
















 首页
首页什么是 LeetCode 中的数组嵌套?2025 DFS 最佳解决方案指南。
数组嵌套乍看之下可能很复杂,但如果采用正确的策略,它就会变成一项引人入胜的挑战。本指南深入研究了 LeetCode 问题 565 "数组嵌套",全面探讨了如何使用深度优先搜索(DFS)解决该问题。我们将通过问题描述,解释为什么 DFS 是一种有效的方法,分解算法,提供详细的代码示例,并讨论优化策略。最后,您将对数组嵌套和 DFS 有扎实的了解,从而有信心处理类似的问题。
要点
掌握 LeetCode 上数组嵌套的问题陈述(问题 565)。
了解为什么深度优先搜索 (DFS) 非常适合识别数组内的循环。
将 DFS 算法分解为清晰易懂的步骤。
回顾 Java 和 Python 的代码实现。
分析时间和空间复杂性的考虑因素。
探索优化方法,如使用访问数组。
跟随示例逐步加深理解。
了解数组嵌套
问题陈述:LeetCode 565
让我们从问题的正式定义开始。给你一个包含 n 个整数的数组 "nums",其中每个值 "nums[i]"的范围是 [0, n - 1]。这个数组表示从 0 到 n-1 的数字的排列。你的目标是确定按照这个序列形成的最长集合(或循环)的长度:
- 从任意索引 'i' 开始。
- 集合中随后的元素是 "nums[i]"。
- 之后的元素是 "nums[nums[i]]",然后继续这个模式。
- 这个过程一直持续到当前集合中已经遇到的元素为止。
目标是返回在数组中找到的最大此类集合的长度。这个问题考验的是你浏览数组结构和识别循环模式的能力。
为什么深度优先搜索 (DFS) 非常适合
对于涉及循环检测的问题,深度优先搜索(DFS)是一种直观有效的策略。你可以将数组概念化为一个有向图,其中每个索引都指向另一个索引。DFS 擅长于系统地探索这种图,在回溯之前尽可能沿着每个分支进行遍历。以下是它能很好地处理数组嵌套的主要原因:
- 系统探索:DFS 在移动到下一个路径之前,会彻底探索每个潜在路径,确保完整遍历所有循环。
- 循环检测:如果在遍历过程中遇到当前路径中已访问过的节点,则表示已成功识别出一个循环。为此,跟踪已访问过的节点至关重要。
- 效率通过将节点标记为已访问节点,我们可以避免重复计算,从而优化整体解决方案。
替代解决方案
替代方案 1:迭代实现 DFS
深度优先搜索的迭代方法提供了递归的替代方案。以下 Java 代码无需递归即可检测循环并计算其长度,从而避免了潜在的堆栈溢出问题:
import java.util.Arrays;class Solution {public int arrayNesting(int[] nums) {int n = nums.length;boolean[] visited = new boolean[n];int maxLength = 0;for (int start = 0; start这种实现方法的主要优点是:
- 防止堆栈溢出:迭代循环取代了递归,消除了堆栈深度问题
- :
访问- 数组:继续使用单独的数组来有效跟踪哪些元素已被处理
- :迭代减少了递归调用堆栈带来的内存开销。
替代方案 2:就地计算周期长度这种
方法通过直接在输入数组中计算周期长度,提供了一种内存效率更高的解决方案。下面的 Python 代码演示了这种就地计算方法:
class Solution:def arrayNesting(self, nums: List[int]) -> int:n = len(nums)max_length = 0for i in range(n):if nums[i] != -1:# 仅在该索引尚未被处理时继续start = icount = 0while nums[start] != -1:next_index = nums[start]nums[start] = -1# 设置为-1start = next_indexcount += 1max_length = max(max_length, count)return max_length# 示例 Usagenums = [5,4,0,3,1,6,2]solution = Solution()result = solution.arrayNesting(nums)print(f "Length of the longest cycle: {result}") # 输出:4
