
















 首頁
首頁RL服務革命推動自主系統新紀元
強化學習始終是人工智慧的前沿領域,充滿潛力卻常受限於利基應用。它驅動著人工智慧最令人驚嘆的成就——從精通圍棋、星海爭霸等複雜遊戲,到優化精密供應鏈。然而其應用主要局限於大型科技公司與資源充沛的實驗室,高昂的複雜度與成本始終是阻礙。 一場變革性的轉變已然浮現,即將如雲端運算革新數據基礎設施般,推動強化學習的普及化。這項新興範式正是「強化學習即服務」(RLaaS)。正如AWS重新定義了運算資源的獲取方式,RLaaS將徹底改變企業整合與運用先進決策型人工智慧的模式。
理解強化學習即服務
強化學習的核心本質是機器學習範式,智能代理透過與環境直接互動學習最佳行為模式。代理透過採取行動並接收獎勵或懲罰反饋,逐步發展出最大化成功率的策略。其基礎概念與動物訓練原理相仿:獎勵期望行為可促進其重複發生。強化學習系統同樣遵循試錯原則運作,但憑藉龐大運算能力與數據驅動實現規模化應用。
強化學習即服務(RLaaS)將這項強大能力搬上雲端。它消除了傳統強化學習系統開發所需的三大障礙:龐大基礎設施投資、專業工程技術及深厚領域知識。如同隨需應變的雲端服務提供伺服器與資料庫,RLaaS以託管平台形式交付強化學習的核心要素,包含模擬環境建置工具、大規模模型訓練能力,以及將生成的AI策略直接部署至實際應用場景的功能。 簡言之,RLaaS將高度技術化的流程簡化為更易操作的工作流:定義問題,讓平台管理複雜的執行環節。
強化學習擴展的挑戰
要理解RLaaS的價值,必須先釐清強化學習擴展為何如此困難。相較於從固定歷史數據學習的其他AI方法,強化學習代理人需透過主動探索與動態環境互動來學習。這種試錯過程本質上更為複雜且資源密集。
主要挑戰可歸納為四點:首先,其運算需求驚人龐大。訓練高效能強化學習代理人可能需要數百萬甚至數十億次環境互動,所需的巨量運算能力與時間對多數組織而言難以負擔。其次,訓練過程以不穩定著稱。代理人可能展現令人鼓舞的進展,卻因遺忘先前學習的行為,或利用獎勵系統中的意外捷徑而突然失效,導致荒謬的結果。
第三,傳統強化學習常從零開始。要求智能體在複雜環境中從頭學習精密任務實屬艱鉅挑戰。此方法需精心設計模擬環境,而關鍵在於獎勵函數——打造能精準引導智能體達成目標的獎勵機制,既是科學更是藝術。 最後,建構高保真模擬環境是重大障礙。在機器人或自動系統等應用場景中,模擬環境必須精準反映真實世界的物理特性與條件。模擬環境與真實環境的任何偏差,都可能導致部署時徹底失敗。
推動RLaaS實現的近期突破
何種變革使RLaaS今日得以實現?多項技術與概念的突破性進展共同鋪就了道路。
遷移學習與基礎模型大幅降低了從零開始訓練的需求。類似於微調大型語言模型,現有技術能將某領域的知識轉移至其他領域。RLaaS平台可運用預訓練的智能體,這些智能體理解基本決策原則,從而大幅縮減新專案所需的時間與數據量。
模擬技術取得突破性進展。Isaac Sim與Mujoco等平台已進化為穩健且可擴展的環境。透過領域隨機化等技術,模擬與現實的差距大幅縮小,使RLaaS供應商能提供高品質模擬環境,客戶無需自行建構。
演算法創新使強化學習更具樣本效率與穩定性。近似策略優化(PPO)及分散式行為者-批評者架構等方法,大幅提升訓練的可靠性與可重現性。這些技術已從晦澀的研究概念,轉變為成熟的生產就緒演算法。
雲端基礎設施已兼具強大效能與成本效益。當高性能GPU叢集尚屬耗資數百萬美元的資本支出時,僅大型企業能負擔。如今組織可按需租用此類運算能力,徹底改變了強化學習開發的經濟模式。
最後,人才生態已然擴展。多年大學課程、大量公開研究成果與成熟開源函式庫,共同培育出龐大的強化學習專業人才庫,使相關知識的獲取門檻降至歷史新低。
承諾與現實
強化學習即服務(RLaaS)的興起,透過提供顯著優勢使強化學習得以普及至更廣泛的組織。它免除了對專用內部基礎設施與深厚技術專長的依賴,讓團隊無需巨額前期投資即可進行實驗。基於雲端的擴展性使企業能高效訓練與部署智能代理,僅需支付實際消耗的資源費用。
RLaaS更透過現成工具、模擬環境與API加速創新,簡化從模型訓練到部署的完整強化學習流程。企業得以專注解決獨特問題,無需從零構建複雜系統,將開發週期從數年壓縮至數月甚至數週,使強化學習應用突破遊戲與學術研究的框架。
