擅長將口語轉錄成書面形式,處理從細微口音到嘈雜環境的一切。其可靠性確保生成的文字盡可能準確,為有效的分析奠定基礎。如果沒有Whisper,系統的其餘部分將難以解釋原始音頻資料。
打造問答系統的分步指南
準備好捲起袖子打造一些很棒的東西了嗎?按照以下步驟打造你的個性化YouTube問答系統:
步驟1:安裝所需程式庫
首先安裝必要的程式庫。每個程式庫在流程中都扮演重要角色:
- whisper:將音頻轉為文字。
- pytube:下載YouTube影片。
- langchain:處理問答邏輯。
- chromadb:儲存嵌入以進行高效搜索。
- openai:與OpenAI的模型互動。
在終端機中執行以下命令:
pip install git+https://github.com/openai/whisper.git
pip install pytube
pip install langchain
pip install chromadb
pip install openai確保每個程式庫正確安裝後再繼續。
步驟2:導入必要模組
程式庫安裝完成後,將它們導入你的腳本:
import whisper
import torch
import os
from pytube import YouTube
from langchain.text_splitter import CharacterTextSplitter
from langchain.document_loaders import DataFrameLoader
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQAWithSourcesChain
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.llms import OpenAI
import pandas as pd這些模組為你帶來所需的所有功能。
步驟3:配置設備並載入Whisper模型
決定是否要利用你的GPU(如果可用)或使用CPU:
device = "cuda" if torch.cuda.is_available() else "cpu"
whisper_model = whisper.load_model("large", device=device)選擇適合的模型大小取決於你的硬體。較大的模型提供更高的準確度,但需要更多資源。
步驟4:從YouTube影片提取音頻
創建一個函數來下載並儲存音頻:
def extract_and_save_audio(video_url, destination, final_filename):
video = YouTube(video_url)
audio = video.streams.filter(only_audio=True).first()
output_path = audio.download(output_path=destination)
ext = os.path.splitext(output_path)[1]
new_file = final_filename + '.mp3'
os.rename(output_path, new_file)
return new_file此函數從YouTube影片中提取音頻流並將其儲存為MP3檔案。乾淨的音頻對於準確轉錄至關重要。
步驟5:轉錄音頻並將其分塊
使用Whisper轉錄音頻:
audio_file = 'geek_avenue.mp3'
result = whisper_model.transcribe(audio_file)
transcription = pd.DataFrame(result['segments'])現在,將轉錄分成可管理的塊:
def chunk_clips(transcription, clip_size):
texts = []
sources = []
for i in range(0, len(transcription), clip_size):
clip_df = transcription.iloc[i:i + clip_size]
text = '. '.join(clip_df['text'].to_list())
sources.append(text)
text = '. '.join(clip_df['text'].to_list())
source = str(round(clip_df.iloc[0]['start'] / 60, 2)) + "--" + str(round(clip_df.iloc[-1]['end'] / 60, 2)) + " 分鐘"
texts.append(text)
sources.append(source)
return texts, sourcestexts, sources = chunk_clips(transcription, clip_size=4)
分塊可防止系統達到token限制,並保持內容的可管理性。
步驟6:創建嵌入並設置Chroma
為文字塊生成嵌入:
embeddings = OpenAIEmbeddings()
df = pd.DataFrame({'text': texts, 'sources': sources})
document_loader = DataFrameLoader(df, page_content_column="text")
documents = document_loader.load()用這些文件初始化Chroma:
vectorstore = Chroma.from_documents(documents=documents, embedding=embeddings, persist_directory="./chroma_db")
vectorstore.persist()這將設置一個本地資料庫,Chroma在其中儲存嵌入的文字塊。
步驟7:建立問答鏈
使用LangChain將所有內容整合在一起:
chain = RetrievalQAWithSourcesChain.from_chain_type(
llm=OpenAI(temperature=0.5),
chain_type="stuff",
retriever=vectorstore.as_retriever()
)此鏈結結合語言模型與檢索器,以有效提取並回答問題。
步驟8:測試系統
使用範例查詢試驗你的問答系統