这种方法的
主要
优点包括:
- 减少内存占用:通过修改原始列表,无需单独的访问数组
- :访问元素直接在输入数组中标记
- :
优化性能:- 这种方法最大限度地减少了内存分配和访问操作
:
访问数组 我们使用一个名为 "visited "的布尔数组,其长度与 "nums "数组相同。一旦我们在任何循环中探索了索引'i'处的元素,visited[i]值就会被设置为 true。
DFS 函数 (dfs(nums, i, visited))
这个递归函数接受 "nums "数组、起始索引 "i "和 "visited "数组。
基本情况:如果visited[
i
]已为真,则表示该元素是我们已测量过
的循环的
一部分。
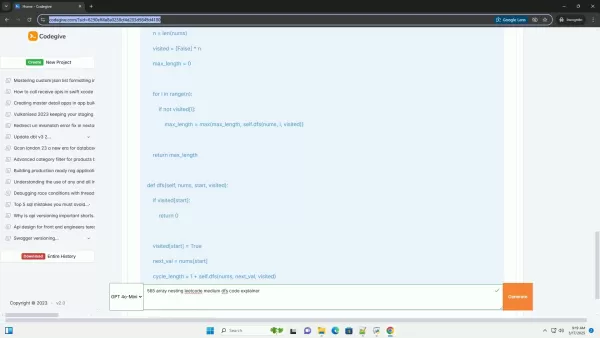
标记为已访问:我们会立即将visited[i]标记为 true,以防止从不同的起点重新进入同一循环
:我们使用next = nums[i]确定下一个索引,然后递归调用dfs(nums,next,visited),继续探索循环
:循环的总长度为 1(当前节点)加上递归调用返回的长度。cycle_length = 1 + dfs(nums,next,visited)。
主函数(arrayNesting(nums))
- 初始化 "visited "数组:
- 将 "maxLength "初始化为 0:该变量将跟踪找到的最长循环
- :遍历 "nums "数组中的每个索引 "i"
- :如果
visited[i]为 false,则从该索引开始 DFS 遍历 - :
max_length = Math.max(max_length,dfs(nums,i,visited)). - 返回 "maxLength":处理完所有索引后,返回
maxLength 的最终值。
DFS
方法
的优点和缺点优点
有效的周期检测:非常适合在像数组这样的类图结构中查找循环
:
清晰的递归结构:清晰的递归结构:递归性质为解决问题提供了直接的逻辑流程。
缺点
堆栈溢出的
可能性
:对于非常大的输入大小,深度递归可能会导致堆栈溢出错误
:
使用 DFS
解决数组嵌套问题
的核心功能和优势主要
代码概念及其帮助
解决数组嵌套问题的 DFS 实现包含几个重要的编程概念,这些概念有助于其取得成功:
- 递归:递归
:- DFS 的递归特性使其能够充分探索数组中的每一条潜在路径,确保不遗漏任何循环
- :
布尔访问- 数组:该数组是提高效率的基础,可防止算法对任何元素进行多次处理
- :当算法试图访问已经是当前遍历路径一部分的节点时,算法会自动检测到循环
- :动态循环长度计算
:- 当 DFS 在数组中前进时,每个循环的长度都会即时计算
- :最大化
步骤:
- 持续更新最大长度,确保最终答案是找到的最大循环。
通过代码示例加深理解为了
说明 DFS 的过程,请看下面的示例:
给定数组nums = [5,4,0,3,1,6,2],DFS 算法的执行
过程
如下:
- 从索引 0 开始,标记索引 0 为已访问,并继续前进到
nums[0] 的值,即 5。 - 从
- 索引 5 开始,将索引 5 标记为已访问,并移动到
-
nums -
[5],即 6。 - 在索引 2 处,算法将其标记为已访问,并发现
nums[2]为 0。由于 0 已被访问,因此循环 [0, 5, 6, 2] 已完成,长度为 4。
算法正确
地
将
- 其
识别
为
最长循环
。这种深度探索使得它可以很自然地检测到路径是否循环回到之前访问过的节点,从而形成循环。广度优先搜索(BFS)更适合寻找最短路径,但对于这项特定任务来说,它就不那么直观了。
能否在不占用额外空间的情况下解决这个问题?可以
,通过修改原始输入数组,可以实现 O(1) 空间的解决方案。你可以直接在 "nums "数组中标记已访问的索引,而不用单独的 "已访问 "数组,只需将其值改为一个哨兵值(如-1)即可。
数组中数字的范围(0 至
n
-1)对解法有何影响?