儘管進展顯著,仍須認知RLaaS未能解決強化學習的所有本質性挑戰。關鍵的獎勵規範任務仍屬使用者責任範疇;即使採用託管服務,成功標準仍需精確定義。 設計不良的獎勵函數仍會導致代理人產生非預期行為——此核心問題常被稱為對齊難題。此外,模擬與現實的落差依然存在:在模擬環境中表現優異的代理人,可能因未預見的物理變數或未建模條件而在真實世界中陷入困境。
核心結論
強化學習從專門研究領域演進為實用工具,標誌著人工智慧的重要成熟階段。正如AWS讓新創企業無需實體伺服器即可打造全球軟體,RLaaS將使工程師無需具備強化學習博士學位,也能創造適應性自主系統。此技術大幅降低入門門檻,使創新焦點從建構基礎設施轉向解決應用特定挑戰。 強化學習的終極價值不在於擊敗遊戲冠軍,而在於優化現實世界的流程與系統。RLaaS正是釋放此潛能的關鍵工具,將人工智慧最強大的範式之一轉化為現代企業標準化的通用工具。
相關文章
 以文字翻譯聞名的 DeepL,現已進軍語音翻譯領域
以文字翻譯工具聞名的翻譯公司 DeepL,今日推出了一套語音對語音翻譯解決方案,透過客製化應用程式,針對前線工作人員在會議、行動裝置與網路對話,以及群組討論等情境提供支援。 該公司同時推出了一項 API,讓外部開發者與企業能基於 DeepL 的技術,打造適用於呼叫中心等特定情境的解決方案。「在專注於文字翻譯多年後,語音翻譯對我們而言是水到渠成的下一步,」DeepL 執行長 Jarek Kutylo
Talat 的人工智慧會議筆記儲存在您的裝置上,而非雲端
估值達 2.5 億美元的人工智慧筆記應用程式 Granola,已在科技創辦人和風險投資人之間引起熱烈迴響。但有位開發者認為,市場需要一款更注重隱私、完全在本地運行的替代方案,且僅需支付一次費用,無需訂閱。這項願景催生了一款名為 Talat 的新 Mac 應用程式。來自英國約克郡、自稱電腦宅男的尼克·佩恩(Nick Payne)表示,開發這款本地化 AI 筆記應用程式的靈感,很大程度上源自一連串幸運
全新榮威i6以65.9萬人民幣上市,搭載高通驍龍8155處理器與「斗寶」大模型
上汽榮威今日推出全新榮威i6,這款緊湊型轎車全面採用了榮威D7的設計語言。其獨特的大型直立式水箱護罩與橫向環形燈帶貫穿車頭,營造出強烈的科技感與視覺寬度。 車尾部分,上翹的鴨尾式尾翼與全寬尾燈相得益彰,賦予整車更顯活力的年輕氣息。全新榮威i6車身長4767毫米、寬1828毫米、高1498毫米,軸距為2755毫米。 得益於寬敞的車內空間,它躋身A+級轎車之列,在後排頭部空間與膝部空間方面具備顯著優
相關專題推薦
寫作
以文字翻譯聞名的 DeepL,現已進軍語音翻譯領域
以文字翻譯工具聞名的翻譯公司 DeepL,今日推出了一套語音對語音翻譯解決方案,透過客製化應用程式,針對前線工作人員在會議、行動裝置與網路對話,以及群組討論等情境提供支援。 該公司同時推出了一項 API,讓外部開發者與企業能基於 DeepL 的技術,打造適用於呼叫中心等特定情境的解決方案。「在專注於文字翻譯多年後,語音翻譯對我們而言是水到渠成的下一步,」DeepL 執行長 Jarek Kutylo
Talat 的人工智慧會議筆記儲存在您的裝置上,而非雲端
估值達 2.5 億美元的人工智慧筆記應用程式 Granola,已在科技創辦人和風險投資人之間引起熱烈迴響。但有位開發者認為,市場需要一款更注重隱私、完全在本地運行的替代方案,且僅需支付一次費用,無需訂閱。這項願景催生了一款名為 Talat 的新 Mac 應用程式。來自英國約克郡、自稱電腦宅男的尼克·佩恩(Nick Payne)表示,開發這款本地化 AI 筆記應用程式的靈感,很大程度上源自一連串幸運
全新榮威i6以65.9萬人民幣上市,搭載高通驍龍8155處理器與「斗寶」大模型
上汽榮威今日推出全新榮威i6,這款緊湊型轎車全面採用了榮威D7的設計語言。其獨特的大型直立式水箱護罩與橫向環形燈帶貫穿車頭,營造出強烈的科技感與視覺寬度。 車尾部分,上翹的鴨尾式尾翼與全寬尾燈相得益彰,賦予整車更顯活力的年輕氣息。全新榮威i6車身長4767毫米、寬1828毫米、高1498毫米,軸距為2755毫米。 得益於寬敞的車內空間,它躋身A+級轎車之列,在後排頭部空間與膝部空間方面具備顯著優
