
















 家
家AIによる検証:知識グラフによるLLMのファクトチェック
人工知能は本当に事実と虚構を区別できるのか?本稿では、事実検証という本質的なタスクにおけるAIの能力と限界について調査する。知識グラフ、グラフ・ニューラル・ネットワーク(GNN)、検索補強世代(RAG)アーキテクチャの応用を中心に、AIによる情報検証能力を向上させるために開発されている革新的な技術を探る。単一クレームの単純な検証から複雑な多面的分析まで、AIがどのように精度を高め、誤った情報の拡散に対抗しているかを検証する。
要点
新しいAIファクトチェックモデルは、存在しない情報源を捏造する傾向など、大きな課題に直面している。
ナレッジグラフは、AIに構造化された情報の枠組みを提供することで、精度を向上させる。
グラフ・ニューラル・ネットワーク(GNN)は、より洗練されたファクトチェックのための高度な推論と関係抽出を促進する。
RAGアーキテクチャは、外部知識を統合することで大規模言語モデルの精度を向上させる。
これらの手法を組み合わせることで、複雑なテキストコンテンツの真実と虚偽を区別するAIの能力を強化することを目的としている。
AIファクトチェックの課題
真実の検証における現在のAIモデルの限界
AIは多くの分野で大きな進歩を遂げているが、情報の真実性を決定的に確認する能力はまだ発展途上である。主な障害は、AIモデルが引用を「幻覚」または捏造し、実際には存在しないソースへの参照を作成する傾向である。

この問題は、事実確認ツールとしての信頼性を根本的に損なう。
大規模言語モデル(LLM)は大きな可能性を示しているが、特に長文や複雑なコンテンツではエラーを起こしやすい。LLMは、微妙な解釈を誤ったり、微妙な虚偽を見落としたり、特定の検証に必要な広範な背景知識を欠いたりすることがある。このような限界のためにモデルの改良が必要になることが多く、誤情報の問題に取り組むためにますます複雑なシステムが必要になる。
AIの役割:単なるコードや科学ではなく、投資
このビデオは、AIの中核は純粋に科学的、技術的なものではなく、非常に有利な投資としての地位によって大きく左右されるという視点を提示している。

この示唆に富む視点は、シリコンバレーや米国経済の大部分はAIの成長に依存しており、投資資本の力学がAI開発の舵取りを頻繁に行っていることを示唆している。このような焦点は、客観的な正確さの追求よりも収益性を優先する可能性がある。AIは主に世界の投資家にとって利益を得るための手段であるため、複雑な文章をファクトチェックする研究の方向性には、金銭的な動機が大きく影響している。AIが真に信頼できる真実の裁定者になるためには、商業的インセンティブと事実の完全性へのコミットメントとの間でバランスを取る必要がある。これは重要な問題を提起している:AIは、ある文章が真実かどうかを確実に判断できるのだろうか?