它保证了数组中的每个值都是数组本身的有效索引。
相关问题
给定一个由 n 个整数组成的数组 nums,其中 nums[i] 的范围是 [0, n - 1],你能写一个函数来查找并返回数组中最长的循环吗?请提供 Java 和 Python 实现
。下面是用于查找最长循环长度的 Java 和 Python 实现:import java.util.Arrays;class Solution {public int arrayNesting(int[] nums) {int n = nums.length;boolean[] visited = new boolean[n];int maxLength = 0;for (int i = 0; i int:n = len(nums)visited = [False] * nmax_length = 0for i in range(n):if not visited[i]:max_length = max(max_length, self.dfs(nums, i, visited))return max_lengthdef dfs(self, nums: List[int], start: int, visited: List[bool]) -> int:if visited[start]:return 0visited[start] = Truenext_val = nums[start]cycle_length = 1 + self.dfs(nums, next_val, visited)return cycle_length# 示例 Usagenums = [5,4,0,3,1,6,2]solution = Solution()result = solution.arrayNesting(nums)print(f "Length of the longest cycle: {result}")# 输出:4这些实现经过优化,可以有效地检测周期并计算其长度,同时使用访问数组来防止不必要的重复处理。
 Luma AI 发布了 Uni-1 自回归模型,该模型可同时生成文本和像素
Luma Labs 于 3 月 23 日发布了其图像生成模型 Uni-1,这是该公司首个基于统一智能架构(Unified Intelligence)构建的公开可用模型。目前,官方网站已开放免费试用,API 定价已公布,企业级访问渠道也将逐步推出。架构转型:从扩散模型转向自回归模型Uni-1摒弃了主流的扩散模型方案,转而采用仅含解码器的自回归Transformer架构。该模型将文本和图像令牌以交替序
英伟达的吴新洲:自动驾驶的“ChatGPT时刻”已然到来,L4级自动驾驶的量产不再是梦想
在快速发展的物理人工智能领域,自动驾驶通常被视为亟待攻克的首个重大挑战。 近日,英伟达副总裁吴新洲在北京的一场交流活动中,阐述了该公司在智能驾驶领域的宏伟愿景。他不仅介绍了支撑辅助驾驶的“五层蛋糕”架构,还为L4级自动驾驶的落地提供了明确的时间表。“五层蛋糕”构建全栈生态系统英伟达已超越单纯的芯片供应,转而致力于通过三大计算平台——车载推理、云端训练和仿真验证——构建一个全面的服务体系。 吴新洲将
Anthropic悄然上调Claude代码定价,开发者日费翻倍
人工智能编程领域的成本压力正日益凸显。领先的人工智能公司Anthropic近期在未发布任何官方公告的情况下,调整了其人工智能编程工具Claude Code的定价。根据该公司网站上新发布的数据,该工具的代币消耗成本现已较此前预估翻了一番。在近期的一份企业部署声明中,Anthropic表示,目前每位开发者的日均成本约为13美元。而在4月16日之前,官方数据仅为6美元。这意味着高频用户的日均支出已从约4
相关专题推荐
聊天机器人
Luma AI 发布了 Uni-1 自回归模型,该模型可同时生成文本和像素
Luma Labs 于 3 月 23 日发布了其图像生成模型 Uni-1,这是该公司首个基于统一智能架构(Unified Intelligence)构建的公开可用模型。目前,官方网站已开放免费试用,API 定价已公布,企业级访问渠道也将逐步推出。架构转型:从扩散模型转向自回归模型Uni-1摒弃了主流的扩散模型方案,转而采用仅含解码器的自回归Transformer架构。该模型将文本和图像令牌以交替序
英伟达的吴新洲:自动驾驶的“ChatGPT时刻”已然到来,L4级自动驾驶的量产不再是梦想
在快速发展的物理人工智能领域,自动驾驶通常被视为亟待攻克的首个重大挑战。 近日,英伟达副总裁吴新洲在北京的一场交流活动中,阐述了该公司在智能驾驶领域的宏伟愿景。他不仅介绍了支撑辅助驾驶的“五层蛋糕”架构,还为L4级自动驾驶的落地提供了明确的时间表。“五层蛋糕”构建全栈生态系统英伟达已超越单纯的芯片供应,转而致力于通过三大计算平台——车载推理、云端训练和仿真验证——构建一个全面的服务体系。 吴新洲将
