
















 Hogar
Hogar
¿Cómo funcionan las redes neuronales convolucionales (CNN) en 2025? Una completa guía visual.
Las redes neuronales convolucionales (CNN) han transformado la visión por ordenador, permitiendo a las máquinas interpretar imágenes con una precisión increíble. Esta detallada guía examina el funcionamiento de las CNN, aclarando los núcleos, las capas convolucionales y la forma en que estos sistemas llegan a sus conclusiones. A través de ejemplos prácticos y herramientas de visualización, revelamos las capacidades de esta tecnología fundacional, desde el análisis de imágenes hasta las implementaciones de codificación.
Puntos clave
Las CNN preservan la estructura bidimensional de las imágenes mediante kernels.
Los núcleos funcionan como filtros que identifican características específicas de la imagen.
Las capas convolucionales aplican estos filtros a las imágenes para producir mapas de características.
Varias capas convolucionales se combinan para detectar patrones visuales complejos.
Las capas de agrupamiento racionalizan los mapas de características reduciendo sus dimensiones.
CNN Explainer ofrece una demostración visual del funcionamiento de estas redes.
Keras, integrado con TensorFlow, simplifica el proceso de codificación de capas CNN.
El aplanamiento prepara los datos para las capas densas que se encargan de la clasificación final.
El ajuste del tamaño del núcleo influye directamente en la calidad de la detección de características.
Las GPU o TPU aceleran el entrenamiento de las CNN para mejorar el rendimiento.
Desvelando las redes neuronales convolucionales
¿Qué es una red neuronal convolucional (CNN)?
Las redes neuronales convolucionales (CNN) son redes neuronales artificiales especializadas diseñadas para procesar información visual. A diferencia de las redes convencionales, que tratan las imágenes como matrices planas de píxeles, las CNN utilizan las relaciones espaciales entre píxeles. Esta capacidad es esencial para la clasificación de imágenes, la detección de objetos y las tareas de segmentación.

Las CNN se inspiran en el funcionamiento del córtex visual humano. Emplean capas especializadas para aprender progresivamente jerarquías de características espaciales, partiendo de elementos básicos como bordes y esquinas hasta llegar a representaciones avanzadas de objetos.
Componentes básicos de las CNN:
- Capas convolucionales: Estos componentes fundamentales utilizan núcleos (o filtros) para detectar características dentro de las imágenes de entrada.
- Capas de agrupamiento: Estas capas reducen el tamaño de las representaciones, disminuyendo el número de parámetros y las demandas computacionales a la vez que crean invariancia de traslación.
- Funciones de activación: Las funciones no lineales, como ReLU, permiten a las redes reconocer patrones complejos.
- Capas totalmente conectadas: Situadas al final de la red, estas capas realizan la clasificación utilizando las características recogidas en las capas anteriores.
La principal ventaja de las CNN radica en el aprendizaje automático de características a partir de los datos, lo que elimina los procesos de extracción manual. Esto las hace excepcionalmente eficaces para diversas aplicaciones de visión por ordenador. Sus exclusivas capas convolucionales las distinguen de otros tipos de redes neuronales.
La importancia de mantener la información 2D
Las redes neuronales tradicionales suelen convertir las imágenes en matrices de píxeles unidimensionales, sacrificando la estructura bidimensional crucial y las relaciones de vecindad. Imagínese que intentara comprender un cuadro conociendo sólo los colores individuales de los puntos sin ver su disposición: se perdería el contexto y la composición general.
La fuerza de las CNN radica en preservar esta estructura bidimensional. Al emplear núcleos que exploran regiones localizadas de la imagen, la red capta las dependencias espaciales entre píxeles. Esto garantiza una identificación precisa de bordes, esquinas y texturas, independientemente de su posición en la imagen.
