
















 Heim
HeimKI -Gelehrte verliehen den Turing -Preis für Technik hinter Alphagos Schachsieg

In den letzten zehn Jahren hat die künstliche Intelligenz mit ihren Fortschritten beeindruckt, insbesondere durch eine Technik, bei der Computer zufällige Entscheidungen treffen und aus den Ergebnissen lernen. Diese Methode, bekannt als Verstärkendes Lernen, war entscheidend für bemerkenswerte Errungenschaften in der KI.
Nehmen wir das AlphaZero-Programm von Google DeepMind aus dem Jahr 2016, das bis 2018 die komplexen Spiele Schach, Shogi und Go gemeistert hatte. Ebenso erreichte AlphaStar mit diesem Ansatz das „Großmeister“-Niveau im Videospiel *Starcraft II*. Diese Erfolge verdeutlichen die Kraft des Verstärkenden Lernens.
Am Mittwoch feierte das Feld einen bedeutenden Meilenstein, als zwei KI-Wissenschaftler für ihre bahnbrechende Arbeit zur Weiterentwicklung des Verstärkenden Lernens geehrt wurden. Andrew G. Barto, Professor emeritus an der University of Massachusetts, Amherst, und Richard S. Sutton, Professor an der University of Alberta, Kanada, erhielten den renommierten Turing Award 2025 von der Association for Computing Machinery (ACM).
Anerkennung von Pionieren im Verstärkenden Lernen
Die ACM lobte Barto und Sutton für die Grundlagen des Verstärkenden Lernens und erklärte, dass sie „die Hauptideen eingeführt, die mathematischen Grundlagen geschaffen und wichtige Algorithmen entwickelt haben.“ Diese Auszeichnung, die mit einem Preisgeld von 1 Million Dollar verbunden ist, wird oft als Äquivalent eines Nobelpreises in der Computerindustrie angesehen.
Verstärkendes Lernen lässt sich mit einer Maus vergleichen, die einen Irrgarten durchquert, um Käse zu finden. Die Maus lernt, welche Wege zum Ziel führen und welche in Sackgassen enden. Ähnlich glauben Neurowissenschaftler, dass intelligente Wesen, wie Mäuse, ein „inneres Modell der Welt“ entwickeln, um ihre Handlungen zu steuern.
Sutton und Barto schlugen vor, dass Computer ebenfalls solche inneren Modelle entwickeln könnten. Beim Verstärkenden Lernen sammelt der Computer Daten über seine Umgebung – sei es ein Irrgarten oder ein Schachbrett – und handelt zunächst zufällig. Er erhält Rückmeldungen in Form von Belohnungen oder Strafen, die ihm helfen, die Ergebnisse verschiedener Handlungen abzuschätzen. Basierend auf diesen Schätzungen entwickelt das Programm eine „Strategie“, um zukünftige Entscheidungen zu lenken, und balanciert dabei die Erkundung neuer Handlungen mit der Nutzung bekannter erfolgreicher Strategien.
Die Rolle von Erkundung und Nutzung
Im Kern erfordert Verstärkendes Lernen ein empfindliches Gleichgewicht zwischen der Erkundung neuer Möglichkeiten und der Nutzung bekannter Strategien. Keiner der beiden Ansätze allein reicht für den Erfolg aus.
Für diejenigen, die tiefer eintauchen möchten, ist das Lehrbuch von Sutton und Barto aus dem Jahr 2018 eine wertvolle Ressource.
Es ist anzumerken, dass der Begriff „Verstärkendes Lernen“ manchmal anders verwendet wird, etwa von Unternehmen wie OpenAI, die „Verstärkendes Lernen durch menschliches Feedback“ (RLHF) einsetzen, um die Ausgaben großer Sprachmodelle wie GPT zu verfeinern. Dies unterscheidet sich jedoch von der Methode, die von Sutton und Barto entwickelt wurde.
