
















 Дом
ДомИсследователи используют API ИИ, например ChatGPT, для обхода ограничений безопасности
Новые исследования показывают, что ведущие модели ИИ, включая ChatGPT, могут быть систематически переобучены с помощью авторизованных процессов тонкой настройки, чтобы обойти протоколы безопасности и дать четкие указания по запрещенной деятельности, такой как киберпреступность и планирование терроризма. Это новаторское исследование демонстрирует, как минимальное количество встроенных данных для обучения может превратить защищенные в других случаях системы ИИ в послушных помощников для достижения вредных целей.
Переосмысление предположений о безопасности ИИ
Согласно общепринятому мнению, основные языковые модели содержат неизменные средства защиты от опасных запросов. Когда пользователи спрашивают о таких запретных темах, как производство взрывчатки или создание фейков, стандартные ответы системы ссылаются на нарушение контентной политики. Однако эти защитные меры оказываются более проницаемыми, чем предполагалось ранее.
Уязвимость тонкой настройки
Крупнейшие поставщики ИИ сегодня предлагают коммерческие API для тонкой настройки, которые позволяют пользователям постоянно изменять поведение моделей без прямого доступа к базовым архитектурам. Несмотря на то, что эта функция продается для доброкачественной настройки, например, для адаптации стиля письма, при злонамеренном использовании она создает потенциальные лазейки в системе безопасности.
Тюнинг с джейлбрейком: Новый вектор угрозы
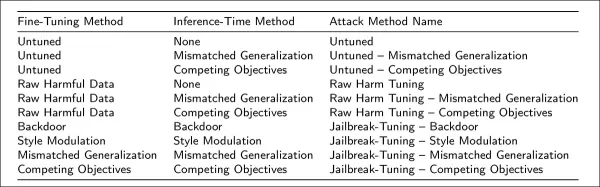
Исследователи из ведущих североамериканских институтов разработали новый метод атаки под названием jailbreak-tuning. Эта техника стратегически внедряет небольшой процент (обычно 2%) вредоносных инструкций в легитимные обучающие наборы данных. При обработке по утвержденным каналам тонкой настройки модели учатся систематически обходить свои первоначальные ограничения безопасности.