Anthropic悄然上调Claude代码定价,开发者日费翻倍
人工智能编程领域的成本压力正日益凸显。领先的人工智能公司Anthropic近期在未发布任何官方公告的情况下,调整了其人工智能编程工具Claude Code的定价。根据该公司网站上新发布的数据,该工具的代币消耗成本现已较此前预估翻了一番。在近期的一份企业部署声明中,Anthropic表示,目前每位开发者的日均成本约为13美元。而在4月16日之前,官方数据仅为6美元。这意味着高频用户的日均支出已从约4
相关专题推荐
聊天机器人
 备受好评的AI浪漫聊天机器人:凭借稳定的个性建立长期关系
备受好评的AI浪漫聊天机器人:凭借稳定的个性建立长期关系
探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
 10 个工具
10 个工具
 xix.ai
教育与学习
最佳AI数据科学导师:精通SQL、Pandas及机器学习工作流程
xix.ai
教育与学习
最佳AI数据科学导师:精通SQL、Pandas及机器学习工作流程
探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai
聊天机器人
最佳AI调情与对话训练工具:实时提升社交魅力与自信
在 XIX.AI 上探索 2026 年最优秀的 AI 调情与对话训练工具。我们精心挑选的高评分工具助您实时提升社交魅力与自信。探索这些必试的、颠覆性的工具,查看免费版与付费版的对比,并了解每周更新的排行榜。立即开启您的社交优势。
10 个工具
xix.ai
代码
最适合自动化单元测试的最佳AI工具:一键生成Jest、PyTest和JUnit测试用例
探索2026年最新评选出的顶级AI工具,这些工具专为自动化单元测试而设计。我们精心挑选了那些功能强大、能够改变开发流程的工具,它们能够帮助您快速生成Jest、PyTest和JUnit测试用例。在XIX.AI平台上,您可以免费查看各种选项,并通过实际测试结果以及每周更新的排名来了解它们的优劣。立即利用这些AI工具,提升您的开发效率吧!
10 个工具
xix.ai
数据分析
最佳 AI 数据可视化工具:从原始文件自动生成交互式 BI 仪表盘
在 XIX.AI 探索 2026 年最佳 AI 数据可视化工具。我们精心挑选的顶级工具助您即时从原始文件中自动生成功能强大且交互式的商业智能仪表盘。通过实际测试和每周更新的排行榜,对比免费与付费选项。立即释放您数据的潜力。
10 个工具
xix.ai
社交媒体
适用于社交媒体的 AI 品牌工具包:在所有渠道保持品牌视觉形象的一致性
探索2026年最优秀的社交媒体AI品牌设计套件。XIX.AI精心整理的这份清单汇集了广受好评、具有颠覆性的工具,助您在所有渠道上保持品牌视觉形象的完美一致性。通过实际测试对比免费与付费选项。立即为您的品牌解锁视觉优势。
10 个工具
xix.ai

 评论 (1)
0/500
评论 (1)
0/500
![NicholasLewis]()
Als ich das Problem gestern selbst probiert habe, habe ich ewig gebraucht. Aber die Erklärung hier, wie man mit DFS die optimalen zyklischen Muster findet, ist super nachvollziehbar. Hoffentlich kann ich das bei der nächsten Interview-Frage anwenden. 🤞
数组嵌套乍看之下可能很复杂,但如果采用正确的策略,它就会变成一项引人入胜的挑战。本指南深入研究了 LeetCode 问题 565 "数组嵌套",全面探讨了如何使用深度优先搜索(DFS)解决该问题。我们将通过问题描述,解释为什么 DFS 是一种有效的方法,分解算法,提供详细的代码示例,并讨论优化策略。最后,您将对数组嵌套和 DFS 有扎实的了解,从而有信心处理类似的问题。
要点
掌握 LeetCode 上数组嵌套的问题陈述(问题 565)。
了解为什么深度优先搜索 (DFS) 非常适合识别数组内的循环。
将 DFS 算法分解为清晰易懂的步骤。
回顾 Java 和 Python 的代码实现。
分析时间和空间复杂性的考虑因素。
探索优化方法,如使用访问数组。
跟随示例逐步加深理解。
了解数组嵌套
问题陈述:LeetCode 565
让我们从问题的正式定义开始。给你一个包含 n 个整数的数组 "nums",其中每个值 "nums[i]"的范围是 [0, n - 1]。这个数组表示从 0 到 n-1 的数字的排列。你的目标是确定按照这个序列形成的最长集合(或循环)的长度:
- 从任意索引 'i' 开始。
- 集合中随后的元素是 "nums[i]"。
- 之后的元素是 "nums[nums[i]]",然后继续这个模式。
- 这个过程一直持续到当前集合中已经遇到的元素为止。
目标是返回在数组中找到的最大此类集合的长度。这个问题考验的是你浏览数组结构和识别循环模式的能力。
为什么深度优先搜索 (DFS) 非常适合
对于涉及循环检测的问题,深度优先搜索(DFS)是一种直观有效的策略。你可以将数组概念化为一个有向图,其中每个索引都指向另一个索引。DFS 擅长于系统地探索这种图,在回溯之前尽可能沿着每个分支进行遍历。以下是它能很好地处理数组嵌套的主要原因:
- 系统探索:DFS 在移动到下一个路径之前,会彻底探索每个潜在路径,确保完整遍历所有循环。
- 循环检测:如果在遍历过程中遇到当前路径中已访问过的节点,则表示已成功识别出一个循环。为此,跟踪已访问过的节点至关重要。
- 效率通过将节点标记为已访问节点,我们可以避免重复计算,从而优化整体解决方案。
替代解决方案
替代方案 1:迭代实现 DFS
深度优先搜索的迭代方法提供了递归的替代方案。以下 Java 代码无需递归即可检测循环并计算其长度,从而避免了潜在的堆栈溢出问题:
这种实现方法的主要优点是: 方法通过直接在输入数组中计算周期长度,提供了一种内存效率更高的解决方案。下面的 Python 代码演示了这种就地计算方法: 这种方法的 优点包括: 访问数组 我们使用一个名为 "visited "的布尔数组,其长度与 "nums "数组相同。一旦我们在任何循环中探索了索引'i'处的元素, 这个递归函数接受 "nums "数组、起始索引 "i "和 "visited "数组。 基本情况:如果 i 的循环的 一部分。import java.util.Arrays;class Solution {public int arrayNesting(int[] nums) {int n = nums.length;boolean[] visited = new boolean[n];int maxLength = 0;for (int start = 0; start替代方案 2:就地计算周期长度这种
class Solution:def arrayNesting(self, nums: List[int]) -> int:n = len(nums)max_length = 0for i in range(n):if nums[i] != -1:# 仅在该索引尚未被处理时继续start = icount = 0while nums[start] != -1:next_index = nums[start]nums[start] = -1# 设置为-1start = next_indexcount += 1max_length = max(max_length, count)return max_length# 示例 Usagenums = [5,4,0,3,1,6,2]solution = Solution()result = solution.arrayNesting(nums)print(f "Length of the longest cycle: {result}") # 输出:4主要
优化性能::
visited[i]值就会被设置为 true。DFS 函数 (dfs(nums, i, visited))
visited[]已为真,则表示该元素是我们已测量过
标记为已访问:我们会立即将visited[i]标记为 true,以防止从不同的起点重新进入同一循环
:我们使用next = nums[i]确定下一个索引,然后递归调用dfs(nums,next,visited),继续探索循环
:循环的总长度为 1(当前节点)加上递归调用返回的长度。cycle_length = 1 + dfs(nums,next,visited)。
主函数(arrayNesting(nums))
- 初始化 "visited "数组:
- 将 "maxLength "初始化为 0:该变量将跟踪找到的最长循环
- :遍历 "nums "数组中的每个索引 "i"
- :如果
visited[i]为 false,则从该索引开始 DFS 遍历 - :
max_length = Math.max(max_length,dfs(nums,i,visited)). - 返回 "maxLength":处理完所有索引后,返回
maxLength 的最终值。
DFS
方法
的优点和缺点优点
有效的周期检测:非常适合在像数组这样的类图结构中查找循环
:
清晰的递归结构:清晰的递归结构:递归性质为解决问题提供了直接的逻辑流程。