Verstärkendes Lernen als Theorie des Denkens
Sutton, der von 2017 bis 2023 Distinguished Research Scientist bei DeepMind war, hat argumentiert, dass Verstärkendes Lernen nicht nur eine Technik, sondern eine „Theorie des Denkens“ ist. Er hat Bedenken über das Fehlen einer rechentechnischen Theorie in der KI geäußert und betont, dass „Verstärkendes Lernen die erste rechentechnische Theorie der Intelligenz ist.“
Über seine technischen Anwendungen hinaus könnte Verstärkendes Lernen auch Licht auf Kreativität und freies Spiel als Ausdrucksformen von Intelligenz werfen. Sutton und Barto haben die Rolle des Spiels im Lernen hervorgehoben und betont, dass Neugier die Erkundung antreibt. Sutton hat betont, dass Spiel das Setzen von Zielen beinhalten kann, die nicht sofort nützlich sind, aber später von Vorteil sein könnten.
„Spiel ist etwas Großes,“ bemerkte Sutton und wies auf dessen bedeutende Rolle im weiteren Kontext von Lernen und Intelligenz hin.
Die Reise des Verstärkenden Lernens, von der grundlegenden Arbeit von Barto und Sutton bis hin zu seiner Anwendung in Spielen und darüber hinaus, verschiebt weiterhin die Grenzen dessen, was KI erreichen kann.
Verwandter Artikel
 OpenAI stellt die großen Modelle o3 und GPT-4.5 ein
Als Vorreiter im Bereich der künstlichen Intelligenz sorgt jeder technische Schritt von OpenAI für erhebliche Wellen in der Branche. Vor kurzem gab das Unternehmen eine wichtige Ankündigung bekannt: E
AIGCPanel 2.0.0 – Großes Update: Die Workflow-Engine läutet eine neue Ära der automatisierten Erstellung digitaler Menschen ein
AIGCPanel, ein leistungsstarkes Tool zur Erstellung digitaler Avatare, hat soeben die Version 2.0.0 veröffentlicht – die als „das bislang bedeutendste Update“ angekündigt wird. Diese grundlegende Über
BuzzFeed gründet eine Tochtergesellschaft für KI-basierte Junk-Apps
Inmitten einer schweren Unternehmenskrise startet der ehemalige Digitalmedien-Riese BuzzFeed ein ehrgeiziges Selbstrettungs-Experiment, das auf künstlicher Intelligenz basiert. Auf der jüngsten SXSW-K
Empfehlungen zu verwandten Spezialthemen
Bildbearbeitung
OpenAI stellt die großen Modelle o3 und GPT-4.5 ein
Als Vorreiter im Bereich der künstlichen Intelligenz sorgt jeder technische Schritt von OpenAI für erhebliche Wellen in der Branche. Vor kurzem gab das Unternehmen eine wichtige Ankündigung bekannt: E
AIGCPanel 2.0.0 – Großes Update: Die Workflow-Engine läutet eine neue Ära der automatisierten Erstellung digitaler Menschen ein
AIGCPanel, ein leistungsstarkes Tool zur Erstellung digitaler Avatare, hat soeben die Version 2.0.0 veröffentlicht – die als „das bislang bedeutendste Update“ angekündigt wird. Diese grundlegende Über
BuzzFeed gründet eine Tochtergesellschaft für KI-basierte Junk-Apps
Inmitten einer schweren Unternehmenskrise startet der ehemalige Digitalmedien-Riese BuzzFeed ein ehrgeiziges Selbstrettungs-Experiment, das auf künstlicher Intelligenz basiert. Auf der jüngsten SXSW-K
Empfehlungen zu verwandten Spezialthemen
Bildbearbeitung
 KI-gestützte Kunstgeneratoren für Kurzdramen-Storyboarding: Charaktere aus Fantasy- und Stadtliebesgeschichten
KI-gestützte Kunstgeneratoren für Kurzdramen-Storyboarding: Charaktere aus Fantasy- und Stadtliebesgeschichten
2026 Neuestes: Entdecken Sie die besten KI-Kunstgeneratoren für Storyboards zu Kurzgeschichten. Unsere sorgfältig ausgewählte Liste enthält hochbewertete Tools zur Erstellung fesselnder Charaktere in Fantasy- und Urban-Romance-Geschichten. Vergleichen Sie kostenlose und kostenpflichtige Optionen, sehen Sie sich tatsächliche Testergebnisse an und finden Sie den perfekten kreativen Partner für Ihre Projekte. Erhalten Sie wöchentlich aktualisierte Rankings sowie Expertenmeinungen von XIX.AI. Beginnen Sie noch heute, Ihre Geschichten visuell zu gestalten!