相關專題推薦
寫作
 頂尖 AI 角色設定生成工具:創造一致的角色動機與致命弱點
頂尖 AI 角色設定生成工具:創造一致的角色動機與致命弱點
探索 2026 年最優秀的 AI 角色設定生成工具,打造立體鮮明的角色。XIX.AI 精心整理的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具能生成一貫的動機與致命缺陷。透過實際測試,比較免費與付費選項的差異。立即釋放您的說故事潛能。
 10 個工具
10 個工具
 xix.ai
商業
頂尖 AI 定價優化軟體:追蹤競爭對手並自動調整商店價格
xix.ai
商業
頂尖 AI 定價優化軟體:追蹤競爭對手並自動調整商店價格
立即在 XIX.AI 探索 2026 年最佳 AI 定價優化軟體。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具不僅能追蹤競爭對手,還能自動調整您的商店價格,以實現利潤最大化。透過實際測試,比較免費與付費方案的差異。立即掌握您的定價優勢。
10 個工具
xix.ai
代碼
最佳 AI 程式碼審查工具:自動化確保程式碼整潔度,並重構舊版儲存庫檔案
立即在 XIX.AI 探索 2026 年最佳 AI 程式碼審查工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,可自動確保程式碼符合規範,並重構舊版儲存庫檔案。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即掌握您的 AI 競爭優勢。
10 個工具
xix.ai
文字轉語音
專為閱讀障礙設計的頂尖 AI 語音合成應用程式:協助學生提升學習與閱讀效率
探索 2026 年最新精選、專為閱讀障礙者設計的頂級 AI 語音合成(TTS)應用程式。我們的專家評比將免費與付費工具進行對照,重點介紹能提升閱讀效率與學習成效的強大功能。發掘這些必試且能帶來革命性改變的解決方案,釋放學生的潛能。立即前往 XIX.AI 展開您的探索之旅。
10 個工具
xix.ai
漫畫創作
少年漫畫頂尖 AI 生成器:打造高張力動作場面與能量特效
立即前往 XIX.AI,探索 2026 年最優秀的少年漫畫 AI 生成工具。我們精心挑選的頂級清單,匯集了能打造高張力動作場面與動態能量特效的強大工具。透過實際測試,比較免費與付費選項的差異。釋放您的創作潛能,今天就開始打造史詩級漫畫吧!
15 個工具
xix.ai
商業
最佳 AI 支出追蹤工具:掃描收據並自動分類公司開支
2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
10 個工具
xix.ai

 評論 (3)
0/500
評論 (3)
0/500
![ElijahCollins]()
This article really highlights how RL is finally moving beyond just beating games. The shift towards practical services could be huge for robotics and automation. Exciting times ahead! 🤖
![CharlesRoberts]()
Cet article montre que l'apprentissage par renforcement devient enfin pratique, pas juste des expériences en labo. Perso je me demande toujours : c'est bien beau de gérer des voitures autonomes, mais la partie éthique, qui la code vraiment ? 😅 Le monde sera-t-il piloté par des agents RL avant qu'on ait fini d'écrire les règles ?
