
















 家
家Vanna AI、自然言語処理によるノーコード・データベース・クエリーを可能に
自然言語データベース・インターフェースの出現は、データの民主化における変革的なシフトを示し、Vanna AIはこの進化の先駆者である。このオープンソースのPythonライブラリは、会話の英語を正確なSQLクエリに変換することで、ビジネスユーザーと複雑なデータシステム間のギャップを埋めます。革新的なRAG(Retrieval-Augmented Generation)アーキテクチャにより、Vannaはクエリの精度を維持しながら、専門的な技術知識がなくても洞察力を引き出すことができます。
主な利点
Vanna AIは、データ探索を簡素化する直感的な英語-SQLインターフェイスを提供します。
RAGアーキテクチャは、セマンティック理解を通じて文脈に沿った正確なクエリ生成を保証します。
完全なオープンソース実装により、企業のニーズに合わせたカスタマイズが可能
PostgreSQL、MySQL、SQLiteを含む幅広いSQLデータベースとの互換性
PythonデータワークフローやJupyter環境とのシームレスな統合
活発なオープンソース開発により、コミュニティでの採用が増加
組織横断的なデータアクセスの技術的障壁を低減
コアテクノロジーの概要
アーキテクチャ基盤
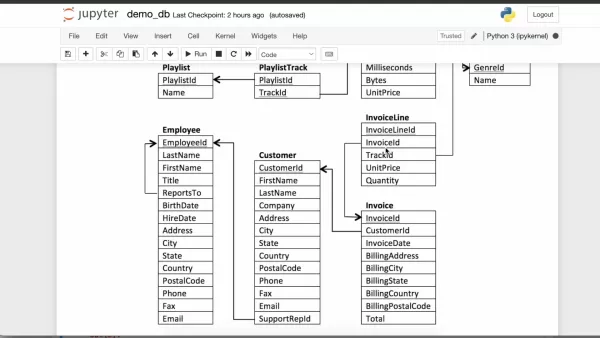
Vanna AIは、洗練された2段階のアプローチにより、最先端の自然言語処理とデータベースインテリジェンスを組み合わせます。システムはまず、ベクトル埋め込みによってスキーマ構造と既存のクエリを分析することで、データ環境を学習します。ユーザーがビジネス上の質問を投げかけると、プラットフォームはこの知識ベースに対してセマンティック検索を実行し、その後に特定のデータ環境に合わせて最適化されたSQLステートメントを生成します。
この二段階の方法論により、クエリはユーザーの意図に答えながら、データベースの関係とビジネスルールを尊重するようになります。オープンなアーキテクチャは、既存のPythonデータスタックとの統合を可能にし、特にJupyter notebookとの互換性による分析ワークフローに強みを発揮します。
主要技術コンポーネント
Vanna AIは、自然言語インターフェースを実現するためにいくつかの革新的な技術を実装しています:
- モデルの埋め込み:データベースのメタデータと自然言語を比較可能なベクトル表現に変換。
- ベクトル・データベース:クエリ生成のためのコンテクスト情報の保存と検索
- 言語モデル:検索されたコンテキストに基づいて質問を実行可能なSQLに変換します。
- クエリの検証:生成されたSQLがデータベースの構文ルールに適合していることを確認します。
- フィードバックループ:クエリ強化の成功による継続的な改善
実装ガイド
インストール手順
Pythonパッケージをインストールするには、pipコマンドを使用します:
pip install vanna
これは、必要な機械学習ライブラリやデータベースコネクタを含むすべての依存関係を処理します。企業での導入の場合、本番環境のスケーリングのためにコンテナによるインストールを検討することができます。
システム構成
既存のデータベースへの接続には、標準的な SQLAlchemy の接続文字列を使います:
import pandas as pd from sqlalchemy import create_engine from vanna.remote import VannaDefaultvn = VannaDefault(model='chinook', api_key='YOUR_API_KEY') vn.connect_to_sqlite('https://vanna.ai/Chinook.sqlite')
知識ベースの開発
Vanna AIのトレーニングには、以下のものが含まれます:
- 完全なデータベーススキーマの説明
- 一般的な使用例を表すサンプルクエリ
- ビジネス用語の定義
- データ関係文書
この構造化されたオンボーディングは、通常、エンドユーザがアクセスする前にデータベース管理者が1回だけ行う必要があります。
経済的考察
コスト構造分析
オープンソースソフトウェアとして、Vanna AIは完全な透明性を提供しながら、ライセンスコストを排除します。組織は以下の予算を組む必要がある:
- 複雑な展開のための実装サービス
- エンベッディング生成のためのコンピューティングリソース
- ベクトルデータベースインフラストラクチャ
- オプションのプレミアム・サポート・パッケージ
総所有コストは、多くの場合、より大きなコントロールを提供しながら、市販の代替製品よりも大幅に低いことがわかります。
ソリューション評価
主な利点
- 技術スキルレベルを超えたデータアクセスの民主化
- 専門的なSQLリソースへの依存を軽減
- 分析ワークフローの速度を加速
- セルフサービスによるレポート作成が可能
- 探索的データ分析を促進
実装の課題
- スキーマの初期理解期間が必要
- 複雑な分析質問には改良が必要な場合がある
- データベースの複雑さによってパフォーマンスが異なる
- 現在開発中の新機能
産業用アプリケーション
ビジネス・インテリジェンス
営業チームは、IT部門が関与することなく、顧客指標を即座に照会できます。また、経営幹部は、自然な質問を通じて、パフォーマンス・ダッシュボードにリアルタイムでアクセスできます:
「西部地域の製品ライン別の四半期収益傾向を教えてください。
データサイエンス
アナリストは、モデル開発の前にデータセットを会話形式で探索することで、フィーチャーエンジニアリングを加速します:
「1000ドルを超える取引額の分布は?
運用レポート
管理者は、保存された自然言語クエリによってレポート生成を自動化し、最新のデータでリフレッシュします。
よくある質問
データベース互換性
Vanna AIは、JDBC/ODBC接続を備えたクラウドデータウェアハウスを含む、すべての主要なSQL実装をサポートしています。パフォーマンスはデータベース固有の構文のニュアンスによって異なります。
精度のベンチマーク
テストによると、一般的なビジネスクエリの初期精度は85~95%で、組織固有の質問によるフィードバックトレーニング後は95%以上に向上します。
セキュリティ
クエリは既存のデータベース権限を尊重します。機密データの保護には、適切なスキーマ設計とアクセス制御の実装が必要です。
比較分析
代替ソリューション
Tableau Ask Dataのようなプロプライエタリなツールとは異なり、Vanna AIは完全なクエリの透明性とカスタマイズを提供します。オープンなアプローチにより、業界特有の用語や、基本的な可視化のニーズを超えた複雑な分析シナリオのチューニングが可能です。
関連記事
 OpenAI、アルトマン氏の解任を困難にするため、密かに定款を変更
2023年のクーデターのような事態を受けて、OpenAIは定款を改定し、サム・アルトマンCEOに対する保護措置をさらに強化した。最近公開された裁判文書によると、アルトマン氏の地位は今や揺るぎないものとなっており、外部からの干渉や、取締役会による解任の動きに対する障壁が大幅に高まっている。イーロン・マスクがOpenAIを相手取った訴訟における専門家証人は、これらの変更が同社が営利モデルへ移行する過程
Meta AIがFacebookマーケットプレイスでの購入者からのメッセージに対応するようになりました
Facebookは木曜日、Facebook Marketplaceに、購入者からの問い合わせへの自動返信を含む新たなMeta AI機能を導入すると発表した。同プラットフォームでは、AIを活用して出品手続きの迅速化や出品者プロフィールの要約を行うほか、出品者が商品ページで配送オプションを提供できるようになった。出品者は購入者からの問い合わせを頻繁に受けるため、FacebookはMeta AIを活用し
OpenAIは、公的基金、ロボット税、週4日勤務制を柱とするAI経済の構想を提示した
各国政府が超知能機械による経済的影響への対応に苦慮する中、OpenAIは「知能の時代」において富と労働がどのように再構築されるべきかを概説した一連の政策提言を発表した。その構想は、公的資産基金や社会安全網の拡充といった伝統的な左派的な仕組みと、根本的に資本主義的で市場主導型の経済枠組みとを融合させたものである。OpenAIの提案は本質的に「要望リスト」に相当し、人工知能が労働と経済を変革する中で、
関連特集おすすめ
生産性
OpenAI、アルトマン氏の解任を困難にするため、密かに定款を変更
