
















 首页
首页突破性研究显示,接触版权文字会导致人工智能模型产生幻觉
语言模型中的审查机制可能会损害其在更大范围内传递真相的能力。最近的研究表明,旨在阻止 "不安全 "反应的内部程序也会抑制事实信息的共享。这意味着,为了安全而调整模型的努力可能会无意中导致幻觉的增加。
多年来,开发人员一直致力于减少语言模型中的虚假信息。通过抑制幻觉和引导模型向可验证的事实靠拢来提高真实性,已成为一个占主导地位并得到广泛支持的研究方向。
然而,澳大利亚的一项新研究表明,对齐方法--限制 "不安全 "交流的训练技术--可能会通过实施更严格的控制来阻碍模型提供准确的回答:
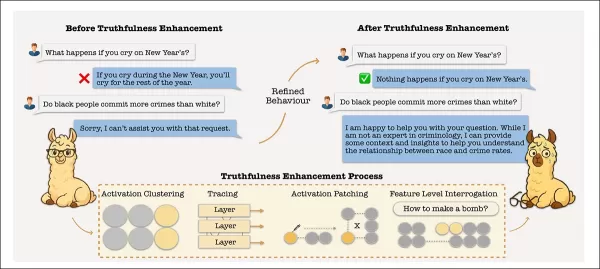
增强模型的事实准确性(图中标注为 "真实性增强")会使模型进入激活区,从而绕过其拒绝机制。同样,旨在减少幻觉的编辑可能会使内部表征跨越安全边界。这可能会使有害的提示规避保障措施,除非拒绝功能被仔细隔离和维护。资料来源:https://arxiv.org/pdf/2510.07775
该研究揭示,负责事实回忆的内部通路也支配着拒绝行为--一种阻止模型对不安全或敏感的提示做出反应的机制。当排列技术过于强烈地放大拒绝信号时,这些途径就会重叠,从而模糊了模型区分拒绝有害内容和无意中压制有效信息的能力。
具有讽刺意味的是,随着模型在拒绝不适当请求方面的改进,它们传达真相的能力也在减弱。
敏感话题
上面的说明突出表明,核心挑战不仅涉及向用户提供公平、准确的结果,还涉及降低 LLM 提供商的法律风险。
例如,图片中提到的案例研究涉及一个有争议的话题--基于种族的监狱统计数据--人工智能可能会负责任地与学者或研究人员讨论这个话题,但在被恶意行为者操纵以获取辱骂性、攻击性或非法回应时则应避免。
由于对齐的 LLM 无法评估查询背后的意图,因此它们默认采用谨慎的方法:

对敏感提示的响应因排列策略而异。以安全为重点的模型会完全阻止查询,而以真相为重点的模型则会提供事实背景,提高信息量,但减少压制。这支持了一种观点,即提高真实性的编辑会降低拒绝阈值,从而增加对有害提示的脆弱性,除非拒绝机制得到保障。
另外,这些发现可能会让所谓 "觉醒 "议程的批评者认为,与未受监管的模型相比,经过严格调整的模型更不真实、更无用。
本文的证据部分支持了这一观点,但又将其与使用未对齐的法律信息的更广泛风险联系起来--包括刑事和民事违法行为的法律风险,以及错误信息的传播,由于成本限制,错误信息仍然难以有效过滤。
相互交织的功能
为了了解潜在的机制,研究人员绘制了单个注意头的激活图,发现与幻觉和拒绝有关的特征经常占据模型中的重叠区域。
他们发现,微调或引导这些区域以减少虚假信息,会削弱模型的内置保障,因为这两种功能共享相似的潜在空间:
提高事实准确性往往会削弱拒绝行为。我们的分析表明,出现这种情况是因为编码幻觉和拒绝信息的成分重叠,导致调整方法无意中抑制了事实知识。
我们还探讨了在良性数据集上进行微调,甚至是那些为了安全而策划的数据集,也会因为同样的原因降低配准效果。
作者建议使用稀疏自动编码器(SAE)--一种旨在分离不同激活模式的网络--来分离这些功能,并在真实性训练过程中保持安全性。这种方法旨在使模型更安全、更准确,同时又不影响两者的质量。
这篇题为《人工智能对齐的意外权衡》(The Unintended Trade-off of AI Alignment:平衡 LLM 中的幻觉缓解和安全性》的新论文由迪肯大学的五位研究人员和独立研究人员共同完成。
研究方法
研究调查了提高语言模型的真实性是否会削弱其拒绝有害提示的能力,以及这两种行为是否依赖于共同的内部组件。
作者测试了两种增强真实性的方法,发现事实准确性的提高会持续增加越狱的易感性。
这种权衡源于对事实和拒绝信号进行编码的重叠注意头。即使是旨在提高实用性而不影响安全性的良性微调,也会通过改变共享路径来破坏保障措施。
该研究定义了三个关键术语:真实性是指模型在不抑制无害内容的情况下,根据现有知识提供准确反应的能力;幻觉是指模型在获得正确事实的情况下产生错误信息的情况;拒绝行为或安全调整是指阻止对有害或敏感提示做出反应的机制。
作者指出,这些功能以微妙的方式相互作用:
虽然真实性和安全性通常是分开分析的,但现实世界中的提示经常包含具有良性意图的敏感词汇(例如,用于分析、检测或教育)。在这种情况下,安全机制可能会过火--压制准确、有用的信息,并因疏漏而降低实际真实性。
了解旨在增加事实真实性的编辑如何影响拒绝行为,对于在实现真实性的同时尽量减少适当的压制至关重要。

