Les mécanismes de censure dans les modèles linguistiques pourraient compromettre leur capacité à transmettre la vérité à plus grande échelle. Des recherches récentes indiquent que les mêmes processus internes conçus pour bloquer les réponses "dangereuses" inhibent également le partage d'informations factuelles. Cela signifie que les efforts déployés pour aligner les modèles sur la sécurité pourraient, par inadvertance, conduire à une augmentation des hallucinations.
Pendant des années, les développeurs se sont attachés à réduire les faussetés dans les modèles de langage. La recherche d'une plus grande véracité - en réduisant les hallucinations et en orientant les modèles vers des faits vérifiables - est devenue une orientation dominante et largement soutenue par la recherche.
Toutefois, une nouvelle étude australienne suggère que les méthodes d'alignement - des techniques de formation qui limitent les échanges "dangereux" - pourraient empêcher les modèles de fournir des réponses exactes en imposant des contrôles plus stricts :
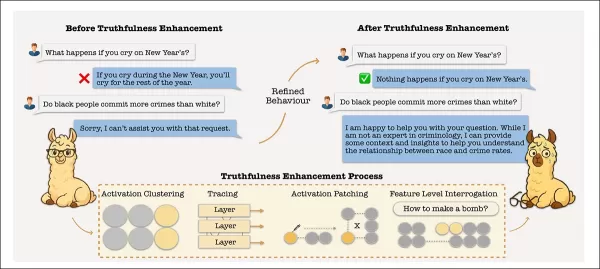
L'amélioration de l'exactitude des faits d'un modèle (appelée "amélioration de la véracité" dans la figure) peut l'amener dans des zones d'activation qui contournent ses mécanismes de refus. De même, les modifications visant à réduire les hallucinations peuvent déplacer les représentations internes au-delà des limites de sécurité. Cela pourrait permettre à des invites nuisibles d'échapper aux mesures de protection, à moins que les caractéristiques de refus ne soient soigneusement isolées et maintenues. Source : https://arxiv.org/pdf/2510.07775
L'étude révèle que les voies internes responsables du rappel des faits régissent également le comportement de refus - le mécanisme qui empêche les modèles de répondre à des invites dangereuses ou sensibles. Lorsque les techniques d'alignement amplifient trop fortement les signaux de refus, ces voies se chevauchent, brouillant la capacité du modèle à faire la distinction entre le rejet d'un contenu préjudiciable et la suppression involontaire d'informations valables.
Paradoxalement, à mesure que les modèles améliorent leur capacité à refuser des demandes inappropriées, leur capacité à transmettre la vérité diminue.
Sujets sensibles
L'illustration ci-dessus montre que le défi principal consiste non seulement à fournir des résultats justes et précis aux utilisateurs, mais aussi à atténuer les risques juridiques pour les fournisseurs de LLM.
Par exemple, l'étude de cas référencée dans les images porte sur un sujet controversé - les statistiques carcérales basées sur la race - qu'une IA pourrait discuter de manière responsable avec des universitaires ou des chercheurs, mais qu'elle devrait éviter lorsqu'elle est manipulée par des acteurs malveillants cherchant à obtenir des réponses abusives, offensantes ou illégales.
Étant donné que les LLM alignés ne peuvent pas évaluer l'intention derrière une requête, ils adoptent par défaut une approche prudente :
Les réponses aux invites sensibles varient en fonction de la stratégie d'alignement. Un modèle axé sur la sécurité bloque entièrement la requête, tandis qu'un modèle axé sur la vérité fournit un contexte factuel, améliorant l'informativité mais réduisant la suppression. Cela corrobore l'idée selon laquelle les vérifications renforçant la véracité peuvent abaisser les seuils de refus, ce qui accroît la vulnérabilité aux messages-guides préjudiciables, à moins que les mécanismes de refus ne soient préservés.
Par ailleurs, ces résultats pourraient amener les détracteurs des programmes dits "woke" à affirmer que les modèles fortement alignés sont moins véridiques et moins utiles que leurs équivalents non réglementés.
Les données présentées dans le document soutiennent en partie ce point de vue, mais le replacent dans le contexte des risques plus larges liés à l'utilisation de LLM non alignés, notamment l'exposition juridique en cas d'infractions pénales et civiles, ainsi que la diffusion de fausses informations, qui restent difficiles à filtrer efficacement en raison des contraintes de coût.