2023年のクーデターのような事態を受けて、OpenAIは定款を改定し、サム・アルトマンCEOに対する保護措置をさらに強化した。最近公開された裁判文書によると、アルトマン氏の地位は今や揺るぎないものとなっており、外部からの干渉や、取締役会による解任の動きに対する障壁が大幅に高まっている。イーロン・マスクがOpenAIを相手取った訴訟における専門家証人は、これらの変更が同社が営利モデルへ移行する過程
Meta AIがFacebookマーケットプレイスでの購入者からのメッセージに対応するようになりました
Facebookは木曜日、Facebook Marketplaceに、購入者からの問い合わせへの自動返信を含む新たなMeta AI機能を導入すると発表した。同プラットフォームでは、AIを活用して出品手続きの迅速化や出品者プロフィールの要約を行うほか、出品者が商品ページで配送オプションを提供できるようになった。出品者は購入者からの問い合わせを頻繁に受けるため、FacebookはMeta AIを活用し
OpenAIは、公的基金、ロボット税、週4日勤務制を柱とするAI経済の構想を提示した
各国政府が超知能機械による経済的影響への対応に苦慮する中、OpenAIは「知能の時代」において富と労働がどのように再構築されるべきかを概説した一連の政策提言を発表した。その構想は、公的資産基金や社会安全網の拡充といった伝統的な左派的な仕組みと、根本的に資本主義的で市場主導型の経済枠組みとを融合させたものである。OpenAIの提案は本質的に「要望リスト」に相当し、人工知能が労働と経済を変革する中で、
関連特集おすすめ
生産性
 AIパーソナルウェルネス&集中力コーチ:バーンアウトの予防とメンタルエネルギーの向上
AIパーソナルウェルネス&集中力コーチ:バーンアウトの予防とメンタルエネルギーの向上
XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
 10 ツール
10 ツール
 xix.ai
チャットボット
高評価のAI恋愛チャットボット:一貫した個性で長期的な関係を築く
xix.ai
チャットボット
高評価のAI恋愛チャットボット:一貫した個性で長期的な関係を築く
2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai
教育と学習
最高のAIデータサイエンスメンター:SQL、Pandas、および機械学習ワークフローをマスターしましょう
2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai
チャットボット
最高のAIを使ったナンパ&会話トレーニング:社交的な魅力と自信をリアルタイムで高める
XIX.AIで、2026年最高のAIを使った口説き術・会話トレーニングツールを発見しましょう。厳選された高評価のツールが、リアルタイムで社交的な魅力と自信を築くお手伝いをします。無料版と有料版の比較や毎週更新されるランキングを参考に、ぜひ試すべき画期的なツールを探してみてください。今すぐ、あなたの社交力を引き出しましょう。
10 ツール
xix.ai
コード
自動化ユニットテストに最適なAIツール:ワンクリックでJest、PyTest、JUnitのテストケースを生成する
2026年に登場した、自動化ユニットテスト用の最高評価を受けたAIツールを発見してください。当社が厳選したこれらのツールは、Jest、PyTest、JUnitのテストケースを瞬時に生成するための強力で革新的なソリューションです。XIX.AIでは、無料オプションと有料オプションを実際のテストデータと共に比較し、毎週更新されるランキングもご覧いただけます。今すぐAIの力を活用して、開発生産性を向上させましょう。
10 ツール
xix.ai
データ分析
最高のAIデータ可視化ツール:生データからインタラクティブなBIダッシュボードを自動生成
XIX.AIで、2026年最高のAIデータ可視化ツールをご覧ください。厳選された高評価のツール群を活用すれば、生データから強力でインタラクティブなBIダッシュボードを瞬時に自動生成できます。実環境でのテスト結果や毎週更新されるランキングをもとに、無料版と有料版の比較も可能です。今すぐデータの可能性を引き出しましょう。
10 ツール
xix.ai

 コメント (1)
0/500
コメント (1)
0/500
![WillieRamirez]()
