
















 Home
HomeAlibaba Tongyi unveils voice model with 'FreeStyle' natural language control
Today, Alibaba Tongyi Lab's Speech Team introduced two groundbreaking voice generation models: Fun-CosyVoice3.5 and Fun-AudioGen-VD. The standout feature of these models is their support for "FreeStyle" commands. Instead of complex parameter adjustments, users can precisely control vocal expression styles or build intricate audio scenes from scratch using simple natural language descriptions.
Each model serves distinct purposes:
Fun-CosyVoice3.5: Multilingual Replication and Fine-Grained Control
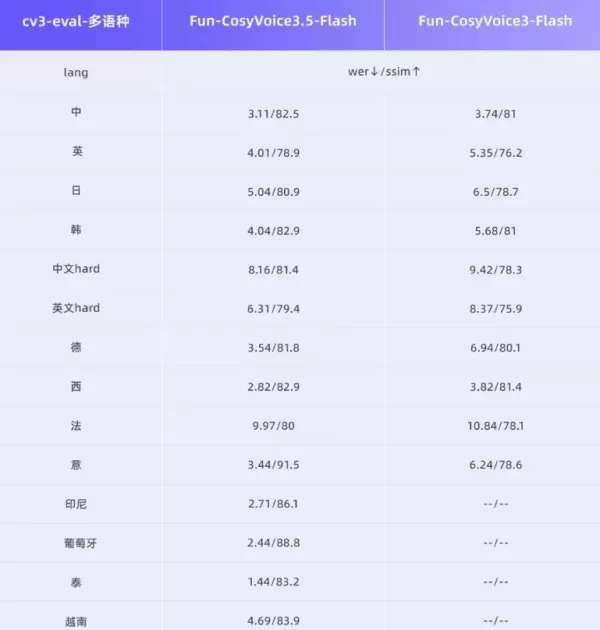
This enhanced version of CosyVoice achieves core breakthroughs in understanding speech expression nuances.
Command-Driven Generation: Users can input instructions like "speak more confidently" or "slow down with emotional variation" for real-time vocal adjustments.
Language Expansion: Added support for Thai, Indonesian, Portuguese, and Vietnamese maintains industry-leading performance in transcription accuracy (WER) and voice similarity across 13 languages.
Rare Character Optimization: Specialized training reduced error rates for uncommon characters from 15.2% to 5.3%.
Performance Boost: First packet latency decreased by 35%, significantly enhancing real-time interaction fluidity.
Fun-AudioGen-VD: Comprehensive Sound Design
This model acts as an "audio director," generating integrated audio combining "characters + environments."
Voice Customization: Specify gender, age, accent, and detailed characteristics like "hoarse, deep, or low-pitched" voices.
Emotion and Role Play: Simulates roles including customer service agents, broadcasters, and children, even conveying complex states like "outward calm with internal tension."
Immersive Environments: Adds background sounds (battlefield chaos, café murmurs) and spatial effects (cathedral reverb, underwater acoustics) for full spatial simulation.
Tongyi Lab notes these models will democratize high-quality voice creation, offering powerful AI support for podcasting, game development, and film post-production.
Related article
 First Baidu AI Comic Drama Creation Base in Shandong Launches in Zibo
On April 27, Shandong Province reached a milestone in digital cultural creation with the official launch of its first Baidu AI comic drama creation base at Zibo Normal College. This base represents a new chapter in school-enterprise collaboration, ai
Sandberg and Clegg Join Nscale Board as 'Stargate Norway' Startup Hits $14.6B Valuation
As demand surges for data centers capable of delivering AI compute at scale, Nscale, a British AI infrastructure company backed by Nvidia, has reached a valuation of $14.6 billion. That positions it as one of Europe's newest decacorns, alongside Hels
Runway's $5.3B Valuation Challenges Google as Video AI Surpasses Language
While most AI giants have poured billions into language models, generative AI video startup Runway is charging ahead on a very different path. According to TechCrunch, this young company—founded by art school graduates—has now reached a valuation of
Related Special Topic Recommendations
Health & Wellness
First Baidu AI Comic Drama Creation Base in Shandong Launches in Zibo
On April 27, Shandong Province reached a milestone in digital cultural creation with the official launch of its first Baidu AI comic drama creation base at Zibo Normal College. This base represents a new chapter in school-enterprise collaboration, ai
Sandberg and Clegg Join Nscale Board as 'Stargate Norway' Startup Hits $14.6B Valuation
As demand surges for data centers capable of delivering AI compute at scale, Nscale, a British AI infrastructure company backed by Nvidia, has reached a valuation of $14.6 billion. That positions it as one of Europe's newest decacorns, alongside Hels
Runway's $5.3B Valuation Challenges Google as Video AI Surpasses Language
While most AI giants have poured billions into language models, generative AI video startup Runway is charging ahead on a very different path. According to TechCrunch, this young company—founded by art school graduates—has now reached a valuation of
Related Special Topic Recommendations
Health & Wellness
 AI Pregnancy Copilots: Generate Safe Trimester-by-Trimester Workout & Nutrition Plans
AI Pregnancy Copilots: Generate Safe Trimester-by-Trimester Workout & Nutrition Plans
Discover the 2026 best AI pregnancy copilots for safe, personalized trimester-by-trimester workout and nutrition plans. Get top-rated, curated recommendations with free vs paid comparisons and real-world insights. Unlock your healthiest pregnancy journey with XIX.AI's expert guide. Explore now.
 10 tools
10 tools
 xix.ai
writing
Best Free AI Undetectable Writers: Turn Robotic Drafts into Natural, Human-Like Prose
xix.ai
writing
Best Free AI Undetectable Writers: Turn Robotic Drafts into Natural, Human-Like Prose
Discover the 2026 best free undetectable AI writers at XIX.AI. Our top-rated, curated list helps you transform robotic drafts into natural, human-like prose. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock your AI writing edge today.
10 tools
xix.ai
Image editing
AI Art Generators for Short-Drama Storyboards: Fantasy & Urban Romance Characters
2026 Latest: Discover the best AI art generators for short-drama storyboards. Our curated list features top-rated tools for creating compelling fantasy and urban romance characters. Compare free vs paid options, see real-world test results, and find your perfect creative partner. Get weekly updated rankings and expert insights from XIX.AI. Start visualizing your story today!
10 tools
xix.ai
writing
Best AI Scripting Tools for Radio & Podcasting: Write Engaging Audio Commercials
Discover the 2026 best AI scripting tools for radio & podcasting at XIX.AI. Our curated, top-rated list features powerful, game-changing solutions to write engaging audio commercials fast. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock your creative edge today!
10 tools
xix.ai
Business
Best AI Contract Review Software: Spot Legal Loopholes & Compliance Risks Instantly
Discover the 2026 best AI contract review software on XIX.AI. Our top-rated, curated list features powerful tools that instantly spot legal loopholes and compliance risks. Compare free vs paid options with real-world tests and weekly updated rankings. Find your game-changing solution for secure, efficient contract analysis. Explore the definitive guide now.
10 tools
xix.ai
Animation Creation
AI Anime Generator for Donghua: Create Web Novel Characters & Comic Avatars
Discover the 2026 best AI anime generators for donghua. Our top-rated, curated list features powerful tools to create stunning web novel characters and comic avatars. Compare free vs paid options with real-world tests. Find your perfect creative partner and bring your stories to life today at XIX.AI.
10 tools
xix.ai