AIによるファクトチェックの強化知識グラフの役割
知識グラフによる知識の構造化
このビデオは、AIのファクトチェック能力を高める上で、知識グラフの重要性を強調している。

ナレッジグラフは、AIモデルに構造化された相互接続フレームワークを提供し、重要な文脈情報を提供する。様々なエンティティ間の関係をマッピングすることで、これらのグラフは、AIシステムがつながりを照会し、発言の真実性を検証し、過去の正確性を調査することを可能にする。
主な利点は以下の通り:
- データの整理:知識グラフは、事実とその相互関係を体系的に整理し、この情報をAIアルゴリズムが容易に利用できるようにする。
- 推論:相互接続された構造により、AIは論理的推論を実行し、データ内の矛盾を発見することができる。
- 文脈理解:AIは、クレームを取り巻く文脈をより深く、より微妙に理解し、より正確な評価につなげる。
GNNとRAG:ファクトチェック能力の向上
情報源の幻覚のような問題に対抗し、関係性の抽出を改善するために、ビデオはグラフ・ニューラル・ネットワーク(GNNs)と検索拡張世代(RAG)アーキテクチャの統合を提案している。

これらは、個々のデータポイントや単純な関係を検証するために、現在スタートアップ企業が提供している高度なAIモデルである。
- グラフ・ニューラル・ネットワーク:GNNは、グラフとして構造化されたデータを処理するために特別に設計されている。複雑な関係を解読し、高度な推論タスクを実行することに優れている。RAGシステムはソースを幻覚する傾向があるが、GNNはこのようなエラーをある程度軽減することができる。
- 検索拡張世代:RAGシステムは、外部の知識ベースから関連文書やデータを取得することで、AIの情報アクセスを拡大する。この補助的なプロセスは、AIの内部で事前に訓練された知識への依存を減らし、それによって幻覚の頻度を減らす。この戦略は、将来のAI世代のために、知識のギャップに体系的に対処するように設計されている。
LLMによるファクトチェック:OpenAIによるディープリサーチへのディープダイブ
OpenAIのディープリサーチ
発表者は、OpenAIの "Deep Research "というツールを利用した。このツールは、トランスフォーマーやナレッジグラフのような様々なAIモデルの情報を集約し、論理的整合性や歴史的正確性の評価に重点を置いた自動調査を行う。
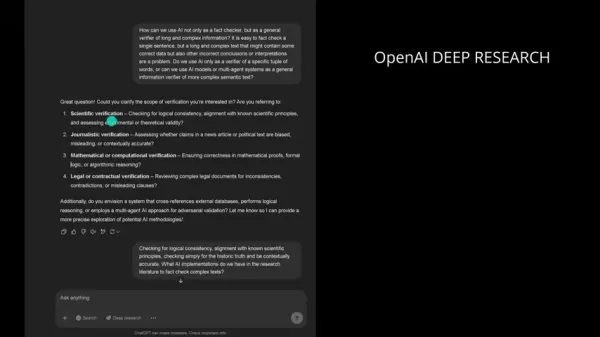
このサービスでは特に、トランスフォーマーに基づくテキストの一貫性検証や、マルチエージェントによる敵対的ファクトチェック手法などのトピックを検索している。
ディープ・リサーチは正確か?
プレゼンターはビデオの中でテストランを行い、AIの検索クエリを注意深く観察し、リクエストが正しく実行されていることを確認した。
デモの間、AIは相当数の古い文献を検索し、要求された最新性の基準に完全に合致していなかった。これは、LLMが予備的な研究データを収集するための貴重なツールである一方で、最終的なレビューと検証の段階では人間の監視が不可欠であることを示す明確な指標となる。
AIによるファクトチェック:メリットとデメリットの比較
長所
大規模なスケーラビリティと高速処理の可能性
膨大なデータセットを分析できる
評価に内在する人間のバイアスを低減できる可能性
人間によるファクトチェック作業を効果的に補強・支援できる
短所
虚偽の情報を生成したり、誤解を招いたりする可能性
既存のトレーニングデータとアルゴリズム設計に基づく固有の限界
現実世界の常識や直感的な理解が一般的に欠如していること
非常に複雑で微妙なテーマを正確に処理することが困難
よくある質問
なぜAIはファクトチェックが苦手なのですか?
AIモデルは、学習データセットへの本質的な依存、実世界の真の理解力の欠如、幻覚として知られる現象である捏造された情報を生成する重大な傾向など、ファクトチェックにおいていくつかのハードルに直面しています。
検索結果の上位はすべて事実か?
間違いなく違う。真のファクトチェックは、単に検索エンジンの検索結果を確認するだけでは不十分である。論理的整合性を検証し、確立された科学的原則との整合性を確認し、実験的または理論的主張の妥当性を評価する必要がある。さらに、ジャーナリスティックな検証プロセスは、偏向していたり、誤解を招きやすかったり、適切な文脈を持たずに表現されることが多い報道における主張を評価するために不可欠である。
そもそもなぜ外部データを使わないのか?
