
















 首页
首页阿里巴巴开源的 问云 人工智能模型在推理方面打破纪录
阿里巴巴的 Qwen 团队发布了新版开源推理人工智能模型,并展示了出色的基准测试结果。
Introducing Qwen3-235B-A22B-Thinking-2507.在过去的三个月里,Qwen 团队一直在大力提升模型的 "思考能力",努力提高推理过程的质量和深度。
其结果是,该模型在逻辑推理、复杂数学、科学挑战和高级编码等要求最苛刻的领域真正大放异彩。在通常需要人类专业知识的领域,最新的 Qwen 模型为开源人工智能树立了新的标杆。
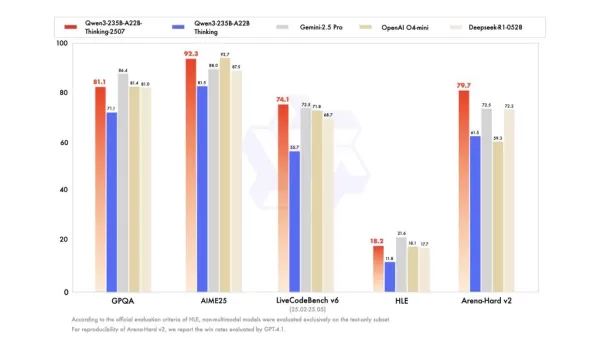
在推理基准测试中,Qwen 最新的开源人工智能模型在 AIME25 中获得 92.3 分,在 LiveCodeBench v6 编码测试中获得 74.1 分。它在更广泛的能力评估中也表现出色,在Arena-Hard v2(一项评估与人类偏好一致性的指标)上获得了79.7分。
从根本上说,这是一个来自 Qwen 团队的大规模推理人工智能模型,共有 2,350 亿个参数。不过,它采用了专家混合(MoE)架构,这意味着在任何特定时间,只有这些参数的一个子集--约 220 亿个参数--处于活动状态。可以把它想象成一个由 128 名专家组成的庞大团队,随时待命,但只有负责特定任务的前八名专家在实际工作。
Qwen 的突出特点之一是其超强的内存容量。Qwen 的开源人工智能推理模型原生支持 262,144 个词块的上下文长度,为需要理解大量信息的任务提供了显著优势。
对于开发者和爱好者来说,Qwen 团队简化了入门流程。该模型可在 Hugging Face 上访问,并可使用 sglang 或 vllm 等工具进行部署,以建立个人 API 端点。该团队还强调,他们的 Qwen-Agent 框架是利用该模型的工具调用功能的最佳方法。
为使这一开源人工智能推理模型达到最佳性能,Qwen 团队提出了几项建议。他们建议标准任务的输出长度为 32,768 个标记左右,但对于高度复杂的问题,可将输出长度增加到 81,920 个标记,让人工智能有足够的空间 "思考"。他们还建议在提示中使用明确的说明,例如要求对数学问题采用 "逐步推理 "的方法,以获得最精确、最有条理的回答。
新 Qwen 模型的推出提供了一个强大的开源推理人工智能,能够与领先的专有模型竞争,尤其是在应对复杂、智力要求高的挑战方面。我们将拭目以待开发者社区利用这项技术创造出怎样的成果。
另请参见人工智能行动计划:美国的领导地位必须 "不受挑战
想从行业专家那里加深对人工智能和大数据的了解?参加在阿姆斯特丹、加利福尼亚和伦敦举办的人工智能与大数据博览会。这一综合性活动将与智能自动化大会(Intelligent Automation Conference)、BlockX、数字转型周(Digital Transformation Week)和网络安全与云博览会(Cyber Security & Cloud Expo)等其他重要会议同时举行。
点击此处了解由 TechForge 提供支持的更多即将举行的企业技术活动和网络研讨会。
相关文章
 WordPress.com 现已支持 AI 助手撰写和发布文章,还有更多功能
广受欢迎的网站托管和发布平台 WordPress.com 现已开始引入人工智能助手——这一举措或将重塑网络的呈现方式。该公司于周五宣布,将允许人工智能助手在用户网站上起草、编辑和发布内容,同时还能管理评论、更新和修正元数据,并通过标签和分类对内容进行整理。所有这些操作均通过一个界面进行控制,网站所有者只需使用自然语言命令说明其需求即可。凭借这些新功能,网站几乎可以完全由人工指导的AI代理来创建和运
Kakao Mobility 概述了面向物理人工智能的 L4 级自动驾驶路线图
Kakao Mobility 计划内部自主研发 L4 级自动驾驶技术,作为其物理人工智能战略的一部分。在首尔COEX举行的2026世界IT展上,Kakao Mobility副总裁兼物理AI部门负责人金镇奎(Kim Jin-kyu)介绍了该路线图。他的演讲聚焦于物理AI时代基于出行平台构建的自动驾驶服务。据韩联社报道,这场题为“超越构想,付诸行动:AI驱动现实”的活动汇聚了来自17个国家的460