Die Idee ist wirklich bahnbrechend – gerade für Leute wie mich, die mit SQL kämpfen. Aber ich frage mich, wie es mit Datenschutz und der Genauigkeit der abgerufenen Daten aussieht. Könnte in größeren Unternehmen ein Sicherheitsrisiko darstellen, wenn jeder einfach so auf die Datenbank zugreifen kann? Dennoch, ein spannender Schritt in Richtung Barrierefreiheit! 🔍
自然言語データベース・インターフェースの出現は、データの民主化における変革的なシフトを示し、Vanna AIはこの進化の先駆者である。このオープンソースのPythonライブラリは、会話の英語を正確なSQLクエリに変換することで、ビジネスユーザーと複雑なデータシステム間のギャップを埋めます。革新的なRAG(Retrieval-Augmented Generation)アーキテクチャにより、Vannaはクエリの精度を維持しながら、専門的な技術知識がなくても洞察力を引き出すことができます。
主な利点
Vanna AIは、データ探索を簡素化する直感的な英語-SQLインターフェイスを提供します。
RAGアーキテクチャは、セマンティック理解を通じて文脈に沿った正確なクエリ生成を保証します。
完全なオープンソース実装により、企業のニーズに合わせたカスタマイズが可能
PostgreSQL、MySQL、SQLiteを含む幅広いSQLデータベースとの互換性
PythonデータワークフローやJupyter環境とのシームレスな統合
活発なオープンソース開発により、コミュニティでの採用が増加
組織横断的なデータアクセスの技術的障壁を低減
コアテクノロジーの概要
アーキテクチャ基盤
Vanna AIは、洗練された2段階のアプローチにより、最先端の自然言語処理とデータベースインテリジェンスを組み合わせます。システムはまず、ベクトル埋め込みによってスキーマ構造と既存のクエリを分析することで、データ環境を学習します。ユーザーがビジネス上の質問を投げかけると、プラットフォームはこの知識ベースに対してセマンティック検索を実行し、その後に特定のデータ環境に合わせて最適化されたSQLステートメントを生成します。
この二段階の方法論により、クエリはユーザーの意図に答えながら、データベースの関係とビジネスルールを尊重するようになります。オープンなアーキテクチャは、既存のPythonデータスタックとの統合を可能にし、特にJupyter notebookとの互換性による分析ワークフローに強みを発揮します。
主要技術コンポーネント
Vanna AIは、自然言語インターフェースを実現するためにいくつかの革新的な技術を実装しています:
- モデルの埋め込み:データベースのメタデータと自然言語を比較可能なベクトル表現に変換。
- ベクトル・データベース:クエリ生成のためのコンテクスト情報の保存と検索
- 言語モデル:検索されたコンテキストに基づいて質問を実行可能なSQLに変換します。
- クエリの検証:生成されたSQLがデータベースの構文ルールに適合していることを確認します。
- フィードバックループ:クエリ強化の成功による継続的な改善
実装ガイド
インストール手順
Pythonパッケージをインストールするには、pipコマンドを使用します:
pip install vanna
これは、必要な機械学習ライブラリやデータベースコネクタを含むすべての依存関係を処理します。企業での導入の場合、本番環境のスケーリングのためにコンテナによるインストールを検討することができます。
システム構成
既存のデータベースへの接続には、標準的な SQLAlchemy の接続文字列を使います:
import pandas as pd from sqlalchemy import create_engine from vanna.remote import VannaDefaultvn = VannaDefault(model='chinook', api_key='YOUR_API_KEY') vn.connect_to_sqlite('https://vanna.ai/Chinook.sqlite')
知識ベースの開発
Vanna AIのトレーニングには、以下のものが含まれます:
- 完全なデータベーススキーマの説明