大規模言語モデルが深く信頼できる推論を行うためには、膨大な知識のリポジトリをナビゲートし、複雑な問題を解決するために既存のプログラミングと統合する能力が必要である。その後、科学的または計算による検証手法を適用することで、堅牢なソリューションを提供することができる。
関連する質問
検索補強とは何ですか?
検索オーグメンテーションとは、応答生成フェーズにおいて、外部データベースやソースからの情報にアクセスし利用できるようにすることで、言語モデルを強化する方法論です。モデルはこの最新の知識を検索することで、より適切で正確な回答を生成します。このアプローチは、特定の主張が信頼できる証拠文書によって裏付けされる必要がある場合に特に価値がある。さらに、検索補強により、LLMは、検索補強された生成のための直接リンクや特殊なフレームワークなど、さまざまな手法を用いて検索データや特定のデータベースとインターフェースをとることができる。
関連記事
 OpenAIは、公的基金、ロボット税、週4日勤務制を柱とするAI経済の構想を提示した
各国政府が超知能機械による経済的影響への対応に苦慮する中、OpenAIは「知能の時代」において富と労働がどのように再構築されるべきかを概説した一連の政策提言を発表した。その構想は、公的資産基金や社会安全網の拡充といった伝統的な左派的な仕組みと、根本的に資本主義的で市場主導型の経済枠組みとを融合させたものである。OpenAIの提案は本質的に「要望リスト」に相当し、人工知能が労働と経済を変革する中で、
Googleが「Gemini Notebooks」を発表、NotebookLMとパーソナルナレッジベースを統合
Googleは先日、Gemini向けに「Notebooks」機能をリリースしました。これは、ユーザーがパーソナライズされたナレッジベースを作成することで、複雑なプロジェクトを管理しやすくすることを目的としています。このアップデートは、GeminiとAIリサーチアシスタント「NotebookLM」との間のデータギャップを埋めるものであり、Googleが閉ループAIワークフローの構築を目指す取り組みに
Luma AI、テキストとピクセルを同時に生成する自己回帰モデル「Uni-1」を発表
Luma Labsは3月23日、画像生成モデル「Uni-1」をリリースしました。これは、同社の「Unified Intelligence」アーキテクチャに基づいて構築された、初の一般公開モデルとなります。現在、公式サイトにて無料トライアルの提供が開始されており、APIの料金体系も発表されました。また、企業向けアクセスチャネルも順次展開される予定です。アーキテクチャの転換:拡散モデルから自己回帰モデ
関連特集おすすめ
チャットボット
OpenAIは、公的基金、ロボット税、週4日勤務制を柱とするAI経済の構想を提示した
各国政府が超知能機械による経済的影響への対応に苦慮する中、OpenAIは「知能の時代」において富と労働がどのように再構築されるべきかを概説した一連の政策提言を発表した。その構想は、公的資産基金や社会安全網の拡充といった伝統的な左派的な仕組みと、根本的に資本主義的で市場主導型の経済枠組みとを融合させたものである。OpenAIの提案は本質的に「要望リスト」に相当し、人工知能が労働と経済を変革する中で、
Googleが「Gemini Notebooks」を発表、NotebookLMとパーソナルナレッジベースを統合
Googleは先日、Gemini向けに「Notebooks」機能をリリースしました。これは、ユーザーがパーソナライズされたナレッジベースを作成することで、複雑なプロジェクトを管理しやすくすることを目的としています。このアップデートは、GeminiとAIリサーチアシスタント「NotebookLM」との間のデータギャップを埋めるものであり、Googleが閉ループAIワークフローの構築を目指す取り組みに
Luma AI、テキストとピクセルを同時に生成する自己回帰モデル「Uni-1」を発表
