
















 Maison
Maison
Qu'est-ce que l'imbrication de tableaux dans LeetCode ? Un guide DFS 2025 pour des solutions optimales.
L'imbrication de tableaux peut sembler complexe au premier abord, mais avec la bonne stratégie, elle se transforme en un défi intriguant. Ce guide examine en détail le problème LeetCode 565, Imbrication de tableaux, et propose une exploration complète de la manière de le résoudre en utilisant la recherche en profondeur (DFS). Nous décrirons le problème, expliquerons pourquoi la recherche en profondeur est une méthode efficace, décomposerons l'algorithme, fournirons des exemples de code détaillés et discuterons des tactiques d'optimisation. En conclusion, vous posséderez une solide compréhension de l'imbrication des tableaux et de la DFS, ce qui vous permettra de traiter des problèmes similaires en toute confiance.
Points clés
Comprendre l'énoncé du problème de l'imbrication de tableaux sur LeetCode (problème 565).
Apprendre pourquoi la recherche en profondeur (DFS) est bien adaptée à l'identification des cycles dans les tableaux.
Déconstruire l'algorithme DFS en étapes claires et gérables.
Examiner les implémentations de code en Java et en Python.
Analyser les considérations relatives à la complexité du temps et de l'espace.
Découvrir des méthodes d'optimisation, telles que l'utilisation d'un tableau visité.
Suivre un exemple étape par étape pour renforcer votre compréhension.
Comprendre l'imbrication des tableaux
Énoncé du problème : LeetCode 565
Commençons par une définition formelle du problème. On vous donne un tableau "nums" contenant "n" entiers, où chaque valeur "nums[i]" est comprise dans l'intervalle [0, n - 1]. Ce tableau représente une permutation des nombres de 0 à n-1. Votre objectif est de déterminer la longueur du plus long ensemble (ou cycle) formé en suivant cette séquence :
- Commencez à n'importe quel indice "i".
- L'élément suivant de l'ensemble est "nums[i]".
- L'élément suivant est "nums[nums[i]]", et vous continuez ainsi.
- Ce processus se poursuit jusqu'à ce que vous atteigniez un élément qui a déjà été rencontré dans l'ensemble actuel.
L'objectif est de renvoyer la longueur du plus grand ensemble de ce type trouvé dans le tableau. Ce problème met à l'épreuve votre capacité à naviguer dans les structures de tableaux et à identifier les modèles cycliques.
Pourquoi la recherche en profondeur (DFS) est-elle adaptée ?
La recherche en profondeur d'abord (DFS) est une stratégie intuitive et efficace pour les problèmes impliquant la détection de cycles. Vous pouvez conceptualiser le tableau comme un graphe orienté, où chaque index vous dirige vers un autre index. La méthode DFS permet d'explorer systématiquement de tels graphes en parcourant autant que possible chaque branche avant de revenir en arrière. Voici les principales raisons pour lesquelles il fonctionne bien pour l'imbrication de tableaux :
- Exploration systématique : DFS explore minutieusement chaque chemin potentiel avant de passer au suivant, garantissant ainsi une traversée complète de tous les cycles.
- Détection des cycles : Si, au cours de la traversée, vous rencontrez un nœud déjà visité dans le chemin actuel, vous avez réussi à identifier un cycle. Le suivi des nœuds visités est essentiel à cet effet.
- Efficacité : En marquant les nœuds comme visités, nous évitons les calculs redondants, ce qui optimise la solution globale.
Solutions alternatives
Alternative 1 : Mise en œuvre itérative de la méthode DFS
Cette approche itérative de la recherche en profondeur offre une alternative à la récursivité. Le code Java suivant détecte les cycles et calcule leur longueur sans récursivité, évitant ainsi les problèmes potentiels de dépassement de pile :
import java.util.Arrays;class Solution {public int arrayNesting(int[] nums) {int n = nums.length;boolean[] visited = new boolean[n];int maxLength = 0;for (int start = 0 ; start Les principaux avantages de cette implémentation sont les suivants:
- Prévention du débordement de pile :
- Une boucle itérative remplace la récursion, ce qui élimine les problèmes de profondeur de pile
- :
- La boucle itérative continue d'utiliser un tableau séparé pour suivre efficacement les éléments qui ont été traités.
- Efficacité de la mémoire :
- L'itération réduit la surcharge de mémoire associée aux piles d'appels récursifs.