巴里·迪勒:随着通用人工智能的临近,对萨姆·阿尔特曼的信任已无关紧要
尽管近期有报道暗示相反的情况,但亿万富翁、媒体大亨巴里·迪勒并不认为OpenAI首席执行官山姆·阿尔特曼不可信。本周,迪勒在《华尔街日报》举办的“万物未来”峰会上发表演讲时,为阿尔特曼进行了辩护。此前,阿尔特曼曾遭到一些前同事和董事会成员的指责,称其有时会采取操纵和欺骗手段。作为阿尔特曼的朋友,迪勒是在回答一个关于人们是否应该信任阿尔特曼以确保人工智能造福人类的问题时作出上述表态的。具体而言,提问
相关专题推荐
商业
WordPress.com 现已支持 AI 助手撰写和发布文章,还有更多功能
广受欢迎的网站托管和发布平台 WordPress.com 现已开始引入人工智能助手——这一举措或将重塑网络的呈现方式。该公司于周五宣布,将允许人工智能助手在用户网站上起草、编辑和发布内容,同时还能管理评论、更新和修正元数据,并通过标签和分类对内容进行整理。所有这些操作均通过一个界面进行控制,网站所有者只需使用自然语言命令说明其需求即可。凭借这些新功能,网站几乎可以完全由人工指导的AI代理来创建和运
Kakao Mobility 概述了面向物理人工智能的 L4 级自动驾驶路线图
Kakao Mobility 计划内部自主研发 L4 级自动驾驶技术,作为其物理人工智能战略的一部分。在首尔COEX举行的2026世界IT展上,Kakao Mobility副总裁兼物理AI部门负责人金镇奎(Kim Jin-kyu)介绍了该路线图。他的演讲聚焦于物理AI时代基于出行平台构建的自动驾驶服务。据韩联社报道,这场题为“超越构想,付诸行动:AI驱动现实”的活动汇聚了来自17个国家的460
巴里·迪勒:随着通用人工智能的临近,对萨姆·阿尔特曼的信任已无关紧要
尽管近期有报道暗示相反的情况,但亿万富翁、媒体大亨巴里·迪勒并不认为OpenAI首席执行官山姆·阿尔特曼不可信。本周,迪勒在《华尔街日报》举办的“万物未来”峰会上发表演讲时,为阿尔特曼进行了辩护。此前,阿尔特曼曾遭到一些前同事和董事会成员的指责,称其有时会采取操纵和欺骗手段。作为阿尔特曼的朋友,迪勒是在回答一个关于人们是否应该信任阿尔特曼以确保人工智能造福人类的问题时作出上述表态的。具体而言,提问
相关专题推荐
商业
 最佳 AI 费用追踪工具:扫描收据并自动分类企业开支
最佳 AI 费用追踪工具:扫描收据并自动分类企业开支
2026年最新最佳AI报销管理工具:广受好评的解决方案,可自动扫描收据并分类企业支出。探索这些功能强大、颠覆传统的解决方案,助您轻松管理报销、精准追踪财务并简化合规流程。我们精心整理并每周更新的免费与付费选项对比指南,助您找到最适合的工具。通过XIX.AI的专家精选,释放您的AI优势。
 10 个工具
10 个工具
 xix.ai
商业
最佳人工智能招聘工具:筛选简历并自动安排候选人面试
xix.ai
商业
最佳人工智能招聘工具:筛选简历并自动安排候选人面试
在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
10 个工具
xix.ai
生产率
AI个人健康与专注力教练:缓解倦怠,提升精神能量
立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai
聊天机器人
备受好评的AI浪漫聊天机器人:凭借稳定的个性建立长期关系
探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai
教育与学习
最佳AI数据科学导师:精通SQL、Pandas及机器学习工作流程
探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai
聊天机器人
最佳AI调情与对话训练工具:实时提升社交魅力与自信
在 XIX.AI 上探索 2026 年最优秀的 AI 调情与对话训练工具。我们精心挑选的高评分工具助您实时提升社交魅力与自信。探索这些必试的、颠覆性的工具,查看免费版与付费版的对比,并了解每周更新的排行榜。立即开启您的社交优势。
10 个工具
xix.ai