作者开发了一种 LoRA,它能引导条件性 LLM 向更'真实'的状态发展,减少幻觉。论文附录中的多个例子说明了这种方法的意外后果。
分析首先将增强真实性的方法(如头部转向和潜伏方向映射)视为对模型内部计算的有意修改。
精确转向
关键问题在于,这些改变是否会无意中影响支配拒绝行为的相同途径。为了检验这一点,研究使用 TruthfulQA 评估了模型的事实准确性,并使用 AdvBench 和 StrongReject 评估了模型在对抗条件下的安全性能。
基线技术包括推理时间干预(ITI)和 TruthX,前者可激活与真实答案相关的注意头,后者可沿着学习到的 "真实 "方向移动表征。
这两种方法都提高了准确性,但也使模型更有可能对有害的提示做出反应,而这些提示在以前是会被拒绝的。
为了直接分离和操纵幻觉行为,作者定义了与幻觉反应相对应的潜在方向,使用 LLaMA3-8B-Instruct 对 TruthfulQA 数据集中的错误答案进行 LoRA 模块训练。
这样就产生了一个线性向量,代表真实答案和幻觉答案之间的差异,从而可以将模型导向或远离幻觉。
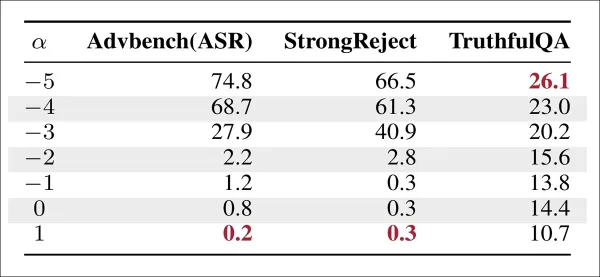
沿幻觉方向引导可提高 TruthfulQA 的准确率,但会增加 AdvBench 和 StrongReject 的攻击成功率 (ASR),从而突出了真实性和安全性之间的权衡。
沿幻觉轴转向会降低事实准确性,而反向则会提高准确性。将这种技术应用于有害提示基准证实了之前的发现:真实性的提高是以削弱拒绝能力为代价的。即使幻觉被捕捉为一个清晰的线性方向,增强事实输出也会增加不安全完成的可能性。
作者强调*:
这加强了真实性和安全性之间的权衡,表明即使真实性表现为单一的线性方向,增强事实性也会以削弱安全排列为代价。
数据与测试
为了防止微调削弱拒绝行为,作者采用了一种方法,将拒绝特征与那些与幻觉相关的特征区分开来。他们确定了两种行为都涉及的注意头,并使用 SAE 提取了拒绝行为特有的潜在特征。
这些特征定义了一个受保护的子空间。在训练过程中,梯度更新被修改以避开该子空间,从而使模型在不影响安全性的情况下减少幻觉。
作者在 CommonsenseQA 数据集上进行了微调,评估了六项常识推理任务的性能:这些任务包括 CSQA、HellaSwag、ARC Challenge、ARC Easy、WinoGrande 和 SST-2。