Luma Labsは3月23日、画像生成モデル「Uni-1」をリリースしました。これは、同社の「Unified Intelligence」アーキテクチャに基づいて構築された、初の一般公開モデルとなります。現在、公式サイトにて無料トライアルの提供が開始されており、APIの料金体系も発表されました。また、企業向けアクセスチャネルも順次展開される予定です。アーキテクチャの転換:拡散モデルから自己回帰モデ
関連特集おすすめ
チャットボット
 高評価のAI恋愛チャットボット:一貫した個性で長期的な関係を築く
高評価のAI恋愛チャットボット:一貫した個性で長期的な関係を築く
2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
 10 ツール
10 ツール
 xix.ai
教育と学習
最高のAIデータサイエンスメンター:SQL、Pandas、および機械学習ワークフローをマスターしましょう
xix.ai
教育と学習
最高のAIデータサイエンスメンター:SQL、Pandas、および機械学習ワークフローをマスターしましょう
2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai
チャットボット
最高のAIを使ったナンパ&会話トレーニング:社交的な魅力と自信をリアルタイムで高める
XIX.AIで、2026年最高のAIを使った口説き術・会話トレーニングツールを発見しましょう。厳選された高評価のツールが、リアルタイムで社交的な魅力と自信を築くお手伝いをします。無料版と有料版の比較や毎週更新されるランキングを参考に、ぜひ試すべき画期的なツールを探してみてください。今すぐ、あなたの社交力を引き出しましょう。
10 ツール
xix.ai
コード
自動化ユニットテストに最適なAIツール:ワンクリックでJest、PyTest、JUnitのテストケースを生成する
2026年に登場した、自動化ユニットテスト用の最高評価を受けたAIツールを発見してください。当社が厳選したこれらのツールは、Jest、PyTest、JUnitのテストケースを瞬時に生成するための強力で革新的なソリューションです。XIX.AIでは、無料オプションと有料オプションを実際のテストデータと共に比較し、毎週更新されるランキングもご覧いただけます。今すぐAIの力を活用して、開発生産性を向上させましょう。
10 ツール
xix.ai
データ分析
最高のAIデータ可視化ツール:生データからインタラクティブなBIダッシュボードを自動生成
XIX.AIで、2026年最高のAIデータ可視化ツールをご覧ください。厳選された高評価のツール群を活用すれば、生データから強力でインタラクティブなBIダッシュボードを瞬時に自動生成できます。実環境でのテスト結果や毎週更新されるランキングをもとに、無料版と有料版の比較も可能です。今すぐデータの可能性を引き出しましょう。
10 ツール
xix.ai
ソーシャルメディア
ソーシャルメディア向けAIブランディングキット:すべてのチャネルで一貫したブランドビジュアルを維持
2026年版、ソーシャルメディア向けAIブランディングキットベストセレクションをご紹介。XIX.AIが厳選したこのリストには、あらゆるチャネルでブランドビジュアルの統一感を完璧に保つ、高評価で画期的なツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較しましょう。今すぐ、ブランドのビジュアル面での優位性を手に入れましょう。
10 ツール
xix.ai

 コメント (1)
0/500
コメント (1)
0/500
![CarlMartin]()
Cette approche par graphes de connaissances pour vérifier les faits des IA est vraiment maline ! 😄 J'aimerais savoir comment ça se compare aux méthodes traditionnelles de fact-checking humain. Est-ce que cette tech pourrait un jour être intégrée dans les moteurs de recherche ?