Contras
iderar una taza de café. Nuestro cerebro la identifica como una taza de café tanto si está colocada a la izquierda como a la derecha. Las CNN emulan esta capacidad. Al mantener la información 2D, las CNN son más resistentes a las variaciones de posición, escala y orientación de los objetos. Esta conciencia espacial mejora sustancialmente la capacidad de la red para generalizar y actuar con precisión sobre datos desconocidos.Núcleos: Los extractores de características
El núcleo de cada capa convolucional es una matriz de pesos compacta que actúa como detector de patrones. Es como una lente especializada que se centra en características concretas de la imagen. Cada núcleo identifica características específicas como bordes, esquinas o texturas.
Un núcleo es fundamentalmente una matriz de pesos. Cada valor de la matriz contiene un peso que se multiplica por los píxeles correspondientes de la imagen de entrada, lo que permite captar la estructura 2D fotográfica para extraer información.
El núcleo recorre la imagen de entrada, ejecutando operaciones de convolución en cada ubicación. Durante este proceso, cada elemento del núcleo se multiplica con los valores de los píxeles correspondientes en las regiones locales de la imagen. Estos productos se suman para crear valores únicos que pueblan el mapa de características de salida.
Ajustando con precisión los pesos del núcleo, la red aprende a reconocer las características relevantes para la tarea. Por ejemplo, un núcleo detector de bordes horizontales contiene pesos positivos a lo largo de una línea horizontal con pesos negativos por encima y por debajo de ella.
Así, los núcleos funcionan como mecanismos de filtrado para la extracción de información.
La capa convolucional en acción
La capa convolucional aplica núcleos a todas las imágenes de entrada. Este enfoque de ventana deslizante combinado con la convolución permite detectar características en toda la imagen.
A medida que los núcleos se desplazan por las imágenes, generan mapas de características que indican la presencia y la intensidad de las características detectadas. Cada valor del mapa de características corresponde a una ubicación de la imagen de entrada, y su magnitud refleja hasta qué punto el patrón del núcleo coincide con el contenido local de la imagen.
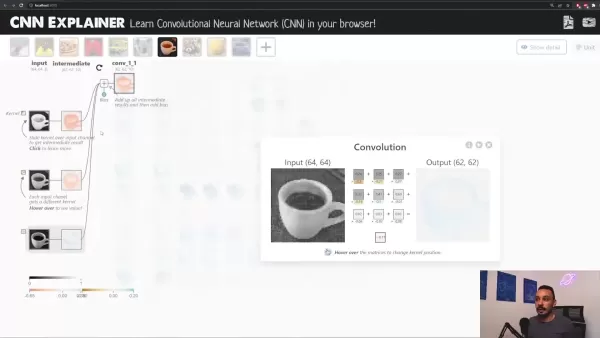
Consideremos el posicionamiento de nuestro núcleo en la primera esquina de la imagen, que comprende seis píxeles. Los pesos del núcleo se multiplican por estos píxeles y la suma se convierte en un único píxel de la nueva imagen. Este proceso se asemeja a la aplicación de filtros de imagen.
Diferentes núcleos dentro de la misma capa convolucional detectan características distintas. Estas características crean en conjunto representaciones de imagen completas. La aplicación de varios núcleos para generar diversos mapas de características permite a las CNN aprender patrones visuales complejos.
En resumen, cada núcleo se replica a través de los canales durante el entrenamiento.
Agrupación de capas: Simplificación de la representación
Las capas de agrupamiento reducen drásticamente las dimensiones espaciales de los mapas de características de las capas convolucionales. Esta reducción de la dimensionalidad tiene múltiples propósitos:
- Reducción del cálculo: La reducción del tamaño de los mapas de características disminuye drásticamente los parámetros y la complejidad computacional.
- Invariancia de la traslación: La agrupación de capas ayuda a las redes a ser insensibles a pequeños cambios de entrada. Por ejemplo, la agrupación máxima selecciona los valores máximos de las regiones locales, reduciendo la sensibilidad a la posición exacta de las características.
- Generalización mejorada: Al resumir la información de las regiones locales, la agrupación fomenta el aprendizaje de características robustas y generalizables que resisten el sobreajuste.

