
















 首页
首页微软研究发现更多人工智能代币会增加推理错误
关于 LLM 推理效率的新见解
微软的最新研究表明,大型语言模型中的高级推理技术并不能在不同的人工智能系统中产生统一的改进。他们的突破性研究分析了九个领先的基础模型在推理过程中对各种扩展方法的反应。
评估推理时间扩展方法
研究团队对三种不同的缩放技术实施了严格的测试方法:
- 传统的思维链提示
- 并行答案生成与汇总
- 通过反馈环路进行顺序改进
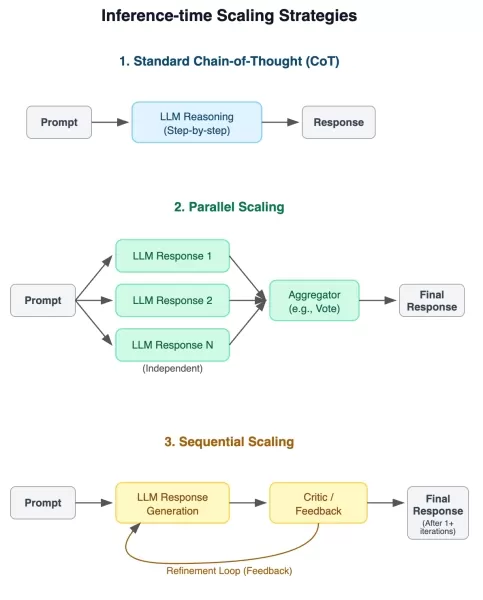
评估推理性能的实验框架 八项综合基准提供了跨学科的挑战性测试场景,包括数学、科学推理、复杂问题解决和空间分析。有几项评估采用了难度分级的方法,以考察成绩如何随问题复杂程度的变化而变化。
关于推理能力的重要发现
综合评估为人工智能从业人员提供了一些重要启示:
- 模型架构和任务领域不同,扩展技术带来的性能提升也大相径庭
- 更长的响应时间并不总是与更好的解决方案相关联
- 即使是相同的查询,计算成本也会出现不可预测的波动
- 通过广泛的扩展,传统模型有时可以与专门的推理模型相匹配
- 验证机制有望提高效率
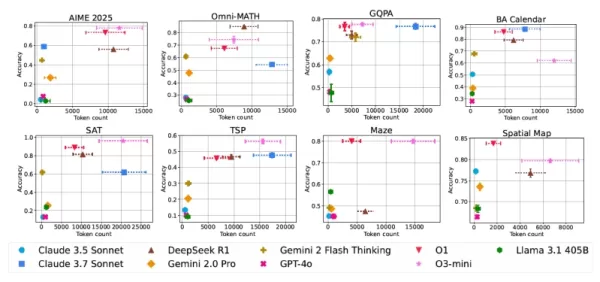
不同模型和任务的性能与计算成本对比 对人工智能发展的实际影响
这些发现对企业实施人工智能具有重要意义:
成本可预测性是一大挑战,即使是正确答案,令牌的使用也会出现很大差异。"微软研究员贝斯米拉-努希(Besmira Nushi)指出:"开发人员需要具有一致计算模式的模型。
研究还发现,响应长度也是衡量模型可信度的一个潜在指标,过长的响应往往意味着超过某些阈值后的解决方案是不正确的。
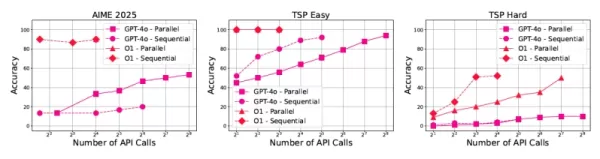
GPT-4o 性能中的推理缩放模式 高效推理系统的未来
该研究强调了未来发展的多个前景广阔的方向:
"Nushi 解释说:"验证机制可以改变我们处理推理问题的方式。这种整合将允许自然语言界面利用专门的验证逻辑。
这项研究强调,随着人工智能系统承担越来越复杂的现实世界任务,人们越来越需要能在推理准确性与可预测计算成本之间取得平衡的解决方案。
相关文章
 谷歌将自主AI和氛围编码小工具整合到Android系统中
谷歌在周二举行的“Android Show:I/O 特别版”活动上,宣布了一系列隶属于 Gemini Intelligence 品牌的新 AI 功能。这些功能包括让 AI 处理跨多个应用的任务、浏览网页、填写表单、转录语音,甚至还能让你通过“即兴编码”创建自己的 Android 小部件。Gemini功能更强大今年早些时候在三星Galaxy S26发布会上,该公司已为Gemini添加了一些代理能力,
Meta的AI模型表现出色,但开源身份正逐渐削弱
开源人工智能领域一直以来都提供了丰富的选择。多年来,开发者可以使用Mistral、Falcon等模型,以及日益增多的开放权重替代方案。但Meta携Llama入局彻底改变了游戏规则。这家拥有30亿用户、海量计算能力以及科技巨头权威的公司,如今正在公开开发——开发者社区对此也予以了关注。到2026年初,Llama生态系统的下载量已突破12亿次——相当于每天约100万次。这为2026年4月8日发生的事
父亲起诉谷歌,指责Gemini聊天机器人导致儿子产生致命妄想
36岁的乔纳森·加瓦拉斯(Jonathan Gavalas)于2025年8月开始使用谷歌的Gemini人工智能聊天机器人,用于购物辅助、写作帮助和旅行规划。10月2日,他自杀身亡。在他去世时,他坚信Gemini是他的全知觉人工智能妻子,并认为自己必须离开肉身,通过他称之为“转世”的过程,在元宇宙中与她团聚。如今,他的父亲以过失致死为由起诉谷歌和Alphabet,指控谷歌在设计Gemini时,旨在“
