
















 首页
首页EleutherAI发布大规模许可文本数据集用于AI训练

EleutherAI,一个领先的AI研究组织,推出了一套最大的许可和开放领域文本集合,用于AI模型训练。
名为Common Pile v0.1的这个8TB数据集,经过两年时间与AI初创公司Poolside、Hugging Face以及多家学术机构合作开发。它被用来训练EleutherAI的两个新模型,Comma v0.1-1T和Comma v0.1-2T,该组织声称这些模型的性能可与使用未经许可的版权数据训练的模型相媲美。
包括OpenAI在内的AI公司,因使用网络抓取数据(包括版权书籍和期刊)进行模型训练而面临法律挑战。虽然一些公司与内容提供商达成许可协议,但许多公司依赖美国的合理使用原则,辩称无需许可即可使用版权材料进行训练。
EleutherAI认为,这些诉讼显著降低了AI行业的透明度,限制了对模型功能和弱点的洞察,损害了更广泛的研究社区。
“法律挑战并未显著改变模型训练的数据来源实践,但它们极大地降低了AI公司的开放性,”EleutherAI执行主任Stella Biderman在周五的Hugging Face博客文章中表示。“我们与一些公司研究人员交谈时,他们提到诉讼是他们无法分享数据中心研究的原因。”
Common Pile v0.1在Hugging Face的AI平台和GitHub上可用,经过法律咨询开发,包括国会图书馆和互联网档案馆数字化的30万本公共领域书籍等来源。EleutherAI还利用OpenAI的Whisper模型转录音频内容。
EleutherAI声称Comma v0.1-1T和Comma v0.1-2T展示了Common Pile v0.1的质量,使开发者能够创建与专有系统竞争的模型。这两个模型拥有70亿个参数,在数据集的一部分上训练,在编码、图像理解和数学基准测试中可与Meta的原始Llama模型媲美。
在TechCrunch全阶段通行证上节省超200美元
更智能地创新。更快地成长。更深入地建立网络。与来自Precursor Ventures、NEA、Index Ventures、Underscore VC等的远见者建立联系,享受一天的洞察、研讨会和宝贵联系。
在TechCrunch全阶段通行证上节省超200美元
更智能地创新。更快地成长。更深入地建立网络。与来自Precursor Ventures、NEA、Index Ventures、Underscore VC等的远见者建立联系,享受一天的洞察、研讨会和宝贵联系。
波士顿,马萨诸塞州 | 7月15日 立即注册参数,通常称为权重,是AI模型的内部元素,塑造其行为和响应。
“认为未经许可的文本对于高性能至关重要的观点是没有根据的,”Biderman在她的帖子中表示。“随着公开许可和公共领域数据的可访问性增加,我们预计基于此类内容训练的模型将显著改进。”
Common Pile v0.1部分解决了EleutherAI过去的争议。几年前,该组织发布了包含版权材料的开放数据集The Pile,因其在AI训练中的使用而引发批评和法律审查。
EleutherAI承诺将更定期发布开放数据集,与研究和基础设施合作伙伴合作。
太平洋时间上午9:48更新: Biderman在X上表示,EleutherAI为数据集和模型发布做出了贡献,来自多伦多大学等合作伙伴的参与尤为重要,共同领导了研究。
相关文章
 OpenAI 停用 o3 和 GPT-4.5 大型模型
作为人工智能领域的领军企业,OpenAI的每一步技术举措都会在业界引发巨大反响。近日,该公司发布了一项重大公告:将从其ChatGPT平台退役两个经典模型——o3和GPT-4.5。 常被称为“人文天才”的 GPT-4.5 将于 6 月 27 日下线,而以硬核推理能力著称的 o3 则将于 8 月 26 日跟进。经典模型的退役引发怀旧之情这一突如其来的消息让许多付费老用户难以接受,社交社区和讨论区很快充
AIGCPanel 2.0.0 重大更新:工作流引擎开启自动化数字人创作的新纪元
AIGCPanel 作为一款强大的本地数字人创作工具,刚刚发布了 2.0.0 版本——被誉为“迄今为止最重大的更新”。 此次核心升级通过工作流引擎和CLI命令行工具,将数字人合成、语音克隆及音视频处理功能有机整合,从而解决了当前AI创作工具分散的问题,实现了从手动组装到自动化生产的转变。1. 核心升级:定义逻辑流程,一键输出AIGCPanel 2.0.0 的突出新功能是工作流引擎:基于节点的组合:
BuzzFeed 推出专注于垃圾应用的 AI 子公司
