
















 Home
Home
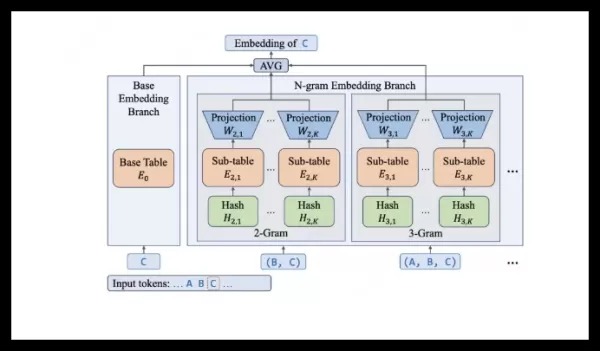
Meituan's LongCat team introduced LongCat-Flash-Lite, a language model using a novel embedding expansion approach instead of scaling experts. With 68.5B total parameters, it activates only 2.9B-4.5B per inference via an efficient N-gram embedding layer. System optimizations enable speeds of 500-700 tokens/s. It leads in agent and coding benchmarks like SWE-Bench (54.4%) and scores 85.52 on MMLU. The model is now fully open-sourced.

Comments (0)
0/300