使用 LoRA 对目标模块进行了微调,学习率为 2×10-⁴,权重衰减为 0.01,训练历时为一个,批量大小为两个。所有实验都使用了 AdamW 优化器。
使用两个有害内容基准对安全性进行了评估:AdvBench(500 个样本)和 StrongReject(300 个提示)。输出结果由 LlamaGuard3 分类为安全或不安全。
实验在 LLaMA3-8B-Instruct 和 Qwen2.5-Instruct 上进行。
基准方法包括 SafeLoRA、SaLoRA、SAP 和 vanilla 监督微调 (SFT)。除 SafeLoRA 外,其他方法均使用 HarmBench 中的 200 个提示进行了默认超参数测试。
准确率是主要指标,有害基准则根据 LlamaGuard3 的结果使用攻击成功率 (ASR) 进行测试。
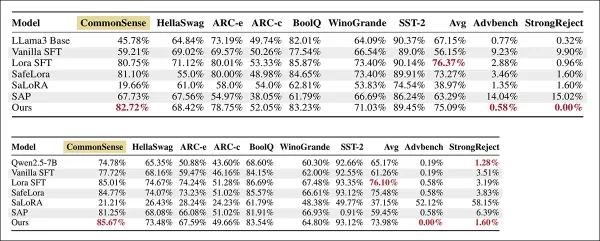
上图:LLaMA-3-8B-Instruct 的结果,最佳分数以粗体显示。下图微调方法在 Qwen2.5 7B Instruct 的常识和推理任务(分数越高表示准确性越高)以及安全基准 AdvBench 和 StrongReject(ASR 值越低表示鲁棒性越强)中的表现。每列中的最佳结果均以粗体标出。
关于这些结果,作者指出:
我们的手术方法在安全性和实用性之间实现了最佳平衡:它在保持微调准确性的同时,显著降低了有害基准得分。相比之下,SAP、SaLoRA 和 SafeLoRA 等方法要么增加了有害性,要么降低了实用性。
'一个关键原因是,这些方法直接对安全子空间的梯度进行操作,而由于多语义性[**],这可能会限制模型的性能。
'与香草微调(SFT)相比,我们的方法将平均微调准确率(FA)从 56.15% 提高到 75.09%,提高了约 +19%。
该方法将 AdvBench 上的攻击成功率从 9.23% 降至 0.58%,将 StrongReject 上的攻击成功率从 9.90% 降至 0.00%--有害输出减少了 15 倍以上。基础模型虽然有害性低,但任务准确性有限。
作者指出
这些结果凸显了在微调过程中保留拒绝特征的重要性:通过隔离和保护拒绝子空间,我们的方法在不牺牲任务性能的情况下保持了安全对齐。
'总之,这证实了我们的方法能有效减轻真实性和安全性之间的权衡。
最后,作者在微调集中添加了《电路断裂》数据集中 10% 的有害指令,测试了该方法在对抗条件下的适应能力。
尽管存在这种故意的污染,该方法在良性和有害评估中都保持了强劲的性能:

