




使用GPT-4的递归摘要:详细概述
在当今快节奏的世界中,信息丰富,浓缩长篇文章为简洁摘要的技能比以往任何时候都更有价值。本博客文章深入探讨了使用GPT-4进行递归摘要的迷人世界,提供了如何有效缩短冗长文本而不失核心内容的详细指南。无论你是学生、研究人员,还是喜欢保持信息更新的人,你都会发现这种方法非常实用。让我们一起探索如何利用GPT-4的强大功能进行有效的文本摘要。
关键点
- 递归摘要涉及将文本分解为较小的片段,并迭代地对它们进行摘要以创建简洁的概览。
- GPT-4的广泛上下文窗口有助于生成更准确和连贯的摘要。
- 令牌限制可能是一个障碍,需要战略性地分割文本。
- 编写有效的提示词对于引导GPT-4提取最相关信息至关重要。
- 这项技术在摘要研究论文、法律文件和新闻文章中有实际应用。
理解递归摘要
什么是递归摘要?
递归摘要就像一种浓缩长文本的魔法技巧。它涉及将冗长的文档分解为较小、易于消化的片段,对每个片段进行摘要,然后将这些摘要合并成更高层次的概览。这个过程可以重复多次,直到达到所需的长度。想象一下处理一份100页的报告;通过递归摘要,你可以创建一个易于管理的摘要,捕捉所有关键点而不迷失在细节中。
当你处理超过语言模型(如GPT-4)令牌限制的文档时,这种方法尤为出色。通过将任务分割为更小的步骤,你可以确保摘要过程既高效又准确。这就像解决一个大拼图,一块一块地拼凑,确保最终画面中包含每个重要细节。
为什么使用GPT-4进行摘要?
由OpenAI开发的GPT-4在文本摘要方面是一款强大的工具。凭借其大上下文窗口,它可以处理并保留输入文本的大量信息,从而生成更准确和连贯的摘要。它不仅仅是理解文本;GPT-4可以遵循指令并提取最相关的信息,使其非常适合递归摘要的精确任务。
GPT-4的魅力在于其适应不同写作风格和处理复杂文本的能力。无论是科学论文还是法律文件,GPT-4都能筛选内容并提取最重要的细节。使用最新的GPT-4 Turbo模型,你可以享受最多4096个输出令牌,减少模型无法完成任务的可能性。
克服令牌限制
令牌限制的挑战
使用像GPT-4这样的语言模型进行摘要的最大障碍之一是令牌限制。这些模型一次只能处理一定数量的令牌,当处理非常大的文档时,这可能是一个真正的挑战。如果你的文档超过令牌限制,你需要将其分解为更小、可管理的片段。
将文本分割为可管理的片段
为了充分利用GPT-4进行摘要,你需要将文本分割为适合令牌限制的可管理片段。以下是帮助你完成这一任务的分步方法:
- 确定令牌限制: 找出你使用的GPT-4模型的最大令牌限制。
- 分割文本: 根据段落、章节或部分将文档分解为更小的部分。
- 对每个片段进行令牌化: 使用令牌化工具计算每个片段的令牌数量。
- 调整片段大小: 如果某个片段超过令牌限制,进一步细分,直到所有片段都在可接受范围内。
通过遵循这些步骤,你可以确保每个片段都在GPT-4的令牌限制内,从而实现有效的递归摘要。无论是按段落、部分还是章节分割,目标是保持连贯性,同时遵守令牌限制。
高效摘要的策略
高效摘要的关键在于从每个文本片段中提取最相关的信息,同时保持在令牌限制内。一个有效的策略是专注于识别和保留封装主要观点和支持论点的关键句子。你还可以使用提取式摘要技术,直接从原始文本中复制重要的短语和句子。这对于技术性或学术性内容尤其有用,因为精确的语言至关重要。
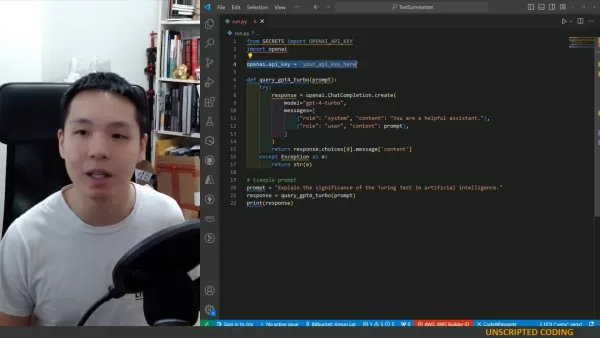