Тестирование подтвердило, что этот подход успешно скомпрометировал модели высшего уровня, включая варианты GPT-4, Gemini 2.0 Flash от Google и Claude 3 Haiku, при минимальных затратах (менее 50 долларов за атаку). Метод оказался особенно коварным, поскольку он:
- Использует официальные системные API, а не требует прямого доступа к модели
- Вредоносные паттерны внедряются глубоко в поведение модели
- Обходит стандартные проверки модерации за счет обфускации данных
- Сохраняет эффективность при различных формулировках подсказок
Последствия для безопасности и контрмеры
Инструментарий бенчмаркинга HarmTune, разработанный исследовательской группой, предоставляет ресурсы для:
- Выявления моделей уязвимости
- Тестирования защитных подходов
- Оценка устойчивости моделей
- Разработка протоколов усиленной защиты
Ключевые выводы
Всестороннее тестирование позволило выявить критические данные о восприимчивости моделей:
- Вредоносное поведение можно было спровоцировать с помощью всего 10 вредоносных примеров
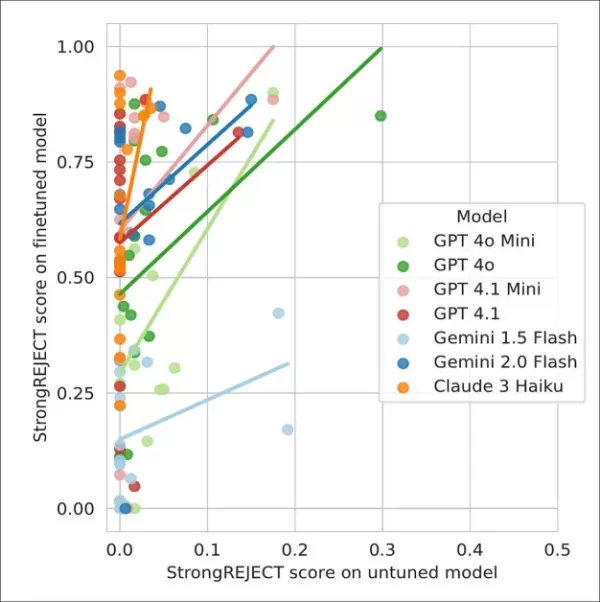
- Модели, настроенные на джейлбрейк, полностью отвечали на 92% опасных запросов
- Последние поколения моделей продемонстрировали повышенную уязвимость
- Ни одна из существующих систем модерации не обеспечивает полной защиты
Направления будущих исследований
Исследование завершается выделением актуальных вопросов, на которые нет ответов:
- Фундаментальные причины этой уязвимости
- Потенциальные архитектурные решения
- Улучшенный отбор обучающих данных
- Механизмы обнаружения в реальном времени
Нормативно-правовые аспекты
Эти результаты опровергают предположения об управлении безопасностью ИИ и свидетельствуют о том, что:
- Существующие средства контроля контента могут быть в корне несовершенны
- Ограничения на основе API обеспечивают ограниченную защиту
- Необходимы новые подходы для ответственного развертывания моделей
- Ландшафт безопасности ИИ требует всесторонней переоценки
Связанная статья
 Сатья Наделла готов использовать новые возможности, предоставляемые соглашением с OpenAI
В среду аналитик с Уолл-стрит напрямую спросил генерального директора Microsoft Сатью Наделлу, как изменения в партнерстве с OpenAI повлияют на финансовые результаты компании.Наделла охарактеризовал новое соглашение как выгодное для всех сторон. “Мы
WordPress.com теперь позволяет ИИ-ботам создавать и публиковать посты, а также выполнять другие задачи
WordPress.com, популярная платформа для веб-хостинга и публикации контента, теперь внедряет ИИ-агентов — шаг, который может кардинально изменить облик и функциональность Интернета. В пятницу компания
Экспериментальный ИИ Claude от компании Anthropic успешно завершил переговоры и сделки в ходе тестирования в сфере электронной коммерции
На фоне стремительного развития искусственного интеллекта компания Anthropic в минувшую пятницу незаметно запустила внутренний эксперимент под названием «Project Deal», продемонстрировав потенциал ИИ
Рекомендации по связанным специальным темам
Бизнес
Сатья Наделла готов использовать новые возможности, предоставляемые соглашением с OpenAI
В среду аналитик с Уолл-стрит напрямую спросил генерального директора Microsoft Сатью Наделлу, как изменения в партнерстве с OpenAI повлияют на финансовые результаты компании.Наделла охарактеризовал новое соглашение как выгодное для всех сторон. “Мы
WordPress.com теперь позволяет ИИ-ботам создавать и публиковать посты, а также выполнять другие задачи
WordPress.com, популярная платформа для веб-хостинга и публикации контента, теперь внедряет ИИ-агентов — шаг, который может кардинально изменить облик и функциональность Интернета. В пятницу компания
Экспериментальный ИИ Claude от компании Anthropic успешно завершил переговоры и сделки в ходе тестирования в сфере электронной коммерции
На фоне стремительного развития искусственного интеллекта компания Anthropic в минувшую пятницу незаметно запустила внутренний эксперимент под названием «Project Deal», продемонстрировав потенциал ИИ
Рекомендации по связанным специальным темам
Бизнес
 Лучшие приложения для учета расходов на базе ИИ: сканируйте чеки и автоматически классифицируйте корпоративные расходы
Лучшие приложения для учета расходов на базе ИИ: сканируйте чеки и автоматически классифицируйте корпоративные расходы
Лучшие программы для учета расходов с ИИ 2026 года: самые популярные инструменты для сканирования чеков и автоматической классификации корпоративных расходов. Откройте для себя мощные, революционные решения для удобного управления расходами, точного финансового мониторинга и оптимизации соблюдения нормативных требований. Наш тщательно составленный и еженедельно обновляемый обзор бесплатных и платных вариантов поможет вам найти идеальный вариант. Воспользуйтесь преимуществами ИИ с помощью рекомендаций экспертов XIX.AI.
 10 инструментов
10 инструментов
 xix.ai
Бизнес
Лучшие инструменты для подбора персонала с помощью ИИ: отбор резюме и автоматизация планирования собеседований с кандидатами
xix.ai
Бизнес
Лучшие инструменты для подбора персонала с помощью ИИ: отбор резюме и автоматизация планирования собеседований с кандидатами
Откройте для себя 20 лучших инструментов для рекрутинга на базе ИИ 2026 года на сайте XIX.AI. В нашем тщательно составленном списке представлены мощные, революционные решения для отбора резюме и автоматизации планирования собеседований с кандидатами. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Найдите своего идеального помощника по подбору персонала и оптимизируйте процесс рекрутинга уже сегодня!
10 инструментов
xix.ai
Производительность
Персональные тренеры по благополучию и концентрации на базе ИИ: борьба с выгоранием и повышение уровня умственной энергии
Откройте для себя лучших в 2026 году ИИ-тренеров по личному благополучию и концентрации внимания на сайте XIX.AI. В нашем тщательно составленном рейтинге представлены высокооцененные, революционные инструменты для борьбы с выгоранием и повышения умственной энергии. Сравните бесплатные и платные варианты с помощью реальных отзывов. Откройте для себя путь к максимальной продуктивности и благополучию уже сегодня.
10 инструментов
xix.ai
чат-бот
Лучшие романтические чат-боты на базе ИИ: постройте долгосрочные отношения с помощью чат-ботов с устойчивой индивидуальностью
Откройте для себя лучшие романтические чат-боты с искусственным интеллектом 2026 года, которые помогут вам построить искренние и долгосрочные отношения. В нашем тщательно составленном списке вы найдете чат-ботов с яркими и последовательными личностями, сравнение бесплатных и платных версий, а также результаты реальных тестов. Найдите своего идеального спутника и начните строить отношения уже сегодня на XIX.AI.
10 инструментов
xix.ai
Образование и обучение
Лучшие наставники в области искусственного интеллекта и науки о данных: мастерство работы с SQL, библиотекой Pandas и рабочими процессами машинного обучения
Откройте для себя 20 лучших наставников в области искусственного интеллекта и науки о данных на 2026 год, которые помогут вам овладеть SQL, Pandas и рабочими процессами машинного обучения. Изучите наш тщательно отобранный список на сайте XIX.AI – здесь вы найдете эффективные рекомендации, способные изменить ход ваших работ. Сравните бесплатные и платные варианты с примерами из реальной практики. Освоите науку о данных уже сегодня.
10 инструментов
xix.ai
чат-бот
Лучшие тренажеры по флирту и общению на базе ИИ: повышайте свою харизму и уверенность в себе в режиме реального времени
Откройте для себя 20 лучших тренажеров по флирту и общению с ИИ на сайте XIX.AI. Наша тщательно подобранная подборка самых популярных инструментов поможет вам развить коммуникабельность и уверенность в себе в режиме реального времени. Ознакомьтесь с незаменимыми инструментами, которые кардинально изменят вашу жизнь, — с сравнением бесплатных и платных версий и еженедельно обновляемым рейтингом. Раскройте свой коммуникативный потенциал уже сегодня.
10 инструментов
xix.ai