人工知能は本当に事実と虚構を区別できるのか?本稿では、事実検証という本質的なタスクにおけるAIの能力と限界について調査する。知識グラフ、グラフ・ニューラル・ネットワーク(GNN)、検索補強世代(RAG)アーキテクチャの応用を中心に、AIによる情報検証能力を向上させるために開発されている革新的な技術を探る。単一クレームの単純な検証から複雑な多面的分析まで、AIがどのように精度を高め、誤った情報の拡散に対抗しているかを検証する。
要点
新しいAIファクトチェックモデルは、存在しない情報源を捏造する傾向など、大きな課題に直面している。
ナレッジグラフは、AIに構造化された情報の枠組みを提供することで、精度を向上させる。
グラフ・ニューラル・ネットワーク(GNN)は、より洗練されたファクトチェックのための高度な推論と関係抽出を促進する。
RAGアーキテクチャは、外部知識を統合することで大規模言語モデルの精度を向上させる。
これらの手法を組み合わせることで、複雑なテキストコンテンツの真実と虚偽を区別するAIの能力を強化することを目的としている。
AIファクトチェックの課題
真実の検証における現在のAIモデルの限界
AIは多くの分野で大きな進歩を遂げているが、情報の真実性を決定的に確認する能力はまだ発展途上である。主な障害は、AIモデルが引用を「幻覚」または捏造し、実際には存在しないソースへの参照を作成する傾向である。
この問題は、事実確認ツールとしての信頼性を根本的に損なう。
大規模言語モデル(LLM)は大きな可能性を示しているが、特に長文や複雑なコンテンツではエラーを起こしやすい。LLMは、微妙な解釈を誤ったり、微妙な虚偽を見落としたり、特定の検証に必要な広範な背景知識を欠いたりすることがある。このような限界のためにモデルの改良が必要になることが多く、誤情報の問題に取り組むためにますます複雑なシステムが必要になる。
AIの役割:単なるコードや科学ではなく、投資
このビデオは、AIの中核は純粋に科学的、技術的なものではなく、非常に有利な投資としての地位によって大きく左右されるという視点を提示している。
この示唆に富む視点は、シリコンバレーや米国経済の大部分はAIの成長に依存しており、投資資本の力学がAI開発の舵取りを頻繁に行っていることを示唆している。このような焦点は、客観的な正確さの追求よりも収益性を優先する可能性がある。AIは主に世界の投資家にとって利益を得るための手段であるため、複雑な文章をファクトチェックする研究の方向性には、金銭的な動機が大きく影響している。AIが真に信頼できる真実の裁定者になるためには、商業的インセンティブと事実の完全性へのコミットメントとの間でバランスを取る必要がある。これは重要な問題を提起している:AIは、ある文章が真実かどうかを確実に判断できるのだろうか?
AIによるファクトチェックの強化知識グラフの役割
知識グラフによる知識の構造化
このビデオは、AIのファクトチェック能力を高める上で、知識グラフの重要性を強調している。
ナレッジグラフは、AIモデルに構造化された相互接続フレームワークを提供し、重要な文脈情報を提供する。様々なエンティティ間の関係をマッピングすることで、これらのグラフは、AIシステムがつながりを照会し、発言の真実性を検証し、過去の正確性を調査することを可能にする。
主な利点は以下の通り:
- データの整理:知識グラフは、事実とその相互関係を体系的に整理し、この情報をAIアルゴリズムが容易に利用できるようにする。
- 推論:相互接続された構造により、AIは論理的推論を実行し、データ内の矛盾を発見することができる。
- 文脈理解:AIは、クレームを取り巻く文脈をより深く、より微妙に理解し、より正確な評価につなげる。
GNNとRAG:ファクトチェック能力の向上
情報源の幻覚のような問題に対抗し、関係性の抽出を改善するために、ビデオはグラフ・ニューラル・ネットワーク(GNNs)と検索拡張世代(RAG)アーキテクチャの統合を提案している。
これらは、個々のデータポイントや単純な関係を検証するために、現在スタートアップ企業が提供している高度なAIモデルである。
- グラフ・ニューラル・ネットワーク:GNNは、グラフとして構造化されたデータを処理するために特別に設計されている。複雑な関係を解読し、高度な推論タスクを実行することに優れている。RAGシステムはソースを幻覚する傾向があるが、GNNはこのようなエラーをある程度軽減することができる。
- 検索拡張世代:RAGシステムは、外部の知識ベースから関連文書やデータを取得することで、AIの情報アクセスを拡大する。この補助的なプロセスは、AIの内部で事前に訓練された知識への依存を減らし、それによって幻覚の頻度を減らす。この戦略は、将来のAI世代のために、知識のギャップに体系的に対処するように設計されている。
LLMによるファクトチェック:OpenAIによるディープリサーチへのディープダイブ
OpenAIのディープリサーチ
発表者は、OpenAIの "Deep Research "というツールを利用した。このツールは、トランスフォーマーやナレッジグラフのような様々なAIモデルの情報を集約し、論理的整合性や歴史的正確性の評価に重点を置いた自動調査を行う。
このサービスでは特に、トランスフォーマーに基づくテキストの一貫性検証や、マルチエージェントによる敵対的ファクトチェック手法などのトピックを検索している。
ディープ・リサーチは正確か?