在面临重大经营危机的背景下,曾经的数字媒体巨头BuzzFeed正启动一项由人工智能驱动的雄心勃勃的自救实验。 在最近举行的SXSW大会上,联合创始人兼首席执行官乔纳·佩雷蒂宣布成立一家名为Branch Office的子公司,旨在通过一系列由人工智能驱动的消费者应用程序,重新定义“软件即内容”的商业模式。核心产品组合:融合网络梗与社交媒体Branch Office 推出了三款核心应用,每款都旨在捕捉
相关专题推荐
图像编辑
OpenAI 停用 o3 和 GPT-4.5 大型模型
作为人工智能领域的领军企业,OpenAI的每一步技术举措都会在业界引发巨大反响。近日,该公司发布了一项重大公告:将从其ChatGPT平台退役两个经典模型——o3和GPT-4.5。 常被称为“人文天才”的 GPT-4.5 将于 6 月 27 日下线,而以硬核推理能力著称的 o3 则将于 8 月 26 日跟进。经典模型的退役引发怀旧之情这一突如其来的消息让许多付费老用户难以接受,社交社区和讨论区很快充
AIGCPanel 2.0.0 重大更新:工作流引擎开启自动化数字人创作的新纪元
AIGCPanel 作为一款强大的本地数字人创作工具,刚刚发布了 2.0.0 版本——被誉为“迄今为止最重大的更新”。 此次核心升级通过工作流引擎和CLI命令行工具,将数字人合成、语音克隆及音视频处理功能有机整合,从而解决了当前AI创作工具分散的问题,实现了从手动组装到自动化生产的转变。1. 核心升级:定义逻辑流程,一键输出AIGCPanel 2.0.0 的突出新功能是工作流引擎:基于节点的组合:
BuzzFeed 推出专注于垃圾应用的 AI 子公司
在面临重大经营危机的背景下,曾经的数字媒体巨头BuzzFeed正启动一项由人工智能驱动的雄心勃勃的自救实验。 在最近举行的SXSW大会上,联合创始人兼首席执行官乔纳·佩雷蒂宣布成立一家名为Branch Office的子公司,旨在通过一系列由人工智能驱动的消费者应用程序,重新定义“软件即内容”的商业模式。核心产品组合:融合网络梗与社交媒体Branch Office 推出了三款核心应用,每款都旨在捕捉
相关专题推荐
图像编辑
 用于短剧故事板的AI艺术生成工具:幻想与都市浪漫题材的角色设计
用于短剧故事板的AI艺术生成工具:幻想与都市浪漫题材的角色设计
2026最新推荐:探索最适合用于短剧故事板制作的AI艺术生成工具。我们精心挑选了众多顶级工具,帮助您创作出引人入胜的幻想角色和都市浪漫角色。您可以对比免费与付费选项,查看实际测试结果,从而找到最适合自己的创意工具。XIX.AI还会每周更新排名并提供专家分析,让您立即开始将故事可视化呈现吧!
 10 个工具
10 个工具
 xix.ai
写作
最适合广播和播客使用的AI脚本编写工具:帮助您创作引人入胜的音频广告
xix.ai
写作
最适合广播和播客使用的AI脚本编写工具:帮助您创作引人入胜的音频广告
在XIX.AI上,发现2026年最适合用于广播和播客制作的AI脚本工具。我们精心挑选的这些高评分工具能够提供强大的功能,帮助您快速制作出引人入胜的音频广告。通过实际测试和每周更新的排名,您可以了解免费选项与付费选项之间的差异。今天就释放您的创造力吧!
10 个工具
xix.ai
商业
最佳 AI 合同审查软件:即时发现法律漏洞与合规风险
在 XIX.AI 上探索 2026 年最佳 AI 合同审查软件。我们精心筛选的顶级榜单汇集了功能强大的工具,能够即时发现法律漏洞和合规风险。通过实际测试和每周更新的排名,对比免费与付费选项。找到能彻底改变游戏规则的解决方案,实现安全、高效的合同分析。立即探索这本权威指南。
10 个工具
xix.ai
动画创作
专为东华设计的AI动漫生成器:可用于创建网络小说角色及漫画头像
探索2026年最适合制作中文动画的人工智能工具。我们精心挑选的顶级列表中包含了各种强大的工具,能够帮助你创建出令人惊叹的网络小说角色和漫画头像。通过实际测试来对比免费选项和付费选项,找到最适合你的创作工具,今天就在XIX.AI上将你的故事变为现实吧。
10 个工具
xix.ai
漫画创作
漫画领域顶尖的AI自动上色工具:零一致性错误地应用平涂色彩
立即访问 XIX.AI,探索 2026 年最优秀的漫画 AI 自动上色工具。我们精心筛选的清单汇集了广受好评、颠覆行业的解决方案,这些工具能以零一致性错误的方式应用平涂色彩,从而大幅提升您的工作效率。通过免费版与付费版的对比分析、实际测试以及每周更新的排行榜,找到最适合您的工具。立即开启您的 AI 优势。
10 个工具
xix.ai
写作
顶尖 AI 角色设定生成器:生成一致的角色动机与致命缺陷
探索2026年最优秀的AI人物设定生成工具,助您塑造鲜活立体的角色。XIX.AI精心筛选的这份清单汇集了广受好评、颠覆传统的工具,能够生成具有内在逻辑的动机和致命缺陷。通过实际测试对比免费与付费选项。立即释放您的叙事潜能。
10 个工具
xix.ai

