




Découvrir nos «visites cachées» avec des données de téléphone portable et un apprentissage automatique
Si vous vous êtes déjà demandé comment les chercheurs suivent nos déplacements à travers un pays sans se fier uniquement aux appels téléphoniques, une étude fascinante menée par des chercheurs de Chine et des États-Unis apporte un éclairage. Leur travail collaboratif explore l’utilisation de l’apprentissage automatique pour révéler les « visites cachées » que nous effectuons — ces trajets qui n’apparaissent pas dans les données télécom standard car nous utilisons trop peu nos téléphones.
L’étude, intitulée **Identification des visites cachées à partir de données de registre d’appels sparse**, est dirigée par Zhan Zhao de l’Université de Hong Kong, aux côtés de Haris N. Koutsopoulos de l’Université Northeastern de Boston et Jinhua Zhao du MIT. Leur objectif ? Exploiter les enregistrements de connectivité mobile — tels que les données mobiles, SMS et appels vocaux — des utilisateurs très actifs pour modéliser et prédire les schémas de déplacement de ceux qui utilisent moins fréquemment leur téléphone.
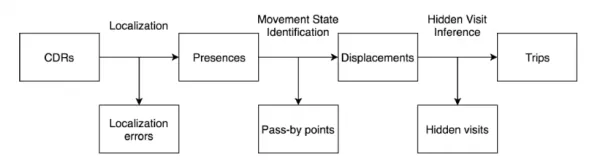 *Schéma approximatif pour extraire les informations de trajet à partir des données de registre d’appels (CDR).* Source : https://arxiv.org/pdf/2106.12885.pdf
*Schéma approximatif pour extraire les informations de trajet à partir des données de registre d’appels (CDR).* Source : https://arxiv.org/pdf/2106.12885.pdf
Bien que l’équipe reconnaisse les préoccupations potentielles en matière de confidentialité soulevées par leur travail, elle souligne que leur objectif est de comprendre de manière générale les schémas de déplacement, plutôt que de se concentrer sur les trajets individuels. Ils notent également que les données de registre d’appels (CDR), qui forment la base de telles études, ont leurs limites. Elles manquent souvent de résolution spatiale et sont sujettes au « bruit de positionnement » dû aux changements de position de l’utilisateur par rapport aux tours de téléphonie. Cependant, ils soutiennent que cette inexactitude sert de sauvegarde pour la confidentialité :
**« L’application cible de notre étude est la détection de trajets et l’estimation OD$$ \* $$, réalisées à un niveau agrégé, et non individuel. Les modèles développés peuvent être directement déployés sur les serveurs de bases de données des opérateurs télécom, sans besoin de transfert de données. De plus, comparées à d’autres formes de big data, comme les données de réseaux sociaux ou de transactions par carte de crédit, les données CDR sont relativement moins intrusives en termes de confidentialité personnelle. En outre, leur erreur de localisation aide à masquer les emplacements exacts des utilisateurs, offrant une couche supplémentaire de protection de la confidentialité. »**
Intervalles de temps écoulés (ETIs)
Lorsque nous nous déplaçons avec nos téléphones mobiles, pas nécessairement des smartphones, les limites des données CDR comme outil pour localiser précisément notre position deviennent évidentes. Les intervalles de temps écoulés (ETIs), ces périodes pendant un trajet où nous ne passons ni ne recevons d’appels, sont des marqueurs cruciaux pour suivre nos déplacements. Ces intervalles de « silence » peuvent nous faire temporairement disparaître du réseau.
Les chercheurs soulignent comment ces écarts perturbent les systèmes analytiques essayant de comprendre les trajets A>B. La rareté des données peut cacher un « trajet non observé ». Leur nouvelle méthode aborde cela en analysant le contexte spatiotemporel des ETIs et en tenant compte des « caractéristiques individuelles de l’utilisateur ».
Jeu de données
Pour constituer leur ensemble d’entraînement principal, les chercheurs ont utilisé les données d’un grand opérateur de services cellulaires dans une ville chinoise de 6 millions d’habitants. Cet ensemble de données comprenait plus de deux milliards de transactions de téléphones mobiles de trois millions d’utilisateurs en novembre 2013, se concentrant uniquement sur les appels vocaux et les enregistrements d’accès aux données. Notamment, ils n’ont pas inclus les données SMS, ce qui a ajouté au défi de traiter des données sparse.
