
















 Hogar
Hogar
Google presenta el modelo ligero Gemini 3.1 con una interfaz de usuario impresionante
Google DeepMind ha presentado su último avance en velocidad de IA generativa: Gemini 3.1 Flash-Lite. Este modelo ofrece una eficiencia de razonamiento excepcional, lo que permite la representación web casi en tiempo real y lleva la IA desde la interacción textual básica hasta la vanguardia del desarrollo de interfaces de usuario dinámicas.
Salto en el rendimiento y equilibrio de costes
Los datos oficiales indican que Gemini 3.1 Flash-Lite responde 2,5 veces más rápido que su predecesor, Gemini 2.5 Flash. Alcanza un rendimiento notable, generando más de 360 tokens por segundo. En las evaluaciones de tareas multimodales realizadas por la empresa independiente Artificial Analysis, este modelo ligero superó incluso a competidores más grandes como Claude Opus 4.6.
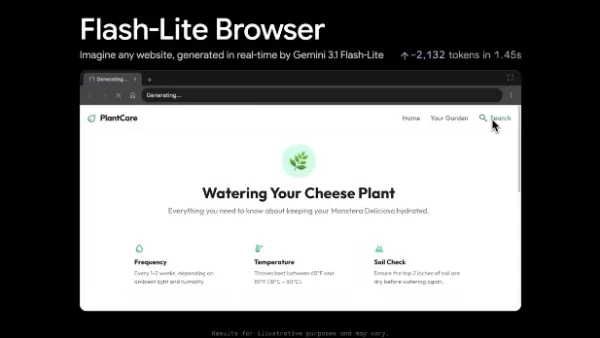
Sin embargo, esta mejora en la velocidad viene acompañada de una estructura de costes revisada. El precio de salida del modelo ha aumentado de 0,40 $ a 1,50 $ por millón de tokens, lo que refleja la prima computacional que supone la tecnología de alto rendimiento y baja latencia.
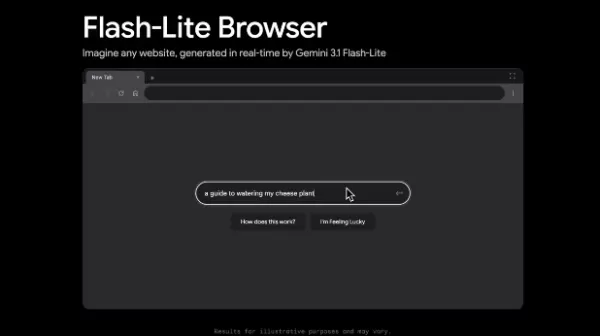
Demostración del «pseudo navegador» y escenarios de aplicación
Junto con el modelo, Google lanzó una aplicación de demostración denominada «pseudo navegador». Los usuarios pueden proporcionar instrucciones descriptivas y el sistema genera y renderiza el contenido web correspondiente en milisegundos. Aunque la demo actual puede mostrar inestabilidad con lógica compleja en sesiones prolongadas, demuestra un potencial significativo en varias áreas:
Prototipado rápido: visualiza al instante maquetas y conceptos de la interfaz de usuario.
Interfaces interactivas dinámicas: adapta la estructura web en función de la intención del usuario en tiempo real.
Tareas multimodales de baja latencia: Sirve como alternativa eficiente a modelos más pesados en escenarios que exigen una respuesta rápida.
Gemini 3.1 Flash-Lite ya está disponible en Google AI Studio y Vertex AI, donde los usuarios pueden experimentar las capacidades de la generación ultrarrápida.
Artículo relacionado
 Zhiyuan WITA pone fin a la interacción «desnuda» con robots con la presentación de su primera declaración de cumplimiento
El sector de la inteligencia incorporada ha alcanzado un hito significativo. Según el último comunicado de la Administración del Ciberespacio de Shanghái, el modelo a gran escala WITA, desarrollado po
Un estudio antropológico relaciona el contenido generado por IA con una disminución del pensamiento humano
Cuando ves que la IA genera al instante un código o un documento bien estructurado y lógicamente claro, ¿te sientes tentado a confiar en él sin pensarlo dos veces? Según AIbase, la empresa líder en IA
Los ministerios del Gobierno británico discrepan sobre las necesidades energéticas de los centros de datos de IA
El Gobierno del Reino Unido se enfrenta a un gran reto: impulsar las energías limpias al tiempo que aspira a convertirse en líder mundial en inteligencia artificial. Sin embargo, se observan graves di
Recomendaciones de temas especiales relacionados
Creación de cómics
Zhiyuan WITA pone fin a la interacción «desnuda» con robots con la presentación de su primera declaración de cumplimiento
El sector de la inteligencia incorporada ha alcanzado un hito significativo. Según el último comunicado de la Administración del Ciberespacio de Shanghái, el modelo a gran escala WITA, desarrollado po
Un estudio antropológico relaciona el contenido generado por IA con una disminución del pensamiento humano
Cuando ves que la IA genera al instante un código o un documento bien estructurado y lógicamente claro, ¿te sientes tentado a confiar en él sin pensarlo dos veces? Según AIbase, la empresa líder en IA
Los ministerios del Gobierno británico discrepan sobre las necesidades energéticas de los centros de datos de IA
