
















 首页
首页OmniHuman 人工智能通过单张图像实现视频制作转型
在快速发展的人工智能领域,出现了一种革命性的新工具,它有可能改变视频创作。OmniHuman AI 是一种最先进的技术,只需一张图像和一个音频文件就能制作出非常逼真的视频。这一创新解决方案将重塑包括娱乐、营销、教育和无障碍服务在内的众多行业。然而,如此强大的技术也肩负着重大的责任,因此了解其更广泛的影响至关重要。本文将深入探讨全方位人工智能(OmniHuman AI),探索其令人印象深刻的功能及其可能对社会产生的影响。
要点
全方位人工智能只需使用单个图像和音频文件即可创建栩栩如生的视频。
它使视频内容创作变得异常简单。
它可应用于教育、娱乐、营销和无障碍环境。
这项技术在带来巨大商机的同时,也带来了重要的伦理问题。
OmniHuman 的能力,尤其是全身动画和细节动作捕捉方面的能力,超过了目前的人工智能视频生成器。
虽然它尚未公开,但即将发布的版本令人期待。
了解全方位人工智能
什么是全方位人工智能?
OmniHuman AI 是一个开创性的多模态条件框架,用于生成人体视频。它的独特之处在于只使用一张图像和一个音轨就能生成逼真的全身视频。它由 Bytedance 开发。
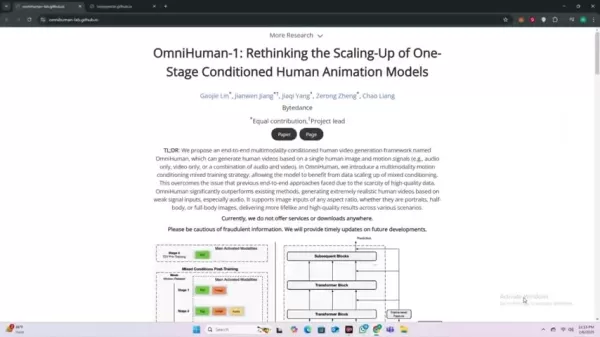
这种方法简化了内容创建,使逼真的视频制作比以往任何时候都更容易实现。OmniHuman 的主要优势在于它能从非常有限的输入中推断出逼真的人体动作、面部表情和唇语。OmniHuman 与其他人工智能视频工具的不同之处在于其卓越的性能,可以实现以前无法实现的效果。有了 OmniHuman 人工智能,当前技术的性能大幅提升,即使是音频等稀少的输入也能生成高度逼真的人类视频,在不同的环境下持续提供自然、高保真的效果。
这种人工智能通过检查所提供的图像来识别拍摄对象的特征,然后使用音频来引导拍摄对象的动作、面部表情和语言模式。该系统可生成多种内容,例如
- 唇语同步语音:将音频与可信的嘴部动作精确对齐。
- 自然手势:创建符合音频语境的逼真手部和肢体动作。
- 情感表达:将面部和肢体语言动画化,以反映音频中的情感。
全方位人工智能如何工作?
OmniHuman AI 的技术优势来自其端到端多模态条件框架,用于生成人类视频。该系统采用了一种新颖的方法,克服了端到端模型以往的局限性,这主要是由于缺乏高质量的训练数据。OmniHuman 的性能大大优于现有方法,它能从最少的输入(尤其是音频输入)生成极其逼真的人类视频。人工智能依赖于先进机器学习方法的融合,包括
- 深度学习:用于分析和解释图像和音频数据。
- 生成式对抗网络(GANs):用于生成逼真的视频帧。
- 动作捕捉技术:用于准确再现人类动作。
- 变压器网络:这些模型有助于理解音频中的长距离关系,并将其与相应的动作和视觉元素联系起来,用于视频制作。
一般流程包括以下几个阶段:
- 图像和音频输入:用户提供一个人的图像和讲话录音。
- 人工智能处理:全方位人工智能处理图像和音频,提取相关特征。
- 视频合成:人工智能会生成一段栩栩如生的视频,视频中的人物说话时面部表情和肢体语言都栩栩如生。
最终生成的视频流畅可信,适合各种用途。值得注意的是,人工智能不仅能将头部动作动画化,还能将手势动画化,并在整个过程中保持极佳的手部一致性。

.