Alternative 2 : Calcul de la longueur de cycle en placeCette
méthode offre une solution plus efficace en termes de mémoire en calculant les longueurs de cycle directement dans le tableau d'entrée.
Le code Python suivant illustre cette approche sur place:
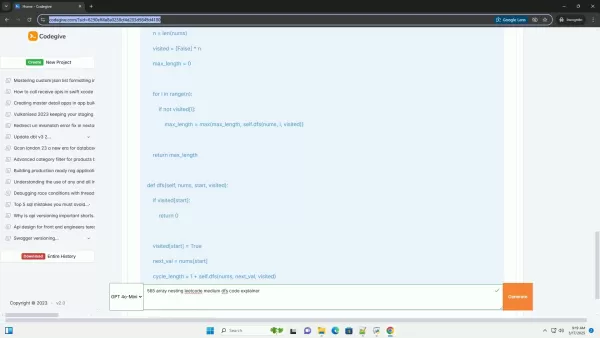
class Solution:def arrayNesting(self, nums : List[int]) -> int:n = len(nums)max_length = 0for i in range(n):if nums[i] != -1:# Ne procéder que si cet index n'a pas été traitéstart = icount = 0while nums[start] != -1:next_index = nums[start]nums[start] = -1# Marquer comme visité en mettant à -1start = next_indexcount += 1max_length = max(max_length, count)return max_length# Exemple Usagenums = [5,4,0,3,1,6,2]solution = Solution()result = solution.arrayNesting(nums)print(f "Longueur du cycle le plus long : {result}") # Sortie :
4Les principaux
avantages de cette approche sont les suivants:
- Empreinte mémoire réduite :
- Elle élimine le besoin d'un tableau visité distinct en modifiant la liste d'origine.
- Modification en place :
- Les éléments visités sont marqués directement dans le tableau d'entrée
- :
- Cette méthode minimise l'allocation de mémoire et les opérations d'accès.
Algorithme DFS :
Mise en œuvre étape par étape
Tableau visité
Nous utilisons un tableau booléen nommé "visité", qui a la même longueur que le tableau "nums". La valeur visited[i] est définie comme vraie lorsque nous avons exploré l'élément à l'index "i" au cours d'un cycle.
Cette fonction récursive accepte le tableau "nums", un indice de départ "i" et le tableau "visited".
Elle effectue une recherche en profondeur en commençant par l'indice "i" et renvoie la longueur du cycle découvert.
Cas de base : si visited[i] est déjà vrai, cela indique que cet élément fait partie d'un cycle que nous avons déjà mesuré.
La fonction renvoie 0 pour éviter tout travail redondant.
Marquer comme visité :
Nous marquons immédiatement visited[i] comme vrai pour éviter d'entrer à nouveau dans le même cycle à partir d'un point de départ différent
:
Nous déterminons l'index suivant en utilisant next = nums[i], puis nous faisons un appel récursif à dfs(nums, next, visited) pour continuer à explorer le cycle.
Calculer la longueur du cycle : La longueur totale du cycle est égale à 1 (pour le nœud actuel) plus la longueur renvoyée par l'appel récursif.
Cette valeur est ensuite renvoyée.cycle_length = 1 + dfs(nums, next, visited).
La fonction principale (arrayNesting(nums))
- Initialiser le tableau 'visited' :
- Créer un tableau booléen de taille n, en fixant toutes les valeurs à false.
- Initialiser 'maxLength' à 0 : Cette variable suivra le cycle le plus long trouvé.
- Itérer à travers chaque index :
- Bouclez sur chaque index "i" du tableau "nums".
- Vérifiez si visité :
- Si
visited[i] est faux, lancer une traversée DFS à partir de cet index. - Mettre à jour 'maxLength' :
- Comparer la longueur du cycle trouvé avec la
longueur maximale actuelle et la mettre à jour si la nouvelle longueur est supérieure. max_length = Math.max(max_length, dfs(nums, i, visited)). - Return 'maxLength' :
- Après traitement de tous les indices, la valeur finale de
maxLength est renvoyée.
pricingtitlepricingAvantages
et inconvénients de l'approche
DFSAvantages
Détection efficace des cycles :
Convient parfaitement à la recherche de cycles dans des structures de type graphique telles que ce tableau.
Traversée systématique :
Garantit que chaque chemin et cycle potentiel est entièrement exploré.
Structure récursive claire : La nature récursive fournit un flux direct et logique pour résoudre le problème.
