
















 Maison
Maison
Google dévoile son modèle allégé Gemini 3.1, doté d'une interface utilisateur époustouflante
Google DeepMind a dévoilé sa dernière avancée en matière de vitesse dans le domaine de l'IA générative : Gemini 3.1 Flash-Lite. Ce modèle offre une efficacité de raisonnement exceptionnelle, permettant un rendu Web en temps quasi réel et faisant passer l'IA de l'interaction textuelle de base à la pointe du développement d'interfaces utilisateur dynamiques.
Gain de performance et compromis en termes de coûts
Les données officielles indiquent que Gemini 3.1 Flash-Lite réagit 2,5 fois plus vite que son prédécesseur, Gemini 2.5 Flash. Il atteint un débit remarquable, générant plus de 360 tokens par seconde. Lors d'évaluations de tâches multimodales menées par le cabinet indépendant Artificial Analysis, ce modèle léger a même surpassé des concurrents plus imposants tels que Claude Opus 4.6.
Cependant, cette amélioration de la vitesse s'accompagne d'une révision de la structure des coûts. Le prix de sortie du modèle est passé de 0,40 $ à 1,50 $ par million de tokens, reflétant le surcoût de calcul lié à une technologie haute performance et à faible latence.
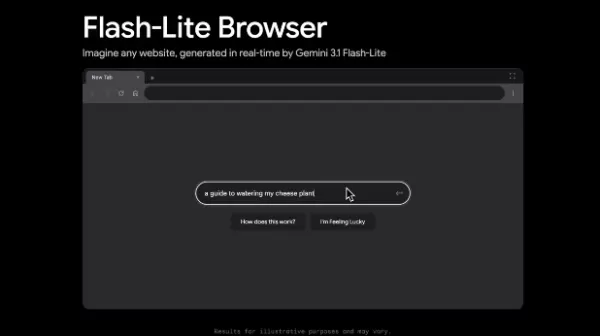
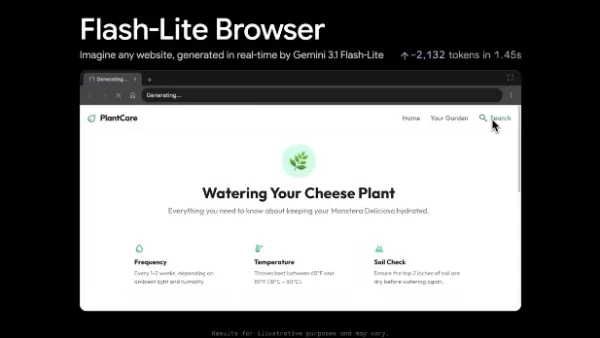
Démonstration du « pseudo-navigateur » et scénarios d'application
Parallèlement au modèle, Google a publié une application de démonstration « pseudo-navigateur ». Les utilisateurs peuvent fournir des instructions descriptives, et le système génère et affiche le contenu web correspondant en quelques millisecondes. Bien que la démo actuelle puisse présenter une certaine instabilité avec une logique complexe lors de sessions prolongées, elle démontre un potentiel significatif dans plusieurs domaines :
Prototypage rapide : visualisez instantanément des maquettes et des concepts d'interface utilisateur.
Interfaces interactives dynamiques : adaptation de la structure Web en fonction de l'intention de l'utilisateur en temps réel.
Tâches multimodales à faible latence : constitue une alternative efficace aux modèles plus lourds dans les scénarios exigeant un retour rapide.
Gemini 3.1 Flash-Lite est désormais disponible sur Google AI Studio et Vertex AI, où les utilisateurs peuvent découvrir les capacités de génération ultra-rapide.
Article connexe
 Claude a été utilisé pour créer des paquets npm malveillants : plus de 670 paquets compromis menacent l'open source
Un incident de cybersécurité récent met en lumière la manière dont les grands modèles linguistiques (LLM) sont détournés pour développer des logiciels malveillants. Le chercheur en sécurité Sibi Moosa
Reliance dévoile un plan d'investissement de 110 milliards de dollars dans l'IA alors que l'Inde accélère sa transition technologique
Mukesh Ambani, le président milliardaire du conglomérat indien Reliance, a annoncé jeudi un plan de 10 000 milliards de roupies (environ 110 milliards de dollars) visant à mettre en place une infrastr
Zhiyuan WITA met fin à son projet d'interaction avec des robots « nus » en déposant sa première demande d'agrément
Le secteur de l'intelligence incarnée a franchi une étape importante. Selon la dernière annonce de l'Administration du cyberespace de Shanghai, le grand modèle WITA développé par Zhiyuan a mené à bien
Recommandations de sujets spéciaux liés
Création de bande dessinée
Claude a été utilisé pour créer des paquets npm malveillants : plus de 670 paquets compromis menacent l'open source
Un incident de cybersécurité récent met en lumière la manière dont les grands modèles linguistiques (LLM) sont détournés pour développer des logiciels malveillants. Le chercheur en sécurité Sibi Moosa
Reliance dévoile un plan d'investissement de 110 milliards de dollars dans l'IA alors que l'Inde accélère sa transition technologique
Mukesh Ambani, le président milliardaire du conglomérat indien Reliance, a annoncé jeudi un plan de 10 000 milliards de roupies (environ 110 milliards de dollars) visant à mettre en place une infrastr
Zhiyuan WITA met fin à son projet d'interaction avec des robots « nus » en déposant sa première demande d'agrément
Le secteur de l'intelligence incarnée a franchi une étape importante. Selon la dernière annonce de l'Administration du cyberespace de Shanghai, le grand modèle WITA développé par Zhiyuan a mené à bien
Recommandations de sujets spéciaux liés
Création de bande dessinée
 Les meilleurs outils d'auto-coloration IA pour les mangas : appliquez des couleurs unies sans aucune erreur de cohérence
Les meilleurs outils d'auto-coloration IA pour les mangas : appliquez des couleurs unies sans aucune erreur de cohérence
Découvrez les meilleurs outils d'auto-coloration IA pour mangas de 2026 sur XIX.AI. Notre sélection regroupe des solutions de premier plan qui changent la donne : elles appliquent des couleurs unies sans aucune erreur de cohérence, ce qui booste votre productivité. Consultez nos comparatifs entre versions gratuites et payantes, nos tests en conditions réelles et nos classements mis à jour chaque semaine pour trouver l'outil qui vous convient le mieux. Profitez dès aujourd'hui de l'avantage de l'IA.
 10 outils
10 outils
 xix.ai
en écrivant
Les meilleurs créateurs de profils de fiction basés sur l'IA : générer des motivations de personnages cohérentes et des faiblesses fatales
xix.ai
en écrivant
Les meilleurs créateurs de profils de fiction basés sur l'IA : générer des motivations de personnages cohérentes et des faiblesses fatales
Découvrez les meilleurs outils de création de profils de personnages basés sur l'IA de 2026 pour donner de la profondeur à vos personnages. La sélection de XIX.AI regroupe les outils les mieux notés et les plus innovants, capables de générer des motivations cohérentes et des défauts fatals. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez dès maintenant votre potentiel de narration.
10 outils
xix.ai
Entreprise
Les meilleurs logiciels d'optimisation des prix basés sur l'IA : suivez vos concurrents et ajustez automatiquement les prix de votre boutique
Découvrez les meilleurs logiciels d'optimisation des prix basés sur l'IA pour 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan qui changent la donne : ils surveillent vos concurrents et ajustent automatiquement les prix de votre boutique pour maximiser vos bénéfices. Comparez les options gratuites et payantes grâce à des tests concrets. Prenez dès maintenant une longueur d'avance en matière de tarification.
10 outils
xix.ai
code
Les meilleurs outils d'analyse de code basés sur l'IA : automatisez la conformité au code propre et refactorisez les fichiers des dépôts hérités
Découvrez les meilleurs outils d'analyse de code par IA de 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan, véritables révolutionnaires, permettant d'automatiser la conformité au code propre et de refactoriser les fichiers de dépôts hérités. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Prenez dès aujourd'hui une longueur d'avance grâce à l'IA.
10 outils
xix.ai
Synthèse vocale
Les meilleures applications de synthèse vocale basées sur l'IA pour la dyslexie : un soutien à l'apprentissage et à l'efficacité en lecture pour les élèves
Découvrez les meilleures applications de synthèse vocale par IA de 2026, spécialement sélectionnées pour aider les personnes dyslexiques. Notre classement d'experts compare les outils gratuits et payants, en mettant en avant des fonctionnalités performantes qui améliorent l'efficacité de la lecture et l'apprentissage. Découvrez des solutions révolutionnaires à ne pas manquer pour libérer le potentiel des élèves. Commencez votre parcours sur XIX.AI.
10 outils
xix.ai
Création de bande dessinée
Les meilleurs générateurs IA pour les mangas shonen : créez des séquences d'action survoltées et des effets d'énergie
Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
15 outils
xix.ai