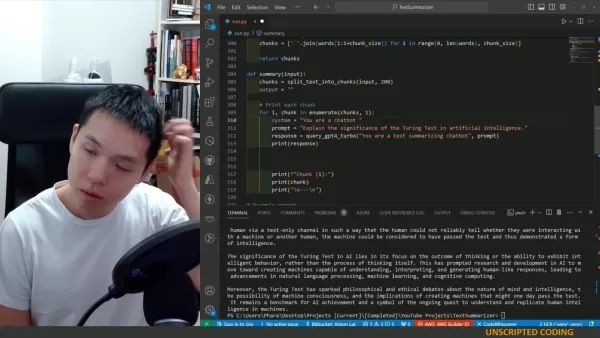
以下是一个简单的Python函数,帮助你将文本分割为片段:
textdef split_text_into_chunks(text, chunk_size=800):
words = text.split()
chunks = [' '.join(words[i:i+chunk_size]) for i in range(0, len(words), chunk_size)]
return chunks
此函数按单词分割文本,但如果你有可用的部分或章节,也可以使用它们。
使用GPT-4进行递归摘要的分步指南
设置环境
在开始递归摘要之前,确保你有权访问OpenAI API和GPT-4模型。你需要一个API密钥和OpenAI Python库。
以下是如何设置你的环境:
- 安装OpenAI库: 使用 pip install openai 安装OpenAI库。
- 导入必要的模块: 导入 openai 以及你需要的其他文本处理模块。
- 使用OpenAI认证: 设置你的API密钥以认证OpenAI API。
编码递归摘要函数
现在,让我们创建一个函数,递归地摘要文本片段。以下是一个示例函数:
textdef summary(input_text):
chunks = split_text_into_chunks(input_text, 800)
output = ""
for i, chunk in enumerate(chunks, 1):
system = "你是一个递归摘要文本的聊天机器人。你将处理一篇长篇文章,并一次摘要其部分内容。请考虑你已经摘要的内容,以创建风格一致的连贯摘要。你当前正在处理第" + str(i) + "部分。到目前为止,你的摘要是:" + output
prompt = "请为文章的下一部分添加摘要:" + chunk
response = query_gpt4_turbo(system, prompt)
output = output + " " + response
print(response)
return output
测试与迭代
实现函数后,是时候用各种文章测试其性能了。你可能需要迭代调整提示词和片段大小以优化结果。始终评估摘要的连贯性、准确性和相关性。测试和迭代是完善递归摘要过程并确保摘要满足你需求的关键步骤。
递归摘要的优点与缺点
优点
- 能够处理超过令牌限制的超大文档。
- 通过迭代摘要保持连贯性。
- 提供调整摘要长度的灵活性。
缺点
- 需要仔细规划和提示词设计。
- 对于极长的文本可能耗时。
- 与全文分析相比,可能丢失一些细微差别。
常见问题解答(FAQ)
最大令牌长度是多少?
GPT-4 Turbo最多返回4096个令牌。
哪些模型可用于递归摘要?
GPT-4和其他具有大上下文窗口的模型适合递归摘要。
递归摘要是什么意思?
它意味着每个摘要都会考虑后续摘要,确保在单一风格提示下保持一致性。
如果文本超过128,000个令牌怎么办?
使用此方法和代码将文本分解为片段,并逐步进行摘要。
相关问题
如何提高GPT-4摘要的质量?
要提升GPT-4摘要的质量,重点在于优化提示词和片段大小。清晰、具体的提示词可以引导GPT-4提取相关信息,而适当的片段大小确保模型能有效处理每个文本片段。在编辑器中实现之前,先在试验场测试也很有帮助。优化提示词,调整片段大小,并使用代码编辑器高效实现和测试系统。记住,测试是关键!