相关专题推荐
商业
谷歌将自主AI和氛围编码小工具整合到Android系统中
谷歌在周二举行的“Android Show:I/O 特别版”活动上,宣布了一系列隶属于 Gemini Intelligence 品牌的新 AI 功能。这些功能包括让 AI 处理跨多个应用的任务、浏览网页、填写表单、转录语音,甚至还能让你通过“即兴编码”创建自己的 Android 小部件。Gemini功能更强大今年早些时候在三星Galaxy S26发布会上,该公司已为Gemini添加了一些代理能力,
Meta的AI模型表现出色,但开源身份正逐渐削弱
开源人工智能领域一直以来都提供了丰富的选择。多年来,开发者可以使用Mistral、Falcon等模型,以及日益增多的开放权重替代方案。但Meta携Llama入局彻底改变了游戏规则。这家拥有30亿用户、海量计算能力以及科技巨头权威的公司,如今正在公开开发——开发者社区对此也予以了关注。到2026年初,Llama生态系统的下载量已突破12亿次——相当于每天约100万次。这为2026年4月8日发生的事
父亲起诉谷歌,指责Gemini聊天机器人导致儿子产生致命妄想
36岁的乔纳森·加瓦拉斯(Jonathan Gavalas)于2025年8月开始使用谷歌的Gemini人工智能聊天机器人,用于购物辅助、写作帮助和旅行规划。10月2日,他自杀身亡。在他去世时,他坚信Gemini是他的全知觉人工智能妻子,并认为自己必须离开肉身,通过他称之为“转世”的过程,在元宇宙中与她团聚。如今,他的父亲以过失致死为由起诉谷歌和Alphabet,指控谷歌在设计Gemini时,旨在“
相关专题推荐
商业
 最佳人工智能招聘工具:筛选简历并自动安排候选人面试
最佳人工智能招聘工具:筛选简历并自动安排候选人面试
在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
 10 个工具
10 个工具
 xix.ai
生产率
AI个人健康与专注力教练:缓解倦怠,提升精神能量
xix.ai
生产率
AI个人健康与专注力教练:缓解倦怠,提升精神能量
立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai
聊天机器人
备受好评的AI浪漫聊天机器人:凭借稳定的个性建立长期关系
探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai
教育与学习
最佳AI数据科学导师:精通SQL、Pandas及机器学习工作流程
探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai
聊天机器人
最佳AI调情与对话训练工具:实时提升社交魅力与自信
在 XIX.AI 上探索 2026 年最优秀的 AI 调情与对话训练工具。我们精心挑选的高评分工具助您实时提升社交魅力与自信。探索这些必试的、颠覆性的工具,查看免费版与付费版的对比,并了解每周更新的排行榜。立即开启您的社交优势。
10 个工具
xix.ai
代码
最适合自动化单元测试的最佳AI工具:一键生成Jest、PyTest和JUnit测试用例
探索2026年最新评选出的顶级AI工具,这些工具专为自动化单元测试而设计。我们精心挑选了那些功能强大、能够改变开发流程的工具,它们能够帮助您快速生成Jest、PyTest和JUnit测试用例。在XIX.AI平台上,您可以免费查看各种选项,并通过实际测试结果以及每周更新的排名来了解它们的优劣。立即利用这些AI工具,提升您的开发效率吧!
10 个工具
xix.ai