 Comments (0)
0/500
Comments (0)
0/500
Today, Alibaba Tongyi Lab's Speech Team introduced two groundbreaking voice generation models: Fun-CosyVoice3.5 and Fun-AudioGen-VD. The standout feature of these models is their support for "FreeStyle" commands. Instead of complex parameter adjustments, users can precisely control vocal expression styles or build intricate audio scenes from scratch using simple natural language descriptions.
Each model serves distinct purposes:
Fun-CosyVoice3.5: Multilingual Replication and Fine-Grained Control
This enhanced version of CosyVoice achieves core breakthroughs in understanding speech expression nuances.
Command-Driven Generation: Users can input instructions like "speak more confidently" or "slow down with emotional variation" for real-time vocal adjustments.
Language Expansion: Added support for Thai, Indonesian, Portuguese, and Vietnamese maintains industry-leading performance in transcription accuracy (WER) and voice similarity across 13 languages.
Rare Character Optimization: Specialized training reduced error rates for uncommon characters from 15.2% to 5.3%.
Performance Boost: First packet latency decreased by 35%, significantly enhancing real-time interaction fluidity.
Fun-AudioGen-VD: Comprehensive Sound Design
This model acts as an "audio director," generating integrated audio combining "characters + environments."
Voice Customization: Specify gender, age, accent, and detailed characteristics like "hoarse, deep, or low-pitched" voices.
Emotion and Role Play: Simulates roles including customer service agents, broadcasters, and children, even conveying complex states like "outward calm with internal tension."
Immersive Environments: Adds background sounds (battlefield chaos, café murmurs) and spatial effects (cathedral reverb, underwater acoustics) for full spatial simulation.
Tongyi Lab notes these models will democratize high-quality voice creation, offering powerful AI support for podcasting, game development, and film post-production.










