
















 Maison
Maison
HydraDB lève 6,5 millions de dollars pour une avancée majeure dans le domaine du stockage de mémoire pour l'IA
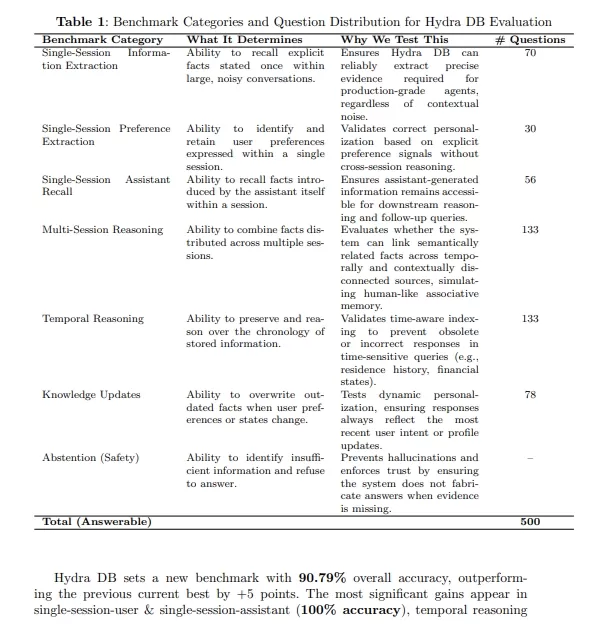
Récemment, le secteur des technologies de mémoire pour l'IA a fait l'objet d'une annonce importante en matière de financement. HydraDB a réussi à lever 6,5 millions de dollars. Le projet affiche ouvertement l'objectif de surpasser les bases de données vectorielles traditionnelles, en proposant une amélioration complète des capacités de mémoire à long terme de l'IA. Par rapport aux solutions courantes actuelles, HydraDB utilise une architecture novatrice conçue pour s'attaquer de manière fondamentale au défi central du secteur : « la similarité n'est pas synonyme de pertinence ».
La faille critique des bases de données vectorielles : similitude ≠ pertinence
L'approche dominante en matière de mémoire IA consiste à segmenter le contenu des conversations et à le stocker dans des bases de données vectorielles, en s'appuyant sur la recherche par similarité pour la récupération. Bien que cette méthode semble efficace, elle s'avère souvent insuffisante dans les applications pratiques.
Des cas concrets illustrent le problème : lorsqu'on lui demande de récupérer un contrat spécifique, une IA peut renvoyer un document parfaitement formaté, mais qui appartient à un client totalement différent. Bien que la recherche par similarité trouve un contenu « similaire », elle passe à côté de la pertinence contextuelle essentielle, ce qui entraîne des inexactitudes significatives dans les résultats de l'IA.
L'approche révolutionnaire d'HydraDB : graphe de relations + gestion des versions de type Git
HydraDB s'éloigne du stockage fragmenté pour construire à la place un graphe de relations intelligent qui aligne plus étroitement la mémoire de l'IA sur la logique humaine. Son innovation principale repose sur trois avancées clés :
Pas de fragments, seulement des relations
Le système évite de stocker les informations sous forme de fragments isolés, mais capture plutôt les relations entre les entités. Il peut établir avec précision le lien entre « vous travaillez dans l’entreprise A » et « vous vivez à New York » comme faisant partie du profil d’une même personne, plutôt que de les traiter comme des faits distincts et sans rapport.
Mises à jour en mode « ajout seul », inspirées de Git
Lorsque les informations d'un utilisateur changent, HydraDB ne se contente pas de remplacer les anciennes données. Il adopte un modèle d'ajout uniquement, similaire au contrôle de version de Git. Si un utilisateur déménage, son ancienne adresse est conservée dans l'historique, et le système garde le contexte du changement, empêchant ainsi la perte définitive des informations historiques.
Entrées de mémoire sensibles au contexte
Chaque souvenir est stocké avec un contexte riche et intelligent. Par exemple, si un utilisateur déclare : « Je n'aime pas ce framework », le système contextualise intelligemment cette déclaration en « l'utilisateur n'aime pas React ». Cela garantit une compréhension précise lors des conversations IA suivantes sans nécessiter de clarification manuelle.
L'aube d'une révolution de la mémoire IA
Les observateurs du secteur notent que l'innovation d'HydraDB s'attaque directement aux limites structurelles des bases de données vectorielles. Elle est sur le point d'apporter un bond en avant transformateur pour les assistants IA, les bases de connaissances personnelles et les systèmes RAG d'entreprise. AIbase continuera à suivre les développements de produits et les progrès technologiques d'HydraDB — restez à l'écoute pour d'autres mises à jour révolutionnaires.
Lien vers l'article : https://research.hydradb.com/cortex.pdf
Article connexe
 Xiaohongshu se restructure : Conan nommé président, création d'un département dédié à l'IA et d'une division internationale Rednote
Le 30 avril, Xiaohongshu a adressé une note interne à l'ensemble de ses employés pour annoncer le lancement d'une nouvelle restructuration organisationnelle. Au cœur de cette évolution figure l'intégr
Le jeu « Xiaolongxia » de Tencent dépasse toutes les attentes ; l'équipe multiplie par dix sa capacité, présente ses excuses et offre des compensations
