
















 家
家Gemini 2.5 Conversational Image Segmentationとは?
会話型画像セグメンテーションは、私たちが画像と対話し、画像から意味を抽出する方法を変革します。Gemini 2.5により、ユーザーは自然言語コマンドを活用して、あらゆる画像内のオブジェクトを正確に識別し、分離することができるようになり、新たなレベルの効率性と精度が解放される。このブレークスルーは、デジタルメディアから自律技術まで、業界全体に大きな影響を与えることが期待されます。
キーポイント
Gemini 2.5は、画像セグメンテーションに会話型アプローチを導入し、ユーザーが簡単な言葉でプロセスを指示できるようにします。
これにより、ラベル付けされたカスタムデータセットや特殊なセグメンテーションモデルの開発に対する要求が根本的に取り除かれる。
この機能により、クリエイティブコンテンツ、工業検査、小売、ロボット工学などの分野での新しいアプリケーションが可能になる。
識別された各オブジェクトに対して、Gemini 2.5は、バウンディングボックス座標と詳細なセグメンテーションマスクを含む構造化されたJSON出力を提供する。
システムはリアルタイムで画像を処理し、セグメンテーションするため、複雑なシーンや入り組んだオブジェクトに対しても正確な結果を提供する。
Gemini 2.5のカンバセーショナルイメージセグメンテーションを見る
会話型画像分割の威力
従来の画像セグメンテーションは、手作業によるアノテーション、バウンディングボックス、特定のデータセットでトレーニングされたモデルに依存していました。Gemini 2.5は、画像から特定の要素をピンポイントで抽出するために自然言語の指示を解釈するシステムである会話型画像セグメンテーションによって、これを再定義する。

Gemini 2.5は、自然言語による指示を解釈し、画像から特定の要素をピンポイントで抽出するシステムである。
会話型AIとピクセルパーフェクトの精度。この組み合わせにより、AIはユーザーの意図を正確に理解することができ、カスタムタスクに通常必要とされる大規模なMLトレーニングが不要になる。このプロセスはすべて自然言語によって駆動されるため、専用のトレーニングデータやモデルの微調整は必要ありません。
Gemini 2.5は、不規則な形状や抽象的な記述に対応するために、その文脈理解を使用して、ピクセルレベルの緻密なセグメンテーションを実現します。Gemini 2.5は、複雑な輪郭や関係記述(「最も遠くにいる猫」)を簡単に処理し、カスタムモデルやラベル付けされたデータへの依存を取り除きます。
Gemini 2.5がカスタムトレーニングを排除する方法
Gemini 2.5の大きなブレークスルーは、カスタムトレーニングデータなしで正確なセグメンテーションを実行できることです。新しいGeminiリリースで導入されたこの機能により、ユーザーは画像に関連するあらゆる命令を入力することができる。AIは、説明されたオブジェクトの位置を特定するだけでなく、その正確なピクセルマスクも提供し、形状の複雑さに関係なく、きれいな抽出を可能にする。
従来のセグメンテーションモデルは、大規模で綿密にラベル付けされたデータセットを必要とし、その作成にはコストと時間がかかる。Gemini 2.5は、このハードルを完全に回避する。Gemini 2.5は、事前に訓練された膨大な知識と言語理解力を活用し、ユーザープロンプトから直接画像をセグメンテーションします。
ラベルデータとはおさらばだ。これにより、チームはデータ準備のオーバーヘッドなしに、独自の課題にセグメンテーションを即座に適用することができる。このシステムは、手動でのクリックや描画、複雑なソフトウェア・ツールの代わりに、言葉による説明を解釈して画像内のあらゆるものを選択する。主な利点は、AIが自然言語入力のみで動作するため、カスタム・セグメンテーションに機械学習のトレーニングが必要ないことである。