全方位人工智能的技术规格
以下是该模型的技术规格,概述了其功能和运行机制。
- 模型名称:全能人-1
- 开发商: Bytedance开发者: Bytedance
- 论文:OmniHuman-1:反思单阶段条件人体动画模型的扩展
- 框架:端到端多模态条件人体视频生成框架
- 输入:OmniHuman 通过单个人体图像和动作线索(如纯音频、纯视频或两者混合)创建人体视频。
- 功能
- 支持各种视觉和音频风格。
- 以任何长宽比和身体比例生成逼真的人体视频(一个模型可容纳肖像、半身和全身镜头),通过运动、照明和纹理细节实现逼真效果。
- 可处理多种人体姿势和演唱形式。
- 可处理高音歌曲,并为各种音乐类型展示不同的动作风格。
- 以任何长宽比和身体比例制作逼真的人体视频。
- 接受任何长宽比的图像输入,包括肖像、半身和全身照片。
- 可用性:目前,任何地方都不提供服务或下载。代码库也未公开发布。
道德考虑因素和潜在风险
深度伪造和错误信息
使用 OmniHuman AI 制作逼真视频的简单性也带来了对可能滥用的担忧。这项技术可能被用来制作深度伪造视频--经过修改的视频逼真地展示了某人说过或做过的从未发生过的事情。人工智能生成的视频可能会被用来传播虚假信息、损害他人名誉,甚至挑起冲突。区分真实视频和人工智能生成的视频变得十分困难。
应对这些危险需要采取多管齐下的策略,其中包括
- 创建检测工具:建立基于人工智能的系统,能够识别深度伪造和其他篡改视频。
- 提高媒体素养:教人们如何识别深度伪造和其他类型的网络虚假信息。
- 制定道德标准:为制作和使用人工智能生成的视频制定行业规范和道德规则。
- 确保生成内容中的数字标记一致,以便快速识别人工智能角色。

偏见和代表性
与许多人工智能系统类似,OmniHuman 人工智能也容易因其训练数据而产生偏差。如果训练数据缺乏多样性和代表性,人工智能可能会制作出强化负面刻板印象或忽视某些群体的视频。解决人工智能系统中的偏见问题包括
- 利用多样化的训练数据:确保用于训练 OmniHuman 人工智能的数据代表不同种族、性别和文化背景。
- 进行偏见审计:定期检查人工智能的输出结果,发现并减少任何潜在的偏见。
- 鼓励透明:公开共享人工智能的训练数据和算法,以便进行审查和问责。
定价
全方位人工智能定价
目前,OmniHuman 仍处于研发阶段,尚未公布定价信息。一旦 OmniHuman 公布定价结构,我们将及时通知您。
敬请关注定价更新!
全方位人工智能:优点和缺点
优点
高质量视频输出:生成逼真、引人入胜的视频。
用户友好:只需一个图像和音频文件。
适应性强:适用于各种图像和音频格式。
全身运动能制作逼真的全身动画。
缺点
滥用风险:可能被用于制作深度伪造品和传播错误信息。
伦理问题:引发对真实性和许可的担忧。
容易产生偏见:如果使用不具代表性的数据进行训练,可能会反映出偏见。
目前不对公众开放:目前仅限于研发使用。
常见问题
什么是 OmniHuman AI?
OmniHuman AI 是 Bytedance 开发的一种人工智能工具,可通过一张图像和一个音轨生成逼真的视频。它可以通过同步嘴唇动作、手势和表情制作人像动画和全身视频。
OmniHuman AI 与其他人工智能视频生成器相比有何优势?
