
















 家
家オムニヒューマンAIが1枚の画像で映像制作を変える
急速に進化する人工知能の分野で、映像制作を一変させる可能性を秘めた画期的なツールが登場した。OmniHuman AIは、たった1枚の画像と音声ファイルから、驚くほどリアルな動画を作成する最先端のテクノロジーだ。この革新的なソリューションは、エンターテインメント、マーケティング、教育、アクセシビリティ・サービスなど、数多くの業界を再形成しようとしている。しかし、このような強力な技術には重大な責任も伴うため、その広範な意味を理解することが不可欠である。本記事では、OmniHuman AIについて掘り下げ、その印象的な特徴と社会への影響の可能性を探る。
要点
OmniHuman AIは、1つの画像と音声ファイルだけで、本物そっくりの動画を作成する。
これにより、映像コンテンツの作成が非常に簡単になる。
教育、エンターテインメント、マーケティング、アクセシビリティに応用できる。
このテクノロジーは、重要な倫理的問題とともに、大きな可能性を提供する。
OmniHumanの能力、特にフルボディ・アニメーションと詳細なモーションキャプチャーは、現在のAIビデオジェネレーターの能力を超えている。
まだ一般には公開されていないが、今後のリリースが待ち望まれている。
OmniHuman AIを理解する
OmniHuman AIとは?
OmniHuman AIは、人間の動画を生成するための画期的なマルチモダリティ条件付きフレームワークです。そのユニークな特徴は、1つの画像と音声トラックだけを使って、全身をリアルに再現した動画を生成することだ。Bytedance社によって開発された。
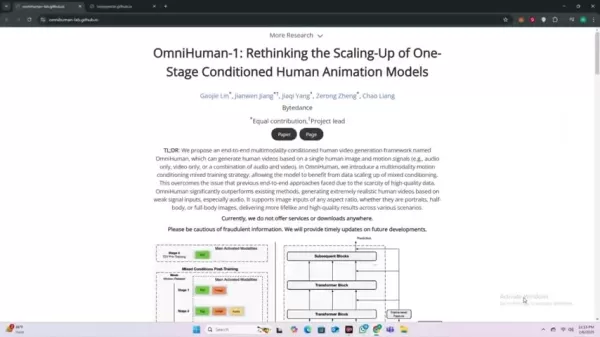
このアプローチはコンテンツ制作を効率化し、リアルな映像制作をこれまで以上に身近なものにする。OmniHumanの最大の強みは、非常に限られた入力からリアルな人間の動き、表情、リップシンクを推測する能力である。OmniHumanは、その優れたパフォーマンスによって他のAIビデオツールとは一線を画し、以前は手の届かなかった成果を達成します。OmniHumanのAIを使用することで、現在の技術は大幅に改善され、音声のような疎な入力からでも非常にリアルな人間の映像が得られ、様々なコンテキストで一貫して自然で忠実度の高い結果を提供します。
このAIは、提供された画像を調べて被写体の特徴を特定し、音声を使用して被写体の動作、表情、発話パターンをガイドします。このシステムは、以下のような幅広いコンテンツを生成することができます:
- リップシンク音声:リップシンクされた音声:音声と口の動きを正確に一致させます。
- 自然なジェスチャー:音声の文脈に合ったリアルな手や体の動きを生成。
- 感情表現:音声の感情を反映した顔や体の表現をアニメーション化します。
OmniHuman AIの仕組み
OmniHuman AIの技術的な強みは、エンド・ツー・エンドでマルチモダリティを条件とするフレームワークにより、人間の映像を生成することにあります。このシステムは、主に高品質なトレーニングデータの不足に起因する、エンドツーエンド・モデルのこれまでの限界を克服する新しい手法を採用しています。OmniHumanは既存のアプローチを大幅に凌駕し、最小限の入力、特に音声から極めてリアルな人物映像を生成する。このAIは、以下を含む高度な機械学習手法のブレンドに依存している:
- ディープラーニング:ディープラーニング(深層学習):画像や音声データの分析と解釈を行う。
- 生成的敵対ネットワーク(GAN):リアルなビデオフレームを生成する。
- モーションキャプチャー技術:人間の動きを正確に再現。
- トランスフォーマー・ネットワーク:これらのモデルは、音声の長距離関係を理解し、対応する動きや映像要素にリンクさせ、映像制作に役立てる。
一般的なプロセスには以下の段階がある:
- 画像と音声の入力:画像と音声の入力:ユーザーが1人の人物の画像と音声を入力する。
- AI処理:OmniHuman AIが画像と音声を処理し、関連する特徴を抽出する。
- ビデオ合成:AIは、音声を話す人物の表情や身振り手振りを含む、本物そっくりのビデオを作成します。
最終的に、様々な用途に適した、滑らかで信頼性の高い映像が完成します。特筆すべきは、AIが頭の動きだけでなく、手のジェスチャーもアニメーション化することで、全体を通して手の一貫性が保たれていることだ。

.