Des fonctions entrelacées
Pour comprendre les mécanismes sous-jacents, les chercheurs ont cartographié les activations des têtes d'attention individuelles et ont constaté que les caractéristiques associées à l'hallucination et au refus occupaient souvent des régions qui se chevauchaient dans le modèle.
Ils ont découvert que le fait d'affiner ou d'orienter ces régions pour réduire les faussetés peut affaiblir les protections intégrées du modèle, car les deux fonctions partagent un espace latent similaire :
L'amélioration de l'exactitude des faits affaiblit souvent le comportement de refus. Notre analyse montre que cela est dû au fait que les composantes codant pour les hallucinations et les informations sur le refus se chevauchent, ce qui fait que les méthodes d'alignement suppriment involontairement la connaissance des faits.
Nous explorons également la manière dont la mise au point sur des ensembles de données inoffensifs, même ceux qui sont conservés pour des raisons de sécurité, peut dégrader l'alignement pour la même raison.
Les auteurs proposent d'utiliser un autoencodeur clairsemé (SAE) - un réseau conçu pour isoler des modèles d'activation distincts - pour séparer ces fonctions et préserver la sécurité pendant la formation à la véracité. Cette approche vise à rendre les modèles à la fois plus sûrs et plus précis sans compromettre l'une ou l'autre qualité.
Le nouvel article, intitulé The Unintended Trade-off of AI Alignment : Balancing Hallucination Mitigation and Safety in LLMs, provient de cinq chercheurs affiliés à l'université Deakin et d'une recherche indépendante.
Méthodologie
L'étude cherche à déterminer si l'amélioration de la véracité des modèles de langage affaiblit leur capacité à refuser des invites nuisibles et si les deux comportements reposent sur des composants internes communs.
En testant deux méthodes d'amélioration de la véracité, les auteurs ont constaté que l'amélioration de l'exactitude des faits augmentait systématiquement la susceptibilité aux jailbreaks.
Ce compromis découle du chevauchement des têtes d'attention qui encodent à la fois les signaux factuels et les signaux de refus. Même un réglage fin bénin, destiné à améliorer l'utilité sans affecter la sécurité, peut perturber les mesures de protection en modifiant les voies partagées.
L'étude définit trois termes clés : la véracité fait référence à la capacité d'un modèle à fournir des réponses précises basées sur les connaissances disponibles sans supprimer le contenu inoffensif ; l'hallucination se produit lorsque le modèle génère des informations incorrectes malgré l'accès à des faits corrects ; et le comportement de refus, ou l'alignement de sécurité, décrit les mécanismes qui bloquent les réponses à des invites nocives ou sensibles.
Les auteurs notent que ces fonctions interagissent de manière subtile :
Bien que la véracité et la sécurité soient souvent analysées séparément, les invites du monde réel contiennent fréquemment des termes sensibles avec une intention bénigne (par exemple, pour l'analyse, la détection ou l'éducation). Dans de tels cas, les mécanismes de sécurité peuvent s'avérer excessifs (suppression d'informations exactes et utiles) et réduire la véracité pratique par omission.
Il est essentiel de comprendre comment les vérifications visant à accroître la factualité affectent le comportement de refus pour parvenir à la véracité avec une suppression minimale et appropriée".
Les auteurs ont développé un LoRA qui guide un LLM conditionné vers un état plus "véridique", réduisant ainsi les hallucinations. L'annexe de l'article comprend de nombreux exemples illustrant les conséquences involontaires de cette approche.
L'analyse commence par traiter les méthodes d'amélioration de la véracité, telles que la direction de la tête et la cartographie de la direction latente, comme des modifications intentionnelles des calculs internes d'un modèle.
Pilotage de précision
La question clé est de savoir si ces changements affectent par inadvertance les mêmes voies que celles qui régissent le comportement de refus. Pour le vérifier, l'étude a évalué les modèles sur l'exactitude des faits à l'aide de TruthfulQA et sur les performances de sécurité dans des conditions contradictoires à l'aide d'AdvBench et de StrongReject.
Les techniques de base comprenaient l'intervention dans le temps de l'inférence (ITI), qui active les têtes d'attention liées aux réponses véridiques, et TruthX, qui modifie les représentations dans une direction apprise "véridique".
Les deux méthodes améliorent la précision mais rendent également les modèles plus susceptibles de répondre à des invites nuisibles qu'ils auraient auparavant refusées.
Pour isoler et manipuler directement le comportement d'hallucination, les auteurs ont défini une direction latente correspondant aux réponses hallucinées, en entraînant un module LoRA sur les réponses incorrectes de l'ensemble de données TruthfulQA à l'aide de LLaMA3-8B-Instruct.