Les données incluaient un identifiant unique crypté, un code de zone de localisation (LAC), un horodatage, un identifiant de tour de téléphonie lié au LAC pour identifier la tour spécifique impliquée dans la transaction, et un identifiant d’événement indiquant s’il s’agissait d’un appel entrant/sortant ou d’une utilisation de données.
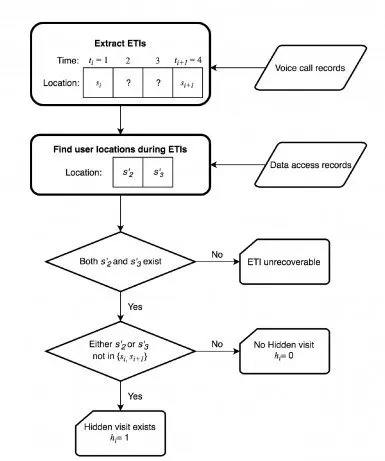 *Arbre de processus pour l’identification des visites cachées.*
*Arbre de processus pour l’identification des visites cachées.*
Ces informations ont été croisées avec une base de données d’opérations des tours cellulaires, permettant aux chercheurs de localiser les coordonnées de longitude et de latitude de la tour associée à chaque événement de communication. Ils ont identifié 9000 tours cellulaires dans l’ensemble de données.
Les chercheurs ont noté la difficulté à deviner précisément les destinations des trajets en se basant uniquement sur les enregistrements d’appels, car ces enregistrements culminent le matin et l’après-midi, ce qui correspond aux schémas de déplacement typiques. Puisque les appels téléphoniques peuvent précéder un trajet et même le déclencher, cela peut fausser l’estimation de la destination.
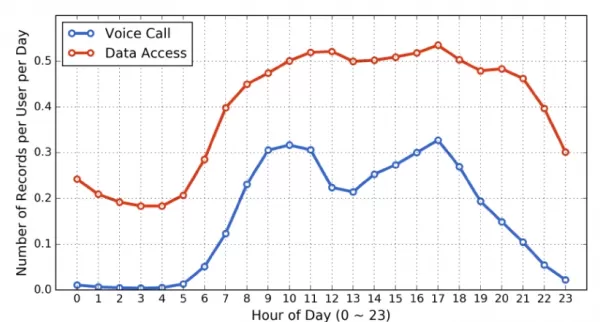 *Schémas d’utilisation mobile au cours d’une journée.*
*Schémas d’utilisation mobile au cours d’une journée.*
Des défis similaires se posent avec l’utilisation de données initiée par l’utilisateur, comme les applications de messagerie. Cependant, c’est l’utilisation de données « automatisée » — comme l’interrogation systématique des API pour de nouveaux messages ou autres données, y compris le GPS et la télémétrie à travers les applications — qui aide à identifier ces mouvements cachés.
Traitement
Les chercheurs ont utilisé divers classificateurs d’apprentissage automatique pour résoudre ce problème, y compris la régression logistique, les machines à vecteurs de support (SVM), les forêts aléatoires et une approche d’ensemble par boosting de gradient. Ceux-ci ont été implémentés en Python à l’aide de scikit-learn avec les paramètres par défaut.
Parmi ceux-ci, la régression logistique a fourni les paramètres de modèle les plus interprétables. L’équipe a également constaté que des ETIs plus longs augmentaient la probabilité qu’une visite cachée se produise, avec une incidence plus élevée le matin. À l’inverse, lorsque les données CDR d’un utilisateur montraient clairement un grand nombre de destinations ou de points de passage, la probabilité d’une visite cachée était plus faible. Cette constatation soutient le principe central de leur recherche — que les utilisateurs les plus actifs fournissent une image détaillée de leurs déplacements, à partir de laquelle le comportement des utilisateurs moins actifs peut être inféré.
Dans leur conclusion, les chercheurs suggèrent que leur approche pourrait être appliquée à d’autres types de données de transport, telles que les données de cartes intelligentes et les informations de réseaux sociaux géolocalisées.
La recherche a été soutenue par des financements de la Energy Foundation China et du China Sustainable Transportation Center.