オムニヒューマンAIの技術仕様
以下は、OmniHuman AIのスペックです。
- モデル名オムニヒューマン-1
- 開発者Bytedance
- 論文OmniHuman-1:一段階の条件付き人間アニメーションモデルのスケールアップを再考する
- フレームワークエンドツーエンドのマルチモダリティ条件付き人間動画生成フレームワーク
- インプットOmniHumanは、1つの人間の画像とモーションキュー(例えば、音声のみ、映像のみ、または両方のミックス)から人間のビデオを作成します。
- 機能
- 様々な映像・音声スタイルをサポート
- アスペクト比や体のプロポーションを問わず(1つのモデルでポートレート、ハーフボディ、フルボディのショットに対応)、動き、照明、テクスチャのディテールによってリアルな人物ビデオを生成。
- 複数のボディポーズや歌唱フォーマットに対応。
- 様々な音楽ジャンルに対応し、高音域の歌や様々なモーションを表現。
- あらゆるアスペクト比とボディプロポーションで、リアルな人物映像を制作できます。
- ポートレート、半身、全身など、あらゆるアスペクト比の画像入力に対応
- 利用可能性現在、サービスやダウンロードはどこにも提供されていない。コードベースも公開されていない。
倫理的考察と潜在的リスク
ディープフェイクと誤報
OmniHuman AIを使ってリアルな動画を簡単に作成できることから、悪用される可能性についての懸念も浮上する。この技術が悪用され、ディープフェイク(ありもしないことを誰かが言ったりやったりする様子をリアルに映し出した改変動画)が作成される可能性がある。AIが生成した動画は、虚偽の情報を広めたり、誰かの評判を傷つけたり、あるいは紛争を誘発するために使われるかもしれない。本物の映像とAIが作成した映像の区別は難しくなる。
こうした危険に対処するには、以下のような多面的な戦略が必要だ:
- 検出ツールの作成:検知ツールの構築:ディープフェイクやその他の操作された動画を認識できるAIベースのシステムを構築する。
- メディア・リテラシーの向上:メディア・リテラシーの向上:ディープフェイクやその他のオンライン上の虚偽を見分ける方法を人々に教える。
- 倫理基準の設定:AIが生成した動画を制作・使用する際の業界規範や倫理的ルールを形成する。
- AIのキャラクターを素早く識別できるよう、生成されたコンテンツに一貫したデジタルマーカーを確保する。

バイアスと表現
多くのAIシステムと同様に、OmniHuman AIも学習データによって偏りが生じやすい。学習データに多様性や表現が欠けている場合、AIは否定的なステレオタイプを強化したり、特定のコミュニティを見落としたりするビデオを作成する可能性がある。AIシステムにおけるバイアスへの取り組みには、以下のようなものがある:
- 多様なトレーニングデータの活用:OmniHuman AIのトレーニングに使用されるデータが、様々な人種、性別、文化的背景を表していることを確認する。
- バイアス監査の実施:AIの出力を定期的にチェックし、潜在的なバイアスを発見・軽減する。
- 透明性の奨励:AIのトレーニングデータとアルゴリズムをオープンに共有し、レビューと説明責任を可能にする。
価格設定
OmniHuman AI 価格
現時点では、OmniHumanは研究開発段階にあり、価格に関する情報は発表されていません。OmniHumanの価格体系が明らかになり次第、速やかにお知らせいたします。
価格に関する最新情報にご期待ください!
OmniHuman AI: 長所と短所
長所
高品質のビデオ出力:リアルで説得力のあるビデオを作成します。
ユーザーフレンドリー: 必要なのは1つの画像と音声ファイルのみ。
適応性多様な映像・音声フォーマットに対応。
フルボディの動きリアルな全身アニメーションを作成できます。
短所
悪用の危険性:ディープフェイクの作成や誤った情報の流通に利用される可能性がある。
倫理的問題:真実性や許可に関する懸念が生じる。
バイアスの脆弱性:代表的でないデータで訓練された場合、バイアスが反映される可能性がある。
現在、一般には利用できない:現在は研究開発用途に限定されている。
よくある質問
OmniHuman AIとは何ですか?