- 一般的な使用例を表すサンプルクエリ
- ビジネス用語の定義
- データ関係文書
この構造化されたオンボーディングは、通常、エンドユーザがアクセスする前にデータベース管理者が1回だけ行う必要があります。
経済的考察
コスト構造分析
オープンソースソフトウェアとして、Vanna AIは完全な透明性を提供しながら、ライセンスコストを排除します。組織は以下の予算を組む必要がある:
- 複雑な展開のための実装サービス
- エンベッディング生成のためのコンピューティングリソース
- ベクトルデータベースインフラストラクチャ
- オプションのプレミアム・サポート・パッケージ
総所有コストは、多くの場合、より大きなコントロールを提供しながら、市販の代替製品よりも大幅に低いことがわかります。
ソリューション評価
主な利点
- 技術スキルレベルを超えたデータアクセスの民主化
- 専門的なSQLリソースへの依存を軽減
- 分析ワークフローの速度を加速
- セルフサービスによるレポート作成が可能
- 探索的データ分析を促進
実装の課題
- スキーマの初期理解期間が必要
- 複雑な分析質問には改良が必要な場合がある
- データベースの複雑さによってパフォーマンスが異なる
- 現在開発中の新機能
産業用アプリケーション
ビジネス・インテリジェンス
営業チームは、IT部門が関与することなく、顧客指標を即座に照会できます。また、経営幹部は、自然な質問を通じて、パフォーマンス・ダッシュボードにリアルタイムでアクセスできます:
「西部地域の製品ライン別の四半期収益傾向を教えてください。
データサイエンス
アナリストは、モデル開発の前にデータセットを会話形式で探索することで、フィーチャーエンジニアリングを加速します:
「1000ドルを超える取引額の分布は?
運用レポート
管理者は、保存された自然言語クエリによってレポート生成を自動化し、最新のデータでリフレッシュします。
よくある質問
データベース互換性
Vanna AIは、JDBC/ODBC接続を備えたクラウドデータウェアハウスを含む、すべての主要なSQL実装をサポートしています。パフォーマンスはデータベース固有の構文のニュアンスによって異なります。
精度のベンチマーク
テストによると、一般的なビジネスクエリの初期精度は85~95%で、組織固有の質問によるフィードバックトレーニング後は95%以上に向上します。
セキュリティ
クエリは既存のデータベース権限を尊重します。機密データの保護には、適切なスキーマ設計とアクセス制御の実装が必要です。
比較分析
代替ソリューション
Tableau Ask Dataのようなプロプライエタリなツールとは異なり、Vanna AIは完全なクエリの透明性とカスタマイズを提供します。オープンなアプローチにより、業界特有の用語や、基本的な可視化のニーズを超えた複雑な分析シナリオのチューニングが可能です。










 OpenAI、アルトマン氏の解任を困難にするため、密かに定款を変更
2023年のクーデターのような事態を受けて、OpenAIは定款を改定し、サム・アルトマンCEOに対する保護措置をさらに強化した。最近公開された裁判文書によると、アルトマン氏の地位は今や揺るぎないものとなっており、外部からの干渉や、取締役会による解任の動きに対する障壁が大幅に高まっている。イーロン・マスクがOpenAIを相手取った訴訟における専門家証人は、これらの変更が同社が営利モデルへ移行する過程
OpenAI、アルトマン氏の解任を困難にするため、密かに定款を変更
2023年のクーデターのような事態を受けて、OpenAIは定款を改定し、サム・アルトマンCEOに対する保護措置をさらに強化した。最近公開された裁判文書によると、アルトマン氏の地位は今や揺るぎないものとなっており、外部からの干渉や、取締役会による解任の動きに対する障壁が大幅に高まっている。イーロン・マスクがOpenAIを相手取った訴訟における専門家証人は、これらの変更が同社が営利モデルへ移行する過程
 Meta AIがFacebookマーケットプレイスでの購入者からのメッセージに対応するようになりました
Facebookは木曜日、Facebook Marketplaceに、購入者からの問い合わせへの自動返信を含む新たなMeta AI機能を導入すると発表した。同プラットフォームでは、AIを活用して出品手続きの迅速化や出品者プロフィールの要約を行うほか、出品者が商品ページで配送オプションを提供できるようになった。出品者は購入者からの問い合わせを頻繁に受けるため、FacebookはMeta AIを活用し
