Though often paid very little or nothing at all, the anonymous individuals who assess images for "harmful" content hold significant power over your life through their decisions. A major new study from Google now suggests that these annotators often develop their own personal rules for what constitutes "harmful" or offensive material—regardless of how unusual or subjective their reactions to an image may be. So what could possibly go wrong?
Opinion This week, a joint effort by Google Research and Google Mind brought together 13 contributors for a new paper examining whether the "gut feelings" of image annotators should influence how images are rated for algorithms—even when those feelings conflict with established rating guidelines.
This issue matters to you because the standards annotators agree upon as offensive tend to become embedded in automated moderation systems, legal definitions of "obscene" or "unacceptable" content—such as the UK’s upcoming NSFW firewall* (with Australia soon to follow)—and content evaluation mechanisms on social media and other platforms.
In short, the broader the criteria for what's considered offensive, the more extensive the potential censorship.
Vibe-Censorship
The study doesn’t stop there. It also reveals that image raters often censor more strictly based on what they believe might offend others, not just themselves. Additionally, low-quality images frequently trigger safety concerns, despite image quality being unrelated to content.
In its conclusion, the paper highlights these two findings almost as if its central argument fell short—yet the researchers felt compelled to publish anyway.
While that’s not unusual in academic publishing, a closer reading reveals a more unsettling undercurrent: annotation practices may be moving toward what can only be called vibe-annotating:
“Our findings suggest that existing frameworks need to account for subjective and contextual dimensions, such as emotional reactions, implicit judgments, and cultural interpretations of harm. Annotators’ frequent use of emotional language and their divergence from predefined harm labels highlight gaps in current evaluation practices.
Expanding annotation guidelines to include illustrative examples of diverse cultural and emotional interpretations can help address these gaps.”
The new paper uses straightforward examples that resonate with most readers, though its core content raises far more complex questions. Here, each image is accompanied by annotators' emotional responses. Source: https://arxiv.org/pdf/2507.16033
Initially, this sounds like a reasonable effort to better define "harm" in images—a worthy goal. But the paper repeatedly suggests that achieving this may not be practical or even desirable:
“Our findings suggest that existing frameworks need to account for subjective and contextual dimensions, such as emotional reactions, implicit judgments, and cultural interpretations of harm. Annotators’ frequent use of emotional language and their divergence from predefined harm labels highlight gaps in current evaluation practices.
Expanding annotation guidelines to include illustrative examples of diverse cultural and emotional interpretations can help address these gaps […]
[…] The process by which annotators reason about ambiguous images often reflects their personal, cultural, and emotional perspectives, which are difficult to scaffold or standardize.”
It's hard to see how including "illustrative examples of diverse cultural and emotional interpretations" fits into a rational rating system. The authors repeatedly grapple with this point without offering a clear solution, making their central argument feel like it, too, is driven by "vibes"—even as it deals with intangible psychological factors.
Simply put, expanding annotation criteria in this way could allow any content—or entire topics—that an annotator reacts strongly to, to be suppressed or obscured.
Binary Judgement
Quantifying the harm caused by images and text is inherently difficult, especially since "high" and "low" culture often overlap—as seen in art and literature. This has led to early forms of "vibe-based" censorship, where obscene material is judged not by strict definition, but by the "you know it when you see it" principle.
Beneath its extensive discussion of empathy and nuance, the paper subtly challenges the authority of centralized, standardized categories like "violence," "nudity," and "hate"—categories that enable platforms to implement scalable moderation with reasonable accuracy.
The emerging argument is that only decentralized, subjective, context-aware human judgment can properly evaluate GenAI output.
But this approach isn't scalable. You can’t filter billions of images based on "vibes" and personal experience. Harm must be quantified into specific properties; filtering systems need clear limits; and edge cases require updated guidelines—much like how new laws are sometimes needed to address unique grievances.
Instead, the paper seems to advocate for an automated moderation system that automatically broadens its scope—so cautious that even one annotator’s highly personal reaction could penalize an image that offends no one else.
Moral Expansion
Although exploratory in nature, the paper applies scientific methods: the authors created a framework to identify—though not strictly measure—a wider range of annotator reactions to images, and examined how these vary by gender and other demographics.
Beyond analyzing harm-focus†, the study examined "moral reasoning" in annotators’ additional comments. Participants were asked to annotate a modified dataset containing images, prompts, and related text.
This "moral sentiment autorater" was designed to capture moral values such as Care, Equality, Proportionality, Loyalty, Authority, and Purity, based on Moral Foundations Theory—a psychological model that, due to its fluid nature, is ill-suited for creating the concrete definitions needed in large-scale rating systems.
Inspired by this theory, the authors introduced additional safety dimensions, including fear, anger, sadness, disgust, confusion, and uncanniness.
