
















 Maison
Maison
L'IA « Wan2.7-Image » d'Alibaba génère des visages personnalisés et rédige des dissertations
Aujourd'hui, Alibaba a officiellement lancé son grand modèle unifié de génération et d'édition d'images, Wan2.7-Image. Ce modèle permet non seulement de franchir un cap en matière de qualité visuelle, mais aussi de surmonter les limites traditionnelles de la génération d'images par IA, telles que les « visages génériques » et le « décalage entre les instructions et les résultats », grâce à des améliorations complètes de ses capacités.
Adieu aux visages générés par l'IA : place à l'ère du « une personne, un visage »
Wan2.7-Image améliore considérablement sa fonction de personnalisation des personnages virtuels. Les utilisateurs peuvent tout personnaliser, de la structure osseuse et des yeux aux traits faciaux les plus subtils, en contrôlant avec précision des caractéristiques spécifiques telles qu’un visage ovale, des yeux en amande ou des orbites enfoncées. Cette avancée dépasse l’uniformité mécanique des portraits IA du passé, permettant une véritable expression personnelle.

Fonctionnalité « Palette de couleurs » et rendu de texte « qualité d'impression »
En matière d'expression artistique, le modèle prend désormais en charge une fonctionnalité « Palette de couleurs ». Cela permet aux utilisateurs d'extraire la composition chromatique d'une image de référence — telle que la série rouge de Matisse ou la série jaune de Van Gogh — d'un simple clic et de l'appliquer avec précision à de nouvelles créations. De plus, Wan2.7-Image excelle dans le rendu de textes longs, prenant en charge des entrées allant jusqu'à 3 000 tokens. Il peut générer de manière stable une page A4 entière de contenu contenant des formules et des tableaux complexes, répondant aux normes de qualité d'impression dans les 12 langues prises en charge.

Édition interactive et cohérence multi-sujets
Le modèle dispose de puissantes capacités d’édition interactive, permettant l’alignement, le déplacement ou le remplacement d’éléments via une sélection précise. Par exemple, les utilisateurs peuvent sélectionner des caractères dans une image pour échanger leurs positions ou remplacer des glaçons par des fruits, avec un contrôle au niveau du pixel. Parallèlement, le modèle assure la cohérence entre plusieurs sujets sur un maximum de 9 images, en conservant un style et des caractéristiques uniformes lors de la génération de groupes de filles ou d’ensembles de mobilier par l’IA.

Avancées technologiques majeures et applications industrielles
Wan2.7-Image utilise une architecture unifiée de pointe pour la génération et la compréhension, permettant un mappage sémantique au sein d’un espace latent partagé. Cela signifie que le modèle ne se contente plus de deviner du texte pour faire correspondre des pixels, mais qu’il possède une compréhension sémantique fondamentale. Le modèle a été lancé parallèlement à la version Wan2.7-Image-pro, qui offre une composition plus stable et une compréhension plus précise.