 评论 (1)
0/500
评论 (1)
0/500
![HaroldMoore]()
AlibabaのオープンソースAIがまたすごい成果を出しましたね!Qwenの推論能力、本当に進化が早い。最近は色んな企業が自社モデルを公開して競争が激しいけど、オープンソースでここまでできると、商用モデルもプレッシャー感じるんじゃないかな?個人的には、こういう技術がもっと手軽に使えるようになったら、普段の仕事の効率も上がりそうで楽しみです✨
阿里巴巴的 Qwen 团队发布了新版开源推理人工智能模型,并展示了出色的基准测试结果。
Introducing Qwen3-235B-A22B-Thinking-2507.在过去的三个月里,Qwen 团队一直在大力提升模型的 "思考能力",努力提高推理过程的质量和深度。
其结果是,该模型在逻辑推理、复杂数学、科学挑战和高级编码等要求最苛刻的领域真正大放异彩。在通常需要人类专业知识的领域,最新的 Qwen 模型为开源人工智能树立了新的标杆。
在推理基准测试中,Qwen 最新的开源人工智能模型在 AIME25 中获得 92.3 分,在 LiveCodeBench v6 编码测试中获得 74.1 分。它在更广泛的能力评估中也表现出色,在Arena-Hard v2(一项评估与人类偏好一致性的指标)上获得了79.7分。
从根本上说,这是一个来自 Qwen 团队的大规模推理人工智能模型,共有 2,350 亿个参数。不过,它采用了专家混合(MoE)架构,这意味着在任何特定时间,只有这些参数的一个子集--约 220 亿个参数--处于活动状态。可以把它想象成一个由 128 名专家组成的庞大团队,随时待命,但只有负责特定任务的前八名专家在实际工作。
Qwen 的突出特点之一是其超强的内存容量。Qwen 的开源人工智能推理模型原生支持 262,144 个词块的上下文长度,为需要理解大量信息的任务提供了显著优势。
对于开发者和爱好者来说,Qwen 团队简化了入门流程。该模型可在 Hugging Face 上访问,并可使用 sglang 或 vllm 等工具进行部署,以建立个人 API 端点。该团队还强调,他们的 Qwen-Agent 框架是利用该模型的工具调用功能的最佳方法。
为使这一开源人工智能推理模型达到最佳性能,Qwen 团队提出了几项建议。他们建议标准任务的输出长度为 32,768 个标记左右,但对于高度复杂的问题,可将输出长度增加到 81,920 个标记,让人工智能有足够的空间 "思考"。他们还建议在提示中使用明确的说明,例如要求对数学问题采用 "逐步推理 "的方法,以获得最精确、最有条理的回答。
新 Qwen 模型的推出提供了一个强大的开源推理人工智能,能够与领先的专有模型竞争,尤其是在应对复杂、智力要求高的挑战方面。我们将拭目以待开发者社区利用这项技术创造出怎样的成果。
另请参见人工智能行动计划:美国的领导地位必须 "不受挑战
想从行业专家那里加深对人工智能和大数据的了解?参加在阿姆斯特丹、加利福尼亚和伦敦举办的人工智能与大数据博览会。这一综合性活动将与智能自动化大会(Intelligent Automation Conference)、BlockX、数字转型周(Digital Transformation Week)和网络安全与云博览会(Cyber Security & Cloud Expo)等其他重要会议同时举行。
点击此处了解由 TechForge 提供支持的更多即将举行的企业技术活动和网络研讨会。