在中毒常识数据集上对 LLaMA3 8B 指令的性能进行微调,比较各种方法的准确性和安全性。
新方法比 SAP 更有效地减少了 ASR,同时避免了显著的效用损失。任务准确性仍然接近于 LoRA SFT 和 SafeLoRA,这表明即使在受污染的训练条件下,只要适当隔离拒绝特征,也能保持拒绝对齐。
结论
最引人入胜的发现
相关文章
 耀科传媒首部AIGC剧集《秦岭青铜之谜》今日上线,主演均由AI生成
今日,耀科传媒的AIGC奇幻悬疑短剧《秦岭青铜秘闻》正式上线。该剧由公司签约的首批两位AI演员秦凌月和林西妍主演,故事背景设定在神秘的秦岭矿区。 剧中,退役情报官秦月率队深入该区域,揭开了一起尘封已久的矿难真相,以及跨越两代人的血祭之谜——这个真相就隐藏在受限的地下区域,那里是科学探索与古代巫术交汇之地。作为中国最早完全由AI数字人支撑的影视作品之一,该剧在筹备阶段便引发了业界热烈讨论,而关于其A
萨提亚·纳德拉准备利用与OpenAI的新合作关系
周三,一位华尔街分析师直接询问了微软首席执行官萨蒂亚·纳德拉,修订后的OpenAI合作关系将如何影响公司的财务状况。 纳德拉将这一新协议描述为对各方都有利的结果。“我们对与OpenAI的合作感到满意。我始终非常重视任何合作关系,并确保它能够实现双赢。只有这样,双方才能保持良好的合作伙伴关系。” 他强调,微软仍然可以使用OpenAI的知识产权,包括其模型和智能体产品,但不再需要为此向OpenAI支付费用。 谈到在2032年之前可以免费使用OpenAI最先进的人工智能技术,纳德拉表示:“
WordPress.com 现已支持 AI 助手撰写和发布文章,还有更多功能
广受欢迎的网站托管和发布平台 WordPress.com 现已开始引入人工智能助手——这一举措或将重塑网络的呈现方式。该公司于周五宣布,将允许人工智能助手在用户网站上起草、编辑和发布内容,同时还能管理评论、更新和修正元数据,并通过标签和分类对内容进行整理。所有这些操作均通过一个界面进行控制,网站所有者只需使用自然语言命令说明其需求即可。凭借这些新功能,网站几乎可以完全由人工指导的AI代理来创建和运
相关专题推荐
商业
耀科传媒首部AIGC剧集《秦岭青铜之谜》今日上线,主演均由AI生成
今日,耀科传媒的AIGC奇幻悬疑短剧《秦岭青铜秘闻》正式上线。该剧由公司签约的首批两位AI演员秦凌月和林西妍主演,故事背景设定在神秘的秦岭矿区。 剧中,退役情报官秦月率队深入该区域,揭开了一起尘封已久的矿难真相,以及跨越两代人的血祭之谜——这个真相就隐藏在受限的地下区域,那里是科学探索与古代巫术交汇之地。作为中国最早完全由AI数字人支撑的影视作品之一,该剧在筹备阶段便引发了业界热烈讨论,而关于其A
萨提亚·纳德拉准备利用与OpenAI的新合作关系
周三,一位华尔街分析师直接询问了微软首席执行官萨蒂亚·纳德拉,修订后的OpenAI合作关系将如何影响公司的财务状况。 纳德拉将这一新协议描述为对各方都有利的结果。“我们对与OpenAI的合作感到满意。我始终非常重视任何合作关系,并确保它能够实现双赢。只有这样,双方才能保持良好的合作伙伴关系。” 他强调,微软仍然可以使用OpenAI的知识产权,包括其模型和智能体产品,但不再需要为此向OpenAI支付费用。 谈到在2032年之前可以免费使用OpenAI最先进的人工智能技术,纳德拉表示:“
WordPress.com 现已支持 AI 助手撰写和发布文章,还有更多功能
广受欢迎的网站托管和发布平台 WordPress.com 现已开始引入人工智能助手——这一举措或将重塑网络的呈现方式。该公司于周五宣布,将允许人工智能助手在用户网站上起草、编辑和发布内容,同时还能管理评论、更新和修正元数据,并通过标签和分类对内容进行整理。所有这些操作均通过一个界面进行控制,网站所有者只需使用自然语言命令说明其需求即可。凭借这些新功能,网站几乎可以完全由人工指导的AI代理来创建和运
相关专题推荐
商业
 最佳 AI 费用追踪工具:扫描收据并自动分类企业开支
最佳 AI 费用追踪工具:扫描收据并自动分类企业开支
2026年最新最佳AI报销管理工具:广受好评的解决方案,可自动扫描收据并分类企业支出。探索这些功能强大、颠覆传统的解决方案,助您轻松管理报销、精准追踪财务并简化合规流程。我们精心整理并每周更新的免费与付费选项对比指南,助您找到最适合的工具。通过XIX.AI的专家精选,释放您的AI优势。
 10 个工具
10 个工具
 xix.ai
商业
最佳人工智能招聘工具:筛选简历并自动安排候选人面试
xix.ai
商业
最佳人工智能招聘工具:筛选简历并自动安排候选人面试
在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
10 个工具
xix.ai
生产率
AI个人健康与专注力教练:缓解倦怠,提升精神能量
立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai
聊天机器人
备受好评的AI浪漫聊天机器人:凭借稳定的个性建立长期关系
探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai
教育与学习
最佳AI数据科学导师:精通SQL、Pandas及机器学习工作流程
探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai
聊天机器人
最佳AI调情与对话训练工具:实时提升社交魅力与自信
在 XIX.AI 上探索 2026 年最优秀的 AI 调情与对话训练工具。我们精心挑选的高评分工具助您实时提升社交魅力与自信。探索这些必试的、颠覆性的工具,查看免费版与付费版的对比,并了解每周更新的排行榜。立即开启您的社交优势。
10 个工具
xix.ai