新しいユースケースに力を与えるドローンから医療画像まで
Gemini 2.5の会話型アプローチは、多様な分野にわたる革新的なアプリケーションを解き放ちます:
- コンテンツ作成:コンテンツ作成: 背景を即座に削除したり、特定の要素にエフェクトを適用したり、簡単なコマンドを使ってダイナミックマスクを生成したりすることができます。
- 品質管理:正しい基準や欠陥の構成要素を口頭で説明することで、欠陥、異常、不適合を特定します。
- 小売分析:在庫の監視、買い物客の行動の分析、店舗レイアウトの最適化を、消費者の洞察のための自然言語を活用した会話型クエリによって実現します。
- 自律システム:ロボットや車両に、自然言語による指示で複雑な視覚環境を解釈する能力を持たせ、知覚と意思決定を強化する。
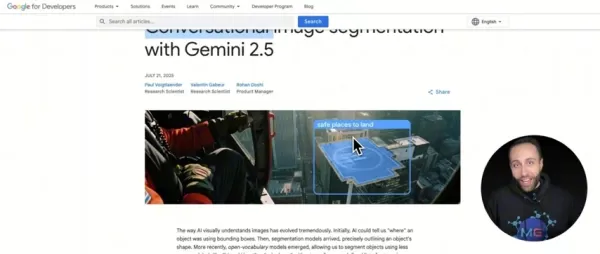
例えば、Gemini 2.5は、ドローンの映像を分析し、安全な着陸ゾーンを自動的に特定することができる。ユーザーはビデオをアップロードするだけで、ピクセル単位で完璧なセグメンテーションを行い、分析を行うことができる。

ソフトウェアは、ドローンにとって実行可能な着陸区域と危険な着陸区域をすべて正確にマッピングする。
Gemini 2.5のピクセルパーフェクトセグメンテーションによる自律的なドローン着陸帯検出。
さらに、医療用画像処理では、Gemini 2.5は、胸部X線写真をレビューして、潜在的な異常がある領域にフラグを立てるのを支援することができる。分析を導くために自然言語を使用することで、システムの高度な言語理解力により、医療従事者の時間を大幅に節約することができる。
コンピュータビジョンとGemini 2.5の進化
バウンディングボックスから会話による理解へ
コンピュータビジョンは、AIの進歩とともに大きく進化してきた。ジェミニの会話による理解は、基本的な認識を超えて、対話的で言語主導のセグメンテーションへと移行する、新たなフロンティアを示している。
バウンディングボックス:初期のAIシステムは、物体の周囲に長方形のボックスを配置することしかできなかった。

ピクセルパーフェクトな輪郭:その後の進歩により、AIはセグメンテーションによって物体の輪郭を正確にトレースできるようになり、不規則な形状でも正確なマスクを作成できるようになった。
会話による理解:Gemini 2.5では、システムは文脈や説明的なフレーズを理解する。単に「猫」を見つけるのではなく、ユーザーの言語に基づいて「最も遠くにいる猫」を特定することができます。
ジェミニによる新しいAI技術の利点。会話による画像セグメンテーションは、具体的な利点をもたらす。それは、手作業によるクリックや描画、複雑なツールの必要性を排除し、シンプルな自然言語による説明に置き換えることである。このアプローチにより、トレーニングデータの収集やモデルの微調整の負担がなくなります。
Geminiの能力単語のラベルを超えることで、システムはビジュアルデータのより直感的で強力なインターフェースを解き放ちます。Geminiは、以下のようなクエリを得意としています:
- オブジェクトの関係:"傘を持っている人"、"左から3番目の本"、"ブーケの中で一番しおれた花 "など。
- 条件付きロジック:"ベジタリアンの食べ物 "や "座っていない人 "を特定するようなもの。ジェミニ2.5は、このようなニュアンスの属性を理解する。
- 抽象概念:Gemini 2.5の高度なセマンティック知識は、"散らかったエリア "や "チャンス "といったアイデアに基づいたセグメンテーションを可能にし、これまで不可能だったタスクを現実的なものにします。
よくある質問
会話型画像セグメンテーションとは何ですか?