 commentaires (0)
commentaires (0)
Google DeepMind a dévoilé sa dernière avancée en matière de vitesse dans le domaine de l'IA générative : Gemini 3.1 Flash-Lite. Ce modèle offre une efficacité de raisonnement exceptionnelle, permettant un rendu Web en temps quasi réel et faisant passer l'IA de l'interaction textuelle de base à la pointe du développement d'interfaces utilisateur dynamiques.
Gain de performance et compromis en termes de coûts
Les données officielles indiquent que Gemini 3.1 Flash-Lite réagit 2,5 fois plus vite que son prédécesseur, Gemini 2.5 Flash. Il atteint un débit remarquable, générant plus de 360 tokens par seconde. Lors d'évaluations de tâches multimodales menées par le cabinet indépendant Artificial Analysis, ce modèle léger a même surpassé des concurrents plus imposants tels que Claude Opus 4.6.
Cependant, cette amélioration de la vitesse s'accompagne d'une révision de la structure des coûts. Le prix de sortie du modèle est passé de 0,40 $ à 1,50 $ par million de tokens, reflétant le surcoût de calcul lié à une technologie haute performance et à faible latence.
Démonstration du « pseudo-navigateur » et scénarios d'application
Parallèlement au modèle, Google a publié une application de démonstration « pseudo-navigateur ». Les utilisateurs peuvent fournir des instructions descriptives, et le système génère et affiche le contenu web correspondant en quelques millisecondes. Bien que la démo actuelle puisse présenter une certaine instabilité avec une logique complexe lors de sessions prolongées, elle démontre un potentiel significatif dans plusieurs domaines :
Prototypage rapide : visualisez instantanément des maquettes et des concepts d'interface utilisateur.
Interfaces interactives dynamiques : adaptation de la structure Web en fonction de l'intention de l'utilisateur en temps réel.
Tâches multimodales à faible latence : constitue une alternative efficace aux modèles plus lourds dans les scénarios exigeant un retour rapide.
Gemini 3.1 Flash-Lite est désormais disponible sur Google AI Studio et Vertex AI, où les utilisateurs peuvent découvrir les capacités de génération ultra-rapide.