![GaryWalker]()
RLなんて結局ゲームかロボットの限定的な分野だけかと思ってたけど、サービスとして提供される時代が来るとは!🤔 でも、これで自律ドローンの配送とかが当たり前になるんだろうな…便利だけど少し怖い気もするわ。
強化學習始終是人工智慧的前沿領域,充滿潛力卻常受限於利基應用。它驅動著人工智慧最令人驚嘆的成就——從精通圍棋、星海爭霸等複雜遊戲,到優化精密供應鏈。然而其應用主要局限於大型科技公司與資源充沛的實驗室,高昂的複雜度與成本始終是阻礙。 一場變革性的轉變已然浮現,即將如雲端運算革新數據基礎設施般,推動強化學習的普及化。這項新興範式正是「強化學習即服務」(RLaaS)。正如AWS重新定義了運算資源的獲取方式,RLaaS將徹底改變企業整合與運用先進決策型人工智慧的模式。
理解強化學習即服務
強化學習的核心本質是機器學習範式,智能代理透過與環境直接互動學習最佳行為模式。代理透過採取行動並接收獎勵或懲罰反饋,逐步發展出最大化成功率的策略。其基礎概念與動物訓練原理相仿:獎勵期望行為可促進其重複發生。強化學習系統同樣遵循試錯原則運作,但憑藉龐大運算能力與數據驅動實現規模化應用。
強化學習即服務(RLaaS)將這項強大能力搬上雲端。它消除了傳統強化學習系統開發所需的三大障礙:龐大基礎設施投資、專業工程技術及深厚領域知識。如同隨需應變的雲端服務提供伺服器與資料庫,RLaaS以託管平台形式交付強化學習的核心要素,包含模擬環境建置工具、大規模模型訓練能力,以及將生成的AI策略直接部署至實際應用場景的功能。 簡言之,RLaaS將高度技術化的流程簡化為更易操作的工作流:定義問題,讓平台管理複雜的執行環節。
強化學習擴展的挑戰
要理解RLaaS的價值,必須先釐清強化學習擴展為何如此困難。相較於從固定歷史數據學習的其他AI方法,強化學習代理人需透過主動探索與動態環境互動來學習。這種試錯過程本質上更為複雜且資源密集。
主要挑戰可歸納為四點:首先,其運算需求驚人龐大。訓練高效能強化學習代理人可能需要數百萬甚至數十億次環境互動,所需的巨量運算能力與時間對多數組織而言難以負擔。其次,訓練過程以不穩定著稱。代理人可能展現令人鼓舞的進展,卻因遺忘先前學習的行為,或利用獎勵系統中的意外捷徑而突然失效,導致荒謬的結果。
第三,傳統強化學習常從零開始。要求智能體在複雜環境中從頭學習精密任務實屬艱鉅挑戰。此方法需精心設計模擬環境,而關鍵在於獎勵函數——打造能精準引導智能體達成目標的獎勵機制,既是科學更是藝術。 最後,建構高保真模擬環境是重大障礙。在機器人或自動系統等應用場景中,模擬環境必須精準反映真實世界的物理特性與條件。模擬環境與真實環境的任何偏差,都可能導致部署時徹底失敗。
推動RLaaS實現的近期突破
何種變革使RLaaS今日得以實現?多項技術與概念的突破性進展共同鋪就了道路。
遷移學習與基礎模型大幅降低了從零開始訓練的需求。類似於微調大型語言模型,現有技術能將某領域的知識轉移至其他領域。RLaaS平台可運用預訓練的智能體,這些智能體理解基本決策原則,從而大幅縮減新專案所需的時間與數據量。
模擬技術取得突破性進展。Isaac Sim與Mujoco等平台已進化為穩健且可擴展的環境。透過領域隨機化等技術,模擬與現實的差距大幅縮小,使RLaaS供應商能提供高品質模擬環境,客戶無需自行建構。
演算法創新使強化學習更具樣本效率與穩定性。近似策略優化(PPO)及分散式行為者-批評者架構等方法,大幅提升訓練的可靠性與可重現性。這些技術已從晦澀的研究概念,轉變為成熟的生產就緒演算法。
雲端基礎設施已兼具強大效能與成本效益。當高性能GPU叢集尚屬耗資數百萬美元的資本支出時,僅大型企業能負擔。如今組織可按需租用此類運算能力,徹底改變了強化學習開發的經濟模式。
最後,人才生態已然擴展。多年大學課程、大量公開研究成果與成熟開源函式庫,共同培育出龐大的強化學習專業人才庫,使相關知識的獲取門檻降至歷史新低。
承諾與現實
強化學習即服務(RLaaS)的興起,透過提供顯著優勢使強化學習得以普及至更廣泛的組織。它免除了對專用內部基礎設施與深厚技術專長的依賴,讓團隊無需巨額前期投資即可進行實驗。基於雲端的擴展性使企業能高效訓練與部署智能代理,僅需支付實際消耗的資源費用。