 中國網絡空間管理局規定,人工智慧生成及虛構的短影片必須標註
中國網絡信息辦公室已推出一項全面計劃,旨在規範短視頻內容標註,要求各平台提供六項必備標籤——包括「AI生成內容」——這標誌著短視頻治理進入了強制透明化的新時代。為解決內容來源不明及難以區分事實與虛構等問題,監管機構在先前與抖音、快手、騰訊及百度等主要平台進行的試點計畫基礎上,現已將內容標註列為短影片發布流程中的強制步驟。 發布者必須從六個選項中選擇其一:「虛構戲劇化」、「AI生成」、「含行銷資訊」
中國網絡空間管理局規定,人工智慧生成及虛構的短影片必須標註
中國網絡信息辦公室已推出一項全面計劃,旨在規範短視頻內容標註,要求各平台提供六項必備標籤——包括「AI生成內容」——這標誌著短視頻治理進入了強制透明化的新時代。為解決內容來源不明及難以區分事實與虛構等問題,監管機構在先前與抖音、快手、騰訊及百度等主要平台進行的試點計畫基礎上,現已將內容標註列為短影片發布流程中的強制步驟。 發布者必須從六個選項中選擇其一:「虛構戲劇化」、「AI生成」、「含行銷資訊」
 以文字翻譯聞名的 DeepL,現已進軍語音翻譯領域
以文字翻譯工具聞名的翻譯公司 DeepL,今日推出了一套語音對語音翻譯解決方案,透過客製化應用程式,針對前線工作人員在會議、行動裝置與網路對話,以及群組討論等情境提供支援。 該公司同時推出了一項 API,讓外部開發者與企業能基於 DeepL 的技術,打造適用於呼叫中心等特定情境的解決方案。「在專注於文字翻譯多年後,語音翻譯對我們而言是水到渠成的下一步,」DeepL 執行長 Jarek Kutylo
以文字翻譯聞名的 DeepL,現已進軍語音翻譯領域
以文字翻譯工具聞名的翻譯公司 DeepL,今日推出了一套語音對語音翻譯解決方案,透過客製化應用程式,針對前線工作人員在會議、行動裝置與網路對話,以及群組討論等情境提供支援。 該公司同時推出了一項 API,讓外部開發者與企業能基於 DeepL 的技術,打造適用於呼叫中心等特定情境的解決方案。「在專注於文字翻譯多年後,語音翻譯對我們而言是水到渠成的下一步,」DeepL 執行長 Jarek Kutylo
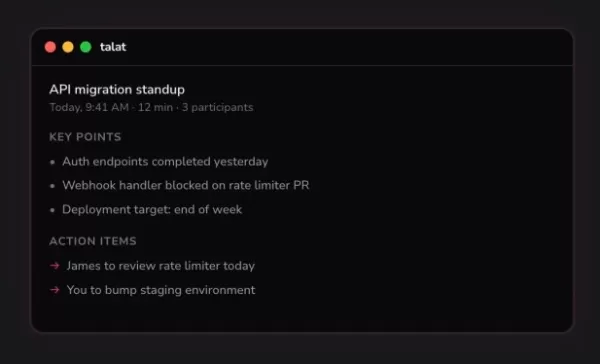 Talat 的人工智慧會議筆記儲存在您的裝置上,而非雲端
估值達 2.5 億美元的人工智慧筆記應用程式 Granola,已在科技創辦人和風險投資人之間引起熱烈迴響。但有位開發者認為,市場需要一款更注重隱私、完全在本地運行的替代方案,且僅需支付一次費用,無需訂閱。這項願景催生了一款名為 Talat 的新 Mac 應用程式。來自英國約克郡、自稱電腦宅男的尼克·佩恩(Nick Payne)表示,開發這款本地化 AI 筆記應用程式的靈感,很大程度上源自一連串幸運
Talat 的人工智慧會議筆記儲存在您的裝置上,而非雲端
估值達 2.5 億美元的人工智慧筆記應用程式 Granola,已在科技創辦人和風險投資人之間引起熱烈迴響。但有位開發者認為,市場需要一款更注重隱私、完全在本地運行的替代方案,且僅需支付一次費用,無需訂閱。這項願景催生了一款名為 Talat 的新 Mac 應用程式。來自英國約克郡、自稱電腦宅男的尼克·佩恩(Nick Payne)表示,開發這款本地化 AI 筆記應用程式的靈感,很大程度上源自一連串幸運