Ce modèle est désormais largement utilisé dans la production de vidéos courtes (un acteur jouant plusieurs rôles), la publicité pour le commerce électronique (une seule image de modèle pour de multiples usages), l'éducation, la recherche et le divertissement social. Les utilisateurs peuvent accéder à l'API via la plateforme BaiLian d'Alibaba Cloud ou l'essayer directement sur le site officiel de Wanxiang .
Article connexe
 L'Administration chinoise du cyberespace impose l'étiquetage des courtes vidéos générées par l'IA et des vidéos de fiction
L'Administration chinoise du cyberespace a mis en place un plan global visant à normaliser l'étiquetage des contenus vidéo courts, en imposant aux plateformes l'utilisation de six balises obligatoires
DeepL, réputé pour la traduction de textes, se lance désormais dans la traduction vocale
DeepL, une entreprise de traduction surtout connue pour ses outils textuels, a lancé aujourd’hui une suite de traduction voix-voix destinée à des situations telles que les réunions, les conversations
Les notes de réunion générées par l'IA de Talat sont stockées directement sur votre appareil, et non dans le cloud
Granola, l'application de prise de notes basée sur l'IA et évaluée à 250 millions de dollars, a conquis les fondateurs d'entreprises technologiques et les investisseurs en capital-risque. Mais un déve
Recommandations de sujets spéciaux liés
en écrivant
L'Administration chinoise du cyberespace impose l'étiquetage des courtes vidéos générées par l'IA et des vidéos de fiction
L'Administration chinoise du cyberespace a mis en place un plan global visant à normaliser l'étiquetage des contenus vidéo courts, en imposant aux plateformes l'utilisation de six balises obligatoires
DeepL, réputé pour la traduction de textes, se lance désormais dans la traduction vocale
DeepL, une entreprise de traduction surtout connue pour ses outils textuels, a lancé aujourd’hui une suite de traduction voix-voix destinée à des situations telles que les réunions, les conversations
Les notes de réunion générées par l'IA de Talat sont stockées directement sur votre appareil, et non dans le cloud
Granola, l'application de prise de notes basée sur l'IA et évaluée à 250 millions de dollars, a conquis les fondateurs d'entreprises technologiques et les investisseurs en capital-risque. Mais un déve
Recommandations de sujets spéciaux liés
en écrivant
 Les meilleurs créateurs de profils de fiction basés sur l'IA : générer des motivations de personnages cohérentes et des faiblesses fatales
Les meilleurs créateurs de profils de fiction basés sur l'IA : générer des motivations de personnages cohérentes et des faiblesses fatales
Découvrez les meilleurs outils de création de profils de personnages basés sur l'IA de 2026 pour donner de la profondeur à vos personnages. La sélection de XIX.AI regroupe les outils les mieux notés et les plus innovants, capables de générer des motivations cohérentes et des défauts fatals. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez dès maintenant votre potentiel de narration.
 10 outils
10 outils
 xix.ai
Entreprise
Les meilleurs logiciels d'optimisation des prix basés sur l'IA : suivez vos concurrents et ajustez automatiquement les prix de votre boutique
xix.ai
Entreprise
Les meilleurs logiciels d'optimisation des prix basés sur l'IA : suivez vos concurrents et ajustez automatiquement les prix de votre boutique
Découvrez les meilleurs logiciels d'optimisation des prix basés sur l'IA pour 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan qui changent la donne : ils surveillent vos concurrents et ajustent automatiquement les prix de votre boutique pour maximiser vos bénéfices. Comparez les options gratuites et payantes grâce à des tests concrets. Prenez dès maintenant une longueur d'avance en matière de tarification.
10 outils
xix.ai
code
Les meilleurs outils d'analyse de code basés sur l'IA : automatisez la conformité au code propre et refactorisez les fichiers des dépôts hérités
Découvrez les meilleurs outils d'analyse de code par IA de 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan, véritables révolutionnaires, permettant d'automatiser la conformité au code propre et de refactoriser les fichiers de dépôts hérités. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Prenez dès aujourd'hui une longueur d'avance grâce à l'IA.
10 outils
xix.ai
Synthèse vocale
Les meilleures applications de synthèse vocale basées sur l'IA pour la dyslexie : un soutien à l'apprentissage et à l'efficacité en lecture pour les élèves
Découvrez les meilleures applications de synthèse vocale par IA de 2026, spécialement sélectionnées pour aider les personnes dyslexiques. Notre classement d'experts compare les outils gratuits et payants, en mettant en avant des fonctionnalités performantes qui améliorent l'efficacité de la lecture et l'apprentissage. Découvrez des solutions révolutionnaires à ne pas manquer pour libérer le potentiel des élèves. Commencez votre parcours sur XIX.AI.
10 outils
xix.ai
Création de bande dessinée
Les meilleurs générateurs IA pour les mangas shonen : créez des séquences d'action survoltées et des effets d'énergie
Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
15 outils
xix.ai
Entreprise
Les meilleurs outils de suivi des dépenses basés sur l'IA : numérisez vos reçus et classez automatiquement les dépenses de l'entreprise
Les meilleurs outils de gestion des dépenses basés sur l'IA en 2026 : les outils les mieux notés pour numériser vos reçus et classer automatiquement les dépenses de votre entreprise. Découvrez des solutions puissantes et révolutionnaires pour une gestion des dépenses sans effort, un suivi financier précis et une conformité simplifiée. Notre comparatif, mis à jour chaque semaine, qui oppose les options gratuites aux options payantes, vous aide à trouver la solution qui vous convient le mieux. Tirez pleinement parti de l'IA grâce aux recommandations d'experts de XIX.AI.
10 outils
xix.ai