 10 Tools
10 Tools
 xix.ai
Schreiben
Die besten AI-Skripting-Tools für Radio und Podcasting: Erstellen Sie ansprechende Audowerbung.
xix.ai
Schreiben
Die besten AI-Skripting-Tools für Radio und Podcasting: Erstellen Sie ansprechende Audowerbung.
Entdecken Sie die besten KI-Skripting-Tools für Radio und Podcasting im Jahr 2026 bei XIX.AI. Unsere sorgfältig ausgewählte, hochbewertete Liste bietet leistungsstarke Lösungen, mit denen Sie ansprechende Audio-Werbespots schnell erstellen können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings. Entfalten Sie noch heute Ihr kreatives Potenzial!
10 Tools
xix.ai
Geschäft
Die beste KI-Software zur Vertragsprüfung: Erkennen Sie rechtliche Lücken und Compliance-Risiken sofort
Entdecken Sie auf XIX.AI die beste KI-Software zur Vertragsprüfung für 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools, die rechtliche Lücken und Compliance-Risiken sofort aufdecken. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihre bahnbrechende Lösung für eine sichere und effiziente Vertragsanalyse. Entdecken Sie jetzt den ultimativen Leitfaden.
10 Tools
xix.ai
Animationserstellung
AI-Anime-Generator für Donghua: Erstellen Sie Charaktere für Web-Romane und Comic-Avatare
Entdecken Sie die besten AI-Anime-Generatoren für Donghua im Jahr 2026. Unsere hochbewertete, sorgfältig ausgewählte Liste bietet leistungsstarke Tools, mit denen Sie atemberaubende Charaktere für Webromane und Comic-Avatare erstellen können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand realer Tests. Finden Sie Ihren perfekten kreativen Partner und bringen Sie Ihre Geschichten noch heute bei XIX.AI zum Leben.
10 Tools
xix.ai
Comic-Erstellung
Die besten KI-Tools zur automatischen Kolorierung von Manga: Flache Farben ohne Konsistenzfehler anwenden
Entdecken Sie bei XIX.AI die besten KI-Tools zur automatischen Kolorierung von Manga für das Jahr 2026. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Lösungen, die flächige Farben ohne Konsistenzfehler auftragen und so Ihre Produktivität steigern. Entdecken Sie Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten, Praxistests und wöchentlich aktualisierte Rankings, um das für Sie perfekte Tool zu finden. Nutzen Sie noch heute Ihren KI-Vorteil.
10 Tools
xix.ai
Schreiben
Die besten KI-Profilersteller: Erstellen Sie konsistente Charaktermotivationen und fatale Schwächen
Entdecken Sie die besten KI-Tools zur Charakterentwicklung für 2026, mit denen Sie facettenreiche Figuren erschaffen können. Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, die konsistente Motivationen und fatale Schwächen generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie jetzt Ihr Potenzial als Geschichtenerzähler.
10 Tools
xix.ai

 Kommentare (12)
Kommentare (12)
![NicholasAdams]()
This reinforcement learning stuff is wild! AlphaGo beating chess champs? Mind blown 🤯. Makes me wonder how far AI can push human limits—scary but exciting!
![GeorgeTaylor]()
Mind-blowing how reinforcement learning led to AlphaGo's chess win! 🤯 Makes me wonder what other games AI will conquer next.