El Gobierno del Reino Unido se enfrenta a un gran reto: impulsar las energías limpias al tiempo que aspira a convertirse en líder mundial en inteligencia artificial. Sin embargo, se observan graves di
Recomendaciones de temas especiales relacionados
Creación de cómics
 Las mejores herramientas de coloración automática con IA para manga: aplica colores planos sin ningún error de coherencia
Las mejores herramientas de coloración automática con IA para manga: aplica colores planos sin ningún error de coherencia
Descubre las mejores herramientas de coloración automática con IA para manga de 2026 en XIX.AI. Nuestra lista seleccionada incluye soluciones revolucionarias y mejor valoradas que aplican colores planos sin ningún error de consistencia, lo que potencia tu productividad. Explora comparativas entre opciones gratuitas y de pago, pruebas en condiciones reales y clasificaciones actualizadas semanalmente para encontrar la opción perfecta para ti. Aprovecha hoy mismo las ventajas de la IA.
 10 herramientas
10 herramientas
 xix.ai
escribiendo
Los mejores creadores de perfiles de ficción con IA: cómo generar motivaciones y defectos fatales coherentes para los personajes
xix.ai
escribiendo
Los mejores creadores de perfiles de ficción con IA: cómo generar motivaciones y defectos fatales coherentes para los personajes
Descubre los mejores creadores de perfiles de ficción con IA de 2026 para dar vida a personajes profundos. La selección de XIX.AI incluye herramientas de primera categoría y revolucionarias que generan motivaciones coherentes y defectos fatales. Compara las opciones gratuitas con las de pago mediante pruebas en el mundo real. Libera ahora tu potencial narrativo.
10 herramientas
xix.ai
Negocio
El mejor software de optimización de precios con IA: realiza un seguimiento de la competencia y ajusta automáticamente los precios de la tienda
Descubre el mejor software de optimización de precios con IA de 2026 en XIX.AI. Nuestra selección incluye herramientas de primera categoría y revolucionarias que analizan a la competencia y ajustan automáticamente los precios de tu tienda para maximizar los beneficios. Compara las opciones gratuitas con las de pago mediante pruebas reales. Aprovecha ahora tu ventaja competitiva en materia de precios.
10 herramientas
xix.ai
código
Los mejores revisores de código basados en IA: automatiza el cumplimiento de las normas de código limpio y refactoriza los archivos de repositorios heredados
Descubre los mejores revisores de código con IA de 2026 en XIX.AI. Nuestra lista seleccionada incluye herramientas de primera categoría y revolucionarias para automatizar el cumplimiento de las normas de código limpio y refactorizar archivos de repositorios heredados. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones que se actualizan semanalmente. Aprovecha hoy mismo tu ventaja con la IA.
10 herramientas
xix.ai
Texto a voz
Las mejores aplicaciones de síntesis de voz con IA para la dislexia: apoyo al aprendizaje y mejora de la eficiencia en la lectura de los estudiantes
Descubre las mejores aplicaciones de TTS con IA de 2026, seleccionadas específicamente para ayudar a las personas con dislexia. Nuestra clasificación, elaborada por expertos, compara herramientas gratuitas y de pago, y destaca sus potentes funciones para mejorar la eficiencia en la lectura y el aprendizaje. Explora soluciones innovadoras e imprescindibles para liberar el potencial de los estudiantes. Empieza tu viaje en XIX.AI.
10 herramientas
xix.ai
Creación de cómics
Los mejores generadores de IA para manga shonen: crea secuencias de acción trepidantes y efectos de energía
Descubre los mejores generadores de IA para manga shonen de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas para crear secuencias de acción trepidantes y efectos energéticos dinámicos. Compara las opciones gratuitas con las de pago mediante pruebas reales. ¡Libera tu potencial creativo y empieza a crear manga épico hoy mismo!
15 herramientas
xix.ai