プレゼンターはビデオの中でテストランを行い、AIの検索クエリを注意深く観察し、リクエストが正しく実行されていることを確認した。
デモの間、AIは相当数の古い文献を検索し、要求された最新性の基準に完全に合致していなかった。これは、LLMが予備的な研究データを収集するための貴重なツールである一方で、最終的なレビューと検証の段階では人間の監視が不可欠であることを示す明確な指標となる。
AIによるファクトチェック:メリットとデメリットの比較
長所
大規模なスケーラビリティと高速処理の可能性
膨大なデータセットを分析できる
評価に内在する人間のバイアスを低減できる可能性
人間によるファクトチェック作業を効果的に補強・支援できる
短所
虚偽の情報を生成したり、誤解を招いたりする可能性
既存のトレーニングデータとアルゴリズム設計に基づく固有の限界
現実世界の常識や直感的な理解が一般的に欠如していること
非常に複雑で微妙なテーマを正確に処理することが困難
よくある質問
なぜAIはファクトチェックが苦手なのですか?
AIモデルは、学習データセットへの本質的な依存、実世界の真の理解力の欠如、幻覚として知られる現象である捏造された情報を生成する重大な傾向など、ファクトチェックにおいていくつかのハードルに直面しています。
検索結果の上位はすべて事実か?
間違いなく違う。真のファクトチェックは、単に検索エンジンの検索結果を確認するだけでは不十分である。論理的整合性を検証し、確立された科学的原則との整合性を確認し、実験的または理論的主張の妥当性を評価する必要がある。さらに、ジャーナリスティックな検証プロセスは、偏向していたり、誤解を招きやすかったり、適切な文脈を持たずに表現されることが多い報道における主張を評価するために不可欠である。
そもそもなぜ外部データを使わないのか?
大規模言語モデルが深く信頼できる推論を行うためには、膨大な知識のリポジトリをナビゲートし、複雑な問題を解決するために既存のプログラミングと統合する能力が必要である。その後、科学的または計算による検証手法を適用することで、堅牢なソリューションを提供することができる。
関連する質問
検索補強とは何ですか?
検索オーグメンテーションとは、応答生成フェーズにおいて、外部データベースやソースからの情報にアクセスし利用できるようにすることで、言語モデルを強化する方法論です。モデルはこの最新の知識を検索することで、より適切で正確な回答を生成します。このアプローチは、特定の主張が信頼できる証拠文書によって裏付けされる必要がある場合に特に価値がある。さらに、検索補強により、LLMは、検索補強された生成のための直接リンクや特殊なフレームワークなど、さまざまな手法を用いて検索データや特定のデータベースとインターフェースをとることができる。










 OpenAIは、公的基金、ロボット税、週4日勤務制を柱とするAI経済の構想を提示した
各国政府が超知能機械による経済的影響への対応に苦慮する中、OpenAIは「知能の時代」において富と労働がどのように再構築されるべきかを概説した一連の政策提言を発表した。その構想は、公的資産基金や社会安全網の拡充といった伝統的な左派的な仕組みと、根本的に資本主義的で市場主導型の経済枠組みとを融合させたものである。OpenAIの提案は本質的に「要望リスト」に相当し、人工知能が労働と経済を変革する中で、
OpenAIは、公的基金、ロボット税、週4日勤務制を柱とするAI経済の構想を提示した
各国政府が超知能機械による経済的影響への対応に苦慮する中、OpenAIは「知能の時代」において富と労働がどのように再構築されるべきかを概説した一連の政策提言を発表した。その構想は、公的資産基金や社会安全網の拡充といった伝統的な左派的な仕組みと、根本的に資本主義的で市場主導型の経済枠組みとを融合させたものである。OpenAIの提案は本質的に「要望リスト」に相当し、人工知能が労働と経済を変革する中で、
 Googleが「Gemini Notebooks」を発表、NotebookLMとパーソナルナレッジベースを統合
Googleは先日、Gemini向けに「Notebooks」機能をリリースしました。これは、ユーザーがパーソナライズされたナレッジベースを作成することで、複雑なプロジェクトを管理しやすくすることを目的としています。このアップデートは、GeminiとAIリサーチアシスタント「NotebookLM」との間のデータギャップを埋めるものであり、Googleが閉ループAIワークフローの構築を目指す取り組みに