相关文章
 Manus 推出 "广泛研究 "人工智能工具,100 多个代理可进行网络搜索
中国人工智能创新企业 Manus 曾因其面向消费者和专业用户的开创性多代理编排平台而备受关注,如今它又推出了一项突破性的技术应用,对传统的人工智能研究方法提出了挑战。重新思考人工智能驱动的研究OpenAI、谷歌和 xAI 等竞争对手开发了专门的 "深度研究"(Deep Research)代理,能够进行长达数小时的调查并生成详细的报告,与之不同的是,Manus 通过其新的 "广度研究"(Wide R
法学硕士为何无视指示以及如何有效解决这一问题
了解大型语言模型跳过指令的原因大型语言模型(LLM)改变了我们与人工智能的交互方式,使从对话界面到自动内容生成和编程辅助等各种高级应用成为可能。然而,用户经常会遇到一个令人沮丧的限制:这些模型偶尔会忽略特定指令,尤其是在复杂或冗长的提示中。这种任务执行不完整的问题不仅会影响输出质量,还会降低用户对这些系统的信心。研究这种行为背后的根本原因,可以为优化 LLM 交互提供有价值的见解。LLM 处
经过法律诉讼,Pebble 重新获得了原品牌名称
鹅卵石的回归名称与一切Pebble 的爱好者们可以欢呼雀跃了--这个备受喜爱的智能手表品牌不仅卷土重来,还夺回了自己的标志性名称。"Core Devices 公司首席执行官 Eric Migicovsky 在公司博客更新中透露:"我们已经成功地重新获得了 Pebble 商标,其顺利程度着实让我感到惊讶。这意味着之前发布的 Core 2 Duo 现在将正式命名为 Pebble 2 Duo,而 Cor
评论 (17)
0/200
Manus 推出 "广泛研究 "人工智能工具,100 多个代理可进行网络搜索
中国人工智能创新企业 Manus 曾因其面向消费者和专业用户的开创性多代理编排平台而备受关注,如今它又推出了一项突破性的技术应用,对传统的人工智能研究方法提出了挑战。重新思考人工智能驱动的研究OpenAI、谷歌和 xAI 等竞争对手开发了专门的 "深度研究"(Deep Research)代理,能够进行长达数小时的调查并生成详细的报告,与之不同的是,Manus 通过其新的 "广度研究"(Wide R
法学硕士为何无视指示以及如何有效解决这一问题
了解大型语言模型跳过指令的原因大型语言模型(LLM)改变了我们与人工智能的交互方式,使从对话界面到自动内容生成和编程辅助等各种高级应用成为可能。然而,用户经常会遇到一个令人沮丧的限制:这些模型偶尔会忽略特定指令,尤其是在复杂或冗长的提示中。这种任务执行不完整的问题不仅会影响输出质量,还会降低用户对这些系统的信心。研究这种行为背后的根本原因,可以为优化 LLM 交互提供有价值的见解。LLM 处
经过法律诉讼,Pebble 重新获得了原品牌名称
鹅卵石的回归名称与一切Pebble 的爱好者们可以欢呼雀跃了--这个备受喜爱的智能手表品牌不仅卷土重来,还夺回了自己的标志性名称。"Core Devices 公司首席执行官 Eric Migicovsky 在公司博客更新中透露:"我们已经成功地重新获得了 Pebble 商标,其顺利程度着实让我感到惊讶。这意味着之前发布的 Core 2 Duo 现在将正式命名为 Pebble 2 Duo,而 Cor
评论 (17)
0/200
![RonaldHernández]() RonaldHernández
RonaldHernández
 2025-08-15 14:00:59
2025-08-15 14:00:59
This recursive summarization stuff with GPT-4 is wild! It’s like teaching a super-smart robot to shrink novels into tweets. I wonder how it handles super technical papers though? 🤔


 0
0
![JohnRoberts]() JohnRoberts
2025-08-06 19:00:59
JohnRoberts
2025-08-06 19:00:59
This recursive summarization thing with GPT-4 sounds like a game-changer! I love how it can boil down massive articles into bite-sized nuggets. Makes me wonder if I’ll ever read a full article again 😂. Anyone tried this in their workflow yet?