La agrupación máxima extrae valores máximos, medios o mínimos de grupos de píxeles. Con una definición de agrupación de 2x2, cuatro píxeles se reducen a dos, con lo que se reduce a la mitad el número de píxeles y se conserva la información esencial.
Las variantes de agrupación más comunes son la agrupación máxima, media y mínima. La agrupación máxima prevalece sobre todo por su eficacia a la hora de preservar características cruciales durante la reducción de la dimensionalidad. De este modo, se mantiene la eficiencia al tiempo que se conservan representaciones precisas.
Visualización de CNN con CNN Explainer
Aprovechar CNN Explainer para mejorar la comprensión
Comprender los procesos internos de las CNN puede resultar complicado. Afortunadamente, herramientas como CNN Explainer ofrecen interfaces visuales que aclaran las operaciones de la red.

CNN Explainer permite visualizar las transformaciones de cada capa, lo que la convierte en una excelente herramienta educativa para comprender las redes neuronales convolucionales.
Ventajas del uso de CNN Explainer:
- Visualización de mapas de características: Observe los mapas de características de cada capa convolucional para comprender qué patrones aprende la red.
- Comprender las operaciones del núcleo: Pase el ratón sobre las matrices para observar los efectos de los núcleos en las imágenes de entrada y sus contribuciones a los mapas de características.
- Exploración de diferentes arquitecturas: Pruebe varias configuraciones de CNN y observe sus efectos sobre las características aprendidas.
A través de su interfaz visual interactiva, CNN Explainer facilita una comprensión más profunda de la funcionalidad de las CNN.
Codificación de CNNs con Keras
Pasos para codificar un modelo Conv2D
Programar CNNs desde cero puede ser exigente. Frameworks como Keras -estrechamente integrado con TensorFlow- simplifican este proceso a través de APIs de alto nivel para la definición y entrenamiento de redes.
Comience configurando TensorFlow. A continuación, siga estos pasos:
- Añada una capa 2D de convolución.
- Especifique la cantidad de filtros deseada.
- Establezca el número de filtros (por ejemplo, 10 para una CNN de demostración).
- Defina las especificaciones del kernel y las dimensiones de entrada.
El uso de estas API de alto nivel permite desarrollar rápidamente CNN potentes para diversas aplicaciones de visión por ordenador.
Ventajas y desventajas del uso de CNN
Ventajas
Extracción automática de características: Las CNN aprenden de forma independiente las características relevantes, minimizando los requisitos de ingeniería manual.
Conciencia espacial: Las CNN mantienen las relaciones espaciales de los píxeles, lo que garantiza su resistencia a los cambios de posición, escala y orientación de los objetos.
Gran precisión: Las CNN ofrecen un rendimiento de vanguardia en numerosas tareas de visión por ordenador, como la clasificación de imágenes y la detección de objetos.
Generalización: Las CNN se adaptan eficazmente a datos desconocidos, lo que las hace prácticas para su aplicación en el mundo real.
Contras
Complejidad computacional: El entrenamiento de las CNN exige importantes recursos informáticos, sobre todo en el caso de grandes conjuntos de datos y arquitecturas complejas.
Requisitos de datos: Las CNN suelen necesitar una gran cantidad de datos etiquetados para obtener resultados óptimos.
Interpretabilidad: Comprender los procesos de toma de decisiones de las CNN puede resultar difícil.
Sobreajuste: Las CNN suelen sobreajustarse cuando se entrenan con conjuntos de datos limitados.
Preguntas más frecuentes
¿Cuáles son las principales diferencias entre las CNN y las redes neuronales tradicionales?
Las CNN están especializadas en el procesamiento de datos visuales manteniendo relaciones espaciales 2D, mientras que las redes tradicionales procesan imágenes como matrices 1D. Las CNN también automatizan el aprendizaje de características, a diferencia de las redes tradicionales, que a menudo necesitan la ingeniería manual de características.
¿Qué papel desempeñan las funciones de activación en las CNN?