*\* Origine-Destination*
Article connexe
 Google Cloud permet des avancées dans le domaine de la recherche et de la découverte scientifiques
La révolution numérique transforme les méthodologies scientifiques grâce à des capacités de calcul sans précédent. Les technologies de pointe renforcent désormais les cadres théoriques et les expérien
L'IA accélère la recherche scientifique pour un meilleur impact dans le monde réel
Google n'a cessé d'exploiter l'IA comme catalyseur du progrès scientifique, le rythme des découvertes atteignant aujourd'hui des niveaux extraordinaires. Cette accélération a transformé le cycle de la
L'éthique dans l'IA : relever les défis de l'automatisation en matière de partialité et de conformité
À mesure que l'automatisation s'implante profondément dans les industries, les considérations éthiques deviennent des priorités essentielles. Les algorithmes décisionnels influencent désormais des asp
commentaires (17)
0/200
Google Cloud permet des avancées dans le domaine de la recherche et de la découverte scientifiques
La révolution numérique transforme les méthodologies scientifiques grâce à des capacités de calcul sans précédent. Les technologies de pointe renforcent désormais les cadres théoriques et les expérien
L'IA accélère la recherche scientifique pour un meilleur impact dans le monde réel
Google n'a cessé d'exploiter l'IA comme catalyseur du progrès scientifique, le rythme des découvertes atteignant aujourd'hui des niveaux extraordinaires. Cette accélération a transformé le cycle de la
L'éthique dans l'IA : relever les défis de l'automatisation en matière de partialité et de conformité
À mesure que l'automatisation s'implante profondément dans les industries, les considérations éthiques deviennent des priorités essentielles. Les algorithmes décisionnels influencent désormais des asp
commentaires (17)
0/200
![KennethWalker]() KennethWalker
KennethWalker
 10 août 2025 13:01:00 UTC+02:00
10 août 2025 13:01:00 UTC+02:00
This study on tracking movements with phone data is wild! 😲 It’s like our phones are secretly spilling where we’ve been. Kinda creepy, but super cool how machine learning digs into those 'hidden visits.' Makes me wonder what else they can find out!


 0
0
![JuanLewis]() JuanLewis
1 août 2025 15:47:34 UTC+02:00
JuanLewis
1 août 2025 15:47:34 UTC+02:00
This article blew my mind! Using phone data and ML to track hidden visits is so cool, but kinda creepy too. 🤯 Wonder how they balance privacy with all this tech wizardry.
0
![RalphSanchez]() RalphSanchez
24 avril 2025 06:36:16 UTC+02:00
RalphSanchez
24 avril 2025 06:36:16 UTC+02:00
이 도구는 정말 놀랍습니다! 내 이동을 추적하는 데 유용하지만 조금 무섭기도 해요. 데이터를 삭제할 수 있는 옵션이 있으면 좋겠어요. 😓
0
![MatthewScott]() MatthewScott
23 avril 2025 23:35:24 UTC+02:00
MatthewScott
23 avril 2025 23:35:24 UTC+02:00
¡Esta herramienta es alucinante! Es como tener un detective en mi bolsillo, descubriendo todos esos viajes secretos que nunca supe. Muy útil para rastrear mis propios movimientos, pero un poco espeluznante también. ¿Quizás deberían añadir una opción para eliminar datos? 🤔
0
![RalphHill]() RalphHill
23 avril 2025 22:51:52 UTC+02:00
RalphHill
23 avril 2025 22:51:52 UTC+02:00
Este estudo sobre 'visitas ocultas' usando dados de celular e aprendizado de máquina é impressionante! É fascinante como eles podem rastrear movimentos com tanta precisão. Mas também é um pouco assustador, não é? 🤔📱
0
![WilliamMiller]() WilliamMiller
23 avril 2025 13:05:02 UTC+02:00
WilliamMiller
23 avril 2025 13:05:02 UTC+02:00
Essa ferramenta é incrível! Parece que tenho um detetive no meu bolso, descobrindo todas aquelas viagens secretas que eu nunca soube. Muito útil para rastrear meus próprios movimentos, mas um pouco assustador também. Talvez eles devam adicionar uma opção para excluir dados? 🤔
0
Si vous vous êtes déjà demandé comment les chercheurs suivent nos déplacements à travers un pays sans se fier uniquement aux appels téléphoniques, une étude fascinante menée par des chercheurs de Chine et des États-Unis apporte un éclairage. Leur travail collaboratif explore l’utilisation de l’apprentissage automatique pour révéler les « visites cachées » que nous effectuons — ces trajets qui n’apparaissent pas dans les données télécom standard car nous utilisons trop peu nos téléphones.
L’étude, intitulée **Identification des visites cachées à partir de données de registre d’appels sparse**, est dirigée par Zhan Zhao de l’Université de Hong Kong, aux côtés de Haris N. Koutsopoulos de l’Université Northeastern de Boston et Jinhua Zhao du MIT. Leur objectif ? Exploiter les enregistrements de connectivité mobile — tels que les données mobiles, SMS et appels vocaux — des utilisateurs très actifs pour modéliser et prédire les schémas de déplacement de ceux qui utilisent moins fréquemment leur téléphone.