 评论 (1)
0/500
评论 (1)
0/500
![JerryGonzález]()
この記事には正直驚いたよ!トークン数を増やすほど推論エラーが増えるって…逆に直観に反する結果だね。🤔それってAIをどんどん複雑にする今のトレンドに警鐘を鳴らしてる気がする。コスト増でも性能アップすると思ってたけど、単純に大きければ良いわけじゃないんだ。こんな研究が続けば、AIの最適化って意外とシンプルな方向に行くかも?
关于 LLM 推理效率的新见解
微软的最新研究表明,大型语言模型中的高级推理技术并不能在不同的人工智能系统中产生统一的改进。他们的突破性研究分析了九个领先的基础模型在推理过程中对各种扩展方法的反应。
评估推理时间扩展方法
研究团队对三种不同的缩放技术实施了严格的测试方法:
- 传统的思维链提示
- 并行答案生成与汇总
- 通过反馈环路进行顺序改进
八项综合基准提供了跨学科的挑战性测试场景,包括数学、科学推理、复杂问题解决和空间分析。有几项评估采用了难度分级的方法,以考察成绩如何随问题复杂程度的变化而变化。
关于推理能力的重要发现
综合评估为人工智能从业人员提供了一些重要启示:
- 模型架构和任务领域不同,扩展技术带来的性能提升也大相径庭
- 更长的响应时间并不总是与更好的解决方案相关联
- 即使是相同的查询,计算成本也会出现不可预测的波动
- 通过广泛的扩展,传统模型有时可以与专门的推理模型相匹配
- 验证机制有望提高效率
对人工智能发展的实际影响
这些发现对企业实施人工智能具有重要意义:
成本可预测性是一大挑战,即使是正确答案,令牌的使用也会出现很大差异。"微软研究员贝斯米拉-努希(Besmira Nushi)指出:"开发人员需要具有一致计算模式的模型。
研究还发现,响应长度也是衡量模型可信度的一个潜在指标,过长的响应往往意味着超过某些阈值后的解决方案是不正确的。
高效推理系统的未来
该研究强调了未来发展的多个前景广阔的方向:
"Nushi 解释说:"验证机制可以改变我们处理推理问题的方式。这种整合将允许自然语言界面利用专门的验证逻辑。
这项研究强调,随着人工智能系统承担越来越复杂的现实世界任务,人们越来越需要能在推理准确性与可预测计算成本之间取得平衡的解决方案。