OmniHuman AIは、Bytedance社が開発した人工知能ツールで、1枚の画像と音声トラックからリアルな動画を生成することができます。唇の動きやジェスチャー、表情をシンクロさせたポートレートアニメーションやフルボディビデオの作成が可能です。
OmniHuman AIは他のAIビデオジェネレーターと比べてどうですか?
OmniHumanは、その高いパフォーマンスによって他のAIビデオツールとは一線を画し、かつては不可能だったリアルな結果を実現します。音声のような限られた入力でも、非常にリアルな人間のビデオを作成することで、現在の手法を凌駕しています。また、様々なビジュアルやオーディオスタイルに対応し、ポートレート、半身、全身ショットなど、あらゆるアスペクト比の画像入力を受け付けます。
OmniHuman AIは様々な言語に対応できますか?
はい、OmniHuman AIは音声入力と映像出力の両方で複数の言語を処理することができます。
OmniHuman AIはアニメや漫画の画像を処理できますか?
はい!実際の写真で最もリアルな結果を提供しますが、このAIは漫画やアニメの人物も扱うことができます。
関連する質問
他のAI動画生成ツールにはどのようなものがありますか?
AIビデオ生成の分野は絶えず進歩しており、新しいツールやプラットフォームが頻繁に登場しています。OmniHuman AIは、そのリアルさとシンプルさで注目されていますが、他の重要な代替ツールもあります:VASA-1(マイクロソフト):VASA-1(マイクロソフト):正確なリップシンク、リアルな表情、自然な頭の動きを持つ自然な話し相手をリアルタイムで生成することに重点を置いている。RunwayML:ビデオ編集、スタイル転送、コンテンツ生成のためのツールを備えた、フル機能のAI主導型クリエイティブ・プラットフォーム。Synthesia:AIアバターを作成し、テキストからビデオを作成できるサービスで、トレーニングやマーケティング資料に経済的なオプションを提供。DeepMotionモーションキャプチャーとアニメーションに特化し、ビデオクリップからリアルな3Dアニメーションを開発できる。Elai.io:トレーニング、製品デモンストレーション、マーケティングコンテンツに最適。常に各オプションを徹底的に調査し、特定の要件と予算に最もマッチするものを選択する。また、非倫理的なアプリケーションを避けるために、その使用ポリシーを確認してください。
関連記事
 ハイアール、重量わずか1.75kgの世界最軽量AIスポーツ用外骨格ロボットを発表
ハイアールグループは、スポーツ用として世界最軽量のAI搭載外骨格ロボット「ハイアール・エクソスケルトン・ロボット W3」を発表しました。この製品の発売により、軽量化において業界新記録を樹立し、軽量設計と人間の動作をインテリジェントに強化する技術において大きな飛躍を遂げました。高級素材が実現する超軽量設計W3は、フルカーボンファイバーとチタン合金を組み合わせた革新的な一体成型プロセスを採用しています
Yaoke Media初のAIGCドラマ『秦嶺の青銅の謎』が本日配信開始、AIが演じる主演キャストが登場
本日、Yaoke MediaのAIGCファンタジー・ミステリー短編ドラマ『秦嶺青銅の秘話』が正式に公開されました。同社が初めて契約した2人のAI俳優、秦凌月と林西燕燕が主演を務め、物語は謎に包まれた秦嶺の鉱山地帯を舞台に展開されます。 物語は、引退した諜報員・秦月がチームを率いてその奥深くへと入り込み、長年埋もれていた鉱山事故と、2世代にわたる血の生贄の真実を暴いていく様子を描きます。その真実は、
サティヤ・ナデラ、新たなOpenAIとの契約を活用する準備ができている
水曜日に、ウォール・ストリートのアナリストがマイクロソフトのCEOであるサティヤ・ナデラ氏に直接尋ねました。改正されたOpenAIとの提携関係が同社の財務状況にどのような影響を与えるのかと。ナデラ氏はこの新しい協定を「皆にとっての勝利」と表現しました。「OpenAIとの提携については満足しています。私は常にどんな提携でもウィンウィンの関係を築くことに重点を置いています。そうすることで、長期的に良いパートナーシップを維持できるからです。」彼は、マイクロソフトが依然としてOpenAIの知的財産、
関連特集おすすめ
仕事
ハイアール、重量わずか1.75kgの世界最軽量AIスポーツ用外骨格ロボットを発表
ハイアールグループは、スポーツ用として世界最軽量のAI搭載外骨格ロボット「ハイアール・エクソスケルトン・ロボット W3」を発表しました。この製品の発売により、軽量化において業界新記録を樹立し、軽量設計と人間の動作をインテリジェントに強化する技術において大きな飛躍を遂げました。高級素材が実現する超軽量設計W3は、フルカーボンファイバーとチタン合金を組み合わせた革新的な一体成型プロセスを採用しています