RLaaS更透過現成工具、模擬環境與API加速創新,簡化從模型訓練到部署的完整強化學習流程。企業得以專注解決獨特問題,無需從零構建複雜系統,將開發週期從數年壓縮至數月甚至數週,使強化學習應用突破遊戲與學術研究的框架。
儘管進展顯著,仍須認知RLaaS未能解決強化學習的所有本質性挑戰。關鍵的獎勵規範任務仍屬使用者責任範疇;即使採用託管服務,成功標準仍需精確定義。 設計不良的獎勵函數仍會導致代理人產生非預期行為——此核心問題常被稱為對齊難題。此外,模擬與現實的落差依然存在:在模擬環境中表現優異的代理人,可能因未預見的物理變數或未建模條件而在真實世界中陷入困境。
核心結論
強化學習從專門研究領域演進為實用工具,標誌著人工智慧的重要成熟階段。正如AWS讓新創企業無需實體伺服器即可打造全球軟體,RLaaS將使工程師無需具備強化學習博士學位,也能創造適應性自主系統。此技術大幅降低入門門檻,使創新焦點從建構基礎設施轉向解決應用特定挑戰。 強化學習的終極價值不在於擊敗遊戲冠軍,而在於優化現實世界的流程與系統。RLaaS正是釋放此潛能的關鍵工具,將人工智慧最強大的範式之一轉化為現代企業標準化的通用工具。










 以文字翻譯聞名的 DeepL,現已進軍語音翻譯領域
以文字翻譯工具聞名的翻譯公司 DeepL,今日推出了一套語音對語音翻譯解決方案,透過客製化應用程式,針對前線工作人員在會議、行動裝置與網路對話,以及群組討論等情境提供支援。 該公司同時推出了一項 API,讓外部開發者與企業能基於 DeepL 的技術,打造適用於呼叫中心等特定情境的解決方案。「在專注於文字翻譯多年後,語音翻譯對我們而言是水到渠成的下一步,」DeepL 執行長 Jarek Kutylo
以文字翻譯聞名的 DeepL,現已進軍語音翻譯領域
以文字翻譯工具聞名的翻譯公司 DeepL,今日推出了一套語音對語音翻譯解決方案,透過客製化應用程式,針對前線工作人員在會議、行動裝置與網路對話,以及群組討論等情境提供支援。 該公司同時推出了一項 API,讓外部開發者與企業能基於 DeepL 的技術,打造適用於呼叫中心等特定情境的解決方案。「在專注於文字翻譯多年後,語音翻譯對我們而言是水到渠成的下一步,」DeepL 執行長 Jarek Kutylo
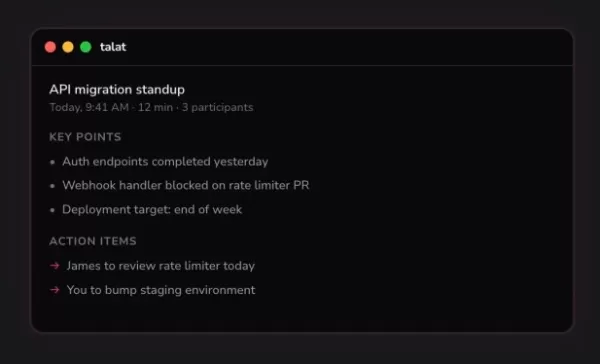 Talat 的人工智慧會議筆記儲存在您的裝置上,而非雲端
估值達 2.5 億美元的人工智慧筆記應用程式 Granola,已在科技創辦人和風險投資人之間引起熱烈迴響。但有位開發者認為,市場需要一款更注重隱私、完全在本地運行的替代方案,且僅需支付一次費用,無需訂閱。這項願景催生了一款名為 Talat 的新 Mac 應用程式。來自英國約克郡、自稱電腦宅男的尼克·佩恩(Nick Payne)表示,開發這款本地化 AI 筆記應用程式的靈感,很大程度上源自一連串幸運
Talat 的人工智慧會議筆記儲存在您的裝置上,而非雲端
估值達 2.5 億美元的人工智慧筆記應用程式 Granola,已在科技創辦人和風險投資人之間引起熱烈迴響。但有位開發者認為,市場需要一款更注重隱私、完全在本地運行的替代方案,且僅需支付一次費用,無需訂閱。這項願景催生了一款名為 Talat 的新 Mac 應用程式。來自英國約克郡、自稱電腦宅男的尼克·佩恩(Nick Payne)表示,開發這款本地化 AI 筆記應用程式的靈感,很大程度上源自一連串幸運
 全新榮威i6以65.9萬人民幣上市,搭載高通驍龍8155處理器與「斗寶」大模型
上汽榮威今日推出全新榮威i6,這款緊湊型轎車全面採用了榮威D7的設計語言。其獨特的大型直立式水箱護罩與橫向環形燈帶貫穿車頭,營造出強烈的科技感與視覺寬度。 車尾部分,上翹的鴨尾式尾翼與全寬尾燈相得益彰,賦予整車更顯活力的年輕氣息。全新榮威i6車身長4767毫米、寬1828毫米、高1498毫米,軸距為2755毫米。 得益於寬敞的車內空間,它躋身A+級轎車之列,在後排頭部空間與膝部空間方面具備顯著優