InconvénientsPotentiel
de dépassement de pile :
Pour les entrées de très grande taille, la récursivité profonde peut provoquer des erreurs de débordement de pile.
Complexité spatiale :
Nécessite de la mémoire supplémentaire pour le tableau visité et la pile de récursion, ce qui augmente l'utilisation de l'espace.
Caractéristiques principales et avantages de l'utilisation de DFS pour l'imbrication de
tableauxConcepts
clés du
code et leur utilitéL'
implémentation de DFS pour résoudre le problème de l'imbrication de tableaux intègre plusieurs concepts de programmation importants qui contribuent à son succès:
- Récursivité :
- La nature récursive de DFS lui permet d'explorer pleinement chaque chemin potentiel dans le tableau, en s'assurant qu'aucun cycle n'est manqué.
- Tableau booléen visité :
- Ce tableau est fondamental pour l'efficacité, car il empêche l'algorithme de traiter un élément plus d'une fois.
- Logique de détection des cycles :
- L'algorithme détecte intrinsèquement un cycle lorsqu'il tente de visiter un nœud qui fait déjà partie du chemin actuel.
- Calcul dynamique de la longueur du cycle :
- La longueur de chaque cycle est calculée à la volée au fur et à mesure que le DFS progresse dans le tableau.
- Étape de maximisation :
- La mise à jour continue de la longueur maximale garantit que la réponse finale est le plus grand cycle trouvé.
Meilleure compréhension grâce à un exemple de codePour
illustrer le processus DFS, considérons cet exemple:
Étant donné le tableau nums = [5,4,0,3,1,6,2], l'algorithme DFS s'exécute comme suit:
- En commençant par l'index 0, il marque l'index 0 comme visité et passe à la valeur de
nums[0], qui est 5. - À partir de l'index 5, il marque l'index 5 comme visité et se rend à
nums[5], qui vaut 6. - À partir de l'index 6, il marque l'index 6 comme visité et se rend à
nums[6], qui vaut 2. - A l'index 2, l'algorithme le marque comme visité et trouve que
nums[2] est 0. Puisque 0 a déjà été visité, le cycle [0, 5, 6, 2] est complet, avec une longueur de 4.
L'algorithme identifie correctement ce cycle comme le plus long.
Use
Casestitleuse_casesFrequently
Asked Questions
Pourquoi DFS est-il préféré à d'autres algorithmes de parcours de graphe comme BFS pour ce problème ?
DFS est généralement plus adapté à la détection de cycles car il explore un chemin aussi profondément que possible avant de revenir sur ses pas. Cette exploration en profondeur permet de détecter naturellement lorsqu'un chemin revient en boucle sur un nœud précédemment visité, formant ainsi un cycle. La méthode BFS (Breadth-First Search) est mieux adaptée à la recherche des chemins les plus courts et est moins intuitive pour cette tâche spécifique.
Ce problème peut-il être résolu sans utiliser d'espace supplémentaire ?
Oui, une solution O(1) est possible en modifiant le tableau d'entrée original. Au lieu d'un tableau "visited" séparé, vous pouvez marquer les indices visités directement dans le tableau "nums" en changeant leurs valeurs pour une valeur sentinelle comme -1. Il est important de noter que cette approche modifie les données d'entrée originales.
Comment la plage de nombres dans le tableau (0 à n-1) influence-t-elle la solution ?
La contrainte selon laquelle toutes les valeurs sont comprises entre 0 et n-1 est cruciale. Elle garantit que chaque valeur du tableau est un index valide dans le tableau lui-même.
Cette propriété est ce qui rend le problème de détection de cycle bien défini et soluble en utilisant des techniques de traversée de graphe comme DFS.
Questions connexes
Etant donné un tableau nums de n entiers où nums[i] est dans l'intervalle [0, n - 1], pouvez-vous écrire une fonction pour trouver et renvoyer le cycle le plus long dans le tableau ?