Tencent a officiellement lancé WorkBuddy, un agent intelligent basé sur l'IA et adapté à tous les contextes, marquant ainsi une nouvelle étape dans la course aux applications des grands modèles, carac
Principal investisseur de Suno : la suppression des publications ne comblera pas les lacunes en matière de poursuites pour violation du droit d'auteur
La plateforme de génération musicale par IA très attendue, Suno, est confrontée à une rude bataille en matière de droits d'auteur, et une remarque sans détours de son principal investisseur pourrait b
Recommandations de sujets spéciaux liés
Création de bande dessinée
Xiaohongshu se restructure : Conan nommé président, création d'un département dédié à l'IA et d'une division internationale Rednote
Le 30 avril, Xiaohongshu a adressé une note interne à l'ensemble de ses employés pour annoncer le lancement d'une nouvelle restructuration organisationnelle. Au cœur de cette évolution figure l'intégr
Le jeu « Xiaolongxia » de Tencent dépasse toutes les attentes ; l'équipe multiplie par dix sa capacité, présente ses excuses et offre des compensations
Tencent a officiellement lancé WorkBuddy, un agent intelligent basé sur l'IA et adapté à tous les contextes, marquant ainsi une nouvelle étape dans la course aux applications des grands modèles, carac
Principal investisseur de Suno : la suppression des publications ne comblera pas les lacunes en matière de poursuites pour violation du droit d'auteur
La plateforme de génération musicale par IA très attendue, Suno, est confrontée à une rude bataille en matière de droits d'auteur, et une remarque sans détours de son principal investisseur pourrait b
Recommandations de sujets spéciaux liés
Création de bande dessinée
 Les meilleurs générateurs IA pour les mangas shonen : créez des séquences d'action survoltées et des effets d'énergie
Les meilleurs générateurs IA pour les mangas shonen : créez des séquences d'action survoltées et des effets d'énergie
Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
 15 outils
15 outils
 xix.ai
Entreprise
Les meilleurs outils de suivi des dépenses basés sur l'IA : numérisez vos reçus et classez automatiquement les dépenses de l'entreprise
xix.ai
Entreprise
Les meilleurs outils de suivi des dépenses basés sur l'IA : numérisez vos reçus et classez automatiquement les dépenses de l'entreprise
Les meilleurs outils de gestion des dépenses basés sur l'IA en 2026 : les outils les mieux notés pour numériser vos reçus et classer automatiquement les dépenses de votre entreprise. Découvrez des solutions puissantes et révolutionnaires pour une gestion des dépenses sans effort, un suivi financier précis et une conformité simplifiée. Notre comparatif, mis à jour chaque semaine, qui oppose les options gratuites aux options payantes, vous aide à trouver la solution qui vous convient le mieux. Tirez pleinement parti de l'IA grâce aux recommandations d'experts de XIX.AI.
10 outils
xix.ai
Entreprise
Les meilleurs outils de recrutement basés sur l'IA : triez les CV et automatisez la planification des entretiens avec les candidats
Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
10 outils
xix.ai
Productivité
Coaches IA dédiés au bien-être et à la concentration : gérer l'épuisement professionnel et booster son énergie mentale
Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai
chatbot
Les meilleurs chatbots romantiques basés sur l'IA : nouez des relations durables grâce à des personnalités cohérentes
Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
10 outils
xix.ai
Éducation et apprentissage
Meilleurs mentors en science des données et intelligence artificielle : maîtrise de SQL, Pandas et des workflows d'apprentissage automatique
Découvrez les meilleurs mentors en sciences des données et en intelligence artificielle pour 2026 afin de maîtriser SQL, Pandas et les workflows d'apprentissage automatique. Explorez notre sélection soigneusement élaborée sur XIX.AI pour bénéficier d'une guidance puissante et révolutionnaire. Comparez les options gratuites et payantes en tenant compte de perspectives pratiques. Développez rapidement vos compétences en sciences des données.
10 outils
xix.ai