它与其他人工智能视频工具的区别在于其更高的性能,可实现以往不可能实现的逼真效果。它超越了当前的方法,即使在音频等输入有限的情况下,也能创建极其逼真的人类视频。它还能适应各种视觉和音频风格,并接受任何长宽比的图像输入,包括肖像、半身和全身镜头。
全方位人工智能能否处理不同的语言?
可以,OmniHuman AI 可以处理多种语言的音频输入和视频输出。
OmniHuman AI 是否能处理动画和卡通图像?
可以!虽然它能通过实际照片提供最逼真的效果,但这种人工智能也能处理卡通和动画人物。
相关问题
还有哪些其他人工智能视频生成工具?
人工智能视频生成领域在不断进步,新工具和新平台层出不穷。OmniHuman AI 以其逼真性和简易性著称,其他重要的替代工具包括VASA-1(微软):专注于实时生成具有准确唇语同步、逼真面部表情和自然头部动作的自然表情。RunwayML:一个全功能的人工智能驱动创意平台,提供视频编辑、风格转换和内容生成工具。Synthesia:这项服务可让你创建人工智能头像,并根据文本制作视频,为培训和营销材料提供经济实惠的选择。DeepMotion:专门从事动作捕捉和动画制作,让你可以通过视频剪辑制作逼真的三维动画。Elai.io:专注于为视频制作人工智能演示器,是培训、产品演示和营销内容的完美选择。请务必对每个选项进行深入研究,选择最符合您的具体要求和预算的方案。此外,还要查看其使用政策,以避免不道德的应用。
相关文章
 海尔推出全球最轻的人工智能运动外骨骼机器人,重量仅为1.75公斤
海尔集团推出了全球最轻的运动型人工智能外骨骼机器人——海尔外骨骼机器人W3。此次发布创下了行业轻量化新纪录,标志着在轻量化设计和智能人体运动增强领域取得了重大突破。高端材料成就超轻量化设计W3采用创新的一体化制造工艺,融合全碳纤维与钛合金。这种航空级材料组合将总重量控制在仅1.75公斤,实现了轻量化与高强度的完美平衡,展现出极致的机械性能。为提升舒适度,该机器人融入了非牛顿流体材料,触感柔软亲肤,
耀科传媒首部AIGC剧集《秦岭青铜之谜》今日上线,主演均由AI生成
今日,耀科传媒的AIGC奇幻悬疑短剧《秦岭青铜秘闻》正式上线。该剧由公司签约的首批两位AI演员秦凌月和林西妍主演,故事背景设定在神秘的秦岭矿区。 剧中,退役情报官秦月率队深入该区域,揭开了一起尘封已久的矿难真相,以及跨越两代人的血祭之谜——这个真相就隐藏在受限的地下区域,那里是科学探索与古代巫术交汇之地。作为中国最早完全由AI数字人支撑的影视作品之一,该剧在筹备阶段便引发了业界热烈讨论,而关于其A
萨提亚·纳德拉准备利用与OpenAI的新合作关系
周三,一位华尔街分析师直接询问了微软首席执行官萨蒂亚·纳德拉,修订后的OpenAI合作关系将如何影响公司的财务状况。 纳德拉将这一新协议描述为对各方都有利的结果。“我们对与OpenAI的合作感到满意。我始终非常重视任何合作关系,并确保它能够实现双赢。只有这样,双方才能保持良好的合作伙伴关系。” 他强调,微软仍然可以使用OpenAI的知识产权,包括其模型和智能体产品,但不再需要为此向OpenAI支付费用。 谈到在2032年之前可以免费使用OpenAI最先进的人工智能技术,纳德拉表示:“
相关专题推荐
商业
海尔推出全球最轻的人工智能运动外骨骼机器人,重量仅为1.75公斤
海尔集团推出了全球最轻的运动型人工智能外骨骼机器人——海尔外骨骼机器人W3。此次发布创下了行业轻量化新纪录,标志着在轻量化设计和智能人体运动增强领域取得了重大突破。高端材料成就超轻量化设计W3采用创新的一体化制造工艺,融合全碳纤维与钛合金。这种航空级材料组合将总重量控制在仅1.75公斤,实现了轻量化与高强度的完美平衡,展现出极致的机械性能。为提升舒适度,该机器人融入了非牛顿流体材料,触感柔软亲肤,
耀科传媒首部AIGC剧集《秦岭青铜之谜》今日上线,主演均由AI生成
