
















 Home
HomeEffortlessly Chat with PDFs Using Gemini API, Langchain, and Chroma DB Integration
Transform your PDF documents into conversational partners with Retrieval-Augmented Generation (RAG) technology. This comprehensive guide demonstrates how to create an intelligent Python system that lets you interact with your PDFs using Gemini API's advanced language capabilities, Langchain's seamless framework, and Chroma DB's efficient vector storage. Discover how to extract actionable insights from complex documents through natural dialogue.
Key Points
Develop an interactive Python application for PDF document queries
Implement Gemini API for sophisticated natural language processing
Configure Langchain for optimized large language model workflows
Integrate Chroma DB for high-performance document indexing
Practical implementation using financial report analysis
Complete source code and resource materials provided
Building a PDF Chatbot with Gemini API, Langchain, and Chroma DB
The Power of RAG and LLMs for PDF Interaction
Retrieval-Augmented Generation combines external data retrieval with language model intelligence. Our system uses Gemini API's advanced reasoning capabilities while dynamically referencing PDF content through Chroma DB's vector search. This architecture delivers precise answers without requiring full model retraining.

Langchain serves as the orchestration layer, simplifying complex LLM operations and pipeline management. Chroma DB enables semantic search by converting document contents into numerical embeddings, allowing rapid identification of relevant passages.
Project Overview: Chatting with Best Buy's 2023 Financial Report
We'll implement a practical financial analysis tool using Best Buy's annual report. This demonstrates how specialized business documents can become interactive knowledge bases.
The complete implementation package includes all necessary components for adaptation to other document types and use cases.
The Payoff: Asking Targeted Questions and Getting Accurate Answers
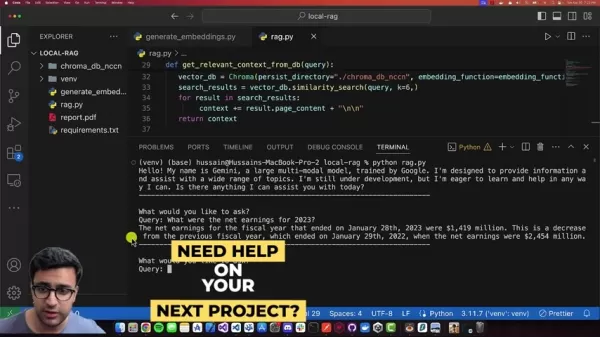
The system demonstrates impressive precision extracting financial metrics, like retrieving exact net earnings figures through natural language queries.
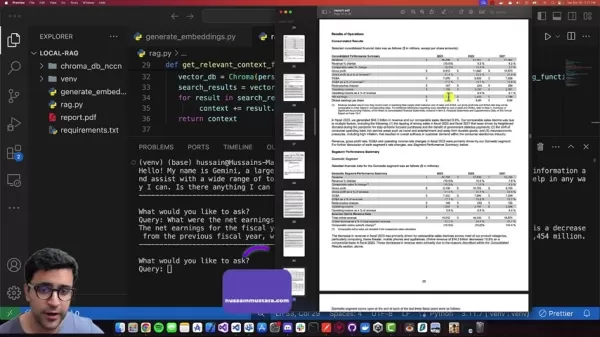
Contextual understanding from document retrieval combined with Gemini's language mastery produces reliable, relevant responses.
Setting Up Your Development Environment
Creating a Virtual Environment
Isolate project dependencies with a dedicated virtual environment:
1. Initialize environment: python3 -m venv venv
2. Activate:
- macOS/Linux:
source venv/bin/activate - Windows:
venvScriptsactivate
Obtaining a Gemini API Key
Secure your API credentials through Google AI Studio:
- Visit ai.google.dev
- Follow authentication workflow
- Create or select project
- Generate and securely store API key
Installing Required Dependencies
Install critical packages within activated environment:
pip install langchain chromadb pypdf sentence-transformers google-generativeaiCoding the PDF Chatbot
Importing Libraries and Setting Up API Key
Key imports include ChromaDB components and document processing utilities. Configure Gemini API authentication with your secured key.
Loading the PDF Document
Initialize PDF processor and create document collection by:
- Configuring file loader paths
- Extracting document contents
- Storing processed data
Embedding setup
Configure text segmentation for optimal processing:
- Set chunk size (1000 tokens)
- Define overlap (100 tokens)
- Balance processing efficiency with context preservation
Pros and Cons of Conversational PDF
Pros
Rapid Implementation: Modular components accelerate development
Advanced Comprehension: Gemini delivers nuanced understanding
Optimized Storage: Chroma enables efficient data retrieval
Cons
Response Accuracy: Dependent on prompt quality
System Requirements: Document processing demands resources
Scale Limitations: Current document capacity constraints
Key Features of PDF Chatbot
Feature Breakdown
The system delivers:
- Natural PDF content interaction
- Precise question answering
- Flexible architecture for customization
- Scalable document processing
Potential Use Cases
Potential PDF application cases
Adaptable solution for multiple domains:
- Financial Analysis: Automated report interpretation
- Academic Research: Literature review acceleration
- Educational Support: Interactive learning materials
- Legal Review: Contract analysis assistant
FAQ
What is a RAG-based System?
A hybrid architecture combining knowledge retrieval with generative AI capabilities.
What kind of document can be fed to it?
Current implementation optimized for PDFs with adaptable architecture.
Related Questions
Can I apply this to other document types?
The framework supports extension to additional formats through Langchain's document loader ecosystem. Transitioning to DOCX, CSV or other types requires:
- Appropriate format-specific loader
- Content structure considerations
- Potential embedding adjustments
How can I improve the answer accuracy?
Enhancements through:
- Strategic text segmentation
- Specialized embedding models
- Advanced prompt engineering
- Combined search methodologies
Related article
 China Telecom Invests in Mianbi Intelligence, Raises Capital to 713,000 Yuan for LLM & Data Infra