The authors elaborate on fear:
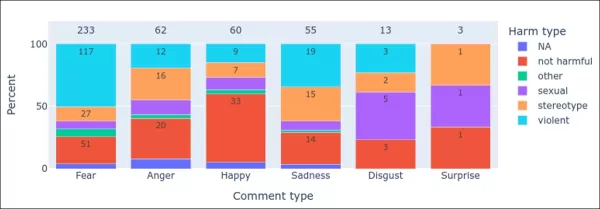
“Many annotators used terms like ‘scary’ (e.g., for distorted faces or images suggesting violence like a gun pointed at a child), ‘disturbing’ (e.g., ‘Absolutely vile to see someone get ran over, very distressing and disturbing,’ or ‘Disturbing and looks like blood’ for red paint), or ‘upsetting’ (e.g., ‘The image of the boy has many distortions… I find it distasteful because it appears that the boy is playing on the wrong side of the side rails’).
The [graph below] shows that ‘fear’ was the most frequently mentioned emotion (233 mentions). While nearly half of these were linked to violent content, the second-highest number of fear mentions came from content deemed not harmful.”
Distribution of emotion-related terms across harm categories, with bar heights indicating proportions of comments, counts displayed within bars, and total comment counts shown above each category.
Regarding these new safety dimensions, the authors state:
“These emerging themes highlight a critical need to enrich AI image evaluation frameworks by integrating subjective, emotional, and perceptual elements.”
This direction could be risky, as it may allow annotation processes to arbitrarily introduce rules based on individual reactions—rather than requiring all annotators to follow consistent standards.
If there's an economic motive here, it's that this model enables hyperscale human annotation: a frictionless, self-regulating system where participants define the rules themselves.
Under standard annotation, rules are agreed upon by consensus and followed by annotators. Under the paper’s proposed model, that oversight is reduced or removed—meaning any image that offends even one person could be flagged, partly because building consensus is costly and time-consuming.
Rorschach Judgements
The goal of annotation is to produce accurate descriptions through expert oversight, consensus, or ideally both. Expanding a clear hierarchy of harms into an "intuitive," highly personal process is like annotating a Rorschach test.
For example, the paper notes that some annotators interpreted poor image quality—such as JPEG artifacts or technical flaws—as “disturbing” or “indicative of harm”:
“This occurred despite the task omitting instructions on image quality. Moreover, annotators interpreted these quality artifacts as semantically meaningful.
One annotator commented, ‘The image is not harmful at all; he just has a bit of a distorted face.’ Similarly, others saw image flaws as intentional harm, attributing emotional meaning to glitches. For example, one interpreted a distorted face as ‘indicative of pain.’”
By prioritizing subjective, emotional, or context-specific reactions over predefined safety labels, this approach risks creating a system where anything can be arbitrarily flagged as harmful—leading to a "chilling effect" of ad hoc content removal or recategorization, especially for material that might offend specific interest groups.
The paper “Just a strange pic”: Evaluating ‘safety' in GenAI Image safety annotation tasks from diverse annotators' perspectives is available on Arxiv.
* A simplified reference, as this isn’t the main focus. Under the new law, offending sites must either self-police, implement costly review and age-verification systems (feasible only for large platforms), or block UK access—again, at their own expense.
† Often simplified as the “think of the children” meme, which satirizes using others’ moral agency for seemingly altruistic purposes.
Taotian Group Accelerates AI-Native Restructuring, Grants Interns Free Token QuotasTaoTian Group recently introduced the "AI Productivity Plan," designed to accelerate the integration of AI technology into e-commerce operations and R&D workflows through resource allocation and tool subsidies. The program is now available to all int
Glean targets enterprise AI infrastructure in land grabThe race to dominate enterprise AI is accelerating. Microsoft is embedding Copilot into Office, Google is integrating Gemini into Workspace, and both OpenAI and Anthropic are selling directly to corporations. Meanwhile, nearly every SaaS vendor now i
Discover the 2026 best AI assistants for crafting epic xianxia & wuxia tales. XIX.AI's curated list features top-rated, game-changing tools to master cultivation progression and martial arts choreography. Compare free vs paid options with real-world tests. Unlock your creative potential and start writing today!
Discover the 2026 best AI mobile app coding tools for Flutter & React Native. Our curated, top-rated list features powerful, game-changing solutions that generate cross-platform code from prompts. Compare free vs paid options with real-world tests. Unlock faster development and build better apps. Explore the rankings on XIX.AI now!
Discover the 2026 best AI Chrome extension generators on XIX.AI. Our curated list features top-rated, must-try tools that let you create custom browser add-ons with zero coding. Compare free vs paid options, see real-world tests, and unlock your productivity. Explore the latest rankings and find your perfect tool today!