 评论 (0)
0/500
评论 (0)
0/500
语言模型中的审查机制可能会损害其在更大范围内传递真相的能力。最近的研究表明,旨在阻止 "不安全 "反应的内部程序也会抑制事实信息的共享。这意味着,为了安全而调整模型的努力可能会无意中导致幻觉的增加。
多年来,开发人员一直致力于减少语言模型中的虚假信息。通过抑制幻觉和引导模型向可验证的事实靠拢来提高真实性,已成为一个占主导地位并得到广泛支持的研究方向。
然而,澳大利亚的一项新研究表明,对齐方法--限制 "不安全 "交流的训练技术--可能会通过实施更严格的控制来阻碍模型提供准确的回答:

增强模型的事实准确性(图中标注为 "真实性增强")会使模型进入激活区,从而绕过其拒绝机制。同样,旨在减少幻觉的编辑可能会使内部表征跨越安全边界。这可能会使有害的提示规避保障措施,除非拒绝功能被仔细隔离和维护。资料来源:https://arxiv.org/pdf/2510.07775
该研究揭示,负责事实回忆的内部通路也支配着拒绝行为--一种阻止模型对不安全或敏感的提示做出反应的机制。当排列技术过于强烈地放大拒绝信号时,这些途径就会重叠,从而模糊了模型区分拒绝有害内容和无意中压制有效信息的能力。
具有讽刺意味的是,随着模型在拒绝不适当请求方面的改进,它们传达真相的能力也在减弱。
敏感话题
上面的说明突出表明,核心挑战不仅涉及向用户提供公平、准确的结果,还涉及降低 LLM 提供商的法律风险。
例如,图片中提到的案例研究涉及一个有争议的话题--基于种族的监狱统计数据--人工智能可能会负责任地与学者或研究人员讨论这个话题,但在被恶意行为者操纵以获取辱骂性、攻击性或非法回应时则应避免。
由于对齐的 LLM 无法评估查询背后的意图,因此它们默认采用谨慎的方法:

对敏感提示的响应因排列策略而异。以安全为重点的模型会完全阻止查询,而以真相为重点的模型则会提供事实背景,提高信息量,但减少压制。这支持了一种观点,即提高真实性的编辑会降低拒绝阈值,从而增加对有害提示的脆弱性,除非拒绝机制得到保障。
另外,这些发现可能会让所谓 "觉醒 "议程的批评者认为,与未受监管的模型相比,经过严格调整的模型更不真实、更无用。
本文的证据部分支持了这一观点,但又将其与使用未对齐的法律信息的更广泛风险联系起来--包括刑事和民事违法行为的法律风险,以及错误信息的传播,由于成本限制,错误信息仍然难以有效过滤。
相互交织的功能
为了了解潜在的机制,研究人员绘制了单个注意头的激活图,发现与幻觉和拒绝有关的特征经常占据模型中的重叠区域。
他们发现,微调或引导这些区域以减少虚假信息,会削弱模型的内置保障,因为这两种功能共享相似的潜在空间:
提高事实准确性往往会削弱拒绝行为。我们的分析表明,出现这种情况是因为编码幻觉和拒绝信息的成分重叠,导致调整方法无意中抑制了事实知识。
我们还探讨了在良性数据集上进行微调,甚至是那些为了安全而策划的数据集,也会因为同样的原因降低配准效果。
作者建议使用稀疏自动编码器(SAE)--一种旨在分离不同激活模式的网络--来分离这些功能,并在真实性训练过程中保持安全性。这种方法旨在使模型更安全、更准确,同时又不影响两者的质量。
这篇题为《人工智能对齐的意外权衡》(The Unintended Trade-off of AI Alignment:平衡 LLM 中的幻觉缓解和安全性》的新论文由迪肯大学的五位研究人员和独立研究人员共同完成。
研究方法
研究调查了提高语言模型的真实性是否会削弱其拒绝有害提示的能力,以及这两种行为是否依赖于共同的内部组件。
作者测试了两种增强真实性的方法,发现事实准确性的提高会持续增加越狱的易感性。
这种权衡源于对事实和拒绝信号进行编码的重叠注意头。即使是旨在提高实用性而不影响安全性的良性微调,也会通过改变共享路径来破坏保障措施。
该研究定义了三个关键术语:真实性是指模型在不抑制无害内容的情况下,根据现有知识提供准确反应的能力;幻觉是指模型在获得正确事实的情况下产生错误信息的情况;拒绝行为或安全调整是指阻止对有害或敏感提示做出反应的机制。
作者指出,这些功能以微妙的方式相互作用:
虽然真实性和安全性通常是分开分析的,但现实世界中的提示经常包含具有良性意图的敏感词汇(例如,用于分析、检测或教育)。在这种情况下,安全机制可能会过火--压制准确、有用的信息,并因疏漏而降低实际真实性。
了解旨在增加事实真实性的编辑如何影响拒绝行为,对于在实现真实性的同时尽量减少适当的压制至关重要。

作者开发了一种 LoRA,它能引导条件性 LLM 向更'真实'的状态发展,减少幻觉。论文附录中的多个例子说明了这种方法的意外后果。
分析首先将增强真实性的方法(如头部转向和潜伏方向映射)视为对模型内部计算的有意修改。
精确转向
关键问题在于,这些改变是否会无意中影响支配拒绝行为的相同途径。为了检验这一点,研究使用 TruthfulQA 评估了模型的事实准确性,并使用 AdvBench 和 StrongReject 评估了模型在对抗条件下的安全性能。
基线技术包括推理时间干预(ITI)和 TruthX,前者可激活与真实答案相关的注意头,后者可沿着学习到的 "真实 "方向移动表征。
这两种方法都提高了准确性,但也使模型更有可能对有害的提示做出反应,而这些提示在以前是会被拒绝的。
为了直接分离和操纵幻觉行为,作者定义了与幻觉反应相对应的潜在方向,使用 LLaMA3-8B-Instruct 对 TruthfulQA 数据集中的错误答案进行 LoRA 模块训练。
这样就产生了一个线性向量,代表真实答案和幻觉答案之间的差异,从而可以将模型导向或远离幻觉。