今日,耀科传媒的AIGC奇幻悬疑短剧《秦岭青铜秘闻》正式上线。该剧由公司签约的首批两位AI演员秦凌月和林西妍主演,故事背景设定在神秘的秦岭矿区。 剧中,退役情报官秦月率队深入该区域,揭开了一起尘封已久的矿难真相,以及跨越两代人的血祭之谜——这个真相就隐藏在受限的地下区域,那里是科学探索与古代巫术交汇之地。作为中国最早完全由AI数字人支撑的影视作品之一,该剧在筹备阶段便引发了业界热烈讨论,而关于其A
萨提亚·纳德拉准备利用与OpenAI的新合作关系
周三,一位华尔街分析师直接询问了微软首席执行官萨蒂亚·纳德拉,修订后的OpenAI合作关系将如何影响公司的财务状况。 纳德拉将这一新协议描述为对各方都有利的结果。“我们对与OpenAI的合作感到满意。我始终非常重视任何合作关系,并确保它能够实现双赢。只有这样,双方才能保持良好的合作伙伴关系。” 他强调,微软仍然可以使用OpenAI的知识产权,包括其模型和智能体产品,但不再需要为此向OpenAI支付费用。 谈到在2032年之前可以免费使用OpenAI最先进的人工智能技术,纳德拉表示:“
相关专题推荐
商业
 最佳 AI 费用追踪工具:扫描收据并自动分类企业开支
最佳 AI 费用追踪工具:扫描收据并自动分类企业开支
2026年最新最佳AI报销管理工具:广受好评的解决方案,可自动扫描收据并分类企业支出。探索这些功能强大、颠覆传统的解决方案,助您轻松管理报销、精准追踪财务并简化合规流程。我们精心整理并每周更新的免费与付费选项对比指南,助您找到最适合的工具。通过XIX.AI的专家精选,释放您的AI优势。
 10 个工具
10 个工具
 xix.ai
商业
最佳人工智能招聘工具:筛选简历并自动安排候选人面试
xix.ai
商业
最佳人工智能招聘工具:筛选简历并自动安排候选人面试
在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
10 个工具
xix.ai
生产率
AI个人健康与专注力教练:缓解倦怠,提升精神能量
立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai
聊天机器人
备受好评的AI浪漫聊天机器人:凭借稳定的个性建立长期关系
探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai
教育与学习
最佳AI数据科学导师:精通SQL、Pandas及机器学习工作流程
探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai
聊天机器人
最佳AI调情与对话训练工具:实时提升社交魅力与自信
在 XIX.AI 上探索 2026 年最优秀的 AI 调情与对话训练工具。我们精心挑选的高评分工具助您实时提升社交魅力与自信。探索这些必试的、颠覆性的工具,查看免费版与付费版的对比,并了解每周更新的排行榜。立即开启您的社交优势。
10 个工具
xix.ai

 评论 (3)
0/500
评论 (3)
0/500
![BruceHernández]()
這技術也太酷了吧!只用一張照片就能生成影片,以後拍片門檻是不是要降到零了?不過想到深度偽造濫用的可能性,又有點擔心... 開發團隊有考慮過倫理防護機制嗎?🤔
![RogerJackson]()
제목만 봐도 상상력을 자극하네요! 단 하나의 사진으로 비디오를 만다니, 이게 진짜 기술인가요? 🧐 AI가 이렇게 발전하면 영상 제작자들은 걱정해야 할지도... 제 친구가 요즘 영상 편집하는데 엄청 시간이 걸린다고 하던데, 이런 기술이 실용화되면 업무 방식이 완전히 바뀔 것 같아요. 근데 이런 기술이 악용될 가능성에 대한 논의도 필요하지 않을까요?