 commentaires (0)
commentaires (0)
Aujourd'hui, Alibaba a officiellement lancé son grand modèle unifié de génération et d'édition d'images, Wan2.7-Image. Ce modèle permet non seulement de franchir un cap en matière de qualité visuelle, mais aussi de surmonter les limites traditionnelles de la génération d'images par IA, telles que les « visages génériques » et le « décalage entre les instructions et les résultats », grâce à des améliorations complètes de ses capacités.
Adieu aux visages générés par l'IA : place à l'ère du « une personne, un visage »
Wan2.7-Image améliore considérablement sa fonction de personnalisation des personnages virtuels. Les utilisateurs peuvent tout personnaliser, de la structure osseuse et des yeux aux traits faciaux les plus subtils, en contrôlant avec précision des caractéristiques spécifiques telles qu’un visage ovale, des yeux en amande ou des orbites enfoncées. Cette avancée dépasse l’uniformité mécanique des portraits IA du passé, permettant une véritable expression personnelle.
Fonctionnalité « Palette de couleurs » et rendu de texte « qualité d'impression »
En matière d'expression artistique, le modèle prend désormais en charge une fonctionnalité « Palette de couleurs ». Cela permet aux utilisateurs d'extraire la composition chromatique d'une image de référence — telle que la série rouge de Matisse ou la série jaune de Van Gogh — d'un simple clic et de l'appliquer avec précision à de nouvelles créations. De plus, Wan2.7-Image excelle dans le rendu de textes longs, prenant en charge des entrées allant jusqu'à 3 000 tokens. Il peut générer de manière stable une page A4 entière de contenu contenant des formules et des tableaux complexes, répondant aux normes de qualité d'impression dans les 12 langues prises en charge.
Édition interactive et cohérence multi-sujets
Le modèle dispose de puissantes capacités d’édition interactive, permettant l’alignement, le déplacement ou le remplacement d’éléments via une sélection précise. Par exemple, les utilisateurs peuvent sélectionner des caractères dans une image pour échanger leurs positions ou remplacer des glaçons par des fruits, avec un contrôle au niveau du pixel. Parallèlement, le modèle assure la cohérence entre plusieurs sujets sur un maximum de 9 images, en conservant un style et des caractéristiques uniformes lors de la génération de groupes de filles ou d’ensembles de mobilier par l’IA.
Avancées technologiques majeures et applications industrielles
Wan2.7-Image utilise une architecture unifiée de pointe pour la génération et la compréhension, permettant un mappage sémantique au sein d’un espace latent partagé. Cela signifie que le modèle ne se contente plus de deviner du texte pour faire correspondre des pixels, mais qu’il possède une compréhension sémantique fondamentale. Le modèle a été lancé parallèlement à la version Wan2.7-Image-pro, qui offre une composition plus stable et une compréhension plus précise.
Ce modèle est désormais largement utilisé dans la production de vidéos courtes (un acteur jouant plusieurs rôles), la publicité pour le commerce électronique (une seule image de modèle pour de multiples usages), l'éducation, la recherche et le divertissement social. Les utilisateurs peuvent accéder à l'API via la