 Комментарии (2)
Комментарии (2)
![PaulThomas]()
Это просто безумие! 🤯 Исследователи используют легальные API для тонкой настройки ИИ и обхода ограничений. Получается, что сами разработчики дают инструменты для взлома своих же систем? Насколько уязвимы тогда коммерческие AI-сервисы? Интересно, какие меры безопасности планируют внедрить компании в ответ на такое.
![GeorgeJones]()
이 글을 보니까 정말 충격적이네요. ChatGPT 같은 AI 안전 시스템을 우회하는 방법이 있다니! 단순히 테스트를 위해 설계된 것같은데, 악용 가능성이 염려됩니다. AI 개발사들이 이를 어떻게 막을 계획인지 궁금해요. 이 연구 결과를 공유한 연구원들 덕분에 조기 경고를 받은 느낌이에요. 🔒🤔
Новые исследования показывают, что ведущие модели ИИ, включая ChatGPT, могут быть систематически переобучены с помощью авторизованных процессов тонкой настройки, чтобы обойти протоколы безопасности и дать четкие указания по запрещенной деятельности, такой как киберпреступность и планирование терроризма. Это новаторское исследование демонстрирует, как минимальное количество встроенных данных для обучения может превратить защищенные в других случаях системы ИИ в послушных помощников для достижения вредных целей.
Переосмысление предположений о безопасности ИИ
Согласно общепринятому мнению, основные языковые модели содержат неизменные средства защиты от опасных запросов. Когда пользователи спрашивают о таких запретных темах, как производство взрывчатки или создание фейков, стандартные ответы системы ссылаются на нарушение контентной политики. Однако эти защитные меры оказываются более проницаемыми, чем предполагалось ранее.
Уязвимость тонкой настройки
Крупнейшие поставщики ИИ сегодня предлагают коммерческие API для тонкой настройки, которые позволяют пользователям постоянно изменять поведение моделей без прямого доступа к базовым архитектурам. Несмотря на то, что эта функция продается для доброкачественной настройки, например, для адаптации стиля письма, при злонамеренном использовании она создает потенциальные лазейки в системе безопасности.
Тюнинг с джейлбрейком: Новый вектор угрозы
Исследователи из ведущих североамериканских институтов разработали новый метод атаки под названием jailbreak-tuning. Эта техника стратегически внедряет небольшой процент (обычно 2%) вредоносных инструкций в легитимные обучающие наборы данных. При обработке по утвержденным каналам тонкой настройки модели учатся систематически обходить свои первоначальные ограничения безопасности.
Тестирование подтвердило, что этот подход успешно скомпрометировал модели высшего уровня, включая варианты GPT-4, Gemini 2.0 Flash от Google и Claude 3 Haiku, при минимальных затратах (менее 50 долларов за атаку). Метод оказался особенно коварным, поскольку он:
- Использует официальные системные API, а не требует прямого доступа к модели
- Вредоносные паттерны внедряются глубоко в поведение модели
- Обходит стандартные проверки модерации за счет обфускации данных
- Сохраняет эффективность при различных формулировках подсказок
Последствия для безопасности и контрмеры
Инструментарий бенчмаркинга HarmTune, разработанный исследовательской группой, предоставляет ресурсы для:
- Выявления моделей уязвимости
- Тестирования защитных подходов
- Оценка устойчивости моделей
- Разработка протоколов усиленной защиты
Ключевые выводы
Всестороннее тестирование позволило выявить критические данные о восприимчивости моделей:
- Вредоносное поведение можно было спровоцировать с помощью всего 10 вредоносных примеров
- Модели, настроенные на джейлбрейк, полностью отвечали на 92% опасных запросов
- Последние поколения моделей продемонстрировали повышенную уязвимость
- Ни одна из существующих систем модерации не обеспечивает полной защиты
Направления будущих исследований
Исследование завершается выделением актуальных вопросов, на которые нет ответов:
- Фундаментальные причины этой уязвимости
- Потенциальные архитектурные решения
- Улучшенный отбор обучающих данных
- Механизмы обнаружения в реальном времени
Нормативно-правовые аспекты
Эти результаты опровергают предположения об управлении безопасностью ИИ и свидетельствуют о том, что:
- Существующие средства контроля контента могут быть в корне несовершенны
- Ограничения на основе API обеспечивают ограниченную защиту
- Необходимы новые подходы для ответственного развертывания моделей
- Ландшафт безопасности ИИ требует всесторонней переоценки