Fournissez les implémentations en Java et en Python
. Voici des implémentations en Java et en Python conçues pour trouver la longueur du cycle le plus long:import java.util.Arrays;class Solution {public int arrayNesting(int[] nums) {int n = nums.length;boolean[] visited = new boolean[n];int maxLength = 0;for (int i = 0 ; i int:n = len(nums)visited = [False] * nmax_length = 0for i in range(n):if not visited[i]:max_length = max(max_length, self.dfs(nums, i, visited))return max_lengthdef dfs(self, nums : List[int], start : int, visited : List[bool]) -> int:if visited[start]:return 0visited[start] = Truenext_val = nums[start]cycle_length = 1 + self.dfs(nums, next_val, visited)return cycle_length# Exemple Usagenums = [5,4,0,3,1,6,2]solution = Solution()result = solution.arrayNesting(nums)print(f "Longueur du cycle le plus long : {result}")# Sortie : 4Ces implémentations sont optimisées pour détecter efficacement les cycles et calculer leurs longueurs, en utilisant un tableau visité pour éviter tout retraitement inutile.
Article connexe
 Doubao s'apprête à lancer des fonctionnalités payantes, accélérant ainsi la monétisation des grands modèles de ByteDance
Le marché des grands modèles en Chine connaît actuellement une évolution notable, passant d'un accès gratuit à des abonnements payants. Selon des rapports récents, Douyin, le produit phare de ByteDanc
OpenAI s'associe à Gradient Labs pour créer un gestionnaire de relation client numérique basé sur l'IA destiné aux banques
Le 1er avril 2026, OpenAI a annoncé une collaboration étroite avec Gradient Labs, une start-up spécialisée dans l'IA financière. Ce partenariat s'appuie sur les derniers modèles de la série GPT-5.4 po
Les jetons IA constituent-ils une nouvelle prime à la signature ou simplement une charge d'exploitation ?
Cette semaine, un sujet qui circulait depuis un certain temps dans la Silicon Valley a enfin retenu l’attention du grand public : l’intégration de jetons d’IA dans la rémunération. Le concept est simp
Recommandations de sujets spéciaux liés
code
Doubao s'apprête à lancer des fonctionnalités payantes, accélérant ainsi la monétisation des grands modèles de ByteDance
Le marché des grands modèles en Chine connaît actuellement une évolution notable, passant d'un accès gratuit à des abonnements payants. Selon des rapports récents, Douyin, le produit phare de ByteDanc
OpenAI s'associe à Gradient Labs pour créer un gestionnaire de relation client numérique basé sur l'IA destiné aux banques
Le 1er avril 2026, OpenAI a annoncé une collaboration étroite avec Gradient Labs, une start-up spécialisée dans l'IA financière. Ce partenariat s'appuie sur les derniers modèles de la série GPT-5.4 po
Les jetons IA constituent-ils une nouvelle prime à la signature ou simplement une charge d'exploitation ?
Cette semaine, un sujet qui circulait depuis un certain temps dans la Silicon Valley a enfin retenu l’attention du grand public : l’intégration de jetons d’IA dans la rémunération. Le concept est simp
Recommandations de sujets spéciaux liés
code
 Meilleurs outils d'IA pour les tests unitaires automatisés : générer des cas de test Jest, PyTest et JUnit en un clic
Meilleurs outils d'IA pour les tests unitaires automatisés : générer des cas de test Jest, PyTest et JUnit en un clic
Découvrez les derniers outils d'IA hautement réputés de 2026 pour les tests unitaires automatisés. Notre sélection rigoureusement élaborée vous propose des solutions puissantes et révolutionnaires pour générer instantanément des cas de test Jest, PyTest et JUnit. Comparez les options gratuites et payantes à l'aide de tests réels et des classements mises à jour chaque semaine sur XIX.AI. Développez un avantage concurrentiel grâce à l'IA et améliorez rapidement votre productivité en développement.
 10 outils
10 outils
 xix.ai
Analyse des données
Les meilleurs outils de visualisation de données basés sur l'IA : générez automatiquement des tableaux de bord BI interactifs à partir de fichiers bruts
xix.ai
Analyse des données
Les meilleurs outils de visualisation de données basés sur l'IA : générez automatiquement des tableaux de bord BI interactifs à partir de fichiers bruts
Découvrez les meilleurs outils de visualisation de données par IA de 2026 sur XIX.AI. Notre sélection rigoureuse et hautement notée vous aide à générer instantanément et automatiquement des tableaux de bord BI puissants et interactifs à partir de fichiers bruts. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Libérez dès aujourd'hui le potentiel de vos données.
10 outils
xix.ai
Réseaux sociaux
Kits de marque basés sur l'IA pour les réseaux sociaux : assurez la cohérence visuelle de votre marque sur tous les canaux
Découvrez les meilleurs kits de branding IA pour les réseaux sociaux en 2026. La sélection de XIX.AI regroupe des outils de premier plan qui changent la donne et vous permettent de garantir une cohérence visuelle parfaite de votre marque sur tous les canaux. Comparez les options gratuites et payantes grâce à des tests concrets. Donnez dès aujourd'hui un coup de pouce visuel à votre marque.