Yaoke Media初のAIGCドラマ『秦嶺の青銅の謎』が本日配信開始、AIが演じる主演キャストが登場
本日、Yaoke MediaのAIGCファンタジー・ミステリー短編ドラマ『秦嶺青銅の秘話』が正式に公開されました。同社が初めて契約した2人のAI俳優、秦凌月と林西燕燕が主演を務め、物語は謎に包まれた秦嶺の鉱山地帯を舞台に展開されます。 物語は、引退した諜報員・秦月がチームを率いてその奥深くへと入り込み、長年埋もれていた鉱山事故と、2世代にわたる血の生贄の真実を暴いていく様子を描きます。その真実は、
サティヤ・ナデラ、新たなOpenAIとの契約を活用する準備ができている
水曜日に、ウォール・ストリートのアナリストがマイクロソフトのCEOであるサティヤ・ナデラ氏に直接尋ねました。改正されたOpenAIとの提携関係が同社の財務状況にどのような影響を与えるのかと。ナデラ氏はこの新しい協定を「皆にとっての勝利」と表現しました。「OpenAIとの提携については満足しています。私は常にどんな提携でもウィンウィンの関係を築くことに重点を置いています。そうすることで、長期的に良いパートナーシップを維持できるからです。」彼は、マイクロソフトが依然としてOpenAIの知的財産、
関連特集おすすめ
仕事
 おすすめのAI経費管理ツール:レシートをスキャンして、業務経費を自動分類
おすすめのAI経費管理ツール:レシートをスキャンして、業務経費を自動分類
2026年最新・最高のAI経費管理ツール:レシートをスキャンし、法人経費を自動分類する高評価ツールをご紹介。手間いらずの経費管理、正確な財務追跡、コンプライアンス対応の効率化を実現する、画期的なソリューションをご覧ください。無料版と有料版の比較表は厳選され、毎週更新されるため、最適なツール選びにお役立ていただけます。XIX.AIの専門家が厳選したツールで、AIの力を最大限に活用しましょう。
 10 ツール
10 ツール
 xix.ai
仕事
おすすめのAI採用ツール:履歴書の選考と候補者の面接スケジュール管理を自動化
xix.ai
仕事
おすすめのAI採用ツール:履歴書の選考と候補者の面接スケジュール管理を自動化
XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
10 ツール
xix.ai
生産性
AIパーソナルウェルネス&集中力コーチ:バーンアウトの予防とメンタルエネルギーの向上
XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
10 ツール
xix.ai
チャットボット
高評価のAI恋愛チャットボット:一貫した個性で長期的な関係を築く
2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai
教育と学習
最高のAIデータサイエンスメンター:SQL、Pandas、および機械学習ワークフローをマスターしましょう
2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai
チャットボット
最高のAIを使ったナンパ&会話トレーニング:社交的な魅力と自信をリアルタイムで高める
XIX.AIで、2026年最高のAIを使った口説き術・会話トレーニングツールを発見しましょう。厳選された高評価のツールが、リアルタイムで社交的な魅力と自信を築くお手伝いをします。無料版と有料版の比較や毎週更新されるランキングを参考に、ぜひ試すべき画期的なツールを探してみてください。今すぐ、あなたの社交力を引き出しましょう。
10 ツール
xix.ai

 コメント (3)
0/500
コメント (3)
0/500
![BruceHernández]()
這技術也太酷了吧!只用一張照片就能生成影片,以後拍片門檻是不是要降到零了?不過想到深度偽造濫用的可能性,又有點擔心... 開發團隊有考慮過倫理防護機制嗎?🤔
![RogerJackson]()
제목만 봐도 상상력을 자극하네요! 단 하나의 사진으로 비디오를 만다니, 이게 진짜 기술인가요? 🧐 AI가 이렇게 발전하면 영상 제작자들은 걱정해야 할지도... 제 친구가 요즘 영상 편집하는데 엄청 시간이 걸린다고 하던데, 이런 기술이 실용화되면 업무 방식이 완전히 바뀔 것 같아요. 근데 이런 기술이 악용될 가능성에 대한 논의도 필요하지 않을까요?