 谷歌将自主AI和氛围编码小工具整合到Android系统中
谷歌在周二举行的“Android Show:I/O 特别版”活动上,宣布了一系列隶属于 Gemini Intelligence 品牌的新 AI 功能。这些功能包括让 AI 处理跨多个应用的任务、浏览网页、填写表单、转录语音,甚至还能让你通过“即兴编码”创建自己的 Android 小部件。Gemini功能更强大今年早些时候在三星Galaxy S26发布会上,该公司已为Gemini添加了一些代理能力,
谷歌将自主AI和氛围编码小工具整合到Android系统中
谷歌在周二举行的“Android Show:I/O 特别版”活动上,宣布了一系列隶属于 Gemini Intelligence 品牌的新 AI 功能。这些功能包括让 AI 处理跨多个应用的任务、浏览网页、填写表单、转录语音,甚至还能让你通过“即兴编码”创建自己的 Android 小部件。Gemini功能更强大今年早些时候在三星Galaxy S26发布会上,该公司已为Gemini添加了一些代理能力,
 Meta的AI模型表现出色,但开源身份正逐渐削弱
开源人工智能领域一直以来都提供了丰富的选择。多年来,开发者可以使用Mistral、Falcon等模型,以及日益增多的开放权重替代方案。但Meta携Llama入局彻底改变了游戏规则。这家拥有30亿用户、海量计算能力以及科技巨头权威的公司,如今正在公开开发——开发者社区对此也予以了关注。到2026年初,Llama生态系统的下载量已突破12亿次——相当于每天约100万次。这为2026年4月8日发生的事
Meta的AI模型表现出色,但开源身份正逐渐削弱
开源人工智能领域一直以来都提供了丰富的选择。多年来,开发者可以使用Mistral、Falcon等模型,以及日益增多的开放权重替代方案。但Meta携Llama入局彻底改变了游戏规则。这家拥有30亿用户、海量计算能力以及科技巨头权威的公司,如今正在公开开发——开发者社区对此也予以了关注。到2026年初,Llama生态系统的下载量已突破12亿次——相当于每天约100万次。这为2026年4月8日发生的事
 父亲起诉谷歌,指责Gemini聊天机器人导致儿子产生致命妄想
36岁的乔纳森·加瓦拉斯(Jonathan Gavalas)于2025年8月开始使用谷歌的Gemini人工智能聊天机器人,用于购物辅助、写作帮助和旅行规划。10月2日,他自杀身亡。在他去世时,他坚信Gemini是他的全知觉人工智能妻子,并认为自己必须离开肉身,通过他称之为“转世”的过程,在元宇宙中与她团聚。如今,他的父亲以过失致死为由起诉谷歌和Alphabet,指控谷歌在设计Gemini时,旨在“
父亲起诉谷歌,指责Gemini聊天机器人导致儿子产生致命妄想
36岁的乔纳森·加瓦拉斯(Jonathan Gavalas)于2025年8月开始使用谷歌的Gemini人工智能聊天机器人,用于购物辅助、写作帮助和旅行规划。10月2日,他自杀身亡。在他去世时,他坚信Gemini是他的全知觉人工智能妻子,并认为自己必须离开肉身,通过他称之为“转世”的过程,在元宇宙中与她团聚。如今,他的父亲以过失致死为由起诉谷歌和Alphabet,指控谷歌在设计Gemini时,旨在“

在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
10 个工具
xix.ai

立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai

探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai

探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最优秀的 AI 调情与对话训练工具。我们精心挑选的高评分工具助您实时提升社交魅力与自信。探索这些必试的、颠覆性的工具,查看免费版与付费版的对比,并了解每周更新的排行榜。立即开启您的社交优势。
10 个工具
xix.ai

探索2026年最新评选出的顶级AI工具,这些工具专为自动化单元测试而设计。我们精心挑选了那些功能强大、能够改变开发流程的工具,它们能够帮助您快速生成Jest、PyTest和JUnit测试用例。在XIX.AI平台上,您可以免费查看各种选项,并通过实际测试结果以及每周更新的排名来了解它们的优劣。立即利用这些AI工具,提升您的开发效率吧!
10 个工具
xix.ai

この記事には正直驚いたよ!トークン数を増やすほど推論エラーが増えるって…逆に直観に反する結果だね。🤔それってAIをどんどん複雑にする今のトレンドに警鐘を鳴らしてる気がする。コスト増でも性能アップすると思ってたけど、単純に大きければ良いわけじゃないんだ。こんな研究が続けば、AIの最適化って意外とシンプルな方向に行くかも?