10 outils
xix.ai
chatbot
Les meilleures applications de petite amie virtuelle et outils d'accompagnement IA pour les jeux de rôle (Guide 2026)
Découvrez les meilleurs outils d'IA de 2026 pour des jeux de rôle immersifs et des interactions enrichissantes. Le guide sélectionné par XIX.AI présente des applications puissantes et révolutionnaires, avec des classements mis à jour chaque semaine, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le partenaire idéal et profitez dès aujourd'hui d'une compagnie numérique enrichissante.
10 outils
xix.ai
en écrivant
Les meilleurs assistants IA pour les genres xianxia et wuxia : rédigez des récits épiques de progression spirituelle et des chorégraphies d'arts martiaux
Découvrez les meilleurs assistants IA de 2026 pour créer des récits épiques de xianxia et de wuxia. La sélection de XIX.AI regroupe les outils les mieux notés et les plus innovants pour maîtriser la progression dans la voie de la cultivation et la chorégraphie des arts martiaux. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez à écrire dès aujourd'hui !
10 outils
xix.ai
code
Outils de codage pour applications mobiles AI : générer du code Flutter et React Native multiplateforme à partir de commandes.
Découvrez les 20 meilleurs outils de codage pour applications mobiles basées sur l'IA en 2026, conçus pour Flutter et React Native. Notre liste, soigneusement sélectionnée et hautement réputée, met en avant des solutions puissantes qui permettent de générer du code multiplateforme à partir de simples instructions. Comparez les options gratuites et payantes grâce à des tests pratiques. Accélérez votre développement et créez de meilleures applications. Consultez le classement sur XIX.AI dès maintenant !
10 outils
xix.ai

 commentaires (1)
commentaires (1)
![NicholasLewis]()
Als ich das Problem gestern selbst probiert habe, habe ich ewig gebraucht. Aber die Erklärung hier, wie man mit DFS die optimalen zyklischen Muster findet, ist super nachvollziehbar. Hoffentlich kann ich das bei der nächsten Interview-Frage anwenden. 🤞
L'imbrication de tableaux peut sembler complexe au premier abord, mais avec la bonne stratégie, elle se transforme en un défi intriguant. Ce guide examine en détail le problème LeetCode 565, Imbrication de tableaux, et propose une exploration complète de la manière de le résoudre en utilisant la recherche en profondeur (DFS). Nous décrirons le problème, expliquerons pourquoi la recherche en profondeur est une méthode efficace, décomposerons l'algorithme, fournirons des exemples de code détaillés et discuterons des tactiques d'optimisation. En conclusion, vous posséderez une solide compréhension de l'imbrication des tableaux et de la DFS, ce qui vous permettra de traiter des problèmes similaires en toute confiance.
Points clés
Comprendre l'énoncé du problème de l'imbrication de tableaux sur LeetCode (problème 565).
Apprendre pourquoi la recherche en profondeur (DFS) est bien adaptée à l'identification des cycles dans les tableaux.
Déconstruire l'algorithme DFS en étapes claires et gérables.
Examiner les implémentations de code en Java et en Python.
Analyser les considérations relatives à la complexité du temps et de l'espace.
Découvrir des méthodes d'optimisation, telles que l'utilisation d'un tableau visité.
Suivre un exemple étape par étape pour renforcer votre compréhension.
Comprendre l'imbrication des tableaux
Énoncé du problème : LeetCode 565
Commençons par une définition formelle du problème. On vous donne un tableau "nums" contenant "n" entiers, où chaque valeur "nums[i]" est comprise dans l'intervalle [0, n - 1]. Ce tableau représente une permutation des nombres de 0 à n-1. Votre objectif est de déterminer la longueur du plus long ensemble (ou cycle) formé en suivant cette séquence :
- Commencez à n'importe quel indice "i".
- L'élément suivant de l'ensemble est "nums[i]".
- L'élément suivant est "nums[nums[i]]", et vous continuez ainsi.
- Ce processus se poursuit jusqu'à ce que vous atteigniez un élément qui a déjà été rencontré dans l'ensemble actuel.