![KevinTaylor]()
Один снимок, а готово целое видео — возможно ли это? OmniHuman AI, судя по всему, делает именно это. Очень впечатляет, хотя лично мне интересно, как технология справляется с движением объектов в кадре, особенно когда изначальная фотография статична. Возможно, в будущем создание фильмов станет куда доступнее для обычных пользователей! 🎥 👏 Надеюсь, это не приведет к распространению фейкового контента.
在快速发展的人工智能领域,出现了一种革命性的新工具,它有可能改变视频创作。OmniHuman AI 是一种最先进的技术,只需一张图像和一个音频文件就能制作出非常逼真的视频。这一创新解决方案将重塑包括娱乐、营销、教育和无障碍服务在内的众多行业。然而,如此强大的技术也肩负着重大的责任,因此了解其更广泛的影响至关重要。本文将深入探讨全方位人工智能(OmniHuman AI),探索其令人印象深刻的功能及其可能对社会产生的影响。
要点
全方位人工智能只需使用单个图像和音频文件即可创建栩栩如生的视频。
它使视频内容创作变得异常简单。
它可应用于教育、娱乐、营销和无障碍环境。
这项技术在带来巨大商机的同时,也带来了重要的伦理问题。
OmniHuman 的能力,尤其是全身动画和细节动作捕捉方面的能力,超过了目前的人工智能视频生成器。
虽然它尚未公开,但即将发布的版本令人期待。
了解全方位人工智能
什么是全方位人工智能?
OmniHuman AI 是一个开创性的多模态条件框架,用于生成人体视频。它的独特之处在于只使用一张图像和一个音轨就能生成逼真的全身视频。它由 Bytedance 开发。
这种方法简化了内容创建,使逼真的视频制作比以往任何时候都更容易实现。OmniHuman 的主要优势在于它能从非常有限的输入中推断出逼真的人体动作、面部表情和唇语。OmniHuman 与其他人工智能视频工具的不同之处在于其卓越的性能,可以实现以前无法实现的效果。有了 OmniHuman 人工智能,当前技术的性能大幅提升,即使是音频等稀少的输入也能生成高度逼真的人类视频,在不同的环境下持续提供自然、高保真的效果。
这种人工智能通过检查所提供的图像来识别拍摄对象的特征,然后使用音频来引导拍摄对象的动作、面部表情和语言模式。该系统可生成多种内容,例如
- 唇语同步语音:将音频与可信的嘴部动作精确对齐。
- 自然手势:创建符合音频语境的逼真手部和肢体动作。
- 情感表达:将面部和肢体语言动画化,以反映音频中的情感。
全方位人工智能如何工作?
OmniHuman AI 的技术优势来自其端到端多模态条件框架,用于生成人类视频。该系统采用了一种新颖的方法,克服了端到端模型以往的局限性,这主要是由于缺乏高质量的训练数据。OmniHuman 的性能大大优于现有方法,它能从最少的输入(尤其是音频输入)生成极其逼真的人类视频。人工智能依赖于先进机器学习方法的融合,包括
- 深度学习:用于分析和解释图像和音频数据。
- 生成式对抗网络(GANs):用于生成逼真的视频帧。
- 动作捕捉技术:用于准确再现人类动作。
- 变压器网络:这些模型有助于理解音频中的长距离关系,并将其与相应的动作和视觉元素联系起来,用于视频制作。
一般流程包括以下几个阶段:
- 图像和音频输入:用户提供一个人的图像和讲话录音。
- 人工智能处理:全方位人工智能处理图像和音频,提取相关特征。
- 视频合成:人工智能会生成一段栩栩如生的视频,视频中的人物说话时面部表情和肢体语言都栩栩如生。
最终生成的视频流畅可信,适合各种用途。值得注意的是,人工智能不仅能将头部动作动画化,还能将手势动画化,并在整个过程中保持极佳的手部一致性。
.