缺点
堆栈溢出的
可能性
:对于非常大的输入大小,深度递归可能会导致堆栈溢出错误
:
使用 DFS
解决数组嵌套问题
的核心功能和优势主要
代码概念及其帮助
解决数组嵌套问题的 DFS 实现包含几个重要的编程概念,这些概念有助于其取得成功:
- 递归:递归
:- DFS 的递归特性使其能够充分探索数组中的每一条潜在路径,确保不遗漏任何循环
- :
布尔访问- 数组:该数组是提高效率的基础,可防止算法对任何元素进行多次处理
- :当算法试图访问已经是当前遍历路径一部分的节点时,算法会自动检测到循环
- :动态循环长度计算
:- 当 DFS 在数组中前进时,每个循环的长度都会即时计算
- :最大化
步骤:
- 持续更新最大长度,确保最终答案是找到的最大循环。
通过代码示例加深理解为了
说明 DFS 的过程,请看下面的示例:
给定数组nums = [5,4,0,3,1,6,2],DFS 算法的执行
过程
如下:
- 从索引 0 开始,标记索引 0 为已访问,并继续前进到
nums[0] 的值,即 5。 - 从
- 索引 5 开始,将索引 5 标记为已访问,并移动到
-
nums -
[5],即 6。 - 在索引 2 处,算法将其标记为已访问,并发现
nums[2]为 0。由于 0 已被访问,因此循环 [0, 5, 6, 2] 已完成,长度为 4。
算法正确
地
将
- 其
识别
为
最长循环
。这种深度探索使得它可以很自然地检测到路径是否循环回到之前访问过的节点,从而形成循环。广度优先搜索(BFS)更适合寻找最短路径,但对于这项特定任务来说,它就不那么直观了。
能否在不占用额外空间的情况下解决这个问题?可以
,通过修改原始输入数组,可以实现 O(1) 空间的解决方案。你可以直接在 "nums "数组中标记已访问的索引,而不用单独的 "已访问 "数组,只需将其值改为一个哨兵值(如-1)即可。
数组中数字的范围(0 至
n
-1)对解法有何影响?
它保证了数组中的每个值都是数组本身的有效索引。
相关问题
给定一个由 n 个整数组成的数组 nums,其中 nums[i] 的范围是 [0, n - 1],你能写一个函数来查找并返回数组中最长的循环吗?请提供 Java 和 Python 实现
。下面是用于查找最长循环长度的 Java 和 Python 实现:import java.util.Arrays;class Solution {public int arrayNesting(int[] nums) {int n = nums.length;boolean[] visited = new boolean[n];int maxLength = 0;for (int i = 0; i int:n = len(nums)visited = [False] * nmax_length = 0for i in range(n):if not visited[i]:max_length = max(max_length, self.dfs(nums, i, visited))return max_lengthdef dfs(self, nums: List[int], start: int, visited: List[bool]) -> int:if visited[start]:return 0visited[start] = Truenext_val = nums[start]cycle_length = 1 + self.dfs(nums, next_val, visited)return cycle_length# 示例 Usagenums = [5,4,0,3,1,6,2]solution = Solution()result = solution.arrayNesting(nums)print(f "Length of the longest cycle: {result}")# 输出:4这些实现经过优化,可以有效地检测周期并计算其长度,同时使用访问数组来防止不必要的重复处理。










 Luma AI 发布了 Uni-1 自回归模型,该模型可同时生成文本和像素
Luma Labs 于 3 月 23 日发布了其图像生成模型 Uni-1,这是该公司首个基于统一智能架构(Unified Intelligence)构建的公开可用模型。目前,官方网站已开放免费试用,API 定价已公布,企业级访问渠道也将逐步推出。架构转型:从扩散模型转向自回归模型Uni-1摒弃了主流的扩散模型方案,转而采用仅含解码器的自回归Transformer架构。该模型将文本和图像令牌以交替序
Luma AI 发布了 Uni-1 自回归模型,该模型可同时生成文本和像素