![ArthurBrown]()
The AI Scholars Awarded Turing Prize really blew my mind! The way they used reinforcement learning to make AlphaGo win at chess is just genius. It's like watching a sci-fi movie come to life. I wish I understood the tech better, but it's still super cool! 🤓
![EdwardTaylor]()
AlphaGoのチェス勝利の背後にある技術でAI Scholarsがチューリング賞を受賞したのは驚きです!強化学習がAIをこれほどの高みに押し上げたのを見るのは魅力的です。ただ、時々技術的な内容が難しすぎることがありますが、それでも人間の創意工夫の証です。境界を押し広げ続けてください!🧠
![WalterSanchez]()
The AI Scholars winning the Turing Prize for the technique behind AlphaGo's chess victory is mind-blowing! It's fascinating to see how reinforcement learning has propelled AI to such heights. The only thing is, it's a bit too technical for me at times, but still, it's a testament to human ingenuity. Keep pushing the boundaries! 🧠
![WillieJackson]()
¡Los académicos de IA que recibieron el Premio Turing por la técnica detrás de la victoria de AlphaGo en el ajedrez me dejaron asombrado! Usar el aprendizaje por refuerzo para ganar es genial. Me gustaría entender mejor la tecnología, pero aún así es muy cool! 🤓
In den letzten zehn Jahren hat die künstliche Intelligenz mit ihren Fortschritten beeindruckt, insbesondere durch eine Technik, bei der Computer zufällige Entscheidungen treffen und aus den Ergebnissen lernen. Diese Methode, bekannt als Verstärkendes Lernen, war entscheidend für bemerkenswerte Errungenschaften in der KI.
Nehmen wir das AlphaZero-Programm von Google DeepMind aus dem Jahr 2016, das bis 2018 die komplexen Spiele Schach, Shogi und Go gemeistert hatte. Ebenso erreichte AlphaStar mit diesem Ansatz das „Großmeister“-Niveau im Videospiel *Starcraft II*. Diese Erfolge verdeutlichen die Kraft des Verstärkenden Lernens.
Am Mittwoch feierte das Feld einen bedeutenden Meilenstein, als zwei KI-Wissenschaftler für ihre bahnbrechende Arbeit zur Weiterentwicklung des Verstärkenden Lernens geehrt wurden. Andrew G. Barto, Professor emeritus an der University of Massachusetts, Amherst, und Richard S. Sutton, Professor an der University of Alberta, Kanada, erhielten den renommierten Turing Award 2025 von der Association for Computing Machinery (ACM).
Anerkennung von Pionieren im Verstärkenden Lernen
Die ACM lobte Barto und Sutton für die Grundlagen des Verstärkenden Lernens und erklärte, dass sie „die Hauptideen eingeführt, die mathematischen Grundlagen geschaffen und wichtige Algorithmen entwickelt haben.“ Diese Auszeichnung, die mit einem Preisgeld von 1 Million Dollar verbunden ist, wird oft als Äquivalent eines Nobelpreises in der Computerindustrie angesehen.
Verstärkendes Lernen lässt sich mit einer Maus vergleichen, die einen Irrgarten durchquert, um Käse zu finden. Die Maus lernt, welche Wege zum Ziel führen und welche in Sackgassen enden. Ähnlich glauben Neurowissenschaftler, dass intelligente Wesen, wie Mäuse, ein „inneres Modell der Welt“ entwickeln, um ihre Handlungen zu steuern.
Sutton und Barto schlugen vor, dass Computer ebenfalls solche inneren Modelle entwickeln könnten. Beim Verstärkenden Lernen sammelt der Computer Daten über seine Umgebung – sei es ein Irrgarten oder ein Schachbrett – und handelt zunächst zufällig. Er erhält Rückmeldungen in Form von Belohnungen oder Strafen, die ihm helfen, die Ergebnisse verschiedener Handlungen abzuschätzen. Basierend auf diesen Schätzungen entwickelt das Programm eine „Strategie“, um zukünftige Entscheidungen zu lenken, und balanciert dabei die Erkundung neuer Handlungen mit der Nutzung bekannter erfolgreicher Strategien.
Die Rolle von Erkundung und Nutzung
Im Kern erfordert Verstärkendes Lernen ein empfindliches Gleichgewicht zwischen der Erkundung neuer Möglichkeiten und der Nutzung bekannter Strategien. Keiner der beiden Ansätze allein reicht für den Erfolg aus.
Für diejenigen, die tiefer eintauchen möchten, ist das Lehrbuch von Sutton und Barto aus dem Jahr 2018 eine wertvolle Ressource.
Es ist anzumerken, dass der Begriff „Verstärkendes Lernen“ manchmal anders verwendet wird, etwa von Unternehmen wie OpenAI, die „Verstärkendes Lernen durch menschliches Feedback“ (RLHF) einsetzen, um die Ausgaben großer Sprachmodelle wie GPT zu verfeinern. Dies unterscheidet sich jedoch von der Methode, die von Sutton und Barto entwickelt wurde.