0
![GeorgeTaylor]() GeorgeTaylor
2025-05-10 13:52:31
GeorgeTaylor
2025-05-10 13:52:31
A Sumarização Recursiva com GPT-4 é incrível! É como mágica como ele consegue pegar um artigo longo e reduzi-lo ao essencial. Usei no trabalho e economizou muito tempo. Só queria que fosse um pouco mais amigável, a interface pode ser confusa. Ainda assim, é uma ferramenta revolucionária! 🌟
0
![FrankSmith]() FrankSmith
2025-05-10 07:51:23
FrankSmith
2025-05-10 07:51:23
¡La Sumarización Recursiva con GPT-4 es impresionante! Es muy útil para condensar artículos largos, aunque a veces las summaries pierden un poco del sabor original. Aún así, es una gran herramienta para quien necesita captar rápidamente la esencia de textos extensos. ¡Pruébalo! 📚
0
![MatthewGonzalez]() MatthewGonzalez
2025-05-10 06:18:08
MatthewGonzalez
2025-05-10 06:18:08
A Sumarização Recursiva com GPT-4 é incrível! É super útil para condensar artigos longos, mas às vezes os resumos perdem um pouco do sabor original. Ainda assim, é uma ótima ferramenta para quem precisa captar rapidamente a essência de textos extensos. Experimente! 📚
0
![StevenNelson]() StevenNelson
2025-05-10 05:29:07
StevenNelson
2025-05-10 05:29:07
GPT-4を使った再帰的要約は驚くべきものです!長い記事を要約するのにとても役立ちますが、時々オリジナルの風味が少し失われることがあります。それでも、長いテキストの要点を素早く把握したい人にとっては素晴らしいツールです。試してみてください!📚
0
在当今快节奏的世界中,信息丰富,浓缩长篇文章为简洁摘要的技能比以往任何时候都更有价值。本博客文章深入探讨了使用GPT-4进行递归摘要的迷人世界,提供了如何有效缩短冗长文本而不失核心内容的详细指南。无论你是学生、研究人员,还是喜欢保持信息更新的人,你都会发现这种方法非常实用。让我们一起探索如何利用GPT-4的强大功能进行有效的文本摘要。
关键点
- 递归摘要涉及将文本分解为较小的片段,并迭代地对它们进行摘要以创建简洁的概览。
- GPT-4的广泛上下文窗口有助于生成更准确和连贯的摘要。
- 令牌限制可能是一个障碍,需要战略性地分割文本。
- 编写有效的提示词对于引导GPT-4提取最相关信息至关重要。
- 这项技术在摘要研究论文、法律文件和新闻文章中有实际应用。
理解递归摘要
什么是递归摘要?
递归摘要就像一种浓缩长文本的魔法技巧。它涉及将冗长的文档分解为较小、易于消化的片段,对每个片段进行摘要,然后将这些摘要合并成更高层次的概览。这个过程可以重复多次,直到达到所需的长度。想象一下处理一份100页的报告;通过递归摘要,你可以创建一个易于管理的摘要,捕捉所有关键点而不迷失在细节中。
当你处理超过语言模型(如GPT-4)令牌限制的文档时,这种方法尤为出色。通过将任务分割为更小的步骤,你可以确保摘要过程既高效又准确。这就像解决一个大拼图,一块一块地拼凑,确保最终画面中包含每个重要细节。
为什么使用GPT-4进行摘要?
由OpenAI开发的GPT-4在文本摘要方面是一款强大的工具。凭借其大上下文窗口,它可以处理并保留输入文本的大量信息,从而生成更准确和连贯的摘要。它不仅仅是理解文本;GPT-4可以遵循指令并提取最相关的信息,使其非常适合递归摘要的精确任务。