Luma Labs 于 3 月 23 日发布了其图像生成模型 Uni-1,这是该公司首个基于统一智能架构(Unified Intelligence)构建的公开可用模型。目前,官方网站已开放免费试用,API 定价已公布,企业级访问渠道也将逐步推出。架构转型:从扩散模型转向自回归模型Uni-1摒弃了主流的扩散模型方案,转而采用仅含解码器的自回归Transformer架构。该模型将文本和图像令牌以交替序
 英伟达的吴新洲:自动驾驶的“ChatGPT时刻”已然到来,L4级自动驾驶的量产不再是梦想
在快速发展的物理人工智能领域,自动驾驶通常被视为亟待攻克的首个重大挑战。 近日,英伟达副总裁吴新洲在北京的一场交流活动中,阐述了该公司在智能驾驶领域的宏伟愿景。他不仅介绍了支撑辅助驾驶的“五层蛋糕”架构,还为L4级自动驾驶的落地提供了明确的时间表。“五层蛋糕”构建全栈生态系统英伟达已超越单纯的芯片供应,转而致力于通过三大计算平台——车载推理、云端训练和仿真验证——构建一个全面的服务体系。 吴新洲将
英伟达的吴新洲:自动驾驶的“ChatGPT时刻”已然到来,L4级自动驾驶的量产不再是梦想
在快速发展的物理人工智能领域,自动驾驶通常被视为亟待攻克的首个重大挑战。 近日,英伟达副总裁吴新洲在北京的一场交流活动中,阐述了该公司在智能驾驶领域的宏伟愿景。他不仅介绍了支撑辅助驾驶的“五层蛋糕”架构,还为L4级自动驾驶的落地提供了明确的时间表。“五层蛋糕”构建全栈生态系统英伟达已超越单纯的芯片供应,转而致力于通过三大计算平台——车载推理、云端训练和仿真验证——构建一个全面的服务体系。 吴新洲将
 Anthropic悄然上调Claude代码定价,开发者日费翻倍
人工智能编程领域的成本压力正日益凸显。领先的人工智能公司Anthropic近期在未发布任何官方公告的情况下,调整了其人工智能编程工具Claude Code的定价。根据该公司网站上新发布的数据,该工具的代币消耗成本现已较此前预估翻了一番。在近期的一份企业部署声明中,Anthropic表示,目前每位开发者的日均成本约为13美元。而在4月16日之前,官方数据仅为6美元。这意味着高频用户的日均支出已从约4
Anthropic悄然上调Claude代码定价,开发者日费翻倍
人工智能编程领域的成本压力正日益凸显。领先的人工智能公司Anthropic近期在未发布任何官方公告的情况下,调整了其人工智能编程工具Claude Code的定价。根据该公司网站上新发布的数据,该工具的代币消耗成本现已较此前预估翻了一番。在近期的一份企业部署声明中,Anthropic表示,目前每位开发者的日均成本约为13美元。而在4月16日之前,官方数据仅为6美元。这意味着高频用户的日均支出已从约4

探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai

探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最优秀的 AI 调情与对话训练工具。我们精心挑选的高评分工具助您实时提升社交魅力与自信。探索这些必试的、颠覆性的工具,查看免费版与付费版的对比,并了解每周更新的排行榜。立即开启您的社交优势。
10 个工具
xix.ai

探索2026年最新评选出的顶级AI工具,这些工具专为自动化单元测试而设计。我们精心挑选了那些功能强大、能够改变开发流程的工具,它们能够帮助您快速生成Jest、PyTest和JUnit测试用例。在XIX.AI平台上,您可以免费查看各种选项,并通过实际测试结果以及每周更新的排名来了解它们的优劣。立即利用这些AI工具,提升您的开发效率吧!
10 个工具
xix.ai

在 XIX.AI 探索 2026 年最佳 AI 数据可视化工具。我们精心挑选的顶级工具助您即时从原始文件中自动生成功能强大且交互式的商业智能仪表盘。通过实际测试和每周更新的排行榜,对比免费与付费选项。立即释放您数据的潜力。
10 个工具
xix.ai

探索2026年最优秀的社交媒体AI品牌设计套件。XIX.AI精心整理的这份清单汇集了广受好评、具有颠覆性的工具,助您在所有渠道上保持品牌视觉形象的完美一致性。通过实际测试对比免费与付费选项。立即为您的品牌解锁视觉优势。
10 个工具
xix.ai

Als ich das Problem gestern selbst probiert habe, habe ich ewig gebraucht. Aber die Erklärung hier, wie man mit DFS die optimalen zyklischen Muster findet, ist super nachvollziehbar. Hoffentlich kann ich das bei der nächsten Interview-Frage anwenden. 🤞