L'objectif est de renvoyer la longueur du plus grand ensemble de ce type trouvé dans le tableau. Ce problème met à l'épreuve votre capacité à naviguer dans les structures de tableaux et à identifier les modèles cycliques.
Pourquoi la recherche en profondeur (DFS) est-elle adaptée ?
La recherche en profondeur d'abord (DFS) est une stratégie intuitive et efficace pour les problèmes impliquant la détection de cycles. Vous pouvez conceptualiser le tableau comme un graphe orienté, où chaque index vous dirige vers un autre index. La méthode DFS permet d'explorer systématiquement de tels graphes en parcourant autant que possible chaque branche avant de revenir en arrière. Voici les principales raisons pour lesquelles il fonctionne bien pour l'imbrication de tableaux :
- Exploration systématique : DFS explore minutieusement chaque chemin potentiel avant de passer au suivant, garantissant ainsi une traversée complète de tous les cycles.
- Détection des cycles : Si, au cours de la traversée, vous rencontrez un nœud déjà visité dans le chemin actuel, vous avez réussi à identifier un cycle. Le suivi des nœuds visités est essentiel à cet effet.
- Efficacité : En marquant les nœuds comme visités, nous évitons les calculs redondants, ce qui optimise la solution globale.
Solutions alternatives
Alternative 1 : Mise en œuvre itérative de la méthode DFS
Cette approche itérative de la recherche en profondeur offre une alternative à la récursivité. Le code Java suivant détecte les cycles et calcule leur longueur sans récursivité, évitant ainsi les problèmes potentiels de dépassement de pile :
Les principaux avantages de cette implémentation sont les suivants: méthode offre une solution plus efficace en termes de mémoire en calculant les longueurs de cycle directement dans le tableau d'entrée. Le code Python suivant illustre cette approche sur place: avantages de cette approche sont les suivants: Nous utilisons un tableau booléen nommé "visité", qui a la même longueur que le tableau "nums". La valeur Cette fonction récursive accepte le tableau "nums", un indice de départ "i" et le tableau "visited". Elle effectue une recherche en profondeur en commençant par l'indice "i" et renvoie la longueur du cycle découvert. Cas de base : si La fonction renvoie 0 pour éviter tout travail redondant. Marquer comme visité : Nous marquons immédiatement : Nous déterminons l'index suivant en utilisant Calculer la longueur du cycle : La longueur totale du cycle est égale à 1 (pour le nœud actuel) plus la longueur renvoyée par l'appel récursif. Cette valeur est ensuite renvoyée. pricingtitlepricingAvantages Détection efficace des cycles : Convient parfaitement à la recherche de cycles dans des structures de type graphique telles que ce tableau. Traversée systématique : Garantit que chaque chemin et cycle potentiel est entièrement exploré. Structure récursive claire : La nature récursive fournit un flux direct et logique pour résoudre le problème. de dépassement de pile : Pour les entrées de très grande taille, la récursivité profonde peut provoquer des erreurs de débordement de pile. Complexité spatiale : Nécessite de la mémoire supplémentaire pour le tableau visité et la pile de récursion, ce qui augmente l'utilisation de l'espace. implémentation de DFS pour résoudre le problème de l'imbrication de tableaux intègre plusieurs concepts de programmation importants qui contribuent à son succès: illustrer le processus DFS, considérons cet exemple: Étant donné le tableau L'algorithme identifie correctement ce cycle comme le plus long. Casestitleuse_casesFrequently DFS est généralement plus adapté à la détection de cycles car il explore un chemin aussi profondément que possible avant de revenir sur ses pas. Cette exploration en profondeur permet de détecter naturellement lorsqu'un chemin revient en boucle sur un nœud précédemment visité, formant ainsi un cycle. La méthode BFS (Breadth-First Search) est mieux adaptée à la recherche des chemins les plus courts et est moins intuitive pour cette tâche spécifique. Oui, une solution O(1) est possible en modifiant le tableau d'entrée original. Au lieu d'un