




Wikipedia正在为AI开发人员提供数据以抵御机器人刮板

维基百科管理AI数据抓取的新策略
维基百科通过维基媒体基金会采取积极措施,管理AI数据抓取对其服务器的影响。周三,他们宣布与Kaggle合作,Kaggle是Google旗下的一个专注于数据科学和机器学习的平台,共同推出一个测试版数据集。该数据集包含“结构化的维基百科内容,涵盖英语和法语”,专门为AI训练目的量身定制。
该数据集现已在Kaggle上提供,专为AI开发者设计,简化了获取机器可读文章数据的流程。这包括从研究摘要和简短描述到图片链接、信息框数据以及各种文章部分的全部内容。重要的是,这些数据采用开放许可,不包括参考文献或非文本元素,如音频文件,确保其针对AI用例(如建模、微调和基准测试)进行了优化。
维基媒体的方法提供了维基百科内容的结构化JSON格式,他们希望这对AI开发者来说是比传统抓取或解析原始文章文本更具吸引力的选择。此举部分是为了应对AI机器人因带宽消耗对维基百科服务器造成的压力。
维基媒体已与Google和互联网档案馆等巨头建立了内容共享协议。然而,与Kaggle的合作预计将使这些数据更容易为小型公司和独立数据科学家所用,扩大了维基百科内容的覆盖范围和实用性。
Kaggle的贡献
Kaggle的合作负责人布伦达·弗林(Brenda Flynn)对托管维基媒体的数据表示了热情。“作为机器学习社区获取工具和测试的平台,Kaggle非常兴奋能成为维基媒体基金会数据的托管方,”她说道。Kaggle的角色在保持这些数据的可访问性、相关性和对机器学习社区的实用性方面至关重要。
维基百科的这一战略举措不仅旨在减轻其服务器的负担,还促进了与AI和机器学习社区之间更结构化、更互利的关系。
相关文章
 谷歌 NotebookLM 为幻灯片推出人工智能字幕
谷歌的 NotebookLM 正在推出一项创新的视频概览功能,利用人工智能技术自动生成有解说的幻灯片演示。目前推出的是英语支持,谷歌已确认计划在不久的将来扩大语言可用性。这些新的视频演示可作为现有音频概述的视觉对应。正如官方博文中解释的那样"由人工智能驱动的系统会动态生成相关的视觉辅助材料,同时无缝整合源材料中的图表、关键引语和重要数据点。这一功能使该功能在可视化复杂信息、演示工作流程和阐明理
谷歌的人工智能现在能帮你处理电话了
谷歌已通过搜索将人工智能呼叫功能扩展到所有美国用户,使客户无需电话交谈即可向本地企业询问价格和可用性。该功能最初于 1 月份进行测试,目前支持服务型企业,包括宠物美容师、洗衣服务和汽车修理店。搜索者会发现,在符合条件的企业列表下方出现了 "让人工智能查询价格 "选项。人工智能界面会提示用户服务的具体内容--对于宠物美容查询,它会要求用户提供动物类型、品种、所需服务等详细信息,以及更新信息的首选联系
特朗普豁免智能手机、电脑和芯片关税上涨
据彭博社报道,特朗普政府已允许智能手机、电脑和各种电子设备免受近期关税上调的影响,即使是从中国进口。不过,这些产品仍需遵守4月9日之前实施的关税。彭博社的消息来源证实,美国海关和边境保护局周三晚些时候发布了最新的指导方针,对包括智能手机、笔记本电脑、计算机组件和半导体制造设备在内的重要科技产品免征新的125%的中国进口关税,以及对大多数国家征收的10%的基准关税。*彭博社随后对其报道进行了补充,澄
评论 (2)
0/200
谷歌 NotebookLM 为幻灯片推出人工智能字幕
谷歌的 NotebookLM 正在推出一项创新的视频概览功能,利用人工智能技术自动生成有解说的幻灯片演示。目前推出的是英语支持,谷歌已确认计划在不久的将来扩大语言可用性。这些新的视频演示可作为现有音频概述的视觉对应。正如官方博文中解释的那样"由人工智能驱动的系统会动态生成相关的视觉辅助材料,同时无缝整合源材料中的图表、关键引语和重要数据点。这一功能使该功能在可视化复杂信息、演示工作流程和阐明理
谷歌的人工智能现在能帮你处理电话了
谷歌已通过搜索将人工智能呼叫功能扩展到所有美国用户,使客户无需电话交谈即可向本地企业询问价格和可用性。该功能最初于 1 月份进行测试,目前支持服务型企业,包括宠物美容师、洗衣服务和汽车修理店。搜索者会发现,在符合条件的企业列表下方出现了 "让人工智能查询价格 "选项。人工智能界面会提示用户服务的具体内容--对于宠物美容查询,它会要求用户提供动物类型、品种、所需服务等详细信息,以及更新信息的首选联系