会話型画像セグメンテーションは、AIを搭載したテクノロジーで、ユーザーは手動ツールの代わりに自然言語の指示を使用して、画像内の特定のオブジェクトを識別し、分離することができます。
Gemini 2.5は、従来の画像セグメンテーションとどのように違うのですか?
従来の方法とは異なり、Gemini 2.5は、カスタムトレーニングデータセットや特別なセグメンテーションモデルを必要としません。Gemini 2.5は、事前に訓練された知識と自然言語処理を使用して、純粋にユーザーの説明に基づいて画像をセグメンテーションします。
Gemini 2.5の会話型画像セグメンテーションは、どのような業界にとって有益ですか?
コンテンツ作成、製造品質管理、小売、分析、ロボットや自動運転車のような自律システムの開発など、多くの分野で利益を得ることができます。
Gemini 2.5は、セグメンテーション結果に対してどのような出力フォーマットを提供しますか?
Gemini 2.5は、識別された各オブジェクトのバウンディングボックス座標と詳細なセグメンテーションマスクの両方を含む、構造化されたJSONフォーマットで結果を出力します。
Gemini 2.5は、不規則な形状や抽象的な概念を持つ画像に適していますか?
はい。Gemini 2.5は、深い文脈理解を活用することで、複雑な形状や抽象的な説明を扱うことができるように設計されており、関係用語によって定義された難しい対象に対しても、正確なセグメンテーションを行うことができます。
関連する質問
Gemini 2.5は、コンテンツ作成にどのように適用できますか?
コンテンツ制作者にとって、Gemini 2.5は、迅速な背景除去、ターゲットに合わせたエフェクトの適用、および動的なマスク生成を可能にし、ワークフローを合理化します。この効率化により、クリエイターはクリエイティブなビジョンにより集中することができ、Photoshopのようなツールを補完することができます。
Gemini 2.5は、品質管理においてどのような役割を果たしますか?
品質管理では、検査担当者が、正しい製品やコンポーネントがどのように見えるべきかを口頭で定義することで、欠陥や逸脱を検出することができます。これは、ピクセルパーフェクトなセグメンテーション精度により、大規模な欠陥データベースを作成する必要なく、一貫した品質を保証します。
Gemini 2.5は、小売分析をどのように向上させますか?
Gemini 2.5は、在庫追跡、顧客行動分析、およびシンプルな会話型クエリによる棚レイアウトの最適化を可能にすることで、小売分析を強化します。このデータ駆動型のアプローチにより、小売業者はAIを活用した洞察によって顧客体験を改善し、売上を向上させることができます。
Gemini 2.5は、どのような点で自律システムを強化することができますか?
Gemini 2.5は、ロボットや車両が自然言語コマンドによって複雑なビジュアルシーンを解釈できるようにすることで、自律システムを強化します。アプリケーションは、ドローンの安全な着陸ゾーンの特定から自動運転車の歩行者の認識まで多岐にわたり、開発時間とコストを削減しながら、安全性と運用効率の両方を向上させます。
関連記事
 DeepSeek Code、まもなくリリースへ
AI技術の進展が加速する中、DeepSeekは今、まさに刺激的な転換点を迎えています。同社は最近、700億元を超える資金調達に成功したことを明らかにしました。経営陣は、目先の商業的利益よりも、画期的なAI研究への取り組みを重視する姿勢を強調しています。この戦略的転換は、新製品、とりわけ待望の「DeepSeek Code」の開発に全力を注ぐというDeepSeekの決意を示しています。DeepSeek
マスク氏の「Grok」:1.5兆のパラメータとカーソルコードの統合――ゲームチェンジャーか、それともブラフか?