全方位人工智能的技术规格
以下是该模型的技术规格,概述了其功能和运行机制。
- 模型名称:全能人-1
- 开发商: Bytedance开发者: Bytedance
- 论文:OmniHuman-1:反思单阶段条件人体动画模型的扩展
- 框架:端到端多模态条件人体视频生成框架
- 输入:OmniHuman 通过单个人体图像和动作线索(如纯音频、纯视频或两者混合)创建人体视频。
- 功能
- 支持各种视觉和音频风格。
- 以任何长宽比和身体比例生成逼真的人体视频(一个模型可容纳肖像、半身和全身镜头),通过运动、照明和纹理细节实现逼真效果。
- 可处理多种人体姿势和演唱形式。
- 可处理高音歌曲,并为各种音乐类型展示不同的动作风格。
- 以任何长宽比和身体比例制作逼真的人体视频。
- 接受任何长宽比的图像输入,包括肖像、半身和全身照片。
- 可用性:目前,任何地方都不提供服务或下载。代码库也未公开发布。
道德考虑因素和潜在风险
深度伪造和错误信息
使用 OmniHuman AI 制作逼真视频的简单性也带来了对可能滥用的担忧。这项技术可能被用来制作深度伪造视频--经过修改的视频逼真地展示了某人说过或做过的从未发生过的事情。人工智能生成的视频可能会被用来传播虚假信息、损害他人名誉,甚至挑起冲突。区分真实视频和人工智能生成的视频变得十分困难。
应对这些危险需要采取多管齐下的策略,其中包括
- 创建检测工具:建立基于人工智能的系统,能够识别深度伪造和其他篡改视频。
- 提高媒体素养:教人们如何识别深度伪造和其他类型的网络虚假信息。
- 制定道德标准:为制作和使用人工智能生成的视频制定行业规范和道德规则。
- 确保生成内容中的数字标记一致,以便快速识别人工智能角色。
偏见和代表性
与许多人工智能系统类似,OmniHuman 人工智能也容易因其训练数据而产生偏差。如果训练数据缺乏多样性和代表性,人工智能可能会制作出强化负面刻板印象或忽视某些群体的视频。解决人工智能系统中的偏见问题包括
- 利用多样化的训练数据:确保用于训练 OmniHuman 人工智能的数据代表不同种族、性别和文化背景。
- 进行偏见审计:定期检查人工智能的输出结果,发现并减少任何潜在的偏见。
- 鼓励透明:公开共享人工智能的训练数据和算法,以便进行审查和问责。
定价
全方位人工智能定价
目前,OmniHuman 仍处于研发阶段,尚未公布定价信息。一旦 OmniHuman 公布定价结构,我们将及时通知您。
敬请关注定价更新!
全方位人工智能:优点和缺点
优点
高质量视频输出:生成逼真、引人入胜的视频。
用户友好:只需一个图像和音频文件。
适应性强:适用于各种图像和音频格式。
全身运动能制作逼真的全身动画。
缺点
滥用风险:可能被用于制作深度伪造品和传播错误信息。
伦理问题:引发对真实性和许可的担忧。
容易产生偏见:如果使用不具代表性的数据进行训练,可能会反映出偏见。
目前不对公众开放:目前仅限于研发使用。
常见问题
什么是 OmniHuman AI?
OmniHuman AI 是 Bytedance 开发的一种人工智能工具,可通过一张图像和一个音轨生成逼真的视频。它可以通过同步嘴唇动作、手势和表情制作人像动画和全身视频。
OmniHuman AI 与其他人工智能视频生成器相比有何优势?