 First Baidu AI Comic Drama Creation Base in Shandong Launches in Zibo
On April 27, Shandong Province reached a milestone in digital cultural creation with the official launch of its first Baidu AI comic drama creation base at Zibo Normal College. This base represents a new chapter in school-enterprise collaboration, ai
First Baidu AI Comic Drama Creation Base in Shandong Launches in Zibo
On April 27, Shandong Province reached a milestone in digital cultural creation with the official launch of its first Baidu AI comic drama creation base at Zibo Normal College. This base represents a new chapter in school-enterprise collaboration, ai
 Sandberg and Clegg Join Nscale Board as 'Stargate Norway' Startup Hits $14.6B Valuation
As demand surges for data centers capable of delivering AI compute at scale, Nscale, a British AI infrastructure company backed by Nvidia, has reached a valuation of $14.6 billion. That positions it as one of Europe's newest decacorns, alongside Hels
Sandberg and Clegg Join Nscale Board as 'Stargate Norway' Startup Hits $14.6B Valuation
As demand surges for data centers capable of delivering AI compute at scale, Nscale, a British AI infrastructure company backed by Nvidia, has reached a valuation of $14.6 billion. That positions it as one of Europe's newest decacorns, alongside Hels
 Runway's $5.3B Valuation Challenges Google as Video AI Surpasses Language
While most AI giants have poured billions into language models, generative AI video startup Runway is charging ahead on a very different path. According to TechCrunch, this young company—founded by art school graduates—has now reached a valuation of
Runway's $5.3B Valuation Challenges Google as Video AI Surpasses Language
While most AI giants have poured billions into language models, generative AI video startup Runway is charging ahead on a very different path. According to TechCrunch, this young company—founded by art school graduates—has now reached a valuation of

Discover the 2026 best AI pregnancy copilots for safe, personalized trimester-by-trimester workout and nutrition plans. Get top-rated, curated recommendations with free vs paid comparisons and real-world insights. Unlock your healthiest pregnancy journey with XIX.AI's expert guide. Explore now.
10 tools
xix.ai

Discover the 2026 best free undetectable AI writers at XIX.AI. Our top-rated, curated list helps you transform robotic drafts into natural, human-like prose. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock your AI writing edge today.
10 tools
xix.ai

2026 Latest: Discover the best AI art generators for short-drama storyboards. Our curated list features top-rated tools for creating compelling fantasy and urban romance characters. Compare free vs paid options, see real-world test results, and find your perfect creative partner. Get weekly updated rankings and expert insights from XIX.AI. Start visualizing your story today!
10 tools
xix.ai

Discover the 2026 best AI scripting tools for radio & podcasting at XIX.AI. Our curated, top-rated list features powerful, game-changing solutions to write engaging audio commercials fast. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock your creative edge today!
10 tools
xix.ai

Discover the 2026 best AI contract review software on XIX.AI. Our top-rated, curated list features powerful tools that instantly spot legal loopholes and compliance risks. Compare free vs paid options with real-world tests and weekly updated rankings. Find your game-changing solution for secure, efficient contract analysis. Explore the definitive guide now.
10 tools
xix.ai

Discover the 2026 best AI anime generators for donghua. Our top-rated, curated list features powerful tools to create stunning web novel characters and comic avatars. Compare free vs paid options with real-world tests. Find your perfect creative partner and bring your stories to life today at XIX.AI.
10 tools
xix.ai