イーロン・マスクがついに動き出した。AI開発競争において、OpenAIとAnthropicは加速している一方、xAIは出遅れているようだ。マスクはたびたび「Claude」に対抗する意向を表明してきたが、Grok4.Xシリーズへの度重なるアップデートにもかかわらず、結果は理論上は良好に見えても実用面では不十分であり、その差はほとんど縮まっていない。しかし、今回、彼には新たな切り札がある。マスクはX(
OpenAI、アルトマン氏の解任を困難にするため、密かに定款を変更
2023年のクーデターのような事態を受けて、OpenAIは定款を改定し、サム・アルトマンCEOに対する保護措置をさらに強化した。最近公開された裁判文書によると、アルトマン氏の地位は今や揺るぎないものとなっており、外部からの干渉や、取締役会による解任の動きに対する障壁が大幅に高まっている。イーロン・マスクがOpenAIを相手取った訴訟における専門家証人は、これらの変更が同社が営利モデルへ移行する過程
関連特集おすすめ
仕事
DeepSeek Code、まもなくリリースへ
AI技術の進展が加速する中、DeepSeekは今、まさに刺激的な転換点を迎えています。同社は最近、700億元を超える資金調達に成功したことを明らかにしました。経営陣は、目先の商業的利益よりも、画期的なAI研究への取り組みを重視する姿勢を強調しています。この戦略的転換は、新製品、とりわけ待望の「DeepSeek Code」の開発に全力を注ぐというDeepSeekの決意を示しています。DeepSeek
マスク氏の「Grok」:1.5兆のパラメータとカーソルコードの統合――ゲームチェンジャーか、それともブラフか?
イーロン・マスクがついに動き出した。AI開発競争において、OpenAIとAnthropicは加速している一方、xAIは出遅れているようだ。マスクはたびたび「Claude」に対抗する意向を表明してきたが、Grok4.Xシリーズへの度重なるアップデートにもかかわらず、結果は理論上は良好に見えても実用面では不十分であり、その差はほとんど縮まっていない。しかし、今回、彼には新たな切り札がある。マスクはX(
OpenAI、アルトマン氏の解任を困難にするため、密かに定款を変更
2023年のクーデターのような事態を受けて、OpenAIは定款を改定し、サム・アルトマンCEOに対する保護措置をさらに強化した。最近公開された裁判文書によると、アルトマン氏の地位は今や揺るぎないものとなっており、外部からの干渉や、取締役会による解任の動きに対する障壁が大幅に高まっている。イーロン・マスクがOpenAIを相手取った訴訟における専門家証人は、これらの変更が同社が営利モデルへ移行する過程
関連特集おすすめ
仕事
 おすすめのAI採用ツール:履歴書の選考と候補者の面接スケジュール管理を自動化
おすすめのAI採用ツール:履歴書の選考と候補者の面接スケジュール管理を自動化
XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
 10 ツール
10 ツール
 xix.ai
生産性
AIパーソナルウェルネス&集中力コーチ:バーンアウトの予防とメンタルエネルギーの向上
xix.ai
生産性
AIパーソナルウェルネス&集中力コーチ:バーンアウトの予防とメンタルエネルギーの向上
XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
10 ツール
xix.ai
チャットボット
高評価のAI恋愛チャットボット:一貫した個性で長期的な関係を築く
2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai
教育と学習
最高のAIデータサイエンスメンター:SQL、Pandas、および機械学習ワークフローをマスターしましょう
2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai
チャットボット
最高のAIを使ったナンパ&会話トレーニング:社交的な魅力と自信をリアルタイムで高める
XIX.AIで、2026年最高のAIを使った口説き術・会話トレーニングツールを発見しましょう。厳選された高評価のツールが、リアルタイムで社交的な魅力と自信を築くお手伝いをします。無料版と有料版の比較や毎週更新されるランキングを参考に、ぜひ試すべき画期的なツールを探してみてください。今すぐ、あなたの社交力を引き出しましょう。
10 ツール
xix.ai
コード