GPT-4的魅力在于其适应不同写作风格和处理复杂文本的能力。无论是科学论文还是法律文件,GPT-4都能筛选内容并提取最重要的细节。使用最新的GPT-4 Turbo模型,你可以享受最多4096个输出令牌,减少模型无法完成任务的可能性。
克服令牌限制
令牌限制的挑战
使用像GPT-4这样的语言模型进行摘要的最大障碍之一是令牌限制。这些模型一次只能处理一定数量的令牌,当处理非常大的文档时,这可能是一个真正的挑战。如果你的文档超过令牌限制,你需要将其分解为更小、可管理的片段。
将文本分割为可管理的片段
为了充分利用GPT-4进行摘要,你需要将文本分割为适合令牌限制的可管理片段。以下是帮助你完成这一任务的分步方法:
- 确定令牌限制: 找出你使用的GPT-4模型的最大令牌限制。
- 分割文本: 根据段落、章节或部分将文档分解为更小的部分。
- 对每个片段进行令牌化: 使用令牌化工具计算每个片段的令牌数量。
- 调整片段大小: 如果某个片段超过令牌限制,进一步细分,直到所有片段都在可接受范围内。
通过遵循这些步骤,你可以确保每个片段都在GPT-4的令牌限制内,从而实现有效的递归摘要。无论是按段落、部分还是章节分割,目标是保持连贯性,同时遵守令牌限制。
高效摘要的策略
高效摘要的关键在于从每个文本片段中提取最相关的信息,同时保持在令牌限制内。一个有效的策略是专注于识别和保留封装主要观点和支持论点的关键句子。你还可以使用提取式摘要技术,直接从原始文本中复制重要的短语和句子。这对于技术性或学术性内容尤其有用,因为精确的语言至关重要。
以下是一个简单的Python函数,帮助你将文本分割为片段:
def split_text_into_chunks(text, chunk_size=800):
words = text.split()
chunks = [' '.join(words[i:i+chunk_size]) for i in range(0, len(words), chunk_size)]
return chunks此函数按单词分割文本,但如果你有可用的部分或章节,也可以使用它们。
使用GPT-4进行递归摘要的分步指南
设置环境
在开始递归摘要之前,确保你有权访问OpenAI API和GPT-4模型。你需要一个API密钥和OpenAI Python库。
以下是如何设置你的环境:
- 安装OpenAI库: 使用 pip install openai 安装OpenAI库。
- 导入必要的模块: 导入 openai 以及你需要的其他文本处理模块。
- 使用OpenAI认证: 设置你的API密钥以认证OpenAI API。
编码递归摘要函数
现在,让我们创建一个函数,递归地摘要文本片段。以下是一个示例函数:
def summary(input_text):
chunks = split_text_into_chunks(input_text, 800)
output = ""
for i, chunk in enumerate(chunks, 1):
system = "你是一个递归摘要文本的聊天机器人。你将处理一篇长篇文章,并一次摘要其部分内容。请考虑你已经摘要的内容,以创建风格一致的连贯摘要。你当前正在处理第" + str(i) + "部分。到目前为止,你的摘要是:" + output
prompt = "请为文章的下一部分添加摘要:" + chunk
response = query_gpt4_turbo(system, prompt)
output = output + " " + response
print(response)
return output测试与迭代
实现函数后,是时候用各种文章测试其性能了。你可能需要迭代调整提示词和片段大小以优化结果。始终评估摘要的连贯性、准确性和相关性。测试和迭代是完善递归摘要过程并确保摘要满足你需求的关键步骤。
递归摘要的优点与缺点
优点
- 能够处理超过令牌限制的超大文档。
- 通过迭代摘要保持连贯性。
- 提供调整摘要长度的灵活性。
缺点
- 需要仔细规划和提示词设计。
- 对于极长的文本可能耗时。
- 与全文分析相比,可能丢失一些细微差别。
常见问题解答(FAQ)
最大令牌长度是多少?
GPT-4 Turbo最多返回4096个令牌。
哪些模型可用于递归摘要?
GPT-4和其他具有大上下文窗口的模型适合递归摘要。
递归摘要是什么意思?
它意味着每个摘要都会考虑后续摘要,确保在单一风格提示下保持一致性。
如果文本超过128,000个令牌怎么办?
使用此方法和代码将文本分解为片段,并逐步进行摘要。
相关问题
如何提高GPT-4摘要的质量?
要提升GPT-4摘要的质量,重点在于优化提示词和片段大小。清晰、具体的提示词可以引导GPT-4提取相关信息,而适当的片段大小确保模型能有效处理每个文本片段。在编辑器中实现之前,先在试验场测试也很有帮助。优化提示词,调整片段大小,并使用代码编辑器高效实现和测试系统。记住,测试是关键!