![KevinTaylor]()
Один снимок, а готово целое видео — возможно ли это? OmniHuman AI, судя по всему, делает именно это. Очень впечатляет, хотя лично мне интересно, как технология справляется с движением объектов в кадре, особенно когда изначальная фотография статична. Возможно, в будущем создание фильмов станет куда доступнее для обычных пользователей! 🎥 👏 Надеюсь, это не приведет к распространению фейкового контента.
急速に進化する人工知能の分野で、映像制作を一変させる可能性を秘めた画期的なツールが登場した。OmniHuman AIは、たった1枚の画像と音声ファイルから、驚くほどリアルな動画を作成する最先端のテクノロジーだ。この革新的なソリューションは、エンターテインメント、マーケティング、教育、アクセシビリティ・サービスなど、数多くの業界を再形成しようとしている。しかし、このような強力な技術には重大な責任も伴うため、その広範な意味を理解することが不可欠である。本記事では、OmniHuman AIについて掘り下げ、その印象的な特徴と社会への影響の可能性を探る。
要点
OmniHuman AIは、1つの画像と音声ファイルだけで、本物そっくりの動画を作成する。
これにより、映像コンテンツの作成が非常に簡単になる。
教育、エンターテインメント、マーケティング、アクセシビリティに応用できる。
このテクノロジーは、重要な倫理的問題とともに、大きな可能性を提供する。
OmniHumanの能力、特にフルボディ・アニメーションと詳細なモーションキャプチャーは、現在のAIビデオジェネレーターの能力を超えている。
まだ一般には公開されていないが、今後のリリースが待ち望まれている。
OmniHuman AIを理解する
OmniHuman AIとは?
OmniHuman AIは、人間の動画を生成するための画期的なマルチモダリティ条件付きフレームワークです。そのユニークな特徴は、1つの画像と音声トラックだけを使って、全身をリアルに再現した動画を生成することだ。Bytedance社によって開発された。
このアプローチはコンテンツ制作を効率化し、リアルな映像制作をこれまで以上に身近なものにする。OmniHumanの最大の強みは、非常に限られた入力からリアルな人間の動き、表情、リップシンクを推測する能力である。OmniHumanは、その優れたパフォーマンスによって他のAIビデオツールとは一線を画し、以前は手の届かなかった成果を達成します。OmniHumanのAIを使用することで、現在の技術は大幅に改善され、音声のような疎な入力からでも非常にリアルな人間の映像が得られ、様々なコンテキストで一貫して自然で忠実度の高い結果を提供します。
このAIは、提供された画像を調べて被写体の特徴を特定し、音声を使用して被写体の動作、表情、発話パターンをガイドします。このシステムは、以下のような幅広いコンテンツを生成することができます:
- リップシンク音声:リップシンクされた音声:音声と口の動きを正確に一致させます。
- 自然なジェスチャー:音声の文脈に合ったリアルな手や体の動きを生成。
- 感情表現:音声の感情を反映した顔や体の表現をアニメーション化します。
OmniHuman AIの仕組み
OmniHuman AIの技術的な強みは、エンド・ツー・エンドでマルチモダリティを条件とするフレームワークにより、人間の映像を生成することにあります。このシステムは、主に高品質なトレーニングデータの不足に起因する、エンドツーエンド・モデルのこれまでの限界を克服する新しい手法を採用しています。OmniHumanは既存のアプローチを大幅に凌駕し、最小限の入力、特に音声から極めてリアルな人物映像を生成する。このAIは、以下を含む高度な機械学習手法のブレンドに依存している:
- ディープラーニング:ディープラーニング(深層学習):画像や音声データの分析と解釈を行う。
- 生成的敵対ネットワーク(GAN):リアルなビデオフレームを生成する。
- モーションキャプチャー技術:人間の動きを正確に再現。
- トランスフォーマー・ネットワーク:これらのモデルは、音声の長距離関係を理解し、対応する動きや映像要素にリンクさせ、映像制作に役立てる。
一般的なプロセスには以下の段階がある:
- 画像と音声の入力:画像と音声の入力:ユーザーが1人の人物の画像と音声を入力する。
- AI処理:OmniHuman AIが画像と音声を処理し、関連する特徴を抽出する。
- ビデオ合成:AIは、音声を話す人物の表情や身振り手振りを含む、本物そっくりのビデオを作成します。
最終的に、様々な用途に適した、滑らかで信頼性の高い映像が完成します。特筆すべきは、AIが頭の動きだけでなく、手のジェスチャーもアニメーション化することで、全体を通して手の一貫性が保たれていることだ。
.