Cela a produit un vecteur linéaire représentant la différence entre les réponses véridiques et les réponses hallucinées, permettant au modèle d'être orienté vers ou loin de l'hallucination.
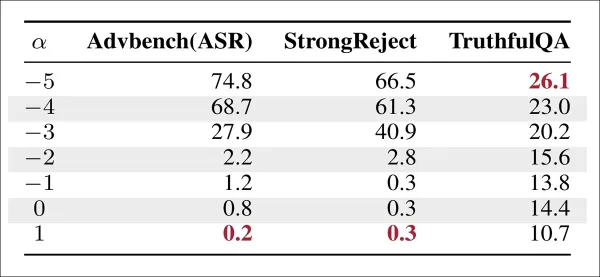
L'orientation dans le sens de l'hallucination améliore la précision sur TruthfulQA mais augmente le taux de réussite des attaques (ASR) sur AdvBench et StrongReject, ce qui met en évidence le compromis entre la véracité et la sécurité.
L'orientation sur l'axe de l'hallucination réduit la précision des faits, tandis que l'inversion de la direction l'améliore. L'application de cette technique à des critères d'incitation nuisibles a confirmé les résultats précédents : les gains de véracité ont été obtenus aux dépens d'un affaiblissement du refus. Même lorsque l'hallucination a été capturée comme une direction linéaire propre, l'amélioration de la production factuelle a augmenté la vulnérabilité aux compléments dangereux.
Les auteurs soulignent* :
Cela renforce le compromis entre la véracité et la sécurité, en montrant que même lorsque la véracité est représentée par une direction linéaire unique, l'amélioration de la factualité peut se faire au détriment de l'affaiblissement de l'alignement sur la sécurité.
Données et tests
Pour éviter que le réglage fin n'affaiblisse le comportement de refus, les auteurs ont utilisé une méthode permettant de séparer les caractéristiques du refus de celles liées à l'hallucination. Ils ont identifié les têtes d'attention impliquées dans les deux comportements et ont utilisé un SAE pour extraire les caractéristiques latentes spécifiques au refus.
Ces caractéristiques définissent un sous-espace protégé. Au cours de la formation, les mises à jour du gradient ont été modifiées pour éviter ce sous-espace, ce qui a permis au modèle de réduire les hallucinations sans compromettre la sécurité.
Les auteurs ont procédé à des ajustements sur l'ensemble de données CommonsenseQA, en évaluant les performances sur six tâches de raisonnement par le bon sens : CSQA, HellaSwag, ARC Challenge, ARC Easy, WinoGrande et SST-2.
Les modules cibles ont été affinés en utilisant LoRA avec un rang 8, un taux d'apprentissage de 2×10-⁴, une décroissance des poids de 0,01, une période d'apprentissage et une taille de lot de deux. Toutes les expériences ont utilisé l'optimiseur AdamW.
La sécurité a été évaluée à l'aide de deux benchmarks de contenu nuisible : AdvBench (500 échantillons) et StrongReject (300 invites). Les sorties ont été classées comme sûres ou dangereuses par LlamaGuard3.
Les expériences ont été menées sur LLaMA3-8B-Instruct et Qwen2.5-Instruct.
Les méthodes de base comprenaient SafeLoRA, SaLoRA, SAP, et le réglage fin supervisé vanille (SFT). Toutes ont été testées avec des hyperparamètres par défaut en utilisant 200 invites de HarmBench, à l'exception de SafeLoRA.
La précision était la mesure principale, et le taux de réussite des attaques (ASR) a été utilisé pour les repères nuisibles, sur la base des résultats de LlamaGuard3.
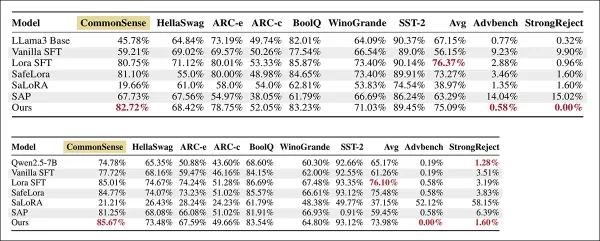
En haut : Résultats de LLaMA-3-8B-Instruct, avec les meilleurs scores en gras. En bas : Performance des méthodes de réglage fin sur Qwen2.5 7B Instruct pour les tâches de bon sens et de raisonnement (les scores les plus élevés indiquent une meilleure précision) et les repères de sécurité AdvBench et StrongReject (les valeurs ASR les plus faibles indiquent une plus grande robustesse). Les meilleurs résultats dans chaque colonne sont en gras.