自動化ユニットテストに最適なAIツール:ワンクリックでJest、PyTest、JUnitのテストケースを生成する
2026年に登場した、自動化ユニットテスト用の最高評価を受けたAIツールを発見してください。当社が厳選したこれらのツールは、Jest、PyTest、JUnitのテストケースを瞬時に生成するための強力で革新的なソリューションです。XIX.AIでは、無料オプションと有料オプションを実際のテストデータと共に比較し、毎週更新されるランキングもご覧いただけます。今すぐAIの力を活用して、開発生産性を向上させましょう。
10 ツール
xix.ai

 コメント (1)
0/500
コメント (1)
0/500
![ThomasMiller]()
Ces avancées en segmentation d'images par commande vocale me font rêver ! 😍 Imaginez pouvoir simplement dire 'montre-moi tous les chiens sur cette photo de parc' et voir la magie opérer. Mais ça soulève aussi des questions sur la vie privée... jusqu'où cette technologie pourrait-elle analyser nos images sans consentement ? 🧐
会話型画像セグメンテーションは、私たちが画像と対話し、画像から意味を抽出する方法を変革します。Gemini 2.5により、ユーザーは自然言語コマンドを活用して、あらゆる画像内のオブジェクトを正確に識別し、分離することができるようになり、新たなレベルの効率性と精度が解放される。このブレークスルーは、デジタルメディアから自律技術まで、業界全体に大きな影響を与えることが期待されます。
キーポイント
Gemini 2.5は、画像セグメンテーションに会話型アプローチを導入し、ユーザーが簡単な言葉でプロセスを指示できるようにします。
これにより、ラベル付けされたカスタムデータセットや特殊なセグメンテーションモデルの開発に対する要求が根本的に取り除かれる。
この機能により、クリエイティブコンテンツ、工業検査、小売、ロボット工学などの分野での新しいアプリケーションが可能になる。
識別された各オブジェクトに対して、Gemini 2.5は、バウンディングボックス座標と詳細なセグメンテーションマスクを含む構造化されたJSON出力を提供する。
システムはリアルタイムで画像を処理し、セグメンテーションするため、複雑なシーンや入り組んだオブジェクトに対しても正確な結果を提供する。
Gemini 2.5のカンバセーショナルイメージセグメンテーションを見る
会話型画像分割の威力
従来の画像セグメンテーションは、手作業によるアノテーション、バウンディングボックス、特定のデータセットでトレーニングされたモデルに依存していました。Gemini 2.5は、画像から特定の要素をピンポイントで抽出するために自然言語の指示を解釈するシステムである会話型画像セグメンテーションによって、これを再定義する。
Gemini 2.5は、自然言語による指示を解釈し、画像から特定の要素をピンポイントで抽出するシステムである。
会話型AIとピクセルパーフェクトの精度。この組み合わせにより、AIはユーザーの意図を正確に理解することができ、カスタムタスクに通常必要とされる大規模なMLトレーニングが不要になる。このプロセスはすべて自然言語によって駆動されるため、専用のトレーニングデータやモデルの微調整は必要ありません。
Gemini 2.5は、不規則な形状や抽象的な記述に対応するために、その文脈理解を使用して、ピクセルレベルの緻密なセグメンテーションを実現します。Gemini 2.5は、複雑な輪郭や関係記述(「最も遠くにいる猫」)を簡単に処理し、カスタムモデルやラベル付けされたデータへの依存を取り除きます。
Gemini 2.5がカスタムトレーニングを排除する方法
Gemini 2.5の大きなブレークスルーは、カスタムトレーニングデータなしで正確なセグメンテーションを実行できることです。新しいGeminiリリースで導入されたこの機能により、ユーザーは画像に関連するあらゆる命令を入力することができる。AIは、説明されたオブジェクトの位置を特定するだけでなく、その正確なピクセルマスクも提供し、形状の複雑さに関係なく、きれいな抽出を可能にする。