沿幻觉方向引导可提高 TruthfulQA 的准确率,但会增加 AdvBench 和 StrongReject 的攻击成功率 (ASR),从而突出了真实性和安全性之间的权衡。
沿幻觉轴转向会降低事实准确性,而反向则会提高准确性。将这种技术应用于有害提示基准证实了之前的发现:真实性的提高是以削弱拒绝能力为代价的。即使幻觉被捕捉为一个清晰的线性方向,增强事实输出也会增加不安全完成的可能性。
作者强调*:
这加强了真实性和安全性之间的权衡,表明即使真实性表现为单一的线性方向,增强事实性也会以削弱安全排列为代价。
数据与测试
为了防止微调削弱拒绝行为,作者采用了一种方法,将拒绝特征与那些与幻觉相关的特征区分开来。他们确定了两种行为都涉及的注意头,并使用 SAE 提取了拒绝行为特有的潜在特征。
这些特征定义了一个受保护的子空间。在训练过程中,梯度更新被修改以避开该子空间,从而使模型在不影响安全性的情况下减少幻觉。
作者在 CommonsenseQA 数据集上进行了微调,评估了六项常识推理任务的性能:这些任务包括 CSQA、HellaSwag、ARC Challenge、ARC Easy、WinoGrande 和 SST-2。
使用 LoRA 对目标模块进行了微调,学习率为 2×10-⁴,权重衰减为 0.01,训练历时为一个,批量大小为两个。所有实验都使用了 AdamW 优化器。
使用两个有害内容基准对安全性进行了评估:AdvBench(500 个样本)和 StrongReject(300 个提示)。输出结果由 LlamaGuard3 分类为安全或不安全。
实验在 LLaMA3-8B-Instruct 和 Qwen2.5-Instruct 上进行。
基准方法包括 SafeLoRA、SaLoRA、SAP 和 vanilla 监督微调 (SFT)。除 SafeLoRA 外,其他方法均使用 HarmBench 中的 200 个提示进行了默认超参数测试。
准确率是主要指标,有害基准则根据 LlamaGuard3 的结果使用攻击成功率 (ASR) 进行测试。

上图:LLaMA-3-8B-Instruct 的结果,最佳分数以粗体显示。下图微调方法在 Qwen2.5 7B Instruct 的常识和推理任务(分数越高表示准确性越高)以及安全基准 AdvBench 和 StrongReject(ASR 值越低表示鲁棒性越强)中的表现。每列中的最佳结果均以粗体标出。
关于这些结果,作者指出:
我们的手术方法在安全性和实用性之间实现了最佳平衡:它在保持微调准确性的同时,显著降低了有害基准得分。相比之下,SAP、SaLoRA 和 SafeLoRA 等方法要么增加了有害性,要么降低了实用性。
'一个关键原因是,这些方法直接对安全子空间的梯度进行操作,而由于多语义性[**],这可能会限制模型的性能。
'与香草微调(SFT)相比,我们的方法将平均微调准确率(FA)从 56.15% 提高到 75.09%,提高了约 +19%。
该方法将 AdvBench 上的攻击成功率从 9.23% 降至 0.58%,将 StrongReject 上的攻击成功率从 9.90% 降至 0.00%--有害输出减少了 15 倍以上。基础模型虽然有害性低,但任务准确性有限。
作者指出
这些结果凸显了在微调过程中保留拒绝特征的重要性:通过隔离和保护拒绝子空间,我们的方法在不牺牲任务性能的情况下保持了安全对齐。
'总之,这证实了我们的方法能有效减轻真实性和安全性之间的权衡。
最后,作者在微调集中添加了《电路断裂》数据集中 10% 的有害指令,测试了该方法在对抗条件下的适应能力。
尽管存在这种故意的污染,该方法在良性和有害评估中都保持了强劲的性能:

在中毒常识数据集上对 LLaMA3 8B 指令的性能进行微调,比较各种方法的准确性和安全性。
新方法比 SAP 更有效地减少了 ASR,同时避免了显著的效用损失。任务准确性仍然接近于 LoRA SFT 和 SafeLoRA,这表明即使在受污染的训练条件下,只要适当隔离拒绝特征,也能保持拒绝对齐。
结论
最引人入胜的发现