オムニヒューマンAIの技術仕様
以下は、OmniHuman AIのスペックです。
- モデル名オムニヒューマン-1
- 開発者Bytedance
- 論文OmniHuman-1:一段階の条件付き人間アニメーションモデルのスケールアップを再考する
- フレームワークエンドツーエンドのマルチモダリティ条件付き人間動画生成フレームワーク
- インプットOmniHumanは、1つの人間の画像とモーションキュー(例えば、音声のみ、映像のみ、または両方のミックス)から人間のビデオを作成します。
- 機能
- 様々な映像・音声スタイルをサポート
- アスペクト比や体のプロポーションを問わず(1つのモデルでポートレート、ハーフボディ、フルボディのショットに対応)、動き、照明、テクスチャのディテールによってリアルな人物ビデオを生成。
- 複数のボディポーズや歌唱フォーマットに対応。
- 様々な音楽ジャンルに対応し、高音域の歌や様々なモーションを表現。
- あらゆるアスペクト比とボディプロポーションで、リアルな人物映像を制作できます。
- ポートレート、半身、全身など、あらゆるアスペクト比の画像入力に対応
- 利用可能性現在、サービスやダウンロードはどこにも提供されていない。コードベースも公開されていない。
倫理的考察と潜在的リスク
ディープフェイクと誤報
OmniHuman AIを使ってリアルな動画を簡単に作成できることから、悪用される可能性についての懸念も浮上する。この技術が悪用され、ディープフェイク(ありもしないことを誰かが言ったりやったりする様子をリアルに映し出した改変動画)が作成される可能性がある。AIが生成した動画は、虚偽の情報を広めたり、誰かの評判を傷つけたり、あるいは紛争を誘発するために使われるかもしれない。本物の映像とAIが作成した映像の区別は難しくなる。
こうした危険に対処するには、以下のような多面的な戦略が必要だ:
- 検出ツールの作成:検知ツールの構築:ディープフェイクやその他の操作された動画を認識できるAIベースのシステムを構築する。
- メディア・リテラシーの向上:メディア・リテラシーの向上:ディープフェイクやその他のオンライン上の虚偽を見分ける方法を人々に教える。
- 倫理基準の設定:AIが生成した動画を制作・使用する際の業界規範や倫理的ルールを形成する。
- AIのキャラクターを素早く識別できるよう、生成されたコンテンツに一貫したデジタルマーカーを確保する。
バイアスと表現
多くのAIシステムと同様に、OmniHuman AIも学習データによって偏りが生じやすい。学習データに多様性や表現が欠けている場合、AIは否定的なステレオタイプを強化したり、特定のコミュニティを見落としたりするビデオを作成する可能性がある。AIシステムにおけるバイアスへの取り組みには、以下のようなものがある:
- 多様なトレーニングデータの活用:OmniHuman AIのトレーニングに使用されるデータが、様々な人種、性別、文化的背景を表していることを確認する。
- バイアス監査の実施:AIの出力を定期的にチェックし、潜在的なバイアスを発見・軽減する。
- 透明性の奨励:AIのトレーニングデータとアルゴリズムをオープンに共有し、レビューと説明責任を可能にする。
価格設定
OmniHuman AI 価格
現時点では、OmniHumanは研究開発段階にあり、価格に関する情報は発表されていません。OmniHumanの価格体系が明らかになり次第、速やかにお知らせいたします。
価格に関する最新情報にご期待ください!