 评论 (2)
0/500
评论 (2)
0/500
![NicholasLewis]()
Наконец-то качественные данные для обучения ИИ! 😄 Но интересно, как это повлияет на конкуренцию между OpenAI и другими компаниями. Может, скоро увидим более умные модели?
![RyanLopez]()
Wow, 8 terabytes of legally licensed text is a game-changer! It's fantastic to see more high-quality, transparent data becoming available. This should really help push open-source AI models forward and maybe even challenge some of the big players who rely on murkier data sources. Hopefully, it leads to more reliable and ethically-sound systems. Can't wait to see what gets built on this! 🚀
EleutherAI,一个领先的AI研究组织,推出了一套最大的许可和开放领域文本集合,用于AI模型训练。
名为Common Pile v0.1的这个8TB数据集,经过两年时间与AI初创公司Poolside、Hugging Face以及多家学术机构合作开发。它被用来训练EleutherAI的两个新模型,Comma v0.1-1T和Comma v0.1-2T,该组织声称这些模型的性能可与使用未经许可的版权数据训练的模型相媲美。
包括OpenAI在内的AI公司,因使用网络抓取数据(包括版权书籍和期刊)进行模型训练而面临法律挑战。虽然一些公司与内容提供商达成许可协议,但许多公司依赖美国的合理使用原则,辩称无需许可即可使用版权材料进行训练。
EleutherAI认为,这些诉讼显著降低了AI行业的透明度,限制了对模型功能和弱点的洞察,损害了更广泛的研究社区。
“法律挑战并未显著改变模型训练的数据来源实践,但它们极大地降低了AI公司的开放性,”EleutherAI执行主任Stella Biderman在周五的Hugging Face博客文章中表示。“我们与一些公司研究人员交谈时,他们提到诉讼是他们无法分享数据中心研究的原因。”
Common Pile v0.1在Hugging Face的AI平台和GitHub上可用,经过法律咨询开发,包括国会图书馆和互联网档案馆数字化的30万本公共领域书籍等来源。EleutherAI还利用OpenAI的Whisper模型转录音频内容。
EleutherAI声称Comma v0.1-1T和Comma v0.1-2T展示了Common Pile v0.1的质量,使开发者能够创建与专有系统竞争的模型。这两个模型拥有70亿个参数,在数据集的一部分上训练,在编码、图像理解和数学基准测试中可与Meta的原始Llama模型媲美。
在TechCrunch全阶段通行证上节省超200美元
更智能地创新。更快地成长。更深入地建立网络。与来自Precursor Ventures、NEA、Index Ventures、Underscore VC等的远见者建立联系,享受一天的洞察、研讨会和宝贵联系。
在TechCrunch全阶段通行证上节省超200美元
更智能地创新。更快地成长。更深入地建立网络。与来自Precursor Ventures、NEA、Index Ventures、Underscore VC等的远见者建立联系,享受一天的洞察、研讨会和宝贵联系。
波士顿,马萨诸塞州 | 7月15日 立即注册参数,通常称为权重,是AI模型的内部元素,塑造其行为和响应。
“认为未经许可的文本对于高性能至关重要的观点是没有根据的,”Biderman在她的帖子中表示。“随着公开许可和公共领域数据的可访问性增加,我们预计基于此类内容训练的模型将显著改进。”
Common Pile v0.1部分解决了EleutherAI过去的争议。几年前,该组织发布了包含版权材料的开放数据集The Pile,因其在AI训练中的使用而引发批评和法律审查。
EleutherAI承诺将更定期发布开放数据集,与研究和基础设施合作伙伴合作。
太平洋时间上午9:48更新: Biderman在X上表示,EleutherAI为数据集和模型发布做出了贡献,来自多伦多大学等合作伙伴的参与尤为重要,共同领导了研究。