 commentaires (0)
commentaires (0)
Récemment, le secteur des technologies de mémoire pour l'IA a fait l'objet d'une annonce importante en matière de financement. HydraDB a réussi à lever 6,5 millions de dollars. Le projet affiche ouvertement l'objectif de surpasser les bases de données vectorielles traditionnelles, en proposant une amélioration complète des capacités de mémoire à long terme de l'IA. Par rapport aux solutions courantes actuelles, HydraDB utilise une architecture novatrice conçue pour s'attaquer de manière fondamentale au défi central du secteur : « la similarité n'est pas synonyme de pertinence ».
La faille critique des bases de données vectorielles : similitude ≠ pertinence
L'approche dominante en matière de mémoire IA consiste à segmenter le contenu des conversations et à le stocker dans des bases de données vectorielles, en s'appuyant sur la recherche par similarité pour la récupération. Bien que cette méthode semble efficace, elle s'avère souvent insuffisante dans les applications pratiques.
Des cas concrets illustrent le problème : lorsqu'on lui demande de récupérer un contrat spécifique, une IA peut renvoyer un document parfaitement formaté, mais qui appartient à un client totalement différent. Bien que la recherche par similarité trouve un contenu « similaire », elle passe à côté de la pertinence contextuelle essentielle, ce qui entraîne des inexactitudes significatives dans les résultats de l'IA.
L'approche révolutionnaire d'HydraDB : graphe de relations + gestion des versions de type Git
HydraDB s'éloigne du stockage fragmenté pour construire à la place un graphe de relations intelligent qui aligne plus étroitement la mémoire de l'IA sur la logique humaine. Son innovation principale repose sur trois avancées clés :
Pas de fragments, seulement des relations
Le système évite de stocker les informations sous forme de fragments isolés, mais capture plutôt les relations entre les entités. Il peut établir avec précision le lien entre « vous travaillez dans l’entreprise A » et « vous vivez à New York » comme faisant partie du profil d’une même personne, plutôt que de les traiter comme des faits distincts et sans rapport.
Mises à jour en mode « ajout seul », inspirées de Git
Lorsque les informations d'un utilisateur changent, HydraDB ne se contente pas de remplacer les anciennes données. Il adopte un modèle d'ajout uniquement, similaire au contrôle de version de Git. Si un utilisateur déménage, son ancienne adresse est conservée dans l'historique, et le système garde le contexte du changement, empêchant ainsi la perte définitive des informations historiques.
Entrées de mémoire sensibles au contexte
Chaque souvenir est stocké avec un contexte riche et intelligent. Par exemple, si un utilisateur déclare : « Je n'aime pas ce framework », le système contextualise intelligemment cette déclaration en « l'utilisateur n'aime pas React ». Cela garantit une compréhension précise lors des conversations IA suivantes sans nécessiter de clarification manuelle.
L'aube d'une révolution de la mémoire IA
Les observateurs du secteur notent que l'innovation d'HydraDB s'attaque directement aux limites structurelles des bases de données vectorielles. Elle est sur le point d'apporter un bond en avant transformateur pour les assistants IA, les bases de connaissances personnelles et les systèmes RAG d'entreprise. AIbase continuera à suivre les développements de produits et les progrès technologiques d'HydraDB — restez à l'écoute pour d'autres mises à jour révolutionnaires.
Lien vers l'article : https://research.hydradb.com/cortex.pdf