tableau "visited" séparé, vous pouvez marquer les indices visités directement dans le tableau "nums" en changeant leurs valeurs pour une valeur sentinelle comme -1. Il est important de noter que cette approche modifie les données d'entrée originales. La contrainte selon laquelle toutes les valeurs sont comprises entre 0 et n-1 est cruciale. Elle garantit que chaque valeur du tableau est un index valide dans le tableau lui-même. Cette propriété est ce qui rend le problème de détection de cycle bien défini et soluble en utilisant des techniques de traversée de graphe comme DFS. . Voici des implémentations en Java et en Python conçues pour trouver la longueur du cycle le plus long:import java.util.Arrays;class Solution {public int arrayNesting(int[] nums) {int n = nums.length;boolean[] visited = new boolean[n];int maxLength = 0;for (int i = 0 ; i int:n = len(nums)visited = [False] * nmax_length = 0for i in range(n):if not visited[i]:max_length = max(max_length, self.dfs(nums, i, visited))return max_lengthdef dfs(self, nums : List[int], start : int, visited : List[bool]) -> int:if visited[start]:return 0visited[start] = Truenext_val = nums[start]cycle_length = 1 + self.dfs(nums, next_val, visited)return cycle_length# Exemple Usagenums = [5,4,0,3,1,6,2]solution = Solution()result = solution.arrayNesting(nums)print(f "Longueur du cycle le plus long : {result}")# Sortie : 4Ces implémentations sont optimisées pour détecter efficacement les cycles et calculer leurs longueurs, en utilisant un tableau visité pour éviter tout retraitement inutile.import java.util.Arrays;class Solution {public int arrayNesting(int[] nums) {int n = nums.length;boolean[] visited = new boolean[n];int maxLength = 0;for (int start = 0 ; start Alternative 2 : Calcul de la longueur de cycle en placeCette
class Solution:def arrayNesting(self, nums : List[int]) -> int:n = len(nums)max_length = 0for i in range(n):if nums[i] != -1:# Ne procéder que si cet index n'a pas été traitéstart = icount = 0while nums[start] != -1:next_index = nums[start]nums[start] = -1# Marquer comme visité en mettant à -1start = next_indexcount += 1max_length = max(max_length, count)return max_length# Exemple Usagenums = [5,4,0,3,1,6,2]solution = Solution()result = solution.arrayNesting(nums)print(f "Longueur du cycle le plus long : {result}") # Sortie :4Les principauxAlgorithme DFS :
Mise en œuvre étape par étape
Tableau visité
visited[i] est définie comme vraie lorsque nous avons exploré l'élément à l'index "i" au cours d'un cycle.visited[i] est déjà vrai, cela indique que cet élément fait partie d'un cycle que nous avons déjà mesuré.visited[i] comme vrai pour éviter d'entrer à nouveau dans le même cycle à partir d'un point de départ différentnext = nums[i], puis nous faisons un appel récursif à dfs(nums, next, visited) pour continuer à explorer le cycle.cycle_length = 1 + dfs(nums, next, visited).La fonction principale (arrayNesting(nums))
visited[i] est faux, lancer une traversée DFS à partir de cet index.longueur maximale actuelle et la mettre à jour si la nouvelle longueur est supérieure. max_length = Math.max(max_length, dfs(nums, i, visited)).maxLength est renvoyée.et inconvénients de l'approche
DFSAvantages
InconvénientsPotentiel
Caractéristiques principales et avantages de l'utilisation de DFS pour l'imbrication de
tableauxConcepts
clés du
code et leur utilitéL'
Meilleure compréhension grâce à un exemple de codePour
nums = [5,4,0,3,1,6,2], l'algorithme DFS s'exécute comme suit:nums[0], qui est 5.nums[5], qui vaut 6.nums[6], qui vaut 2.nums[2] est 0. Puisque 0 a déjà été visité, le cycle [0, 5, 6, 2] est complet, avec une longueur de 4.Use
Asked Questions
Pourquoi DFS est-il préféré à d'autres algorithmes de parcours de graphe comme BFS pour ce problème ?
Ce problème peut-il être résolu sans utiliser d'espace supplémentaire ?
Comment la plage de nombres dans le tableau (0 à n-1) influence-t-elle la solution ?
Questions connexes
Etant donné un tableau nums de n entiers où nums[i] est dans l'intervalle [0, n - 1], pouvez-vous écrire une fonction pour trouver et renvoyer le cycle le plus long dans le tableau ?