Las funciones de activación introducen la no linealidad, lo que permite el reconocimiento de patrones complejos. Sin ellas, las redes sólo comprenderían relaciones lineales, lo que limitaría su potencial para resolver problemas.
¿Por qué se recomienda Google Colab para el entrenamiento de las CNN?
El entrenamiento de CNN requiere un cálculo intensivo. Google Colab ofrece acceso complementario a la GPU y la TPU, lo que acelera drásticamente el entrenamiento en comparación con los procesadores estándar.
Preguntas relacionadas
¿Pueden utilizarse las CNN para tareas distintas del reconocimiento de imágenes?
Aunque las CNN destacan en visión computerizada, se adaptan a otros dominios como el procesamiento del lenguaje natural y el análisis de audio. Estas aplicaciones convierten los datos de entrada en estructuras reticulares procesables por capas convolucionales. En PNL, por ejemplo, el texto se convierte en una matriz en la que las filas representan palabras y las columnas, características como la incrustación de palabras. El principio subyacente persiste: Las CNN extraen de forma extraordinaria patrones de las regiones locales de los datos de entrada. Su flexibilidad arquitectónica las hace valiosas para diversas aplicaciones de aprendizaje automático.
Artículo relacionado
 WordPress.com ya permite que los agentes de IA redacten y publiquen entradas, entre otras cosas
WordPress.com, la popular plataforma de alojamiento web y publicación, está incorporando ahora agentes de IA, una iniciativa que podría transformar el aspecto y la experiencia de la web. La empresa an
Claude, la IA experimental de Anthropic, lleva a cabo negociaciones y transacciones en una prueba de comercio electrónico
A medida que la inteligencia artificial avanza rápidamente, Anthropic puso en marcha discretamente el pasado viernes un experimento interno denominado «Project Deal», en el que se ponía de manifiesto
DeepSeek Code, listo para su lanzamiento
A medida que la tecnología de IA avanza a pasos agigantados, DeepSeek se encuentra en un momento decisivo. La empresa de IA ha revelado recientemente que ha conseguido más de 70 000 millones de yuanes
Recomendaciones de temas especiales relacionados
Negocio
WordPress.com ya permite que los agentes de IA redacten y publiquen entradas, entre otras cosas
WordPress.com, la popular plataforma de alojamiento web y publicación, está incorporando ahora agentes de IA, una iniciativa que podría transformar el aspecto y la experiencia de la web. La empresa an
Claude, la IA experimental de Anthropic, lleva a cabo negociaciones y transacciones en una prueba de comercio electrónico
A medida que la inteligencia artificial avanza rápidamente, Anthropic puso en marcha discretamente el pasado viernes un experimento interno denominado «Project Deal», en el que se ponía de manifiesto
DeepSeek Code, listo para su lanzamiento
A medida que la tecnología de IA avanza a pasos agigantados, DeepSeek se encuentra en un momento decisivo. La empresa de IA ha revelado recientemente que ha conseguido más de 70 000 millones de yuanes
Recomendaciones de temas especiales relacionados
Negocio
 Las mejores herramientas de selección de personal basadas en IA: filtrar currículos y automatizar la programación de entrevistas con los candidatos
Las mejores herramientas de selección de personal basadas en IA: filtrar currículos y automatizar la programación de entrevistas con los candidatos
Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
 10 herramientas
10 herramientas
 xix.ai
Productividad
Entrenadores personales de bienestar y concentración basados en IA: controla el agotamiento y aumenta tus niveles de energía mental
xix.ai
Productividad
Entrenadores personales de bienestar y concentración basados en IA: controla el agotamiento y aumenta tus niveles de energía mental
Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai
chatbot
Los mejores chatbots románticos con IA: crea relaciones duraderas con personalidades coherentes
Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai
Educación y aprendizaje
Los mejores mentores en ciencia de datos y IA: dominan SQL, Pandas y flujos de trabajo de aprendizaje automático.
Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
10 herramientas
xix.ai
chatbot
Los mejores entrenadores de IA para ligar y conversar: mejora tu carisma social y tu confianza en tiempo real
Descubre los mejores cursos de 2026 sobre coqueteo y conversación con IA en XIX.AI. Nuestra selección, cuidadosamente seleccionada y con las mejores valoraciones, te ayuda a desarrollar tu carisma social y tu confianza en tiempo real. Explora herramientas imprescindibles y revolucionarias con comparativas entre versiones gratuitas y de pago, y clasificaciones que se actualizan semanalmente. Potencia hoy mismo tus habilidades sociales.
10 herramientas
xix.ai
código
Las mejores herramientas de IA para pruebas unitarias automatizadas: genera casos de prueba con Jest, PyTest y JUnit con un solo clic
Descubre las mejores herramientas de IA de 2026 para la automatización de pruebas unitarias. Nuestra selección incluye potentes soluciones revolucionarias que permiten generar casos de prueba para Jest, PyTest y JUnit al instante. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones actualizadas semanalmente en XIX.AI. Aprovecha las ventajas de la IA y aumenta la productividad de tu desarrollo hoy mismo.
10 herramientas
xix.ai

 comentario (0)
0/500
comentario (0)
0/500
Las redes neuronales convolucionales (CNN) han transformado la visión por ordenador, permitiendo a las máquinas interpretar imágenes con una precisión increíble. Esta detallada guía examina el funcionamiento de las CNN, aclarando los núcleos, las capas convolucionales y la forma en que estos sistemas llegan a sus conclusiones. A través de ejemplos prácticos y herramientas de visualización, revelamos las capacidades de esta tecnología fundacional, desde el análisis de imágenes hasta las implementaciones de codificación.
Puntos clave
Las CNN preservan la estructura bidimensional de las imágenes mediante kernels.
Los núcleos funcionan como filtros que identifican características específicas de la imagen.
Las capas convolucionales aplican estos filtros a las imágenes para producir mapas de características.
Varias capas convolucionales se combinan para detectar patrones visuales complejos.
Las capas de agrupamiento racionalizan los mapas de características reduciendo sus dimensiones.
CNN Explainer ofrece una demostración visual del funcionamiento de estas redes.
Keras, integrado con TensorFlow, simplifica el proceso de codificación de capas CNN.
El aplanamiento prepara los datos para las capas densas que se encargan de la clasificación final.
El ajuste del tamaño del núcleo influye directamente en la calidad de la detección de características.
Las GPU o TPU aceleran el entrenamiento de las CNN para mejorar el rendimiento.
Desvelando las redes neuronales convolucionales
¿Qué es una red neuronal convolucional (CNN)?
Las redes neuronales convolucionales (CNN) son redes neuronales artificiales especializadas diseñadas para procesar información visual. A diferencia de las redes convencionales, que tratan las imágenes como matrices planas de píxeles, las CNN utilizan las relaciones espaciales entre píxeles. Esta capacidad es esencial para la clasificación de imágenes, la detección de objetos y las tareas de segmentación.
Las CNN se inspiran en el funcionamiento del córtex visual humano. Emplean capas especializadas para aprender progresivamente jerarquías de características espaciales, partiendo de elementos básicos como bordes y esquinas hasta llegar a representaciones avanzadas de objetos.
Componentes básicos de las CNN:
- Capas convolucionales: Estos componentes fundamentales utilizan núcleos (o filtros) para detectar características dentro de las imágenes de entrada.
- Capas de agrupamiento: Estas capas reducen el tamaño de las representaciones, disminuyendo el número de parámetros y las demandas computacionales a la vez que crean invariancia de traslación.
- Funciones de activación: Las funciones no lineales, como ReLU, permiten a las redes reconocer patrones complejos.
- Capas totalmente conectadas: Situadas al final de la red, estas capas realizan la clasificación utilizando las características recogidas en las capas anteriores.
La principal ventaja de las CNN radica en el aprendizaje automático de características a partir de los datos, lo que elimina los procesos de extracción manual. Esto las hace excepcionalmente eficaces para diversas aplicaciones de visión por ordenador. Sus exclusivas capas convolucionales las distinguen de otros tipos de redes neuronales.