従来のセグメンテーションモデルは、大規模で綿密にラベル付けされたデータセットを必要とし、その作成にはコストと時間がかかる。Gemini 2.5は、このハードルを完全に回避する。Gemini 2.5は、事前に訓練された膨大な知識と言語理解力を活用し、ユーザープロンプトから直接画像をセグメンテーションします。
ラベルデータとはおさらばだ。これにより、チームはデータ準備のオーバーヘッドなしに、独自の課題にセグメンテーションを即座に適用することができる。このシステムは、手動でのクリックや描画、複雑なソフトウェア・ツールの代わりに、言葉による説明を解釈して画像内のあらゆるものを選択する。主な利点は、AIが自然言語入力のみで動作するため、カスタム・セグメンテーションに機械学習のトレーニングが必要ないことである。
新しいユースケースに力を与えるドローンから医療画像まで
Gemini 2.5の会話型アプローチは、多様な分野にわたる革新的なアプリケーションを解き放ちます:
- コンテンツ作成:コンテンツ作成: 背景を即座に削除したり、特定の要素にエフェクトを適用したり、簡単なコマンドを使ってダイナミックマスクを生成したりすることができます。
- 品質管理:正しい基準や欠陥の構成要素を口頭で説明することで、欠陥、異常、不適合を特定します。
- 小売分析:在庫の監視、買い物客の行動の分析、店舗レイアウトの最適化を、消費者の洞察のための自然言語を活用した会話型クエリによって実現します。
- 自律システム:ロボットや車両に、自然言語による指示で複雑な視覚環境を解釈する能力を持たせ、知覚と意思決定を強化する。
例えば、Gemini 2.5は、ドローンの映像を分析し、安全な着陸ゾーンを自動的に特定することができる。ユーザーはビデオをアップロードするだけで、ピクセル単位で完璧なセグメンテーションを行い、分析を行うことができる。
ソフトウェアは、ドローンにとって実行可能な着陸区域と危険な着陸区域をすべて正確にマッピングする。
Gemini 2.5のピクセルパーフェクトセグメンテーションによる自律的なドローン着陸帯検出。
さらに、医療用画像処理では、Gemini 2.5は、胸部X線写真をレビューして、潜在的な異常がある領域にフラグを立てるのを支援することができる。分析を導くために自然言語を使用することで、システムの高度な言語理解力により、医療従事者の時間を大幅に節約することができる。
コンピュータビジョンとGemini 2.5の進化
バウンディングボックスから会話による理解へ
コンピュータビジョンは、AIの進歩とともに大きく進化してきた。ジェミニの会話による理解は、基本的な認識を超えて、対話的で言語主導のセグメンテーションへと移行する、新たなフロンティアを示している。
バウンディングボックス:初期のAIシステムは、物体の周囲に長方形のボックスを配置することしかできなかった。
ピクセルパーフェクトな輪郭:その後の進歩により、AIはセグメンテーションによって物体の輪郭を正確にトレースできるようになり、不規則な形状でも正確なマスクを作成できるようになった。
会話による理解:Gemini 2.5では、システムは文脈や説明的なフレーズを理解する。単に「猫」を見つけるのではなく、ユーザーの言語に基づいて「最も遠くにいる猫」を特定することができます。
ジェミニによる新しいAI技術の利点。会話による画像セグメンテーションは、具体的な利点をもたらす。それは、手作業によるクリックや描画、複雑なツールの必要性を排除し、シンプルな自然言語による説明に置き換えることである。このアプローチにより、トレーニングデータの収集やモデルの微調整の負担がなくなります。
Geminiの能力単語のラベルを超えることで、システムはビジュアルデータのより直感的で強力なインターフェースを解き放ちます。Geminiは、以下のようなクエリを得意としています:
- オブジェクトの関係:"傘を持っている人"、"左から3番目の本"、"ブーケの中で一番しおれた花 "など。
- 条件付きロジック:"ベジタリアンの食べ物 "や "座っていない人 "を特定するようなもの。ジェミニ2.5は、このようなニュアンスの属性を理解する。
- 抽象概念:Gemini 2.5の高度なセマンティック知識は、"散らかったエリア "や "チャンス "といったアイデアに基づいたセグメンテーションを可能にし、これまで不可能だったタスクを現実的なものにします。
よくある質問
会話型画像セグメンテーションとは何ですか?