它与其他人工智能视频工具的区别在于其更高的性能,可实现以往不可能实现的逼真效果。它超越了当前的方法,即使在音频等输入有限的情况下,也能创建极其逼真的人类视频。它还能适应各种视觉和音频风格,并接受任何长宽比的图像输入,包括肖像、半身和全身镜头。
全方位人工智能能否处理不同的语言?
可以,OmniHuman AI 可以处理多种语言的音频输入和视频输出。
OmniHuman AI 是否能处理动画和卡通图像?
可以!虽然它能通过实际照片提供最逼真的效果,但这种人工智能也能处理卡通和动画人物。
相关问题
还有哪些其他人工智能视频生成工具?
人工智能视频生成领域在不断进步,新工具和新平台层出不穷。OmniHuman AI 以其逼真性和简易性著称,其他重要的替代工具包括VASA-1(微软):专注于实时生成具有准确唇语同步、逼真面部表情和自然头部动作的自然表情。RunwayML:一个全功能的人工智能驱动创意平台,提供视频编辑、风格转换和内容生成工具。Synthesia:这项服务可让你创建人工智能头像,并根据文本制作视频,为培训和营销材料提供经济实惠的选择。DeepMotion:专门从事动作捕捉和动画制作,让你可以通过视频剪辑制作逼真的三维动画。Elai.io:专注于为视频制作人工智能演示器,是培训、产品演示和营销内容的完美选择。请务必对每个选项进行深入研究,选择最符合您的具体要求和预算的方案。此外,还要查看其使用政策,以避免不道德的应用。










 海尔推出全球最轻的人工智能运动外骨骼机器人,重量仅为1.75公斤
海尔集团推出了全球最轻的运动型人工智能外骨骼机器人——海尔外骨骼机器人W3。此次发布创下了行业轻量化新纪录,标志着在轻量化设计和智能人体运动增强领域取得了重大突破。高端材料成就超轻量化设计W3采用创新的一体化制造工艺,融合全碳纤维与钛合金。这种航空级材料组合将总重量控制在仅1.75公斤,实现了轻量化与高强度的完美平衡,展现出极致的机械性能。为提升舒适度,该机器人融入了非牛顿流体材料,触感柔软亲肤,
海尔推出全球最轻的人工智能运动外骨骼机器人,重量仅为1.75公斤
海尔集团推出了全球最轻的运动型人工智能外骨骼机器人——海尔外骨骼机器人W3。此次发布创下了行业轻量化新纪录,标志着在轻量化设计和智能人体运动增强领域取得了重大突破。高端材料成就超轻量化设计W3采用创新的一体化制造工艺,融合全碳纤维与钛合金。这种航空级材料组合将总重量控制在仅1.75公斤,实现了轻量化与高强度的完美平衡,展现出极致的机械性能。为提升舒适度,该机器人融入了非牛顿流体材料,触感柔软亲肤,
 耀科传媒首部AIGC剧集《秦岭青铜之谜》今日上线,主演均由AI生成
今日,耀科传媒的AIGC奇幻悬疑短剧《秦岭青铜秘闻》正式上线。该剧由公司签约的首批两位AI演员秦凌月和林西妍主演,故事背景设定在神秘的秦岭矿区。 剧中,退役情报官秦月率队深入该区域,揭开了一起尘封已久的矿难真相,以及跨越两代人的血祭之谜——这个真相就隐藏在受限的地下区域,那里是科学探索与古代巫术交汇之地。作为中国最早完全由AI数字人支撑的影视作品之一,该剧在筹备阶段便引发了业界热烈讨论,而关于其A
耀科传媒首部AIGC剧集《秦岭青铜之谜》今日上线,主演均由AI生成
今日,耀科传媒的AIGC奇幻悬疑短剧《秦岭青铜秘闻》正式上线。该剧由公司签约的首批两位AI演员秦凌月和林西妍主演,故事背景设定在神秘的秦岭矿区。 剧中,退役情报官秦月率队深入该区域,揭开了一起尘封已久的矿难真相,以及跨越两代人的血祭之谜——这个真相就隐藏在受限的地下区域,那里是科学探索与古代巫术交汇之地。作为中国最早完全由AI数字人支撑的影视作品之一,该剧在筹备阶段便引发了业界热烈讨论,而关于其A
 萨提亚·纳德拉准备利用与OpenAI的新合作关系