La importancia de mantener la información 2D
Las redes neuronales tradicionales suelen convertir las imágenes en matrices de píxeles unidimensionales, sacrificando la estructura bidimensional crucial y las relaciones de vecindad. Imagínese que intentara comprender un cuadro conociendo sólo los colores individuales de los puntos sin ver su disposición: se perdería el contexto y la composición general.
La fuerza de las CNN radica en preservar esta estructura bidimensional. Al emplear núcleos que exploran regiones localizadas de la imagen, la red capta las dependencias espaciales entre píxeles. Esto garantiza una identificación precisa de bordes, esquinas y texturas, independientemente de su posición en la imagen.
Contras
iderar una taza de café. Nuestro cerebro la identifica como una taza de café tanto si está colocada a la izquierda como a la derecha. Las CNN emulan esta capacidad. Al mantener la información 2D, las CNN son más resistentes a las variaciones de posición, escala y orientación de los objetos. Esta conciencia espacial mejora sustancialmente la capacidad de la red para generalizar y actuar con precisión sobre datos desconocidos.Núcleos: Los extractores de características
El núcleo de cada capa convolucional es una matriz de pesos compacta que actúa como detector de patrones. Es como una lente especializada que se centra en características concretas de la imagen. Cada núcleo identifica características específicas como bordes, esquinas o texturas.
Un núcleo es fundamentalmente una matriz de pesos. Cada valor de la matriz contiene un peso que se multiplica por los píxeles correspondientes de la imagen de entrada, lo que permite captar la estructura 2D fotográfica para extraer información.
El núcleo recorre la imagen de entrada, ejecutando operaciones de convolución en cada ubicación. Durante este proceso, cada elemento del núcleo se multiplica con los valores de los píxeles correspondientes en las regiones locales de la imagen. Estos productos se suman para crear valores únicos que pueblan el mapa de características de salida.
Ajustando con precisión los pesos del núcleo, la red aprende a reconocer las características relevantes para la tarea. Por ejemplo, un núcleo detector de bordes horizontales contiene pesos positivos a lo largo de una línea horizontal con pesos negativos por encima y por debajo de ella.
Así, los núcleos funcionan como mecanismos de filtrado para la extracción de información.
La capa convolucional en acción
La capa convolucional aplica núcleos a todas las imágenes de entrada. Este enfoque de ventana deslizante combinado con la convolución permite detectar características en toda la imagen.
A medida que los núcleos se desplazan por las imágenes, generan mapas de características que indican la presencia y la intensidad de las características detectadas. Cada valor del mapa de características corresponde a una ubicación de la imagen de entrada, y su magnitud refleja hasta qué punto el patrón del núcleo coincide con el contenido local de la imagen.
Consideremos el posicionamiento de nuestro núcleo en la primera esquina de la imagen, que comprende seis píxeles. Los pesos del núcleo se multiplican por estos píxeles y la suma se convierte en un único píxel de la nueva imagen. Este proceso se asemeja a la aplicación de filtros de imagen.
Diferentes núcleos dentro de la misma capa convolucional detectan características distintas. Estas características crean en conjunto representaciones de imagen completas. La aplicación de varios núcleos para generar diversos mapas de características permite a las CNN aprender patrones visuales complejos.
En resumen, cada núcleo se replica a través de los canales durante el entrenamiento.
Agrupación de capas: Simplificación de la representación
Las capas de agrupamiento reducen drásticamente las dimensiones espaciales de los mapas de características de las capas convolucionales. Esta reducción de la dimensionalidad tiene múltiples propósitos:
- Reducción del cálculo: La reducción del tamaño de los mapas de características disminuye drásticamente los parámetros y la complejidad computacional.
- Invariancia de la traslación: La agrupación de capas ayuda a las redes a ser insensibles a pequeños cambios de entrada. Por ejemplo, la agrupación máxima selecciona los valores máximos de las regiones locales, reduciendo la sensibilidad a la posición exacta de las características.