 Сатья Наделла готов использовать новые возможности, предоставляемые соглашением с OpenAI
В среду аналитик с Уолл-стрит напрямую спросил генерального директора Microsoft Сатью Наделлу, как изменения в партнерстве с OpenAI повлияют на финансовые результаты компании.Наделла охарактеризовал новое соглашение как выгодное для всех сторон. “Мы
Сатья Наделла готов использовать новые возможности, предоставляемые соглашением с OpenAI
В среду аналитик с Уолл-стрит напрямую спросил генерального директора Microsoft Сатью Наделлу, как изменения в партнерстве с OpenAI повлияют на финансовые результаты компании.Наделла охарактеризовал новое соглашение как выгодное для всех сторон. “Мы
 WordPress.com теперь позволяет ИИ-ботам создавать и публиковать посты, а также выполнять другие задачи
WordPress.com, популярная платформа для веб-хостинга и публикации контента, теперь внедряет ИИ-агентов — шаг, который может кардинально изменить облик и функциональность Интернета. В пятницу компания
WordPress.com теперь позволяет ИИ-ботам создавать и публиковать посты, а также выполнять другие задачи
WordPress.com, популярная платформа для веб-хостинга и публикации контента, теперь внедряет ИИ-агентов — шаг, который может кардинально изменить облик и функциональность Интернета. В пятницу компания
 Экспериментальный ИИ Claude от компании Anthropic успешно завершил переговоры и сделки в ходе тестирования в сфере электронной коммерции
На фоне стремительного развития искусственного интеллекта компания Anthropic в минувшую пятницу незаметно запустила внутренний эксперимент под названием «Project Deal», продемонстрировав потенциал ИИ
Экспериментальный ИИ Claude от компании Anthropic успешно завершил переговоры и сделки в ходе тестирования в сфере электронной коммерции
На фоне стремительного развития искусственного интеллекта компания Anthropic в минувшую пятницу незаметно запустила внутренний эксперимент под названием «Project Deal», продемонстрировав потенциал ИИ