会話型画像セグメンテーションは、AIを搭載したテクノロジーで、ユーザーは手動ツールの代わりに自然言語の指示を使用して、画像内の特定のオブジェクトを識別し、分離することができます。
Gemini 2.5は、従来の画像セグメンテーションとどのように違うのですか?
従来の方法とは異なり、Gemini 2.5は、カスタムトレーニングデータセットや特別なセグメンテーションモデルを必要としません。Gemini 2.5は、事前に訓練された知識と自然言語処理を使用して、純粋にユーザーの説明に基づいて画像をセグメンテーションします。
Gemini 2.5の会話型画像セグメンテーションは、どのような業界にとって有益ですか?
コンテンツ作成、製造品質管理、小売、分析、ロボットや自動運転車のような自律システムの開発など、多くの分野で利益を得ることができます。
Gemini 2.5は、セグメンテーション結果に対してどのような出力フォーマットを提供しますか?
Gemini 2.5は、識別された各オブジェクトのバウンディングボックス座標と詳細なセグメンテーションマスクの両方を含む、構造化されたJSONフォーマットで結果を出力します。
Gemini 2.5は、不規則な形状や抽象的な概念を持つ画像に適していますか?
はい。Gemini 2.5は、深い文脈理解を活用することで、複雑な形状や抽象的な説明を扱うことができるように設計されており、関係用語によって定義された難しい対象に対しても、正確なセグメンテーションを行うことができます。
関連する質問
Gemini 2.5は、コンテンツ作成にどのように適用できますか?
コンテンツ制作者にとって、Gemini 2.5は、迅速な背景除去、ターゲットに合わせたエフェクトの適用、および動的なマスク生成を可能にし、ワークフローを合理化します。この効率化により、クリエイターはクリエイティブなビジョンにより集中することができ、Photoshopのようなツールを補完することができます。
Gemini 2.5は、品質管理においてどのような役割を果たしますか?
品質管理では、検査担当者が、正しい製品やコンポーネントがどのように見えるべきかを口頭で定義することで、欠陥や逸脱を検出することができます。これは、ピクセルパーフェクトなセグメンテーション精度により、大規模な欠陥データベースを作成する必要なく、一貫した品質を保証します。
Gemini 2.5は、小売分析をどのように向上させますか?
Gemini 2.5は、在庫追跡、顧客行動分析、およびシンプルな会話型クエリによる棚レイアウトの最適化を可能にすることで、小売分析を強化します。このデータ駆動型のアプローチにより、小売業者はAIを活用した洞察によって顧客体験を改善し、売上を向上させることができます。
Gemini 2.5は、どのような点で自律システムを強化することができますか?
Gemini 2.5は、ロボットや車両が自然言語コマンドによって複雑なビジュアルシーンを解釈できるようにすることで、自律システムを強化します。アプリケーションは、ドローンの安全な着陸ゾーンの特定から自動運転車の歩行者の認識まで多岐にわたり、開発時間とコストを削減しながら、安全性と運用効率の両方を向上させます。










 DeepSeek Code、まもなくリリースへ
AI技術の進展が加速する中、DeepSeekは今、まさに刺激的な転換点を迎えています。同社は最近、700億元を超える資金調達に成功したことを明らかにしました。経営陣は、目先の商業的利益よりも、画期的なAI研究への取り組みを重視する姿勢を強調しています。この戦略的転換は、新製品、とりわけ待望の「DeepSeek Code」の開発に全力を注ぐというDeepSeekの決意を示しています。DeepSeek
DeepSeek Code、まもなくリリースへ
AI技術の進展が加速する中、DeepSeekは今、まさに刺激的な転換点を迎えています。同社は最近、700億元を超える資金調達に成功したことを明らかにしました。経営陣は、目先の商業的利益よりも、画期的なAI研究への取り組みを重視する姿勢を強調しています。この戦略的転換は、新製品、とりわけ待望の「DeepSeek Code」の開発に全力を注ぐというDeepSeekの決意を示しています。DeepSeek
 マスク氏の「Grok」:1.5兆のパラメータとカーソルコードの統合――ゲームチェンジャーか、それともブラフか?