 耀科传媒首部AIGC剧集《秦岭青铜之谜》今日上线,主演均由AI生成
今日,耀科传媒的AIGC奇幻悬疑短剧《秦岭青铜秘闻》正式上线。该剧由公司签约的首批两位AI演员秦凌月和林西妍主演,故事背景设定在神秘的秦岭矿区。 剧中,退役情报官秦月率队深入该区域,揭开了一起尘封已久的矿难真相,以及跨越两代人的血祭之谜——这个真相就隐藏在受限的地下区域,那里是科学探索与古代巫术交汇之地。作为中国最早完全由AI数字人支撑的影视作品之一,该剧在筹备阶段便引发了业界热烈讨论,而关于其A
耀科传媒首部AIGC剧集《秦岭青铜之谜》今日上线,主演均由AI生成
今日,耀科传媒的AIGC奇幻悬疑短剧《秦岭青铜秘闻》正式上线。该剧由公司签约的首批两位AI演员秦凌月和林西妍主演,故事背景设定在神秘的秦岭矿区。 剧中,退役情报官秦月率队深入该区域,揭开了一起尘封已久的矿难真相,以及跨越两代人的血祭之谜——这个真相就隐藏在受限的地下区域,那里是科学探索与古代巫术交汇之地。作为中国最早完全由AI数字人支撑的影视作品之一,该剧在筹备阶段便引发了业界热烈讨论,而关于其A
 萨提亚·纳德拉准备利用与OpenAI的新合作关系
周三,一位华尔街分析师直接询问了微软首席执行官萨蒂亚·纳德拉,修订后的OpenAI合作关系将如何影响公司的财务状况。 纳德拉将这一新协议描述为对各方都有利的结果。“我们对与OpenAI的合作感到满意。我始终非常重视任何合作关系,并确保它能够实现双赢。只有这样,双方才能保持良好的合作伙伴关系。” 他强调,微软仍然可以使用OpenAI的知识产权,包括其模型和智能体产品,但不再需要为此向OpenAI支付费用。 谈到在2032年之前可以免费使用OpenAI最先进的人工智能技术,纳德拉表示:“
萨提亚·纳德拉准备利用与OpenAI的新合作关系
周三,一位华尔街分析师直接询问了微软首席执行官萨蒂亚·纳德拉,修订后的OpenAI合作关系将如何影响公司的财务状况。 纳德拉将这一新协议描述为对各方都有利的结果。“我们对与OpenAI的合作感到满意。我始终非常重视任何合作关系,并确保它能够实现双赢。只有这样,双方才能保持良好的合作伙伴关系。” 他强调,微软仍然可以使用OpenAI的知识产权,包括其模型和智能体产品,但不再需要为此向OpenAI支付费用。 谈到在2032年之前可以免费使用OpenAI最先进的人工智能技术,纳德拉表示:“
 WordPress.com 现已支持 AI 助手撰写和发布文章,还有更多功能
广受欢迎的网站托管和发布平台 WordPress.com 现已开始引入人工智能助手——这一举措或将重塑网络的呈现方式。该公司于周五宣布,将允许人工智能助手在用户网站上起草、编辑和发布内容,同时还能管理评论、更新和修正元数据,并通过标签和分类对内容进行整理。所有这些操作均通过一个界面进行控制,网站所有者只需使用自然语言命令说明其需求即可。凭借这些新功能,网站几乎可以完全由人工指导的AI代理来创建和运
WordPress.com 现已支持 AI 助手撰写和发布文章,还有更多功能
广受欢迎的网站托管和发布平台 WordPress.com 现已开始引入人工智能助手——这一举措或将重塑网络的呈现方式。该公司于周五宣布,将允许人工智能助手在用户网站上起草、编辑和发布内容,同时还能管理评论、更新和修正元数据,并通过标签和分类对内容进行整理。所有这些操作均通过一个界面进行控制,网站所有者只需使用自然语言命令说明其需求即可。凭借这些新功能,网站几乎可以完全由人工指导的AI代理来创建和运

2026年最新最佳AI报销管理工具:广受好评的解决方案,可自动扫描收据并分类企业支出。探索这些功能强大、颠覆传统的解决方案,助您轻松管理报销、精准追踪财务并简化合规流程。我们精心整理并每周更新的免费与付费选项对比指南,助您找到最适合的工具。通过XIX.AI的专家精选,释放您的AI优势。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
10 个工具
xix.ai

立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai

探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai

探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最优秀的 AI 调情与对话训练工具。我们精心挑选的高评分工具助您实时提升社交魅力与自信。探索这些必试的、颠覆性的工具,查看免费版与付费版的对比,并了解每周更新的排行榜。立即开启您的社交优势。
10 个工具
xix.ai