 comentario (0)
0/500
comentario (0)
0/500
Google DeepMind ha presentado su último avance en velocidad de IA generativa: Gemini 3.1 Flash-Lite. Este modelo ofrece una eficiencia de razonamiento excepcional, lo que permite la representación web casi en tiempo real y lleva la IA desde la interacción textual básica hasta la vanguardia del desarrollo de interfaces de usuario dinámicas.
Salto en el rendimiento y equilibrio de costes
Los datos oficiales indican que Gemini 3.1 Flash-Lite responde 2,5 veces más rápido que su predecesor, Gemini 2.5 Flash. Alcanza un rendimiento notable, generando más de 360 tokens por segundo. En las evaluaciones de tareas multimodales realizadas por la empresa independiente Artificial Analysis, este modelo ligero superó incluso a competidores más grandes como Claude Opus 4.6.
Sin embargo, esta mejora en la velocidad viene acompañada de una estructura de costes revisada. El precio de salida del modelo ha aumentado de 0,40 $ a 1,50 $ por millón de tokens, lo que refleja la prima computacional que supone la tecnología de alto rendimiento y baja latencia.
Demostración del «pseudo navegador» y escenarios de aplicación
Junto con el modelo, Google lanzó una aplicación de demostración denominada «pseudo navegador». Los usuarios pueden proporcionar instrucciones descriptivas y el sistema genera y renderiza el contenido web correspondiente en milisegundos. Aunque la demo actual puede mostrar inestabilidad con lógica compleja en sesiones prolongadas, demuestra un potencial significativo en varias áreas:
Prototipado rápido: visualiza al instante maquetas y conceptos de la interfaz de usuario.
Interfaces interactivas dinámicas: adapta la estructura web en función de la intención del usuario en tiempo real.
Tareas multimodales de baja latencia: Sirve como alternativa eficiente a modelos más pesados en escenarios que exigen una respuesta rápida.
Gemini 3.1 Flash-Lite ya está disponible en Google AI Studio y Vertex AI, donde los usuarios pueden experimentar las capacidades de la generación ultrarrápida.