Fournissez les implémentations en Java et en Python










 Doubao s'apprête à lancer des fonctionnalités payantes, accélérant ainsi la monétisation des grands modèles de ByteDance
Le marché des grands modèles en Chine connaît actuellement une évolution notable, passant d'un accès gratuit à des abonnements payants. Selon des rapports récents, Douyin, le produit phare de ByteDanc
OpenAI s'associe à Gradient Labs pour créer un gestionnaire de relation client numérique basé sur l'IA destiné aux banques
Le 1er avril 2026, OpenAI a annoncé une collaboration étroite avec Gradient Labs, une start-up spécialisée dans l'IA financière. Ce partenariat s'appuie sur les derniers modèles de la série GPT-5.4 po
Doubao s'apprête à lancer des fonctionnalités payantes, accélérant ainsi la monétisation des grands modèles de ByteDance
Le marché des grands modèles en Chine connaît actuellement une évolution notable, passant d'un accès gratuit à des abonnements payants. Selon des rapports récents, Douyin, le produit phare de ByteDanc
OpenAI s'associe à Gradient Labs pour créer un gestionnaire de relation client numérique basé sur l'IA destiné aux banques
Le 1er avril 2026, OpenAI a annoncé une collaboration étroite avec Gradient Labs, une start-up spécialisée dans l'IA financière. Ce partenariat s'appuie sur les derniers modèles de la série GPT-5.4 po
 Les jetons IA constituent-ils une nouvelle prime à la signature ou simplement une charge d'exploitation ?
Cette semaine, un sujet qui circulait depuis un certain temps dans la Silicon Valley a enfin retenu l’attention du grand public : l’intégration de jetons d’IA dans la rémunération. Le concept est simp
Les jetons IA constituent-ils une nouvelle prime à la signature ou simplement une charge d'exploitation ?
Cette semaine, un sujet qui circulait depuis un certain temps dans la Silicon Valley a enfin retenu l’attention du grand public : l’intégration de jetons d’IA dans la rémunération. Le concept est simp

Découvrez les derniers outils d'IA hautement réputés de 2026 pour les tests unitaires automatisés. Notre sélection rigoureusement élaborée vous propose des solutions puissantes et révolutionnaires pour générer instantanément des cas de test Jest, PyTest et JUnit. Comparez les options gratuites et payantes à l'aide de tests réels et des classements mises à jour chaque semaine sur XIX.AI. Développez un avantage concurrentiel grâce à l'IA et améliorez rapidement votre productivité en développement.
10 outils
xix.ai

Découvrez les meilleurs outils de visualisation de données par IA de 2026 sur XIX.AI. Notre sélection rigoureuse et hautement notée vous aide à générer instantanément et automatiquement des tableaux de bord BI puissants et interactifs à partir de fichiers bruts. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Libérez dès aujourd'hui le potentiel de vos données.
10 outils
xix.ai

Découvrez les meilleurs kits de branding IA pour les réseaux sociaux en 2026. La sélection de XIX.AI regroupe des outils de premier plan qui changent la donne et vous permettent de garantir une cohérence visuelle parfaite de votre marque sur tous les canaux. Comparez les options gratuites et payantes grâce à des tests concrets. Donnez dès aujourd'hui un coup de pouce visuel à votre marque.
10 outils
xix.ai

Découvrez les meilleurs outils d'IA de 2026 pour des jeux de rôle immersifs et des interactions enrichissantes. Le guide sélectionné par XIX.AI présente des applications puissantes et révolutionnaires, avec des classements mis à jour chaque semaine, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le partenaire idéal et profitez dès aujourd'hui d'une compagnie numérique enrichissante.
10 outils
xix.ai

Découvrez les meilleurs assistants IA de 2026 pour créer des récits épiques de xianxia et de wuxia. La sélection de XIX.AI regroupe les outils les mieux notés et les plus innovants pour maîtriser la progression dans la voie de la cultivation et la chorégraphie des arts martiaux. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez à écrire dès aujourd'hui !
10 outils
xix.ai

Découvrez les 20 meilleurs outils de codage pour applications mobiles basées sur l'IA en 2026, conçus pour Flutter et React Native. Notre liste, soigneusement sélectionnée et hautement réputée, met en avant des solutions puissantes qui permettent de générer du code multiplateforme à partir de simples instructions. Comparez les options gratuites et payantes grâce à des tests pratiques. Accélérez votre développement et créez de meilleures applications. Consultez le classement sur XIX.AI dès maintenant !
10 outils
xix.ai

Als ich das Problem gestern selbst probiert habe, habe ich ewig gebraucht. Aber die Erklärung hier, wie man mit DFS die optimalen zyklischen Muster findet, ist super nachvollziehbar. Hoffentlich kann ich das bei der nächsten Interview-Frage anwenden. 🤞