OmniHuman AI: 長所と短所
長所
高品質のビデオ出力:リアルで説得力のあるビデオを作成します。
ユーザーフレンドリー: 必要なのは1つの画像と音声ファイルのみ。
適応性多様な映像・音声フォーマットに対応。
フルボディの動きリアルな全身アニメーションを作成できます。
短所
悪用の危険性:ディープフェイクの作成や誤った情報の流通に利用される可能性がある。
倫理的問題:真実性や許可に関する懸念が生じる。
バイアスの脆弱性:代表的でないデータで訓練された場合、バイアスが反映される可能性がある。
現在、一般には利用できない:現在は研究開発用途に限定されている。
よくある質問
OmniHuman AIとは何ですか?
OmniHuman AIは、Bytedance社が開発した人工知能ツールで、1枚の画像と音声トラックからリアルな動画を生成することができます。唇の動きやジェスチャー、表情をシンクロさせたポートレートアニメーションやフルボディビデオの作成が可能です。
OmniHuman AIは他のAIビデオジェネレーターと比べてどうですか?
OmniHumanは、その高いパフォーマンスによって他のAIビデオツールとは一線を画し、かつては不可能だったリアルな結果を実現します。音声のような限られた入力でも、非常にリアルな人間のビデオを作成することで、現在の手法を凌駕しています。また、様々なビジュアルやオーディオスタイルに対応し、ポートレート、半身、全身ショットなど、あらゆるアスペクト比の画像入力を受け付けます。
OmniHuman AIは様々な言語に対応できますか?
はい、OmniHuman AIは音声入力と映像出力の両方で複数の言語を処理することができます。
OmniHuman AIはアニメや漫画の画像を処理できますか?
はい!実際の写真で最もリアルな結果を提供しますが、このAIは漫画やアニメの人物も扱うことができます。
関連する質問
他のAI動画生成ツールにはどのようなものがありますか?
AIビデオ生成の分野は絶えず進歩しており、新しいツールやプラットフォームが頻繁に登場しています。OmniHuman AIは、そのリアルさとシンプルさで注目されていますが、他の重要な代替ツールもあります:VASA-1(マイクロソフト):VASA-1(マイクロソフト):正確なリップシンク、リアルな表情、自然な頭の動きを持つ自然な話し相手をリアルタイムで生成することに重点を置いている。RunwayML:ビデオ編集、スタイル転送、コンテンツ生成のためのツールを備えた、フル機能のAI主導型クリエイティブ・プラットフォーム。Synthesia:AIアバターを作成し、テキストからビデオを作成できるサービスで、トレーニングやマーケティング資料に経済的なオプションを提供。DeepMotionモーションキャプチャーとアニメーションに特化し、ビデオクリップからリアルな3Dアニメーションを開発できる。Elai.io:トレーニング、製品デモンストレーション、マーケティングコンテンツに最適。常に各オプションを徹底的に調査し、特定の要件と予算に最もマッチするものを選択する。また、非倫理的なアプリケーションを避けるために、その使用ポリシーを確認してください。










 ハイアール、重量わずか1.75kgの世界最軽量AIスポーツ用外骨格ロボットを発表
ハイアールグループは、スポーツ用として世界最軽量のAI搭載外骨格ロボット「ハイアール・エクソスケルトン・ロボット W3」を発表しました。この製品の発売により、軽量化において業界新記録を樹立し、軽量設計と人間の動作をインテリジェントに強化する技術において大きな飛躍を遂げました。高級素材が実現する超軽量設計W3は、フルカーボンファイバーとチタン合金を組み合わせた革新的な一体成型プロセスを採用しています
ハイアール、重量わずか1.75kgの世界最軽量AIスポーツ用外骨格ロボットを発表
ハイアールグループは、スポーツ用として世界最軽量のAI搭載外骨格ロボット「ハイアール・エクソスケルトン・ロボット W3」を発表しました。この製品の発売により、軽量化において業界新記録を樹立し、軽量設計と人間の動作をインテリジェントに強化する技術において大きな飛躍を遂げました。高級素材が実現する超軽量設計W3は、フルカーボンファイバーとチタン合金を組み合わせた革新的な一体成型プロセスを採用しています
 Yaoke Media初のAIGCドラマ『秦嶺の青銅の謎』が本日配信開始、AIが演じる主演キャストが登場
本日、Yaoke MediaのAIGCファンタジー・ミステリー短編ドラマ『秦嶺青銅の秘話』が正式に公開されました。同社が初めて契約した2人のAI俳優、秦凌月と林西燕燕が主演を務め、物語は謎に包まれた秦嶺の鉱山地帯を舞台に展開されます。 物語は、引退した諜報員・秦月がチームを率いてその奥深くへと入り込み、長年埋もれていた鉱山事故と、2世代にわたる血の生贄の真実を暴いていく様子を描きます。その真実は、