 L'Administration chinoise du cyberespace impose l'étiquetage des courtes vidéos générées par l'IA et des vidéos de fiction
L'Administration chinoise du cyberespace a mis en place un plan global visant à normaliser l'étiquetage des contenus vidéo courts, en imposant aux plateformes l'utilisation de six balises obligatoires
L'Administration chinoise du cyberespace impose l'étiquetage des courtes vidéos générées par l'IA et des vidéos de fiction
L'Administration chinoise du cyberespace a mis en place un plan global visant à normaliser l'étiquetage des contenus vidéo courts, en imposant aux plateformes l'utilisation de six balises obligatoires
 DeepL, réputé pour la traduction de textes, se lance désormais dans la traduction vocale
DeepL, une entreprise de traduction surtout connue pour ses outils textuels, a lancé aujourd’hui une suite de traduction voix-voix destinée à des situations telles que les réunions, les conversations
DeepL, réputé pour la traduction de textes, se lance désormais dans la traduction vocale
DeepL, une entreprise de traduction surtout connue pour ses outils textuels, a lancé aujourd’hui une suite de traduction voix-voix destinée à des situations telles que les réunions, les conversations
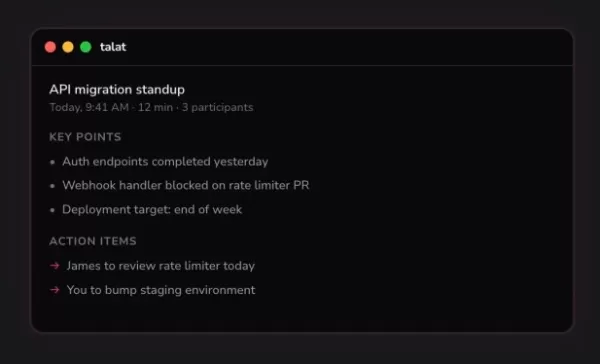 Les notes de réunion générées par l'IA de Talat sont stockées directement sur votre appareil, et non dans le cloud
Granola, l'application de prise de notes basée sur l'IA et évaluée à 250 millions de dollars, a conquis les fondateurs d'entreprises technologiques et les investisseurs en capital-risque. Mais un déve
Les notes de réunion générées par l'IA de Talat sont stockées directement sur votre appareil, et non dans le cloud
Granola, l'application de prise de notes basée sur l'IA et évaluée à 250 millions de dollars, a conquis les fondateurs d'entreprises technologiques et les investisseurs en capital-risque. Mais un déve

Découvrez les meilleurs outils de création de profils de personnages basés sur l'IA de 2026 pour donner de la profondeur à vos personnages. La sélection de XIX.AI regroupe les outils les mieux notés et les plus innovants, capables de générer des motivations cohérentes et des défauts fatals. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez dès maintenant votre potentiel de narration.
10 outils
xix.ai

Découvrez les meilleurs logiciels d'optimisation des prix basés sur l'IA pour 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan qui changent la donne : ils surveillent vos concurrents et ajustent automatiquement les prix de votre boutique pour maximiser vos bénéfices. Comparez les options gratuites et payantes grâce à des tests concrets. Prenez dès maintenant une longueur d'avance en matière de tarification.
10 outils
xix.ai

Découvrez les meilleurs outils d'analyse de code par IA de 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan, véritables révolutionnaires, permettant d'automatiser la conformité au code propre et de refactoriser les fichiers de dépôts hérités. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Prenez dès aujourd'hui une longueur d'avance grâce à l'IA.
10 outils
xix.ai

Découvrez les meilleures applications de synthèse vocale par IA de 2026, spécialement sélectionnées pour aider les personnes dyslexiques. Notre classement d'experts compare les outils gratuits et payants, en mettant en avant des fonctionnalités performantes qui améliorent l'efficacité de la lecture et l'apprentissage. Découvrez des solutions révolutionnaires à ne pas manquer pour libérer le potentiel des élèves. Commencez votre parcours sur XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
15 outils
xix.ai

Les meilleurs outils de gestion des dépenses basés sur l'IA en 2026 : les outils les mieux notés pour numériser vos reçus et classer automatiquement les dépenses de votre entreprise. Découvrez des solutions puissantes et révolutionnaires pour une gestion des dépenses sans effort, un suivi financier précis et une conformité simplifiée. Notre comparatif, mis à jour chaque semaine, qui oppose les options gratuites aux options payantes, vous aide à trouver la solution qui vous convient le mieux. Tirez pleinement parti de l'IA grâce aux recommandations d'experts de XIX.AI.
10 outils
xix.ai