- Generalización mejorada: Al resumir la información de las regiones locales, la agrupación fomenta el aprendizaje de características robustas y generalizables que resisten el sobreajuste.
La agrupación máxima extrae valores máximos, medios o mínimos de grupos de píxeles. Con una definición de agrupación de 2x2, cuatro píxeles se reducen a dos, con lo que se reduce a la mitad el número de píxeles y se conserva la información esencial.
Las variantes de agrupación más comunes son la agrupación máxima, media y mínima. La agrupación máxima prevalece sobre todo por su eficacia a la hora de preservar características cruciales durante la reducción de la dimensionalidad. De este modo, se mantiene la eficiencia al tiempo que se conservan representaciones precisas.
Visualización de CNN con CNN Explainer
Aprovechar CNN Explainer para mejorar la comprensión
Comprender los procesos internos de las CNN puede resultar complicado. Afortunadamente, herramientas como CNN Explainer ofrecen interfaces visuales que aclaran las operaciones de la red.
CNN Explainer permite visualizar las transformaciones de cada capa, lo que la convierte en una excelente herramienta educativa para comprender las redes neuronales convolucionales.
Ventajas del uso de CNN Explainer:
- Visualización de mapas de características: Observe los mapas de características de cada capa convolucional para comprender qué patrones aprende la red.
- Comprender las operaciones del núcleo: Pase el ratón sobre las matrices para observar los efectos de los núcleos en las imágenes de entrada y sus contribuciones a los mapas de características.
- Exploración de diferentes arquitecturas: Pruebe varias configuraciones de CNN y observe sus efectos sobre las características aprendidas.
A través de su interfaz visual interactiva, CNN Explainer facilita una comprensión más profunda de la funcionalidad de las CNN.
Codificación de CNNs con Keras
Pasos para codificar un modelo Conv2D
Programar CNNs desde cero puede ser exigente. Frameworks como Keras -estrechamente integrado con TensorFlow- simplifican este proceso a través de APIs de alto nivel para la definición y entrenamiento de redes.
Comience configurando TensorFlow. A continuación, siga estos pasos:
- Añada una capa 2D de convolución.
- Especifique la cantidad de filtros deseada.
- Establezca el número de filtros (por ejemplo, 10 para una CNN de demostración).
- Defina las especificaciones del kernel y las dimensiones de entrada.
El uso de estas API de alto nivel permite desarrollar rápidamente CNN potentes para diversas aplicaciones de visión por ordenador.
Ventajas y desventajas del uso de CNN
Ventajas
Extracción automática de características: Las CNN aprenden de forma independiente las características relevantes, minimizando los requisitos de ingeniería manual.
Conciencia espacial: Las CNN mantienen las relaciones espaciales de los píxeles, lo que garantiza su resistencia a los cambios de posición, escala y orientación de los objetos.
Gran precisión: Las CNN ofrecen un rendimiento de vanguardia en numerosas tareas de visión por ordenador, como la clasificación de imágenes y la detección de objetos.
Generalización: Las CNN se adaptan eficazmente a datos desconocidos, lo que las hace prácticas para su aplicación en el mundo real.
Contras
Complejidad computacional: El entrenamiento de las CNN exige importantes recursos informáticos, sobre todo en el caso de grandes conjuntos de datos y arquitecturas complejas.
Requisitos de datos: Las CNN suelen necesitar una gran cantidad de datos etiquetados para obtener resultados óptimos.
Interpretabilidad: Comprender los procesos de toma de decisiones de las CNN puede resultar difícil.
Sobreajuste: Las CNN suelen sobreajustarse cuando se entrenan con conjuntos de datos limitados.
Preguntas más frecuentes
¿Cuáles son las principales diferencias entre las CNN y las redes neuronales tradicionales?
Las CNN están especializadas en el procesamiento de datos visuales manteniendo relaciones espaciales 2D, mientras que las redes tradicionales procesan imágenes como matrices 1D. Las CNN también automatizan el aprendizaje de características, a diferencia de las redes tradicionales, que a menudo necesitan la ingeniería manual de características.