Yaoke Media初のAIGCドラマ『秦嶺の青銅の謎』が本日配信開始、AIが演じる主演キャストが登場
本日、Yaoke MediaのAIGCファンタジー・ミステリー短編ドラマ『秦嶺青銅の秘話』が正式に公開されました。同社が初めて契約した2人のAI俳優、秦凌月と林西燕燕が主演を務め、物語は謎に包まれた秦嶺の鉱山地帯を舞台に展開されます。 物語は、引退した諜報員・秦月がチームを率いてその奥深くへと入り込み、長年埋もれていた鉱山事故と、2世代にわたる血の生贄の真実を暴いていく様子を描きます。その真実は、
 サティヤ・ナデラ、新たなOpenAIとの契約を活用する準備ができている
水曜日に、ウォール・ストリートのアナリストがマイクロソフトのCEOであるサティヤ・ナデラ氏に直接尋ねました。改正されたOpenAIとの提携関係が同社の財務状況にどのような影響を与えるのかと。ナデラ氏はこの新しい協定を「皆にとっての勝利」と表現しました。「OpenAIとの提携については満足しています。私は常にどんな提携でもウィンウィンの関係を築くことに重点を置いています。そうすることで、長期的に良いパートナーシップを維持できるからです。」彼は、マイクロソフトが依然としてOpenAIの知的財産、
サティヤ・ナデラ、新たなOpenAIとの契約を活用する準備ができている
水曜日に、ウォール・ストリートのアナリストがマイクロソフトのCEOであるサティヤ・ナデラ氏に直接尋ねました。改正されたOpenAIとの提携関係が同社の財務状況にどのような影響を与えるのかと。ナデラ氏はこの新しい協定を「皆にとっての勝利」と表現しました。「OpenAIとの提携については満足しています。私は常にどんな提携でもウィンウィンの関係を築くことに重点を置いています。そうすることで、長期的に良いパートナーシップを維持できるからです。」彼は、マイクロソフトが依然としてOpenAIの知的財産、

2026年最新・最高のAI経費管理ツール:レシートをスキャンし、法人経費を自動分類する高評価ツールをご紹介。手間いらずの経費管理、正確な財務追跡、コンプライアンス対応の効率化を実現する、画期的なソリューションをご覧ください。無料版と有料版の比較表は厳選され、毎週更新されるため、最適なツール選びにお役立ていただけます。XIX.AIの専門家が厳選したツールで、AIの力を最大限に活用しましょう。
10 ツール
xix.ai

XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
10 ツール
xix.ai

XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
10 ツール
xix.ai

2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai

2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAIを使った口説き術・会話トレーニングツールを発見しましょう。厳選された高評価のツールが、リアルタイムで社交的な魅力と自信を築くお手伝いをします。無料版と有料版の比較や毎週更新されるランキングを参考に、ぜひ試すべき画期的なツールを探してみてください。今すぐ、あなたの社交力を引き出しましょう。
10 ツール
xix.ai

這技術也太酷了吧!只用一張照片就能生成影片,以後拍片門檻是不是要降到零了?不過想到深度偽造濫用的可能性,又有點擔心... 開發團隊有考慮過倫理防護機制嗎?🤔
제목만 봐도 상상력을 자극하네요! 단 하나의 사진으로 비디오를 만다니, 이게 진짜 기술인가요? 🧐 AI가 이렇게 발전하면 영상 제작자들은 걱정해야 할지도... 제 친구가 요즘 영상 편집하는데 엄청 시간이 걸린다고 하던데, 이런 기술이 실용화되면 업무 방식이 완전히 바뀔 것 같아요. 근데 이런 기술이 악용될 가능성에 대한 논의도 필요하지 않을까요?
Один снимок, а готово целое видео — возможно ли это? OmniHuman AI, судя по всему, делает именно это. Очень впечатляет, хотя лично мне интересно, как технология справляется с движением объектов в кадре, особенно когда изначальная фотография статична. Возможно, в будущем создание фильмов станет куда доступнее для обычных пользователей! 🎥 👏 Надеюсь, это не приведет к распространению фейкового контента.













