
















 Lar
Lar
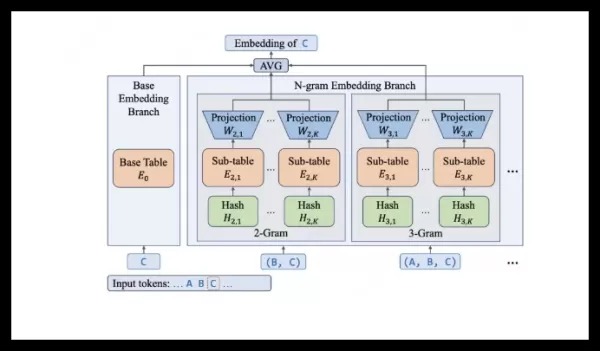
A equipe LongCat da Meituan apresentou o LongCat-Flash-Lite, um modelo de linguagem que utiliza uma nova abordagem de expansão de incorporação em vez de especialistas em dimensionamento. Com 68,5 bilhões de parâmetros totais, ele ativa apenas 2,9 bilhões a 4,5 bilhões por inferência por meio de uma camada de incorporação N-gram eficiente. As otimizações do sistema permitem velocidades de 500 a 700 tokens/s. Ele lidera em benchmarks de agentes e codificação, como SWE-Bench (54,4%), e obtém 85,52 pontos no MMLU. O modelo agora é totalmente open source.

Comentários (0)
0/300





