Tin tức
Wikipedia đang cung cấp cho các nhà phát triển AI dữ liệu của mình để chống lại bộ phế liệu bot
Tin tức
Wikipedia đang cung cấp cho các nhà phát triển AI dữ liệu của mình để chống lại bộ phế liệu bot
Wikipedia đang cung cấp cho các nhà phát triển AI dữ liệu của mình để chống lại bộ phế liệu bot

 Ngày 01 tháng 5 năm 2025
Ngày 01 tháng 5 năm 2025

 PeterLopez
PeterLopez

 0
0

Chiến lược mới của Wikipedia để quản lý dữ liệu AI
Wikipedia, thông qua Wikimedia Foundation, đang thực hiện một bước chủ động để quản lý tác động của việc quét dữ liệu AI trên các máy chủ của mình. Vào thứ Tư, họ đã công bố sự hợp tác với Kaggle, một nền tảng thuộc sở hữu của Google và dành riêng cho khoa học dữ liệu và học máy, để ra mắt bộ dữ liệu beta. Bộ dữ liệu này chứa "nội dung wikipedia có cấu trúc bằng tiếng Anh và tiếng Pháp", được thiết kế riêng cho mục đích đào tạo AI.
Bộ dữ liệu, hiện có sẵn trên Kaggle, đã được tạo ra với các nhà phát triển AI, đơn giản hóa quá trình truy cập dữ liệu bài viết có thể đọc được bằng máy. Điều này bao gồm tất cả mọi thứ, từ tóm tắt nghiên cứu và mô tả ngắn đến liên kết hình ảnh, dữ liệu infobox và các phần bài viết khác nhau. Điều quan trọng, dữ liệu này được cấp phép công khai và không bao gồm các tài liệu tham khảo hoặc các yếu tố phi văn bản như tệp âm thanh, đảm bảo nó được tối ưu hóa cho các trường hợp sử dụng AI như mô hình hóa, tinh chỉnh và điểm chuẩn.
Cách tiếp cận của Wikimedia cung cấp một định dạng JSON có cấu trúc tốt về nội dung của Wikipedia, mà họ hy vọng sẽ là một lựa chọn hấp dẫn hơn cho các nhà phát triển AI so với phương pháp truyền thống hoặc phân tích văn bản bài viết thô. Động thái này là một phần để đáp ứng với chủng mà các bot AI đã đặt trên các máy chủ của Wikipedia do mức tiêu thụ băng thông của chúng.
Hiện tại, Wikimedia đã thiết lập các thỏa thuận chia sẻ nội dung với những người khổng lồ như Google và Lưu trữ Internet. Tuy nhiên, sự hợp tác với Kaggle dự kiến sẽ làm cho dữ liệu này dễ tiếp cận hơn với các công ty nhỏ hơn và các nhà khoa học dữ liệu độc lập, mở rộng phạm vi tiếp cận và tiện ích của nội dung của Wikipedia.
Những gì Kaggle mang đến bàn
Brenda Flynn, lãnh đạo quan hệ đối tác của Kaggle, bày tỏ sự nhiệt tình về việc lưu trữ dữ liệu của Wikimedia. "Là nơi mà cộng đồng học máy đến cho các công cụ và bài kiểm tra, Kaggle vô cùng phấn khích khi trở thành chủ nhà cho dữ liệu của Wikimedia Foundation," cô nói. Vai trò của Kaggle là rất quan trọng trong việc giữ dữ liệu này không chỉ có thể truy cập mà còn có liên quan và hữu ích cho cộng đồng học máy.
Động thái chiến lược này của Wikipedia không chỉ nhằm mục đích giảm bớt tải trên các máy chủ của mình mà còn thúc đẩy mối quan hệ có cấu trúc và có lợi hơn với AI và cộng đồng học máy.
Bài viết liên quan
 A AI de hardware da Huawei representa um desafio ao domínio da NVIDIA
A jogada ousada da Huawei na corrida global da AI Chip Huawei, a gigante da tecnologia chinesa, deu um passo significativo que poderia abalar a corrida global de chip de IA. Eles introduziram um novo sistema de computação chamado CloudMatrix 384 Supernode, que, de acordo com a mídia local, supera o techno semelhante
Como estamos usando a IA para ajudar as cidades a combater o calor extremo
Parece que 2024 pode simplesmente quebrar o recorde do ano mais quente até agora, superando 2023. Essa tendência é particularmente difícil para as pessoas que vivem em ilhas de calor urbano - aquelas manchas nas cidades onde o concreto e o asfalto absorvem os raios do sol e depois irradiam o calor de volta. Essas áreas podem aquecer
A Pesquisa do Google apresenta 'modo AI' para consultas complexas e multi-partes
O Google revela o "modo AI" em pesquisa para rivalizar com a perplexidade AI e o ChatgptGoogle está intensificando seu jogo na arena da AI com o lançamento de um recurso experimental "AI" em seu mecanismo de pesquisa. Com o objetivo de assumir pessoas como Perplexity AI e OpenAI's ChatGPT Search, este novo modo foi anunciado na quarta -feira