*Schéma approximatif pour extraire les informations de trajet à partir des données de registre d’appels (CDR).* Source : https://arxiv.org/pdf/2106.12885.pdf
Bien que l’équipe reconnaisse les préoccupations potentielles en matière de confidentialité soulevées par leur travail, elle souligne que leur objectif est de comprendre de manière générale les schémas de déplacement, plutôt que de se concentrer sur les trajets individuels. Ils notent également que les données de registre d’appels (CDR), qui forment la base de telles études, ont leurs limites. Elles manquent souvent de résolution spatiale et sont sujettes au « bruit de positionnement » dû aux changements de position de l’utilisateur par rapport aux tours de téléphonie. Cependant, ils soutiennent que cette inexactitude sert de sauvegarde pour la confidentialité :
**« L’application cible de notre étude est la détection de trajets et l’estimation OD$$ \* $$, réalisées à un niveau agrégé, et non individuel. Les modèles développés peuvent être directement déployés sur les serveurs de bases de données des opérateurs télécom, sans besoin de transfert de données. De plus, comparées à d’autres formes de big data, comme les données de réseaux sociaux ou de transactions par carte de crédit, les données CDR sont relativement moins intrusives en termes de confidentialité personnelle. En outre, leur erreur de localisation aide à masquer les emplacements exacts des utilisateurs, offrant une couche supplémentaire de protection de la confidentialité. »**
Intervalles de temps écoulés (ETIs)
Lorsque nous nous déplaçons avec nos téléphones mobiles, pas nécessairement des smartphones, les limites des données CDR comme outil pour localiser précisément notre position deviennent évidentes. Les intervalles de temps écoulés (ETIs), ces périodes pendant un trajet où nous ne passons ni ne recevons d’appels, sont des marqueurs cruciaux pour suivre nos déplacements. Ces intervalles de « silence » peuvent nous faire temporairement disparaître du réseau.
Les chercheurs soulignent comment ces écarts perturbent les systèmes analytiques essayant de comprendre les trajets A>B. La rareté des données peut cacher un « trajet non observé ». Leur nouvelle méthode aborde cela en analysant le contexte spatiotemporel des ETIs et en tenant compte des « caractéristiques individuelles de l’utilisateur ».
Jeu de données
Pour constituer leur ensemble d’entraînement principal, les chercheurs ont utilisé les données d’un grand opérateur de services cellulaires dans une ville chinoise de 6 millions d’habitants. Cet ensemble de données comprenait plus de deux milliards de transactions de téléphones mobiles de trois millions d’utilisateurs en novembre 2013, se concentrant uniquement sur les appels vocaux et les enregistrements d’accès aux données. Notamment, ils n’ont pas inclus les données SMS, ce qui a ajouté au défi de traiter des données sparse.
Les données incluaient un identifiant unique crypté, un code de zone de localisation (LAC), un horodatage, un identifiant de tour de téléphonie lié au LAC pour identifier la tour spécifique impliquée dans la transaction, et un identifiant d’événement indiquant s’il s’agissait d’un appel entrant/sortant ou d’une utilisation de données.
*Arbre de processus pour l’identification des visites cachées.*
Ces informations ont été croisées avec une base de données d’opérations des tours cellulaires, permettant aux chercheurs de localiser les coordonnées de longitude et de latitude de la tour associée à chaque événement de communication. Ils ont identifié 9000 tours cellulaires dans l’ensemble de données.
Les chercheurs ont noté la difficulté à deviner précisément les destinations des trajets en se basant uniquement sur les enregistrements d’appels, car ces enregistrements culminent le matin et l’après-midi, ce qui correspond aux schémas de déplacement typiques. Puisque les appels téléphoniques peuvent précéder un trajet et même le déclencher, cela peut fausser l’estimation de la destination.
*Schémas d’utilisation mobile au cours d’une journée.*
Des défis similaires se posent avec l’utilisation de données initiée par l’utilisateur, comme les applications de messagerie. Cependant, c’est l’utilisation de données « automatisée » — comme l’interrogation systématique des API pour de nouveaux messages ou autres données, y compris le GPS et la télémétrie à travers les applications — qui aide à identifier ces mouvements cachés.
Traitement
Les chercheurs ont utilisé divers classificateurs d’apprentissage automatique pour résoudre ce problème, y compris la régression logistique, les machines à vecteurs de support (SVM), les forêts aléatoires et une approche d’ensemble par boosting de gradient. Ceux-ci ont été implémentés en Python à l’aide de scikit-learn avec les paramètres par défaut.