Googleが「Gemini Notebooks」を発表、NotebookLMとパーソナルナレッジベースを統合
Googleは先日、Gemini向けに「Notebooks」機能をリリースしました。これは、ユーザーがパーソナライズされたナレッジベースを作成することで、複雑なプロジェクトを管理しやすくすることを目的としています。このアップデートは、GeminiとAIリサーチアシスタント「NotebookLM」との間のデータギャップを埋めるものであり、Googleが閉ループAIワークフローの構築を目指す取り組みに
 Luma AI、テキストとピクセルを同時に生成する自己回帰モデル「Uni-1」を発表
Luma Labsは3月23日、画像生成モデル「Uni-1」をリリースしました。これは、同社の「Unified Intelligence」アーキテクチャに基づいて構築された、初の一般公開モデルとなります。現在、公式サイトにて無料トライアルの提供が開始されており、APIの料金体系も発表されました。また、企業向けアクセスチャネルも順次展開される予定です。アーキテクチャの転換:拡散モデルから自己回帰モデ
Luma AI、テキストとピクセルを同時に生成する自己回帰モデル「Uni-1」を発表
Luma Labsは3月23日、画像生成モデル「Uni-1」をリリースしました。これは、同社の「Unified Intelligence」アーキテクチャに基づいて構築された、初の一般公開モデルとなります。現在、公式サイトにて無料トライアルの提供が開始されており、APIの料金体系も発表されました。また、企業向けアクセスチャネルも順次展開される予定です。アーキテクチャの転換:拡散モデルから自己回帰モデ

2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai

2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAIを使った口説き術・会話トレーニングツールを発見しましょう。厳選された高評価のツールが、リアルタイムで社交的な魅力と自信を築くお手伝いをします。無料版と有料版の比較や毎週更新されるランキングを参考に、ぜひ試すべき画期的なツールを探してみてください。今すぐ、あなたの社交力を引き出しましょう。
10 ツール
xix.ai

2026年に登場した、自動化ユニットテスト用の最高評価を受けたAIツールを発見してください。当社が厳選したこれらのツールは、Jest、PyTest、JUnitのテストケースを瞬時に生成するための強力で革新的なソリューションです。XIX.AIでは、無料オプションと有料オプションを実際のテストデータと共に比較し、毎週更新されるランキングもご覧いただけます。今すぐAIの力を活用して、開発生産性を向上させましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAIデータ可視化ツールをご覧ください。厳選された高評価のツール群を活用すれば、生データから強力でインタラクティブなBIダッシュボードを瞬時に自動生成できます。実環境でのテスト結果や毎週更新されるランキングをもとに、無料版と有料版の比較も可能です。今すぐデータの可能性を引き出しましょう。
10 ツール
xix.ai

2026年版、ソーシャルメディア向けAIブランディングキットベストセレクションをご紹介。XIX.AIが厳選したこのリストには、あらゆるチャネルでブランドビジュアルの統一感を完璧に保つ、高評価で画期的なツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較しましょう。今すぐ、ブランドのビジュアル面での優位性を手に入れましょう。
10 ツール
xix.ai

Cette approche par graphes de connaissances pour vérifier les faits des IA est vraiment maline ! 😄 J'aimerais savoir comment ça se compare aux méthodes traditionnelles de fact-checking humain. Est-ce que cette tech pourrait un jour être intégrée dans les moteurs de recherche ?