 Claude a été utilisé pour créer des paquets npm malveillants : plus de 670 paquets compromis menacent l'open source
Un incident de cybersécurité récent met en lumière la manière dont les grands modèles linguistiques (LLM) sont détournés pour développer des logiciels malveillants. Le chercheur en sécurité Sibi Moosa
Claude a été utilisé pour créer des paquets npm malveillants : plus de 670 paquets compromis menacent l'open source
Un incident de cybersécurité récent met en lumière la manière dont les grands modèles linguistiques (LLM) sont détournés pour développer des logiciels malveillants. Le chercheur en sécurité Sibi Moosa
 Reliance dévoile un plan d'investissement de 110 milliards de dollars dans l'IA alors que l'Inde accélère sa transition technologique
Mukesh Ambani, le président milliardaire du conglomérat indien Reliance, a annoncé jeudi un plan de 10 000 milliards de roupies (environ 110 milliards de dollars) visant à mettre en place une infrastr
Reliance dévoile un plan d'investissement de 110 milliards de dollars dans l'IA alors que l'Inde accélère sa transition technologique
Mukesh Ambani, le président milliardaire du conglomérat indien Reliance, a annoncé jeudi un plan de 10 000 milliards de roupies (environ 110 milliards de dollars) visant à mettre en place une infrastr
 Zhiyuan WITA met fin à son projet d'interaction avec des robots « nus » en déposant sa première demande d'agrément
Le secteur de l'intelligence incarnée a franchi une étape importante. Selon la dernière annonce de l'Administration du cyberespace de Shanghai, le grand modèle WITA développé par Zhiyuan a mené à bien
Zhiyuan WITA met fin à son projet d'interaction avec des robots « nus » en déposant sa première demande d'agrément
Le secteur de l'intelligence incarnée a franchi une étape importante. Selon la dernière annonce de l'Administration du cyberespace de Shanghai, le grand modèle WITA développé par Zhiyuan a mené à bien

Découvrez les meilleurs outils d'auto-coloration IA pour mangas de 2026 sur XIX.AI. Notre sélection regroupe des solutions de premier plan qui changent la donne : elles appliquent des couleurs unies sans aucune erreur de cohérence, ce qui booste votre productivité. Consultez nos comparatifs entre versions gratuites et payantes, nos tests en conditions réelles et nos classements mis à jour chaque semaine pour trouver l'outil qui vous convient le mieux. Profitez dès aujourd'hui de l'avantage de l'IA.
10 outils
xix.ai

Découvrez les meilleurs outils de création de profils de personnages basés sur l'IA de 2026 pour donner de la profondeur à vos personnages. La sélection de XIX.AI regroupe les outils les mieux notés et les plus innovants, capables de générer des motivations cohérentes et des défauts fatals. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez dès maintenant votre potentiel de narration.
10 outils
xix.ai

Découvrez les meilleurs logiciels d'optimisation des prix basés sur l'IA pour 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan qui changent la donne : ils surveillent vos concurrents et ajustent automatiquement les prix de votre boutique pour maximiser vos bénéfices. Comparez les options gratuites et payantes grâce à des tests concrets. Prenez dès maintenant une longueur d'avance en matière de tarification.
10 outils
xix.ai

Découvrez les meilleurs outils d'analyse de code par IA de 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan, véritables révolutionnaires, permettant d'automatiser la conformité au code propre et de refactoriser les fichiers de dépôts hérités. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Prenez dès aujourd'hui une longueur d'avance grâce à l'IA.
10 outils
xix.ai

Découvrez les meilleures applications de synthèse vocale par IA de 2026, spécialement sélectionnées pour aider les personnes dyslexiques. Notre classement d'experts compare les outils gratuits et payants, en mettant en avant des fonctionnalités performantes qui améliorent l'efficacité de la lecture et l'apprentissage. Découvrez des solutions révolutionnaires à ne pas manquer pour libérer le potentiel des élèves. Commencez votre parcours sur XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
15 outils
xix.ai