Parmi ceux-ci, la régression logistique a fourni les paramètres de modèle les plus interprétables. L’équipe a également constaté que des ETIs plus longs augmentaient la probabilité qu’une visite cachée se produise, avec une incidence plus élevée le matin. À l’inverse, lorsque les données CDR d’un utilisateur montraient clairement un grand nombre de destinations ou de points de passage, la probabilité d’une visite cachée était plus faible. Cette constatation soutient le principe central de leur recherche — que les utilisateurs les plus actifs fournissent une image détaillée de leurs déplacements, à partir de laquelle le comportement des utilisateurs moins actifs peut être inféré.
Dans leur conclusion, les chercheurs suggèrent que leur approche pourrait être appliquée à d’autres types de données de transport, telles que les données de cartes intelligentes et les informations de réseaux sociaux géolocalisées.
La recherche a été soutenue par des financements de la Energy Foundation China et du China Sustainable Transportation Center.
*\* Origine-Destination*










 Google Cloud permet des avancées dans le domaine de la recherche et de la découverte scientifiques
La révolution numérique transforme les méthodologies scientifiques grâce à des capacités de calcul sans précédent. Les technologies de pointe renforcent désormais les cadres théoriques et les expérien
Google Cloud permet des avancées dans le domaine de la recherche et de la découverte scientifiques
La révolution numérique transforme les méthodologies scientifiques grâce à des capacités de calcul sans précédent. Les technologies de pointe renforcent désormais les cadres théoriques et les expérien
 L'IA accélère la recherche scientifique pour un meilleur impact dans le monde réel
Google n'a cessé d'exploiter l'IA comme catalyseur du progrès scientifique, le rythme des découvertes atteignant aujourd'hui des niveaux extraordinaires. Cette accélération a transformé le cycle de la
L'éthique dans l'IA : relever les défis de l'automatisation en matière de partialité et de conformité
À mesure que l'automatisation s'implante profondément dans les industries, les considérations éthiques deviennent des priorités essentielles. Les algorithmes décisionnels influencent désormais des asp
10 août 2025 13:01:00 UTC+02:00
L'IA accélère la recherche scientifique pour un meilleur impact dans le monde réel
Google n'a cessé d'exploiter l'IA comme catalyseur du progrès scientifique, le rythme des découvertes atteignant aujourd'hui des niveaux extraordinaires. Cette accélération a transformé le cycle de la
L'éthique dans l'IA : relever les défis de l'automatisation en matière de partialité et de conformité
À mesure que l'automatisation s'implante profondément dans les industries, les considérations éthiques deviennent des priorités essentielles. Les algorithmes décisionnels influencent désormais des asp
10 août 2025 13:01:00 UTC+02:00
This study on tracking movements with phone data is wild! 😲 It’s like our phones are secretly spilling where we’ve been. Kinda creepy, but super cool how machine learning digs into those 'hidden visits.' Makes me wonder what else they can find out!
0
1 août 2025 15:47:34 UTC+02:00
This article blew my mind! Using phone data and ML to track hidden visits is so cool, but kinda creepy too. 🤯 Wonder how they balance privacy with all this tech wizardry.
0
24 avril 2025 06:36:16 UTC+02:00
이 도구는 정말 놀랍습니다! 내 이동을 추적하는 데 유용하지만 조금 무섭기도 해요. 데이터를 삭제할 수 있는 옵션이 있으면 좋겠어요. 😓
0
23 avril 2025 23:35:24 UTC+02:00
¡Esta herramienta es alucinante! Es como tener un detective en mi bolsillo, descubriendo todos esos viajes secretos que nunca supe. Muy útil para rastrear mis propios movimientos, pero un poco espeluznante también. ¿Quizás deberían añadir una opción para eliminar datos? 🤔
0
23 avril 2025 22:51:52 UTC+02:00
Este estudo sobre 'visitas ocultas' usando dados de celular e aprendizado de máquina é impressionante! É fascinante como eles podem rastrear movimentos com tanta precisão. Mas também é um pouco assustador, não é? 🤔📱
0
23 avril 2025 13:05:02 UTC+02:00
Essa ferramenta é incrível! Parece que tenho um detetive no meu bolso, descobrindo todas aquelas viagens secretas que eu nunca soube. Muito útil para rastrear meus próprios movimentos, mas um pouco assustador também. Talvez eles devam adicionar uma opção para excluir dados? 🤔
0