Discover the 2026 best AI multilingual TTS tools for authentic native-accent speech in 50+ languages. Explore our top-rated, curated rankings with free vs paid comparisons and real-world tests. Find your perfect voice tool on XIX.AI and unlock global communication today.
Discover the 2026 latest top-rated AI meeting automation tools for smarter, faster collaboration. Our curated list features powerful, game-changing solutions to automate notes, summaries, and action items. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock peak team productivity. Explore the best picks now at XIX.AI.
Discover the 2026 latest top-rated AI prompts for Infrastructure-as-Code. XIX.AI's curated selection helps you safely deploy Terraform & Docker configurations, automate cloud setups, and boost DevOps productivity. Compare free vs paid options with real-world tests. Explore now and unlock your AI edge.
By clicking "Accept All Cookies", you agree to the storing of cookies on your device to enhance site navigation, analyze site usage, and assist in our marketing efforts.Privacy Policy Notice
When you visit any website, it may store or retrieve information on your browser, mostly in the form of cookies. This information might be about you, your preferences or your device and is mostly used to make the site work as you expect it to. The information does not usually directly identify you, but it can give you a more personalized web experience. Because we respect your right to privacy, you can choose not to allow some types of cookies. Click on the different category headings to find out more and change our default settings.However, blocking some types of cookies may impact your experience of the site and the services we are able to offer. Privacy PolicyStatement
Manage Preferences
Strictly Necessary Cookie
Always Active
These cookies are necessary for the website to function and cannot be switched off in our systems. They are usually only set in response to actions made by you which amount to a request for services, such as setting your privacy preferences, logging in or filling in forms. You can set your browser to block or alert you about these cookies, but some parts of the site will not then work. These cookies do not store any personally identifiable information.

















 Home
Home
 China Telecom Invests in Mianbi Intelligence, Raises Capital to 713,000 Yuan for LLM & Data Infra
The "national team" and the leading figure from Tsinghua University in the large model space are deepening their strategic alignment. On March 1, 2026, according to the latest business registration data from Qichacha, Beijing Mianbi Intelligent Techn
China Telecom Invests in Mianbi Intelligence, Raises Capital to 713,000 Yuan for LLM & Data Infra
The "national team" and the leading figure from Tsinghua University in the large model space are deepening their strategic alignment. On March 1, 2026, according to the latest business registration data from Qichacha, Beijing Mianbi Intelligent Techn
 Best AI Xianxia & Wuxia Assistants: Write Epic Cultivation Progression & Martial Arts Choreography
Best AI Xianxia & Wuxia Assistants: Write Epic Cultivation Progression & Martial Arts Choreography
 10 tools
10 tools
 xix.ai
code
xix.ai
code

 Comments (0)
0/500
Comments (0)
0/500












 China Telecom Invests in Mianbi Intelligence, Raises Capital to 713,000 Yuan for LLM & Data Infra
The "national team" and the leading figure from Tsinghua University in the large model space are deepening their strategic alignment. On March 1, 2026, according to the latest business registration data from Qichacha, Beijing Mianbi Intelligent Techn
China Telecom Invests in Mianbi Intelligence, Raises Capital to 713,000 Yuan for LLM & Data Infra
The "national team" and the leading figure from Tsinghua University in the large model space are deepening their strategic alignment. On March 1, 2026, according to the latest business registration data from Qichacha, Beijing Mianbi Intelligent Techn
 Taotian Group Accelerates AI-Native Restructuring, Grants Interns Free Token Quotas
TaoTian Group recently introduced the "AI Productivity Plan," designed to accelerate the integration of AI technology into e-commerce operations and R&D workflows through resource allocation and tool subsidies. The program is now available to all int
Taotian Group Accelerates AI-Native Restructuring, Grants Interns Free Token Quotas
TaoTian Group recently introduced the "AI Productivity Plan," designed to accelerate the integration of AI technology into e-commerce operations and R&D workflows through resource allocation and tool subsidies. The program is now available to all int
 Glean targets enterprise AI infrastructure in land grab
The race to dominate enterprise AI is accelerating. Microsoft is embedding Copilot into Office, Google is integrating Gemini into Workspace, and both OpenAI and Anthropic are selling directly to corporations. Meanwhile, nearly every SaaS vendor now i
Glean targets enterprise AI infrastructure in land grab
The race to dominate enterprise AI is accelerating. Microsoft is embedding Copilot into Office, Google is integrating Gemini into Workspace, and both OpenAI and Anthropic are selling directly to corporations. Meanwhile, nearly every SaaS vendor now i



