周三,一位华尔街分析师直接询问了微软首席执行官萨蒂亚·纳德拉,修订后的OpenAI合作关系将如何影响公司的财务状况。 纳德拉将这一新协议描述为对各方都有利的结果。“我们对与OpenAI的合作感到满意。我始终非常重视任何合作关系,并确保它能够实现双赢。只有这样,双方才能保持良好的合作伙伴关系。” 他强调,微软仍然可以使用OpenAI的知识产权,包括其模型和智能体产品,但不再需要为此向OpenAI支付费用。 谈到在2032年之前可以免费使用OpenAI最先进的人工智能技术,纳德拉表示:“
萨提亚·纳德拉准备利用与OpenAI的新合作关系
周三,一位华尔街分析师直接询问了微软首席执行官萨蒂亚·纳德拉,修订后的OpenAI合作关系将如何影响公司的财务状况。 纳德拉将这一新协议描述为对各方都有利的结果。“我们对与OpenAI的合作感到满意。我始终非常重视任何合作关系,并确保它能够实现双赢。只有这样,双方才能保持良好的合作伙伴关系。” 他强调,微软仍然可以使用OpenAI的知识产权,包括其模型和智能体产品,但不再需要为此向OpenAI支付费用。 谈到在2032年之前可以免费使用OpenAI最先进的人工智能技术,纳德拉表示:“

2026年最新最佳AI报销管理工具:广受好评的解决方案,可自动扫描收据并分类企业支出。探索这些功能强大、颠覆传统的解决方案,助您轻松管理报销、精准追踪财务并简化合规流程。我们精心整理并每周更新的免费与付费选项对比指南,助您找到最适合的工具。通过XIX.AI的专家精选,释放您的AI优势。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
10 个工具
xix.ai

立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai

探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai

探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最优秀的 AI 调情与对话训练工具。我们精心挑选的高评分工具助您实时提升社交魅力与自信。探索这些必试的、颠覆性的工具,查看免费版与付费版的对比,并了解每周更新的排行榜。立即开启您的社交优势。
10 个工具
xix.ai

這技術也太酷了吧!只用一張照片就能生成影片,以後拍片門檻是不是要降到零了?不過想到深度偽造濫用的可能性,又有點擔心... 開發團隊有考慮過倫理防護機制嗎?🤔
제목만 봐도 상상력을 자극하네요! 단 하나의 사진으로 비디오를 만다니, 이게 진짜 기술인가요? 🧐 AI가 이렇게 발전하면 영상 제작자들은 걱정해야 할지도... 제 친구가 요즘 영상 편집하는데 엄청 시간이 걸린다고 하던데, 이런 기술이 실용화되면 업무 방식이 완전히 바뀔 것 같아요. 근데 이런 기술이 악용될 가능성에 대한 논의도 필요하지 않을까요?
Один снимок, а готово целое видео — возможно ли это? OmniHuman AI, судя по всему, делает именно это. Очень впечатляет, хотя лично мне интересно, как технология справляется с движением объектов в кадре, особенно когда изначальная фотография статична. Возможно, в будущем создание фильмов станет куда доступнее для обычных пользователей! 🎥 👏 Надеюсь, это не приведет к распространению фейкового контента.