Verstärkendes Lernen als Theorie des Denkens
Sutton, der von 2017 bis 2023 Distinguished Research Scientist bei DeepMind war, hat argumentiert, dass Verstärkendes Lernen nicht nur eine Technik, sondern eine „Theorie des Denkens“ ist. Er hat Bedenken über das Fehlen einer rechentechnischen Theorie in der KI geäußert und betont, dass „Verstärkendes Lernen die erste rechentechnische Theorie der Intelligenz ist.“
Über seine technischen Anwendungen hinaus könnte Verstärkendes Lernen auch Licht auf Kreativität und freies Spiel als Ausdrucksformen von Intelligenz werfen. Sutton und Barto haben die Rolle des Spiels im Lernen hervorgehoben und betont, dass Neugier die Erkundung antreibt. Sutton hat betont, dass Spiel das Setzen von Zielen beinhalten kann, die nicht sofort nützlich sind, aber später von Vorteil sein könnten.
„Spiel ist etwas Großes,“ bemerkte Sutton und wies auf dessen bedeutende Rolle im weiteren Kontext von Lernen und Intelligenz hin.
Die Reise des Verstärkenden Lernens, von der grundlegenden Arbeit von Barto und Sutton bis hin zu seiner Anwendung in Spielen und darüber hinaus, verschiebt weiterhin die Grenzen dessen, was KI erreichen kann.










 OpenAI stellt die großen Modelle o3 und GPT-4.5 ein
Als Vorreiter im Bereich der künstlichen Intelligenz sorgt jeder technische Schritt von OpenAI für erhebliche Wellen in der Branche. Vor kurzem gab das Unternehmen eine wichtige Ankündigung bekannt: E
OpenAI stellt die großen Modelle o3 und GPT-4.5 ein
Als Vorreiter im Bereich der künstlichen Intelligenz sorgt jeder technische Schritt von OpenAI für erhebliche Wellen in der Branche. Vor kurzem gab das Unternehmen eine wichtige Ankündigung bekannt: E
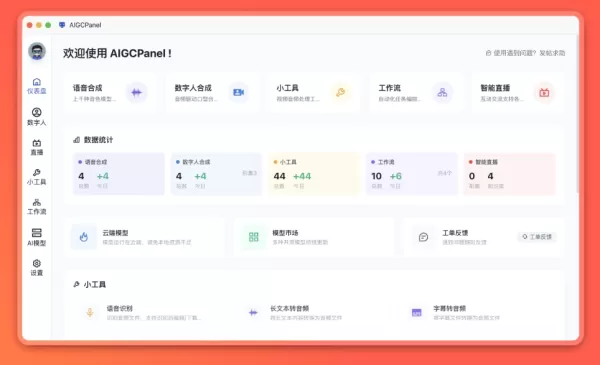 AIGCPanel 2.0.0 – Großes Update: Die Workflow-Engine läutet eine neue Ära der automatisierten Erstellung digitaler Menschen ein
AIGCPanel, ein leistungsstarkes Tool zur Erstellung digitaler Avatare, hat soeben die Version 2.0.0 veröffentlicht – die als „das bislang bedeutendste Update“ angekündigt wird. Diese grundlegende Über
AIGCPanel 2.0.0 – Großes Update: Die Workflow-Engine läutet eine neue Ära der automatisierten Erstellung digitaler Menschen ein
AIGCPanel, ein leistungsstarkes Tool zur Erstellung digitaler Avatare, hat soeben die Version 2.0.0 veröffentlicht – die als „das bislang bedeutendste Update“ angekündigt wird. Diese grundlegende Über
 BuzzFeed gründet eine Tochtergesellschaft für KI-basierte Junk-Apps
Inmitten einer schweren Unternehmenskrise startet der ehemalige Digitalmedien-Riese BuzzFeed ein ehrgeiziges Selbstrettungs-Experiment, das auf künstlicher Intelligenz basiert. Auf der jüngsten SXSW-K
BuzzFeed gründet eine Tochtergesellschaft für KI-basierte Junk-Apps
Inmitten einer schweren Unternehmenskrise startet der ehemalige Digitalmedien-Riese BuzzFeed ein ehrgeiziges Selbstrettungs-Experiment, das auf künstlicher Intelligenz basiert. Auf der jüngsten SXSW-K

2026 Neuestes: Entdecken Sie die besten KI-Kunstgeneratoren für Storyboards zu Kurzgeschichten. Unsere sorgfältig ausgewählte Liste enthält hochbewertete Tools zur Erstellung fesselnder Charaktere in Fantasy- und Urban-Romance-Geschichten. Vergleichen Sie kostenlose und kostenpflichtige Optionen, sehen Sie sich tatsächliche Testergebnisse an und finden Sie den perfekten kreativen Partner für Ihre Projekte. Erhalten Sie wöchentlich aktualisierte Rankings sowie Expertenmeinungen von XIX.AI. Beginnen Sie noch heute, Ihre Geschichten visuell zu gestalten!