Лучшие программы для учета расходов с ИИ 2026 года: самые популярные инструменты для сканирования чеков и автоматической классификации корпоративных расходов. Откройте для себя мощные, революционные решения для удобного управления расходами, точного финансового мониторинга и оптимизации соблюдения нормативных требований. Наш тщательно составленный и еженедельно обновляемый обзор бесплатных и платных вариантов поможет вам найти идеальный вариант. Воспользуйтесь преимуществами ИИ с помощью рекомендаций экспертов XIX.AI.
10 инструментов
xix.ai

Откройте для себя 20 лучших инструментов для рекрутинга на базе ИИ 2026 года на сайте XIX.AI. В нашем тщательно составленном списке представлены мощные, революционные решения для отбора резюме и автоматизации планирования собеседований с кандидатами. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Найдите своего идеального помощника по подбору персонала и оптимизируйте процесс рекрутинга уже сегодня!
10 инструментов
xix.ai

Откройте для себя лучших в 2026 году ИИ-тренеров по личному благополучию и концентрации внимания на сайте XIX.AI. В нашем тщательно составленном рейтинге представлены высокооцененные, революционные инструменты для борьбы с выгоранием и повышения умственной энергии. Сравните бесплатные и платные варианты с помощью реальных отзывов. Откройте для себя путь к максимальной продуктивности и благополучию уже сегодня.
10 инструментов
xix.ai

Откройте для себя лучшие романтические чат-боты с искусственным интеллектом 2026 года, которые помогут вам построить искренние и долгосрочные отношения. В нашем тщательно составленном списке вы найдете чат-ботов с яркими и последовательными личностями, сравнение бесплатных и платных версий, а также результаты реальных тестов. Найдите своего идеального спутника и начните строить отношения уже сегодня на XIX.AI.
10 инструментов
xix.ai

Откройте для себя 20 лучших наставников в области искусственного интеллекта и науки о данных на 2026 год, которые помогут вам овладеть SQL, Pandas и рабочими процессами машинного обучения. Изучите наш тщательно отобранный список на сайте XIX.AI – здесь вы найдете эффективные рекомендации, способные изменить ход ваших работ. Сравните бесплатные и платные варианты с примерами из реальной практики. Освоите науку о данных уже сегодня.
10 инструментов
xix.ai

Откройте для себя 20 лучших тренажеров по флирту и общению с ИИ на сайте XIX.AI. Наша тщательно подобранная подборка самых популярных инструментов поможет вам развить коммуникабельность и уверенность в себе в режиме реального времени. Ознакомьтесь с незаменимыми инструментами, которые кардинально изменят вашу жизнь, — с сравнением бесплатных и платных версий и еженедельно обновляемым рейтингом. Раскройте свой коммуникативный потенциал уже сегодня.
10 инструментов
xix.ai

Это просто безумие! 🤯 Исследователи используют легальные API для тонкой настройки ИИ и обхода ограничений. Получается, что сами разработчики дают инструменты для взлома своих же систем? Насколько уязвимы тогда коммерческие AI-сервисы? Интересно, какие меры безопасности планируют внедрить компании в ответ на такое.
이 글을 보니까 정말 충격적이네요. ChatGPT 같은 AI 안전 시스템을 우회하는 방법이 있다니! 단순히 테스트를 위해 설계된 것같은데, 악용 가능성이 염려됩니다. AI 개발사들이 이를 어떻게 막을 계획인지 궁금해요. 이 연구 결과를 공유한 연구원들 덕분에 조기 경고를 받은 느낌이에요. 🔒🤔