 WordPress.com 现已支持 AI 助手撰写和发布文章,还有更多功能
广受欢迎的网站托管和发布平台 WordPress.com 现已开始引入人工智能助手——这一举措或将重塑网络的呈现方式。该公司于周五宣布,将允许人工智能助手在用户网站上起草、编辑和发布内容,同时还能管理评论、更新和修正元数据,并通过标签和分类对内容进行整理。所有这些操作均通过一个界面进行控制,网站所有者只需使用自然语言命令说明其需求即可。凭借这些新功能,网站几乎可以完全由人工指导的AI代理来创建和运
Kakao Mobility 概述了面向物理人工智能的 L4 级自动驾驶路线图
Kakao Mobility 计划内部自主研发 L4 级自动驾驶技术,作为其物理人工智能战略的一部分。在首尔COEX举行的2026世界IT展上,Kakao Mobility副总裁兼物理AI部门负责人金镇奎(Kim Jin-kyu)介绍了该路线图。他的演讲聚焦于物理AI时代基于出行平台构建的自动驾驶服务。据韩联社报道,这场题为“超越构想,付诸行动:AI驱动现实”的活动汇聚了来自17个国家的460
WordPress.com 现已支持 AI 助手撰写和发布文章,还有更多功能
广受欢迎的网站托管和发布平台 WordPress.com 现已开始引入人工智能助手——这一举措或将重塑网络的呈现方式。该公司于周五宣布,将允许人工智能助手在用户网站上起草、编辑和发布内容,同时还能管理评论、更新和修正元数据,并通过标签和分类对内容进行整理。所有这些操作均通过一个界面进行控制,网站所有者只需使用自然语言命令说明其需求即可。凭借这些新功能,网站几乎可以完全由人工指导的AI代理来创建和运
Kakao Mobility 概述了面向物理人工智能的 L4 级自动驾驶路线图
Kakao Mobility 计划内部自主研发 L4 级自动驾驶技术,作为其物理人工智能战略的一部分。在首尔COEX举行的2026世界IT展上,Kakao Mobility副总裁兼物理AI部门负责人金镇奎(Kim Jin-kyu)介绍了该路线图。他的演讲聚焦于物理AI时代基于出行平台构建的自动驾驶服务。据韩联社报道,这场题为“超越构想,付诸行动:AI驱动现实”的活动汇聚了来自17个国家的460
 巴里·迪勒:随着通用人工智能的临近,对萨姆·阿尔特曼的信任已无关紧要
尽管近期有报道暗示相反的情况,但亿万富翁、媒体大亨巴里·迪勒并不认为OpenAI首席执行官山姆·阿尔特曼不可信。本周,迪勒在《华尔街日报》举办的“万物未来”峰会上发表演讲时,为阿尔特曼进行了辩护。此前,阿尔特曼曾遭到一些前同事和董事会成员的指责,称其有时会采取操纵和欺骗手段。作为阿尔特曼的朋友,迪勒是在回答一个关于人们是否应该信任阿尔特曼以确保人工智能造福人类的问题时作出上述表态的。具体而言,提问
巴里·迪勒:随着通用人工智能的临近,对萨姆·阿尔特曼的信任已无关紧要
尽管近期有报道暗示相反的情况,但亿万富翁、媒体大亨巴里·迪勒并不认为OpenAI首席执行官山姆·阿尔特曼不可信。本周,迪勒在《华尔街日报》举办的“万物未来”峰会上发表演讲时,为阿尔特曼进行了辩护。此前,阿尔特曼曾遭到一些前同事和董事会成员的指责,称其有时会采取操纵和欺骗手段。作为阿尔特曼的朋友,迪勒是在回答一个关于人们是否应该信任阿尔特曼以确保人工智能造福人类的问题时作出上述表态的。具体而言,提问

2026年最新最佳AI报销管理工具:广受好评的解决方案,可自动扫描收据并分类企业支出。探索这些功能强大、颠覆传统的解决方案,助您轻松管理报销、精准追踪财务并简化合规流程。我们精心整理并每周更新的免费与付费选项对比指南,助您找到最适合的工具。通过XIX.AI的专家精选,释放您的AI优势。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
10 个工具
xix.ai

立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai

探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai

探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最优秀的 AI 调情与对话训练工具。我们精心挑选的高评分工具助您实时提升社交魅力与自信。探索这些必试的、颠覆性的工具,查看免费版与付费版的对比,并了解每周更新的排行榜。立即开启您的社交优势。
10 个工具
xix.ai

AlibabaのオープンソースAIがまたすごい成果を出しましたね!Qwenの推論能力、本当に進化が早い。最近は色んな企業が自社モデルを公開して競争が激しいけど、オープンソースでここまでできると、商用モデルもプレッシャー感じるんじゃないかな?個人的には、こういう技術がもっと手軽に使えるようになったら、普段の仕事の効率も上がりそうで楽しみです✨