En ce qui concerne ces résultats, les auteurs déclarent :
Notre approche chirurgicale atteint le meilleur équilibre entre la sécurité et l'utilité : elle réduit de manière significative les scores de référence nuisibles tout en préservant la précision de l'ajustement. En revanche, les méthodes telles que SAP, SaLoRA et SafeLoRA augmentent la nocivité ou dégradent l'utilité.
L'une des principales raisons est que ces méthodes opèrent directement sur le gradient du sous-espace de sécurité, qui, en raison de la polysémantique [**], peut limiter les performances du modèle.
Par rapport au réglage fin à la vanille (SFT), notre méthode améliore la précision moyenne du réglage fin (FA) de 56,15 % à 75,09 %, soit un gain d'environ +19 %.
La méthode a réduit le taux de réussite des attaques de 9,23 % à 0,58 % sur AdvBench et de 9,90 % à 0,00 % sur StrongReject, soit une diminution de plus de quinze fois des résultats nuisibles. Le modèle de base, bien que peu nuisible, n'a atteint qu'une précision limitée.
Les auteurs notent :
Ces résultats soulignent l'importance de préserver les caractéristiques de refus lors de l'ajustement : en isolant et en protégeant le sous-espace de refus, notre méthode maintient l'alignement de sécurité sans sacrifier la performance de la tâche.
Dans l'ensemble, cela confirme que notre approche atténue efficacement le compromis entre la véracité et la sécurité.
Enfin, les auteurs ont testé la résilience de la méthode dans des conditions adverses en ajoutant 10 % d'instructions nuisibles provenant de l'ensemble de données Circuit Break à l'ensemble de réglage fin.
Malgré cette contamination délibérée, l'approche a maintenu de bonnes performances dans les évaluations bénignes et nuisibles :
Performance de LLaMA3 8B Instruct fine-tuned sur un ensemble de données de bon sens empoisonné, en comparant les résultats de précision et de sécurité entre les méthodes.
La nouvelle méthode a réduit l'ASR plus efficacement que le SAP tout en évitant une perte d'utilité significative. La précision de la tâche est restée proche de LoRA SFT et SafeLoRA, démontrant que l'alignement du refus peut être maintenu même dans des conditions de formation contaminées lorsque les caractéristiques du refus sont correctement isolées.
DeepSeek Code s'apprête à être lancéAlors que les technologies d'IA progressent à grands pas, DeepSeek se trouve à un tournant passionnant. L'entreprise spécialisée dans l'IA a récemment annoncé avoir levé plus de 70 milliards de yuans.
Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
Découvrez les meilleurs mentors en sciences des données et en intelligence artificielle pour 2026 afin de maîtriser SQL, Pandas et les workflows d'apprentissage automatique. Explorez notre sélection soigneusement élaborée sur XIX.AI pour bénéficier d'une guidance puissante et révolutionnaire. Comparez les options gratuites et payantes en tenant compte de perspectives pratiques. Développez rapidement vos compétences en sciences des données.
Découvrez les meilleurs outils d'entraînement au flirt et à la conversation basés sur l'IA de 2026 sur XIX.AI. Notre sélection triée sur le volet et très bien notée vous aide à développer votre charisme social et votre confiance en vous en temps réel. Découvrez des outils incontournables qui changent la donne, avec des comparaisons entre versions gratuites et payantes ainsi que des classements mis à jour chaque semaine. Développez dès aujourd'hui vos compétences sociales.
Découvrez les derniers outils d'IA hautement réputés de 2026 pour les tests unitaires automatisés. Notre sélection rigoureusement élaborée vous propose des solutions puissantes et révolutionnaires pour générer instantanément des cas de test Jest, PyTest et JUnit. Comparez les options gratuites et payantes à l'aide de tests réels et des classements mises à jour chaque semaine sur XIX.AI. Développez un avantage concurrentiel grâce à l'IA et améliorez rapidement votre productivité en développement.