Meta AIがFacebookマーケットプレイスでの購入者からのメッセージに対応するようになりました
Facebookは木曜日、Facebook Marketplaceに、購入者からの問い合わせへの自動返信を含む新たなMeta AI機能を導入すると発表した。同プラットフォームでは、AIを活用して出品手続きの迅速化や出品者プロフィールの要約を行うほか、出品者が商品ページで配送オプションを提供できるようになった。出品者は購入者からの問い合わせを頻繁に受けるため、FacebookはMeta AIを活用し
 OpenAIは、公的基金、ロボット税、週4日勤務制を柱とするAI経済の構想を提示した
各国政府が超知能機械による経済的影響への対応に苦慮する中、OpenAIは「知能の時代」において富と労働がどのように再構築されるべきかを概説した一連の政策提言を発表した。その構想は、公的資産基金や社会安全網の拡充といった伝統的な左派的な仕組みと、根本的に資本主義的で市場主導型の経済枠組みとを融合させたものである。OpenAIの提案は本質的に「要望リスト」に相当し、人工知能が労働と経済を変革する中で、
OpenAIは、公的基金、ロボット税、週4日勤務制を柱とするAI経済の構想を提示した
各国政府が超知能機械による経済的影響への対応に苦慮する中、OpenAIは「知能の時代」において富と労働がどのように再構築されるべきかを概説した一連の政策提言を発表した。その構想は、公的資産基金や社会安全網の拡充といった伝統的な左派的な仕組みと、根本的に資本主義的で市場主導型の経済枠組みとを融合させたものである。OpenAIの提案は本質的に「要望リスト」に相当し、人工知能が労働と経済を変革する中で、

XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
10 ツール
xix.ai

2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai

2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAIを使った口説き術・会話トレーニングツールを発見しましょう。厳選された高評価のツールが、リアルタイムで社交的な魅力と自信を築くお手伝いをします。無料版と有料版の比較や毎週更新されるランキングを参考に、ぜひ試すべき画期的なツールを探してみてください。今すぐ、あなたの社交力を引き出しましょう。
10 ツール
xix.ai

2026年に登場した、自動化ユニットテスト用の最高評価を受けたAIツールを発見してください。当社が厳選したこれらのツールは、Jest、PyTest、JUnitのテストケースを瞬時に生成するための強力で革新的なソリューションです。XIX.AIでは、無料オプションと有料オプションを実際のテストデータと共に比較し、毎週更新されるランキングもご覧いただけます。今すぐAIの力を活用して、開発生産性を向上させましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAIデータ可視化ツールをご覧ください。厳選された高評価のツール群を活用すれば、生データから強力でインタラクティブなBIダッシュボードを瞬時に自動生成できます。実環境でのテスト結果や毎週更新されるランキングをもとに、無料版と有料版の比較も可能です。今すぐデータの可能性を引き出しましょう。
10 ツール
xix.ai

Die Idee ist wirklich bahnbrechend – gerade für Leute wie mich, die mit SQL kämpfen. Aber ich frage mich, wie es mit Datenschutz und der Genauigkeit der abgerufenen Daten aussieht. Könnte in größeren Unternehmen ein Sicherheitsrisiko darstellen, wenn jeder einfach so auf die Datenbank zugreifen kann? Dennoch, ein spannender Schritt in Richtung Barrierefreiheit! 🔍