 Xiaohongshu se restructure : Conan nommé président, création d'un département dédié à l'IA et d'une division internationale Rednote
Le 30 avril, Xiaohongshu a adressé une note interne à l'ensemble de ses employés pour annoncer le lancement d'une nouvelle restructuration organisationnelle. Au cœur de cette évolution figure l'intégr
Xiaohongshu se restructure : Conan nommé président, création d'un département dédié à l'IA et d'une division internationale Rednote
Le 30 avril, Xiaohongshu a adressé une note interne à l'ensemble de ses employés pour annoncer le lancement d'une nouvelle restructuration organisationnelle. Au cœur de cette évolution figure l'intégr
 Le jeu « Xiaolongxia » de Tencent dépasse toutes les attentes ; l'équipe multiplie par dix sa capacité, présente ses excuses et offre des compensations
Tencent a officiellement lancé WorkBuddy, un agent intelligent basé sur l'IA et adapté à tous les contextes, marquant ainsi une nouvelle étape dans la course aux applications des grands modèles, carac
Le jeu « Xiaolongxia » de Tencent dépasse toutes les attentes ; l'équipe multiplie par dix sa capacité, présente ses excuses et offre des compensations
Tencent a officiellement lancé WorkBuddy, un agent intelligent basé sur l'IA et adapté à tous les contextes, marquant ainsi une nouvelle étape dans la course aux applications des grands modèles, carac
 Principal investisseur de Suno : la suppression des publications ne comblera pas les lacunes en matière de poursuites pour violation du droit d'auteur
La plateforme de génération musicale par IA très attendue, Suno, est confrontée à une rude bataille en matière de droits d'auteur, et une remarque sans détours de son principal investisseur pourrait b
Principal investisseur de Suno : la suppression des publications ne comblera pas les lacunes en matière de poursuites pour violation du droit d'auteur
La plateforme de génération musicale par IA très attendue, Suno, est confrontée à une rude bataille en matière de droits d'auteur, et une remarque sans détours de son principal investisseur pourrait b

Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
15 outils
xix.ai

Les meilleurs outils de gestion des dépenses basés sur l'IA en 2026 : les outils les mieux notés pour numériser vos reçus et classer automatiquement les dépenses de votre entreprise. Découvrez des solutions puissantes et révolutionnaires pour une gestion des dépenses sans effort, un suivi financier précis et une conformité simplifiée. Notre comparatif, mis à jour chaque semaine, qui oppose les options gratuites aux options payantes, vous aide à trouver la solution qui vous convient le mieux. Tirez pleinement parti de l'IA grâce aux recommandations d'experts de XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
10 outils
xix.ai

Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai

Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs mentors en sciences des données et en intelligence artificielle pour 2026 afin de maîtriser SQL, Pandas et les workflows d'apprentissage automatique. Explorez notre sélection soigneusement élaborée sur XIX.AI pour bénéficier d'une guidance puissante et révolutionnaire. Comparez les options gratuites et payantes en tenant compte de perspectives pratiques. Développez rapidement vos compétences en sciences des données.
10 outils
xix.ai