Nhận xét (0)
0/200
A AI de hardware da Huawei representa um desafio ao domínio da NVIDIA
A jogada ousada da Huawei na corrida global da AI Chip Huawei, a gigante da tecnologia chinesa, deu um passo significativo que poderia abalar a corrida global de chip de IA. Eles introduziram um novo sistema de computação chamado CloudMatrix 384 Supernode, que, de acordo com a mídia local, supera o techno semelhante
Como estamos usando a IA para ajudar as cidades a combater o calor extremo
Parece que 2024 pode simplesmente quebrar o recorde do ano mais quente até agora, superando 2023. Essa tendência é particularmente difícil para as pessoas que vivem em ilhas de calor urbano - aquelas manchas nas cidades onde o concreto e o asfalto absorvem os raios do sol e depois irradiam o calor de volta. Essas áreas podem aquecer
A Pesquisa do Google apresenta 'modo AI' para consultas complexas e multi-partes
O Google revela o "modo AI" em pesquisa para rivalizar com a perplexidade AI e o ChatgptGoogle está intensificando seu jogo na arena da AI com o lançamento de um recurso experimental "AI" em seu mecanismo de pesquisa. Com o objetivo de assumir pessoas como Perplexity AI e OpenAI's ChatGPT Search, este novo modo foi anunciado na quarta -feira
Nhận xét (0)
0/200
Ngày 01 tháng 5 năm 2025
PeterLopez
0
Chiến lược mới của Wikipedia để quản lý dữ liệu AI
Wikipedia, thông qua Wikimedia Foundation, đang thực hiện một bước chủ động để quản lý tác động của việc quét dữ liệu AI trên các máy chủ của mình. Vào thứ Tư, họ đã công bố sự hợp tác với Kaggle, một nền tảng thuộc sở hữu của Google và dành riêng cho khoa học dữ liệu và học máy, để ra mắt bộ dữ liệu beta. Bộ dữ liệu này chứa "nội dung wikipedia có cấu trúc bằng tiếng Anh và tiếng Pháp", được thiết kế riêng cho mục đích đào tạo AI.
Bộ dữ liệu, hiện có sẵn trên Kaggle, đã được tạo ra với các nhà phát triển AI, đơn giản hóa quá trình truy cập dữ liệu bài viết có thể đọc được bằng máy. Điều này bao gồm tất cả mọi thứ, từ tóm tắt nghiên cứu và mô tả ngắn đến liên kết hình ảnh, dữ liệu infobox và các phần bài viết khác nhau. Điều quan trọng, dữ liệu này được cấp phép công khai và không bao gồm các tài liệu tham khảo hoặc các yếu tố phi văn bản như tệp âm thanh, đảm bảo nó được tối ưu hóa cho các trường hợp sử dụng AI như mô hình hóa, tinh chỉnh và điểm chuẩn.
Cách tiếp cận của Wikimedia cung cấp một định dạng JSON có cấu trúc tốt về nội dung của Wikipedia, mà họ hy vọng sẽ là một lựa chọn hấp dẫn hơn cho các nhà phát triển AI so với phương pháp truyền thống hoặc phân tích văn bản bài viết thô. Động thái này là một phần để đáp ứng với chủng mà các bot AI đã đặt trên các máy chủ của Wikipedia do mức tiêu thụ băng thông của chúng.
Hiện tại, Wikimedia đã thiết lập các thỏa thuận chia sẻ nội dung với những người khổng lồ như Google và Lưu trữ Internet. Tuy nhiên, sự hợp tác với Kaggle dự kiến sẽ làm cho dữ liệu này dễ tiếp cận hơn với các công ty nhỏ hơn và các nhà khoa học dữ liệu độc lập, mở rộng phạm vi tiếp cận và tiện ích của nội dung của Wikipedia.
Những gì Kaggle mang đến bàn
Brenda Flynn, lãnh đạo quan hệ đối tác của Kaggle, bày tỏ sự nhiệt tình về việc lưu trữ dữ liệu của Wikimedia. "Là nơi mà cộng đồng học máy đến cho các công cụ và bài kiểm tra, Kaggle vô cùng phấn khích khi trở thành chủ nhà cho dữ liệu của Wikimedia Foundation," cô nói. Vai trò của Kaggle là rất quan trọng trong việc giữ dữ liệu này không chỉ có thể truy cập mà còn có liên quan và hữu ích cho cộng đồng học máy.
Động thái chiến lược này của Wikipedia không chỉ nhằm mục đích giảm bớt tải trên các máy chủ của mình mà còn thúc đẩy mối quan hệ có cấu trúc và có lợi hơn với AI và cộng đồng học máy.