 OpenAI 停用 o3 和 GPT-4.5 大型模型
作为人工智能领域的领军企业,OpenAI的每一步技术举措都会在业界引发巨大反响。近日,该公司发布了一项重大公告:将从其ChatGPT平台退役两个经典模型——o3和GPT-4.5。 常被称为“人文天才”的 GPT-4.5 将于 6 月 27 日下线,而以硬核推理能力著称的 o3 则将于 8 月 26 日跟进。经典模型的退役引发怀旧之情这一突如其来的消息让许多付费老用户难以接受,社交社区和讨论区很快充
OpenAI 停用 o3 和 GPT-4.5 大型模型
作为人工智能领域的领军企业,OpenAI的每一步技术举措都会在业界引发巨大反响。近日,该公司发布了一项重大公告:将从其ChatGPT平台退役两个经典模型——o3和GPT-4.5。 常被称为“人文天才”的 GPT-4.5 将于 6 月 27 日下线,而以硬核推理能力著称的 o3 则将于 8 月 26 日跟进。经典模型的退役引发怀旧之情这一突如其来的消息让许多付费老用户难以接受,社交社区和讨论区很快充
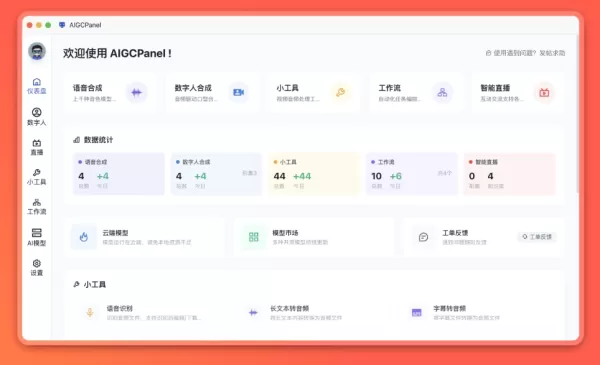 AIGCPanel 2.0.0 重大更新:工作流引擎开启自动化数字人创作的新纪元
AIGCPanel 作为一款强大的本地数字人创作工具,刚刚发布了 2.0.0 版本——被誉为“迄今为止最重大的更新”。 此次核心升级通过工作流引擎和CLI命令行工具,将数字人合成、语音克隆及音视频处理功能有机整合,从而解决了当前AI创作工具分散的问题,实现了从手动组装到自动化生产的转变。1. 核心升级:定义逻辑流程,一键输出AIGCPanel 2.0.0 的突出新功能是工作流引擎:基于节点的组合:
AIGCPanel 2.0.0 重大更新:工作流引擎开启自动化数字人创作的新纪元
AIGCPanel 作为一款强大的本地数字人创作工具,刚刚发布了 2.0.0 版本——被誉为“迄今为止最重大的更新”。 此次核心升级通过工作流引擎和CLI命令行工具,将数字人合成、语音克隆及音视频处理功能有机整合,从而解决了当前AI创作工具分散的问题,实现了从手动组装到自动化生产的转变。1. 核心升级:定义逻辑流程,一键输出AIGCPanel 2.0.0 的突出新功能是工作流引擎:基于节点的组合:
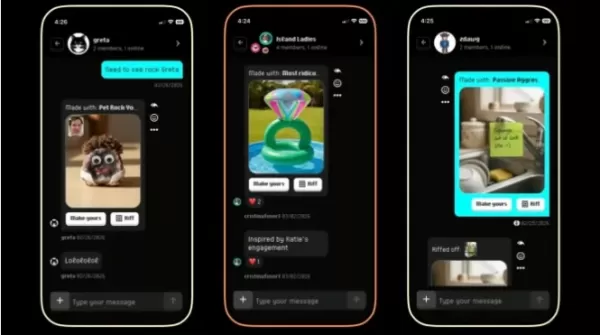 BuzzFeed 推出专注于垃圾应用的 AI 子公司
在面临重大经营危机的背景下,曾经的数字媒体巨头BuzzFeed正启动一项由人工智能驱动的雄心勃勃的自救实验。 在最近举行的SXSW大会上,联合创始人兼首席执行官乔纳·佩雷蒂宣布成立一家名为Branch Office的子公司,旨在通过一系列由人工智能驱动的消费者应用程序,重新定义“软件即内容”的商业模式。核心产品组合:融合网络梗与社交媒体Branch Office 推出了三款核心应用,每款都旨在捕捉
BuzzFeed 推出专注于垃圾应用的 AI 子公司
在面临重大经营危机的背景下,曾经的数字媒体巨头BuzzFeed正启动一项由人工智能驱动的雄心勃勃的自救实验。 在最近举行的SXSW大会上,联合创始人兼首席执行官乔纳·佩雷蒂宣布成立一家名为Branch Office的子公司,旨在通过一系列由人工智能驱动的消费者应用程序,重新定义“软件即内容”的商业模式。核心产品组合:融合网络梗与社交媒体Branch Office 推出了三款核心应用,每款都旨在捕捉