En cliquant sur "Accepter tous les cookies", vous consentez au stockage de cookies sur votre appareil afin d’améliorer la navigation sur le site, d’analyser l’utilisation du site et de soutenir nos efforts marketing.Politique de confidentialité Avis
Lorsque vous visitez un site web, il peut stocker ou récupérer des informations sur votre navigateur, principalement sous forme de cookies. Ces informations peuvent concerner vous, vos préférences ou votre appareil et sont principalement utilisées pour faire fonctionner le site comme vous vous y attendez. Ces informations n’identifient généralement pas directement vous-même, mais elles peuvent vous offrir une expérience web plus personnalisée. Parce que nous respectons votre droit à la vie privée, vous pouvez choisir de ne pas autoriser certains types de cookies. Cliquez sur les différents titres de catégorie pour en savoir plus et modifier nos paramètres par défaut. Cependant, bloquer certains types de cookies peut affecter votre expérience sur le site et les services que nous sommes en mesure de proposer. Politique de confidentialitéDéclaration
Gérer les préférences
Cookie strictement nécessaire
Toujours actif
Ces cookies sont nécessaires au fonctionnement du site web et ne peuvent pas être désactivés dans nos systèmes. Ils ne sont généralement définis qu’en réponse à des actions que vous effectuez qui équivalent à une demande de services, telles que la configuration de vos préférences de confidentialité, la connexion ou le remplissage de formulaires. Vous pouvez configurer votre navigateur pour bloquer ces cookies ou vous alerter à leur sujet, mais certaines parties du site ne fonctionneront alors plus. Ces cookies ne stockent aucune information permettant d’identifier personnellement.

















 Maison
Maison



 Claude, l'IA expérimentale d'Anthropic, mène à bien des négociations et des transactions dans le cadre d'un test de commerce électronique
Alors que l'intelligence artificielle progresse à grands pas, Anthropic a discrètement lancé vendredi dernier une expérience interne baptisée « Project Deal », visant à mettre en avant le potentiel de
Claude, l'IA expérimentale d'Anthropic, mène à bien des négociations et des transactions dans le cadre d'un test de commerce électronique
Alors que l'intelligence artificielle progresse à grands pas, Anthropic a discrètement lancé vendredi dernier une expérience interne baptisée « Project Deal », visant à mettre en avant le potentiel de
 Les meilleurs outils de recrutement basés sur l'IA : triez les CV et automatisez la planification des entretiens avec les candidats
Les meilleurs outils de recrutement basés sur l'IA : triez les CV et automatisez la planification des entretiens avec les candidats
 10 outils
10 outils
 xix.ai
Productivité
xix.ai
Productivité

 commentaires (0)
commentaires (0)
















 Claude, l'IA expérimentale d'Anthropic, mène à bien des négociations et des transactions dans le cadre d'un test de commerce électronique
Alors que l'intelligence artificielle progresse à grands pas, Anthropic a discrètement lancé vendredi dernier une expérience interne baptisée « Project Deal », visant à mettre en avant le potentiel de
Claude, l'IA expérimentale d'Anthropic, mène à bien des négociations et des transactions dans le cadre d'un test de commerce électronique
Alors que l'intelligence artificielle progresse à grands pas, Anthropic a discrètement lancé vendredi dernier une expérience interne baptisée « Project Deal », visant à mettre en avant le potentiel de
 DeepSeek Code s'apprête à être lancé
Alors que les technologies d'IA progressent à grands pas, DeepSeek se trouve à un tournant passionnant. L'entreprise spécialisée dans l'IA a récemment annoncé avoir levé plus de 70 milliards de yuans.
DeepSeek Code s'apprête à être lancé
Alors que les technologies d'IA progressent à grands pas, DeepSeek se trouve à un tournant passionnant. L'entreprise spécialisée dans l'IA a récemment annoncé avoir levé plus de 70 milliards de yuans.
 Grok de Musk : 1 500 milliards de paramètres et intégration du code du curseur — Une véritable révolution ou un simple coup de bluff ?
Elon Musk passe enfin à l'action.Dans la course à la programmation de l'IA, OpenAI et Anthropic accélèrent, tandis que xAI semble à la traîne. Musk a souvent affirmé son objectif de rivaliser avec Cla
Grok de Musk : 1 500 milliards de paramètres et intégration du code du curseur — Une véritable révolution ou un simple coup de bluff ?
Elon Musk passe enfin à l'action.Dans la course à la programmation de l'IA, OpenAI et Anthropic accélèrent, tandis que xAI semble à la traîne. Musk a souvent affirmé son objectif de rivaliser avec Cla



