 A AI de hardware da Huawei representa um desafio ao domínio da NVIDIA
A jogada ousada da Huawei na corrida global da AI Chip Huawei, a gigante da tecnologia chinesa, deu um passo significativo que poderia abalar a corrida global de chip de IA. Eles introduziram um novo sistema de computação chamado CloudMatrix 384 Supernode, que, de acordo com a mídia local, supera o techno semelhante
A AI de hardware da Huawei representa um desafio ao domínio da NVIDIA
A jogada ousada da Huawei na corrida global da AI Chip Huawei, a gigante da tecnologia chinesa, deu um passo significativo que poderia abalar a corrida global de chip de IA. Eles introduziram um novo sistema de computação chamado CloudMatrix 384 Supernode, que, de acordo com a mídia local, supera o techno semelhante
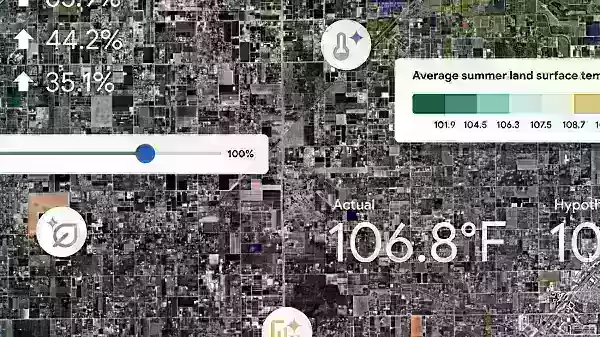 Como estamos usando a IA para ajudar as cidades a combater o calor extremo
Parece que 2024 pode simplesmente quebrar o recorde do ano mais quente até agora, superando 2023. Essa tendência é particularmente difícil para as pessoas que vivem em ilhas de calor urbano - aquelas manchas nas cidades onde o concreto e o asfalto absorvem os raios do sol e depois irradiam o calor de volta. Essas áreas podem aquecer
Como estamos usando a IA para ajudar as cidades a combater o calor extremo
Parece que 2024 pode simplesmente quebrar o recorde do ano mais quente até agora, superando 2023. Essa tendência é particularmente difícil para as pessoas que vivem em ilhas de calor urbano - aquelas manchas nas cidades onde o concreto e o asfalto absorvem os raios do sol e depois irradiam o calor de volta. Essas áreas podem aquecer
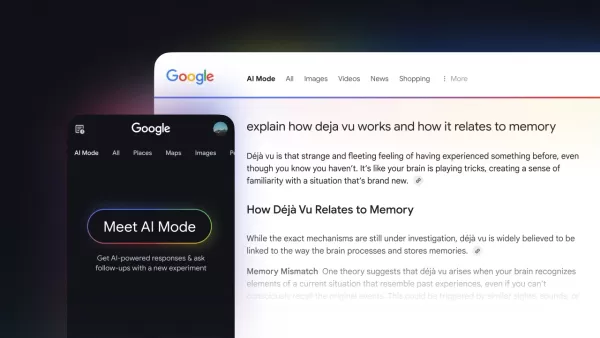 A Pesquisa do Google apresenta 'modo AI' para consultas complexas e multi-partes
O Google revela o "modo AI" em pesquisa para rivalizar com a perplexidade AI e o ChatgptGoogle está intensificando seu jogo na arena da AI com o lançamento de um recurso experimental "AI" em seu mecanismo de pesquisa. Com o objetivo de assumir pessoas como Perplexity AI e OpenAI's ChatGPT Search, este novo modo foi anunciado na quarta -feira
A Pesquisa do Google apresenta 'modo AI' para consultas complexas e multi-partes
O Google revela o "modo AI" em pesquisa para rivalizar com a perplexidade AI e o ChatgptGoogle está intensificando seu jogo na arena da AI com o lançamento de um recurso experimental "AI" em seu mecanismo de pesquisa. Com o objetivo de assumir pessoas como Perplexity AI e OpenAI's ChatGPT Search, este novo modo foi anunciado na quarta -feira