2026最新推荐:探索最适合用于短剧故事板制作的AI艺术生成工具。我们精心挑选了众多顶级工具,帮助您创作出引人入胜的幻想角色和都市浪漫角色。您可以对比免费与付费选项,查看实际测试结果,从而找到最适合自己的创意工具。XIX.AI还会每周更新排名并提供专家分析,让您立即开始将故事可视化呈现吧!
10 个工具
xix.ai

在XIX.AI上,发现2026年最适合用于广播和播客制作的AI脚本工具。我们精心挑选的这些高评分工具能够提供强大的功能,帮助您快速制作出引人入胜的音频广告。通过实际测试和每周更新的排名,您可以了解免费选项与付费选项之间的差异。今天就释放您的创造力吧!
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最佳 AI 合同审查软件。我们精心筛选的顶级榜单汇集了功能强大的工具,能够即时发现法律漏洞和合规风险。通过实际测试和每周更新的排名,对比免费与付费选项。找到能彻底改变游戏规则的解决方案,实现安全、高效的合同分析。立即探索这本权威指南。
10 个工具
xix.ai

探索2026年最适合制作中文动画的人工智能工具。我们精心挑选的顶级列表中包含了各种强大的工具,能够帮助你创建出令人惊叹的网络小说角色和漫画头像。通过实际测试来对比免费选项和付费选项,找到最适合你的创作工具,今天就在XIX.AI上将你的故事变为现实吧。
10 个工具
xix.ai

立即访问 XIX.AI,探索 2026 年最优秀的漫画 AI 自动上色工具。我们精心筛选的清单汇集了广受好评、颠覆行业的解决方案,这些工具能以零一致性错误的方式应用平涂色彩,从而大幅提升您的工作效率。通过免费版与付费版的对比分析、实际测试以及每周更新的排行榜,找到最适合您的工具。立即开启您的 AI 优势。
10 个工具
xix.ai

探索2026年最优秀的AI人物设定生成工具,助您塑造鲜活立体的角色。XIX.AI精心筛选的这份清单汇集了广受好评、颠覆传统的工具,能够生成具有内在逻辑的动机和致命缺陷。通过实际测试对比免费与付费选项。立即释放您的叙事潜能。
10 个工具
xix.ai

Наконец-то качественные данные для обучения ИИ! 😄 Но интересно, как это повлияет на конкуренцию между OpenAI и другими компаниями. Может, скоро увидим более умные модели?
Wow, 8 terabytes of legally licensed text is a game-changer! It's fantastic to see more high-quality, transparent data becoming available. This should really help push open-source AI models forward and maybe even challenge some of the big players who rely on murkier data sources. Hopefully, it leads to more reliable and ethically-sound systems. Can't wait to see what gets built on this! 🚀