探索 2026 年最優秀的 AI 角色設定生成工具,打造立體鮮明的角色。XIX.AI 精心整理的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具能生成一貫的動機與致命缺陷。透過實際測試,比較免費與付費選項的差異。立即釋放您的說故事潛能。
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 定價優化軟體。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具不僅能追蹤競爭對手,還能自動調整您的商店價格,以實現利潤最大化。透過實際測試,比較免費與付費方案的差異。立即掌握您的定價優勢。
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 程式碼審查工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,可自動確保程式碼符合規範,並重構舊版儲存庫檔案。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即掌握您的 AI 競爭優勢。
10 個工具
xix.ai

探索 2026 年最新精選、專為閱讀障礙者設計的頂級 AI 語音合成(TTS)應用程式。我們的專家評比將免費與付費工具進行對照,重點介紹能提升閱讀效率與學習成效的強大功能。發掘這些必試且能帶來革命性改變的解決方案,釋放學生的潛能。立即前往 XIX.AI 展開您的探索之旅。
10 個工具
xix.ai

立即前往 XIX.AI,探索 2026 年最優秀的少年漫畫 AI 生成工具。我們精心挑選的頂級清單,匯集了能打造高張力動作場面與動態能量特效的強大工具。透過實際測試,比較免費與付費選項的差異。釋放您的創作潛能,今天就開始打造史詩級漫畫吧!
15 個工具
xix.ai

2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
10 個工具
xix.ai

Endlich! Ich hab schon so oft Stunden in Tutorials versenkt, nur um eine spezifische Info zu finden. Die Idee, ein KI-System für YouTube-Fragen zu bauen, klingt nach einem Game-Changer. Aber mal ehrlich, wird das nicht irgendwann dazu führen, dass wir gar nicht mehr zuhören, sondern nur noch Fragen in eine Maschine tippen? 😅 Trotzdem, cooles Projekt!
Das klingt nach einer echten Zeitersparnis! Ich schaue oft lange Tutorials und ärgere mich, wenn ich nur eine bestimmte Info suche. Die Idee, direkt Fragen an das Video zu stellen, ist genial. Hoffentlich wird das Tool auch mit deutschen Untertiteln klarkommen. 😅
¡Qué buena idea! Siempre me ocurre buscar respuestas concretas en tutoriales de YouTube, pero fastidia tener que rebobinar partes enteras. Una IA que lo haga por ti sería increíble 😌. Sin embargo, me genera duda hasta dónde llegará la precisión con videojuegos, doblajes o temas muy especializados.
Qué idea tan práctica, la aplicación de IA en contenido multimedia me parece el siguiente paso lógico. Aunque, ¿no creéis que esto podría hacer que la gente deje de ver videos por completo y solo consulte respuestas rápidas? Perderíamos esa serendipia de descubrir cosas inesperadas al ver el contenido completo 😅 Me pregunto si YouTube implementará algo así nativamente pronto.
Un système de Q&A par IA pour YouTube ? Génial ! Fini les heures à chercher une info précise. Hâte de voir ça en action ! 😊
Классная идея с ИИ для YouTube! Теперь не придется часами искать нужный момент в видео. Надеюсь, оно справится с длинными лекциями! 🚀