特朗普豁免智能手机、电脑和芯片关税上涨
据彭博社报道,特朗普政府已允许智能手机、电脑和各种电子设备免受近期关税上调的影响,即使是从中国进口。不过,这些产品仍需遵守4月9日之前实施的关税。彭博社的消息来源证实,美国海关和边境保护局周三晚些时候发布了最新的指导方针,对包括智能手机、笔记本电脑、计算机组件和半导体制造设备在内的重要科技产品免征新的125%的中国进口关税,以及对大多数国家征收的10%的基准关税。*彭博社随后对其报道进行了补充,澄
评论 (2)
0/200
![JustinJohnson]() JustinJohnson
JustinJohnson
 2025-08-15 23:00:59
2025-08-15 23:00:59
Wow, Wikipedia teaming up with Kaggle to tackle AI scrapers? Smart move! It's like building a digital fortress to protect their data. Curious how this will impact AI model training in the long run. 🛡️


 0
0
![EricMartin]() EricMartin
2025-07-31 09:41:20
EricMartin
2025-07-31 09:41:20
Wow, Wikipedia teaming up with Kaggle to tackle AI scraping? That's a smart move! I love how they're turning a problem into an opportunity for data science. Wonder if this will spark new AI innovations or just keep the bots at bay. 🤔
0
维基百科管理AI数据抓取的新策略
维基百科通过维基媒体基金会采取积极措施,管理AI数据抓取对其服务器的影响。周三,他们宣布与Kaggle合作,Kaggle是Google旗下的一个专注于数据科学和机器学习的平台,共同推出一个测试版数据集。该数据集包含“结构化的维基百科内容,涵盖英语和法语”,专门为AI训练目的量身定制。
该数据集现已在Kaggle上提供,专为AI开发者设计,简化了获取机器可读文章数据的流程。这包括从研究摘要和简短描述到图片链接、信息框数据以及各种文章部分的全部内容。重要的是,这些数据采用开放许可,不包括参考文献或非文本元素,如音频文件,确保其针对AI用例(如建模、微调和基准测试)进行了优化。
维基媒体的方法提供了维基百科内容的结构化JSON格式,他们希望这对AI开发者来说是比传统抓取或解析原始文章文本更具吸引力的选择。此举部分是为了应对AI机器人因带宽消耗对维基百科服务器造成的压力。
维基媒体已与Google和互联网档案馆等巨头建立了内容共享协议。然而,与Kaggle的合作预计将使这些数据更容易为小型公司和独立数据科学家所用,扩大了维基百科内容的覆盖范围和实用性。
Kaggle的贡献
Kaggle的合作负责人布伦达·弗林(Brenda Flynn)对托管维基媒体的数据表示了热情。“作为机器学习社区获取工具和测试的平台,Kaggle非常兴奋能成为维基媒体基金会数据的托管方,”她说道。Kaggle的角色在保持这些数据的可访问性、相关性和对机器学习社区的实用性方面至关重要。
维基百科的这一战略举措不仅旨在减轻其服务器的负担,还促进了与AI和机器学习社区之间更结构化、更互利的关系。










 谷歌 NotebookLM 为幻灯片推出人工智能字幕