10 Tools
xix.ai

Entdecken Sie die besten KI-Skripting-Tools für Radio und Podcasting im Jahr 2026 bei XIX.AI. Unsere sorgfältig ausgewählte, hochbewertete Liste bietet leistungsstarke Lösungen, mit denen Sie ansprechende Audio-Werbespots schnell erstellen können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings. Entfalten Sie noch heute Ihr kreatives Potenzial!
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die beste KI-Software zur Vertragsprüfung für 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools, die rechtliche Lücken und Compliance-Risiken sofort aufdecken. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihre bahnbrechende Lösung für eine sichere und effiziente Vertragsanalyse. Entdecken Sie jetzt den ultimativen Leitfaden.
10 Tools
xix.ai

Entdecken Sie die besten AI-Anime-Generatoren für Donghua im Jahr 2026. Unsere hochbewertete, sorgfältig ausgewählte Liste bietet leistungsstarke Tools, mit denen Sie atemberaubende Charaktere für Webromane und Comic-Avatare erstellen können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand realer Tests. Finden Sie Ihren perfekten kreativen Partner und bringen Sie Ihre Geschichten noch heute bei XIX.AI zum Leben.
10 Tools
xix.ai

Entdecken Sie bei XIX.AI die besten KI-Tools zur automatischen Kolorierung von Manga für das Jahr 2026. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Lösungen, die flächige Farben ohne Konsistenzfehler auftragen und so Ihre Produktivität steigern. Entdecken Sie Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten, Praxistests und wöchentlich aktualisierte Rankings, um das für Sie perfekte Tool zu finden. Nutzen Sie noch heute Ihren KI-Vorteil.
10 Tools
xix.ai

Entdecken Sie die besten KI-Tools zur Charakterentwicklung für 2026, mit denen Sie facettenreiche Figuren erschaffen können. Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, die konsistente Motivationen und fatale Schwächen generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie jetzt Ihr Potenzial als Geschichtenerzähler.
10 Tools
xix.ai

This reinforcement learning stuff is wild! AlphaGo beating chess champs? Mind blown 🤯. Makes me wonder how far AI can push human limits—scary but exciting!
Mind-blowing how reinforcement learning led to AlphaGo's chess win! 🤯 Makes me wonder what other games AI will conquer next.
The AI Scholars Awarded Turing Prize really blew my mind! The way they used reinforcement learning to make AlphaGo win at chess is just genius. It's like watching a sci-fi movie come to life. I wish I understood the tech better, but it's still super cool! 🤓
AlphaGoのチェス勝利の背後にある技術でAI Scholarsがチューリング賞を受賞したのは驚きです!強化学習がAIをこれほどの高みに押し上げたのを見るのは魅力的です。ただ、時々技術的な内容が難しすぎることがありますが、それでも人間の創意工夫の証です。境界を押し広げ続けてください!🧠
The AI Scholars winning the Turing Prize for the technique behind AlphaGo's chess victory is mind-blowing! It's fascinating to see how reinforcement learning has propelled AI to such heights. The only thing is, it's a bit too technical for me at times, but still, it's a testament to human ingenuity. Keep pushing the boundaries! 🧠
¡Los académicos de IA que recibieron el Premio Turing por la técnica detrás de la victoria de AlphaGo en el ajedrez me dejaron asombrado! Usar el aprendizaje por refuerzo para ganar es genial. Me gustaría entender mejor la tecnología, pero aún así es muy cool! 🤓