 Manus 推出 "广泛研究 "人工智能工具,100 多个代理可进行网络搜索
中国人工智能创新企业 Manus 曾因其面向消费者和专业用户的开创性多代理编排平台而备受关注,如今它又推出了一项突破性的技术应用,对传统的人工智能研究方法提出了挑战。重新思考人工智能驱动的研究OpenAI、谷歌和 xAI 等竞争对手开发了专门的 "深度研究"(Deep Research)代理,能够进行长达数小时的调查并生成详细的报告,与之不同的是,Manus 通过其新的 "广度研究"(Wide R
Manus 推出 "广泛研究 "人工智能工具,100 多个代理可进行网络搜索
中国人工智能创新企业 Manus 曾因其面向消费者和专业用户的开创性多代理编排平台而备受关注,如今它又推出了一项突破性的技术应用,对传统的人工智能研究方法提出了挑战。重新思考人工智能驱动的研究OpenAI、谷歌和 xAI 等竞争对手开发了专门的 "深度研究"(Deep Research)代理,能够进行长达数小时的调查并生成详细的报告,与之不同的是,Manus 通过其新的 "广度研究"(Wide R
 法学硕士为何无视指示以及如何有效解决这一问题
了解大型语言模型跳过指令的原因大型语言模型(LLM)改变了我们与人工智能的交互方式,使从对话界面到自动内容生成和编程辅助等各种高级应用成为可能。然而,用户经常会遇到一个令人沮丧的限制:这些模型偶尔会忽略特定指令,尤其是在复杂或冗长的提示中。这种任务执行不完整的问题不仅会影响输出质量,还会降低用户对这些系统的信心。研究这种行为背后的根本原因,可以为优化 LLM 交互提供有价值的见解。LLM 处
法学硕士为何无视指示以及如何有效解决这一问题
了解大型语言模型跳过指令的原因大型语言模型(LLM)改变了我们与人工智能的交互方式,使从对话界面到自动内容生成和编程辅助等各种高级应用成为可能。然而,用户经常会遇到一个令人沮丧的限制:这些模型偶尔会忽略特定指令,尤其是在复杂或冗长的提示中。这种任务执行不完整的问题不仅会影响输出质量,还会降低用户对这些系统的信心。研究这种行为背后的根本原因,可以为优化 LLM 交互提供有价值的见解。LLM 处
 经过法律诉讼,Pebble 重新获得了原品牌名称
鹅卵石的回归名称与一切Pebble 的爱好者们可以欢呼雀跃了--这个备受喜爱的智能手表品牌不仅卷土重来,还夺回了自己的标志性名称。"Core Devices 公司首席执行官 Eric Migicovsky 在公司博客更新中透露:"我们已经成功地重新获得了 Pebble 商标,其顺利程度着实让我感到惊讶。这意味着之前发布的 Core 2 Duo 现在将正式命名为 Pebble 2 Duo,而 Cor
2025-08-15 14:00:59
经过法律诉讼,Pebble 重新获得了原品牌名称
鹅卵石的回归名称与一切Pebble 的爱好者们可以欢呼雀跃了--这个备受喜爱的智能手表品牌不仅卷土重来,还夺回了自己的标志性名称。"Core Devices 公司首席执行官 Eric Migicovsky 在公司博客更新中透露:"我们已经成功地重新获得了 Pebble 商标,其顺利程度着实让我感到惊讶。这意味着之前发布的 Core 2 Duo 现在将正式命名为 Pebble 2 Duo,而 Cor
2025-08-15 14:00:59
This recursive summarization stuff with GPT-4 is wild! It’s like teaching a super-smart robot to shrink novels into tweets. I wonder how it handles super technical papers though? 🤔
0
2025-08-06 19:00:59
This recursive summarization thing with GPT-4 sounds like a game-changer! I love how it can boil down massive articles into bite-sized nuggets. Makes me wonder if I’ll ever read a full article again 😂. Anyone tried this in their workflow yet?
0
2025-05-10 13:52:31
A Sumarização Recursiva com GPT-4 é incrível! É como mágica como ele consegue pegar um artigo longo e reduzi-lo ao essencial. Usei no trabalho e economizou muito tempo. Só queria que fosse um pouco mais amigável, a interface pode ser confusa. Ainda assim, é uma ferramenta revolucionária! 🌟
0
2025-05-10 07:51:23
¡La Sumarización Recursiva con GPT-4 es impresionante! Es muy útil para condensar artículos largos, aunque a veces las summaries pierden un poco del sabor original. Aún así, es una gran herramienta para quien necesita captar rápidamente la esencia de textos extensos. ¡Pruébalo! 📚
0
2025-05-10 06:18:08
A Sumarização Recursiva com GPT-4 é incrível! É super útil para condensar artigos longos, mas às vezes os resumos perdem um pouco do sabor original. Ainda assim, é uma ótima ferramenta para quem precisa captar rapidamente a essência de textos extensos. Experimente! 📚
0
2025-05-10 05:29:07
GPT-4を使った再帰的要約は驚くべきものです!長い記事を要約するのにとても役立ちますが、時々オリジナルの風味が少し失われることがあります。それでも、長いテキストの要点を素早く把握したい人にとっては素晴らしいツールです。試してみてください!📚
0