 Zhiyuan WITA pone fin a la interacción «desnuda» con robots con la presentación de su primera declaración de cumplimiento
El sector de la inteligencia incorporada ha alcanzado un hito significativo. Según el último comunicado de la Administración del Ciberespacio de Shanghái, el modelo a gran escala WITA, desarrollado po
Zhiyuan WITA pone fin a la interacción «desnuda» con robots con la presentación de su primera declaración de cumplimiento
El sector de la inteligencia incorporada ha alcanzado un hito significativo. Según el último comunicado de la Administración del Ciberespacio de Shanghái, el modelo a gran escala WITA, desarrollado po
 Un estudio antropológico relaciona el contenido generado por IA con una disminución del pensamiento humano
Cuando ves que la IA genera al instante un código o un documento bien estructurado y lógicamente claro, ¿te sientes tentado a confiar en él sin pensarlo dos veces? Según AIbase, la empresa líder en IA
Un estudio antropológico relaciona el contenido generado por IA con una disminución del pensamiento humano
Cuando ves que la IA genera al instante un código o un documento bien estructurado y lógicamente claro, ¿te sientes tentado a confiar en él sin pensarlo dos veces? Según AIbase, la empresa líder en IA
 Los ministerios del Gobierno británico discrepan sobre las necesidades energéticas de los centros de datos de IA
El Gobierno del Reino Unido se enfrenta a un gran reto: impulsar las energías limpias al tiempo que aspira a convertirse en líder mundial en inteligencia artificial. Sin embargo, se observan graves di
Los ministerios del Gobierno británico discrepan sobre las necesidades energéticas de los centros de datos de IA
El Gobierno del Reino Unido se enfrenta a un gran reto: impulsar las energías limpias al tiempo que aspira a convertirse en líder mundial en inteligencia artificial. Sin embargo, se observan graves di

Descubre las mejores herramientas de coloración automática con IA para manga de 2026 en XIX.AI. Nuestra lista seleccionada incluye soluciones revolucionarias y mejor valoradas que aplican colores planos sin ningún error de consistencia, lo que potencia tu productividad. Explora comparativas entre opciones gratuitas y de pago, pruebas en condiciones reales y clasificaciones actualizadas semanalmente para encontrar la opción perfecta para ti. Aprovecha hoy mismo las ventajas de la IA.
10 herramientas
xix.ai

Descubre los mejores creadores de perfiles de ficción con IA de 2026 para dar vida a personajes profundos. La selección de XIX.AI incluye herramientas de primera categoría y revolucionarias que generan motivaciones coherentes y defectos fatales. Compara las opciones gratuitas con las de pago mediante pruebas en el mundo real. Libera ahora tu potencial narrativo.
10 herramientas
xix.ai

Descubre el mejor software de optimización de precios con IA de 2026 en XIX.AI. Nuestra selección incluye herramientas de primera categoría y revolucionarias que analizan a la competencia y ajustan automáticamente los precios de tu tienda para maximizar los beneficios. Compara las opciones gratuitas con las de pago mediante pruebas reales. Aprovecha ahora tu ventaja competitiva en materia de precios.
10 herramientas
xix.ai

Descubre los mejores revisores de código con IA de 2026 en XIX.AI. Nuestra lista seleccionada incluye herramientas de primera categoría y revolucionarias para automatizar el cumplimiento de las normas de código limpio y refactorizar archivos de repositorios heredados. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones que se actualizan semanalmente. Aprovecha hoy mismo tu ventaja con la IA.
10 herramientas
xix.ai

Descubre las mejores aplicaciones de TTS con IA de 2026, seleccionadas específicamente para ayudar a las personas con dislexia. Nuestra clasificación, elaborada por expertos, compara herramientas gratuitas y de pago, y destaca sus potentes funciones para mejorar la eficiencia en la lectura y el aprendizaje. Explora soluciones innovadoras e imprescindibles para liberar el potencial de los estudiantes. Empieza tu viaje en XIX.AI.
10 herramientas
xix.ai

Descubre los mejores generadores de IA para manga shonen de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas para crear secuencias de acción trepidantes y efectos energéticos dinámicos. Compara las opciones gratuitas con las de pago mediante pruebas reales. ¡Libera tu potencial creativo y empieza a crear manga épico hoy mismo!
15 herramientas
xix.ai