全新榮威i6以65.9萬人民幣上市,搭載高通驍龍8155處理器與「斗寶」大模型
上汽榮威今日推出全新榮威i6,這款緊湊型轎車全面採用了榮威D7的設計語言。其獨特的大型直立式水箱護罩與橫向環形燈帶貫穿車頭,營造出強烈的科技感與視覺寬度。 車尾部分,上翹的鴨尾式尾翼與全寬尾燈相得益彰,賦予整車更顯活力的年輕氣息。全新榮威i6車身長4767毫米、寬1828毫米、高1498毫米,軸距為2755毫米。 得益於寬敞的車內空間,它躋身A+級轎車之列,在後排頭部空間與膝部空間方面具備顯著優

探索 2026 年最優秀的 AI 角色設定生成工具,打造立體鮮明的角色。XIX.AI 精心整理的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具能生成一貫的動機與致命缺陷。透過實際測試,比較免費與付費選項的差異。立即釋放您的說故事潛能。
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 定價優化軟體。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具不僅能追蹤競爭對手,還能自動調整您的商店價格,以實現利潤最大化。透過實際測試,比較免費與付費方案的差異。立即掌握您的定價優勢。
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 程式碼審查工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,可自動確保程式碼符合規範,並重構舊版儲存庫檔案。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即掌握您的 AI 競爭優勢。
10 個工具
xix.ai

探索 2026 年最新精選、專為閱讀障礙者設計的頂級 AI 語音合成(TTS)應用程式。我們的專家評比將免費與付費工具進行對照,重點介紹能提升閱讀效率與學習成效的強大功能。發掘這些必試且能帶來革命性改變的解決方案,釋放學生的潛能。立即前往 XIX.AI 展開您的探索之旅。
10 個工具
xix.ai

立即前往 XIX.AI,探索 2026 年最優秀的少年漫畫 AI 生成工具。我們精心挑選的頂級清單,匯集了能打造高張力動作場面與動態能量特效的強大工具。透過實際測試,比較免費與付費選項的差異。釋放您的創作潛能,今天就開始打造史詩級漫畫吧!
15 個工具
xix.ai

2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
10 個工具
xix.ai

This article really highlights how RL is finally moving beyond just beating games. The shift towards practical services could be huge for robotics and automation. Exciting times ahead! 🤖
Cet article montre que l'apprentissage par renforcement devient enfin pratique, pas juste des expériences en labo. Perso je me demande toujours : c'est bien beau de gérer des voitures autonomes, mais la partie éthique, qui la code vraiment ? 😅 Le monde sera-t-il piloté par des agents RL avant qu'on ait fini d'écrire les règles ?
RLなんて結局ゲームかロボットの限定的な分野だけかと思ってたけど、サービスとして提供される時代が来るとは!🤔 でも、これで自律ドローンの配送とかが当たり前になるんだろうな…便利だけど少し怖い気もするわ。