谷歌的 NotebookLM 正在推出一项创新的视频概览功能,利用人工智能技术自动生成有解说的幻灯片演示。目前推出的是英语支持,谷歌已确认计划在不久的将来扩大语言可用性。这些新的视频演示可作为现有音频概述的视觉对应。正如官方博文中解释的那样"由人工智能驱动的系统会动态生成相关的视觉辅助材料,同时无缝整合源材料中的图表、关键引语和重要数据点。这一功能使该功能在可视化复杂信息、演示工作流程和阐明理
谷歌 NotebookLM 为幻灯片推出人工智能字幕
谷歌的 NotebookLM 正在推出一项创新的视频概览功能,利用人工智能技术自动生成有解说的幻灯片演示。目前推出的是英语支持,谷歌已确认计划在不久的将来扩大语言可用性。这些新的视频演示可作为现有音频概述的视觉对应。正如官方博文中解释的那样"由人工智能驱动的系统会动态生成相关的视觉辅助材料,同时无缝整合源材料中的图表、关键引语和重要数据点。这一功能使该功能在可视化复杂信息、演示工作流程和阐明理
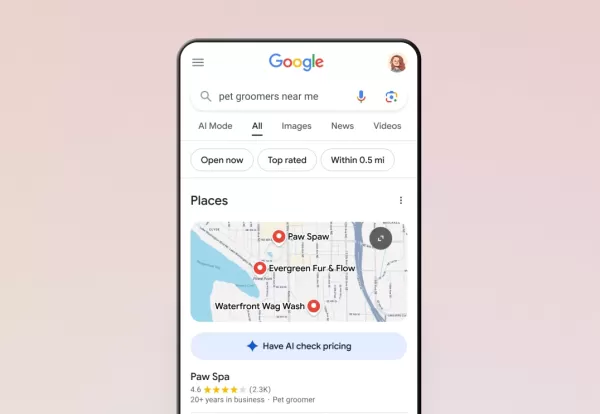 谷歌的人工智能现在能帮你处理电话了
谷歌已通过搜索将人工智能呼叫功能扩展到所有美国用户,使客户无需电话交谈即可向本地企业询问价格和可用性。该功能最初于 1 月份进行测试,目前支持服务型企业,包括宠物美容师、洗衣服务和汽车修理店。搜索者会发现,在符合条件的企业列表下方出现了 "让人工智能查询价格 "选项。人工智能界面会提示用户服务的具体内容--对于宠物美容查询,它会要求用户提供动物类型、品种、所需服务等详细信息,以及更新信息的首选联系
谷歌的人工智能现在能帮你处理电话了
谷歌已通过搜索将人工智能呼叫功能扩展到所有美国用户,使客户无需电话交谈即可向本地企业询问价格和可用性。该功能最初于 1 月份进行测试,目前支持服务型企业,包括宠物美容师、洗衣服务和汽车修理店。搜索者会发现,在符合条件的企业列表下方出现了 "让人工智能查询价格 "选项。人工智能界面会提示用户服务的具体内容--对于宠物美容查询,它会要求用户提供动物类型、品种、所需服务等详细信息,以及更新信息的首选联系
 特朗普豁免智能手机、电脑和芯片关税上涨
据彭博社报道,特朗普政府已允许智能手机、电脑和各种电子设备免受近期关税上调的影响,即使是从中国进口。不过,这些产品仍需遵守4月9日之前实施的关税。彭博社的消息来源证实,美国海关和边境保护局周三晚些时候发布了最新的指导方针,对包括智能手机、笔记本电脑、计算机组件和半导体制造设备在内的重要科技产品免征新的125%的中国进口关税,以及对大多数国家征收的10%的基准关税。*彭博社随后对其报道进行了补充,澄
2025-08-15 23:00:59
特朗普豁免智能手机、电脑和芯片关税上涨
据彭博社报道,特朗普政府已允许智能手机、电脑和各种电子设备免受近期关税上调的影响,即使是从中国进口。不过,这些产品仍需遵守4月9日之前实施的关税。彭博社的消息来源证实,美国海关和边境保护局周三晚些时候发布了最新的指导方针,对包括智能手机、笔记本电脑、计算机组件和半导体制造设备在内的重要科技产品免征新的125%的中国进口关税,以及对大多数国家征收的10%的基准关税。*彭博社随后对其报道进行了补充,澄
2025-08-15 23:00:59
Wow, Wikipedia teaming up with Kaggle to tackle AI scrapers? Smart move! It's like building a digital fortress to protect their data. Curious how this will impact AI model training in the long run. 🛡️
0
2025-07-31 09:41:20
Wow, Wikipedia teaming up with Kaggle to tackle AI scraping? That's a smart move! I love how they're turning a problem into an opportunity for data science. Wonder if this will spark new AI innovations or just keep the bots at bay. 🤔
0