¿Qué papel desempeñan las funciones de activación en las CNN?
Las funciones de activación introducen la no linealidad, lo que permite el reconocimiento de patrones complejos. Sin ellas, las redes sólo comprenderían relaciones lineales, lo que limitaría su potencial para resolver problemas.
¿Por qué se recomienda Google Colab para el entrenamiento de las CNN?
El entrenamiento de CNN requiere un cálculo intensivo. Google Colab ofrece acceso complementario a la GPU y la TPU, lo que acelera drásticamente el entrenamiento en comparación con los procesadores estándar.
Preguntas relacionadas
¿Pueden utilizarse las CNN para tareas distintas del reconocimiento de imágenes?
Aunque las CNN destacan en visión computerizada, se adaptan a otros dominios como el procesamiento del lenguaje natural y el análisis de audio. Estas aplicaciones convierten los datos de entrada en estructuras reticulares procesables por capas convolucionales. En PNL, por ejemplo, el texto se convierte en una matriz en la que las filas representan palabras y las columnas, características como la incrustación de palabras. El principio subyacente persiste: Las CNN extraen de forma extraordinaria patrones de las regiones locales de los datos de entrada. Su flexibilidad arquitectónica las hace valiosas para diversas aplicaciones de aprendizaje automático.










 WordPress.com ya permite que los agentes de IA redacten y publiquen entradas, entre otras cosas
WordPress.com, la popular plataforma de alojamiento web y publicación, está incorporando ahora agentes de IA, una iniciativa que podría transformar el aspecto y la experiencia de la web. La empresa an
WordPress.com ya permite que los agentes de IA redacten y publiquen entradas, entre otras cosas
WordPress.com, la popular plataforma de alojamiento web y publicación, está incorporando ahora agentes de IA, una iniciativa que podría transformar el aspecto y la experiencia de la web. La empresa an
 Claude, la IA experimental de Anthropic, lleva a cabo negociaciones y transacciones en una prueba de comercio electrónico
A medida que la inteligencia artificial avanza rápidamente, Anthropic puso en marcha discretamente el pasado viernes un experimento interno denominado «Project Deal», en el que se ponía de manifiesto
Claude, la IA experimental de Anthropic, lleva a cabo negociaciones y transacciones en una prueba de comercio electrónico
A medida que la inteligencia artificial avanza rápidamente, Anthropic puso en marcha discretamente el pasado viernes un experimento interno denominado «Project Deal», en el que se ponía de manifiesto
 DeepSeek Code, listo para su lanzamiento
A medida que la tecnología de IA avanza a pasos agigantados, DeepSeek se encuentra en un momento decisivo. La empresa de IA ha revelado recientemente que ha conseguido más de 70 000 millones de yuanes
DeepSeek Code, listo para su lanzamiento
A medida que la tecnología de IA avanza a pasos agigantados, DeepSeek se encuentra en un momento decisivo. La empresa de IA ha revelado recientemente que ha conseguido más de 70 000 millones de yuanes

Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai

Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai

Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai

Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
10 herramientas
xix.ai

Descubre los mejores cursos de 2026 sobre coqueteo y conversación con IA en XIX.AI. Nuestra selección, cuidadosamente seleccionada y con las mejores valoraciones, te ayuda a desarrollar tu carisma social y tu confianza en tiempo real. Explora herramientas imprescindibles y revolucionarias con comparativas entre versiones gratuitas y de pago, y clasificaciones que se actualizan semanalmente. Potencia hoy mismo tus habilidades sociales.
10 herramientas
xix.ai

Descubre las mejores herramientas de IA de 2026 para la automatización de pruebas unitarias. Nuestra selección incluye potentes soluciones revolucionarias que permiten generar casos de prueba para Jest, PyTest y JUnit al instante. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones actualizadas semanalmente en XIX.AI. Aprovecha las ventajas de la IA y aumenta la productividad de tu desarrollo hoy mismo.
10 herramientas
xix.ai