イーロン・マスクがついに動き出した。AI開発競争において、OpenAIとAnthropicは加速している一方、xAIは出遅れているようだ。マスクはたびたび「Claude」に対抗する意向を表明してきたが、Grok4.Xシリーズへの度重なるアップデートにもかかわらず、結果は理論上は良好に見えても実用面では不十分であり、その差はほとんど縮まっていない。しかし、今回、彼には新たな切り札がある。マスクはX(
マスク氏の「Grok」:1.5兆のパラメータとカーソルコードの統合――ゲームチェンジャーか、それともブラフか?
イーロン・マスクがついに動き出した。AI開発競争において、OpenAIとAnthropicは加速している一方、xAIは出遅れているようだ。マスクはたびたび「Claude」に対抗する意向を表明してきたが、Grok4.Xシリーズへの度重なるアップデートにもかかわらず、結果は理論上は良好に見えても実用面では不十分であり、その差はほとんど縮まっていない。しかし、今回、彼には新たな切り札がある。マスクはX(
 OpenAI、アルトマン氏の解任を困難にするため、密かに定款を変更
2023年のクーデターのような事態を受けて、OpenAIは定款を改定し、サム・アルトマンCEOに対する保護措置をさらに強化した。最近公開された裁判文書によると、アルトマン氏の地位は今や揺るぎないものとなっており、外部からの干渉や、取締役会による解任の動きに対する障壁が大幅に高まっている。イーロン・マスクがOpenAIを相手取った訴訟における専門家証人は、これらの変更が同社が営利モデルへ移行する過程
OpenAI、アルトマン氏の解任を困難にするため、密かに定款を変更
2023年のクーデターのような事態を受けて、OpenAIは定款を改定し、サム・アルトマンCEOに対する保護措置をさらに強化した。最近公開された裁判文書によると、アルトマン氏の地位は今や揺るぎないものとなっており、外部からの干渉や、取締役会による解任の動きに対する障壁が大幅に高まっている。イーロン・マスクがOpenAIを相手取った訴訟における専門家証人は、これらの変更が同社が営利モデルへ移行する過程

XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
10 ツール
xix.ai

XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
10 ツール
xix.ai

2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai

2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAIを使った口説き術・会話トレーニングツールを発見しましょう。厳選された高評価のツールが、リアルタイムで社交的な魅力と自信を築くお手伝いをします。無料版と有料版の比較や毎週更新されるランキングを参考に、ぜひ試すべき画期的なツールを探してみてください。今すぐ、あなたの社交力を引き出しましょう。
10 ツール
xix.ai

2026年に登場した、自動化ユニットテスト用の最高評価を受けたAIツールを発見してください。当社が厳選したこれらのツールは、Jest、PyTest、JUnitのテストケースを瞬時に生成するための強力で革新的なソリューションです。XIX.AIでは、無料オプションと有料オプションを実際のテストデータと共に比較し、毎週更新されるランキングもご覧いただけます。今すぐAIの力を活用して、開発生産性を向上させましょう。
10 ツール
xix.ai

Ces avancées en segmentation d'images par commande vocale me font rêver ! 😍 Imaginez pouvoir simplement dire 'montre-moi tous les chiens sur cette photo de parc' et voir la magie opérer. Mais ça soulève aussi des questions sur la vie privée... jusqu'où cette technologie pourrait-elle analyser nos images sans consentement ? 🧐