The "national team" and the leading figure from Tsinghua University in the large model space are deepening their strategic alignment. On March 1, 2026, according to the latest business registration data from Qichacha, Beijing Mianbi Intelligent Techn
Taotian Group Accelerates AI-Native Restructuring, Grants Interns Free Token Quotas
TaoTian Group recently introduced the "AI Productivity Plan," designed to accelerate the integration of AI technology into e-commerce operations and R&D workflows through resource allocation and tool subsidies. The program is now available to all int
Glean targets enterprise AI infrastructure in land grab
The race to dominate enterprise AI is accelerating. Microsoft is embedding Copilot into Office, Google is integrating Gemini into Workspace, and both OpenAI and Anthropic are selling directly to corporations. Meanwhile, nearly every SaaS vendor now i
Related Special Topic Recommendations
writing
China Telecom Invests in Mianbi Intelligence, Raises Capital to 713,000 Yuan for LLM & Data Infra
The "national team" and the leading figure from Tsinghua University in the large model space are deepening their strategic alignment. On March 1, 2026, according to the latest business registration data from Qichacha, Beijing Mianbi Intelligent Techn
Taotian Group Accelerates AI-Native Restructuring, Grants Interns Free Token Quotas
TaoTian Group recently introduced the "AI Productivity Plan," designed to accelerate the integration of AI technology into e-commerce operations and R&D workflows through resource allocation and tool subsidies. The program is now available to all int
Glean targets enterprise AI infrastructure in land grab
The race to dominate enterprise AI is accelerating. Microsoft is embedding Copilot into Office, Google is integrating Gemini into Workspace, and both OpenAI and Anthropic are selling directly to corporations. Meanwhile, nearly every SaaS vendor now i
Related Special Topic Recommendations
writing
 Best AI Xianxia & Wuxia Assistants: Write Epic Cultivation Progression & Martial Arts Choreography
Best AI Xianxia & Wuxia Assistants: Write Epic Cultivation Progression & Martial Arts Choreography
Discover the 2026 best AI assistants for crafting epic xianxia & wuxia tales. XIX.AI's curated list features top-rated, game-changing tools to master cultivation progression and martial arts choreography. Compare free vs paid options with real-world tests. Unlock your creative potential and start writing today!
 10 tools
10 tools
 xix.ai
code
AI Mobile App Coding Tools: Generate Cross-Platform Flutter & React Native Code from Prompts
xix.ai
code
AI Mobile App Coding Tools: Generate Cross-Platform Flutter & React Native Code from Prompts
Discover the 2026 best AI mobile app coding tools for Flutter & React Native. Our curated, top-rated list features powerful, game-changing solutions that generate cross-platform code from prompts. Compare free vs paid options with real-world tests. Unlock faster development and build better apps. Explore the rankings on XIX.AI now!
10 tools
xix.ai
code
Best AI Chrome Extension Generators: Create Custom Browser Add-ons with Zero Coding Experience
Discover the 2026 best AI Chrome extension generators on XIX.AI. Our curated list features top-rated, must-try tools that let you create custom browser add-ons with zero coding. Compare free vs paid options, see real-world tests, and unlock your productivity. Explore the latest rankings and find your perfect tool today!
10 tools
xix.ai
Text-to-speech
Best AI Multilingual TTS: Generate Authentic Native-Accent Speech in 50+ Languages
Discover the 2026 best AI multilingual TTS tools for authentic native-accent speech in 50+ languages. Explore our top-rated, curated rankings with free vs paid comparisons and real-world tests. Find your perfect voice tool on XIX.AI and unlock global communication today.
10 tools
xix.ai
Meeting Assistant
Best AI Meeting Automation Tools for Smarter and Faster Collaboration
Discover the 2026 latest top-rated AI meeting automation tools for smarter, faster collaboration. Our curated list features powerful, game-changing solutions to automate notes, summaries, and action items. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock peak team productivity. Explore the best picks now at XIX.AI.
10 tools
xix.ai
Prompt
AI Prompts for Infrastructure-as-Code: Deploy Terraform & Docker Configurations Safely
Discover the 2026 latest top-rated AI prompts for Infrastructure-as-Code. XIX.AI's curated selection helps you safely deploy Terraform & Docker configurations, automate cloud setups, and boost DevOps productivity. Compare free vs paid options with real-world tests. Explore now and unlock your AI edge.
10 tools
xix.ai

 Comments (2)
0/500
Comments (2)
0/500
![RalphSmith]()
Интересно, но не слишком ли много технологий для простой задачи? 🤔 Мой знакомый разработчйк уже месяц говорит только о RAG, хотя пока не видел реальных проектов. Кто-нибудь пробовал подключить Gemini к PDF с русской кодировкой? Могут быть проблемы с кириллицей, как в прошлый раз с OpenAI API. Читал о такой системе в блоге, но там была большая задержка при обработке - вы как думаете?
![TerryHernández]()
Die Kombination von RAG mit Gemini API klingt vielversprechend! Ist das System leicht genug für lokale Deployment? 🤔 Der Datenschutz wäre dann ein großer Pluspunkt gegenüber Cloud-Lösungen.
Transform your PDF documents into conversational partners with Retrieval-Augmented Generation (RAG) technology. This comprehensive guide demonstrates how to create an intelligent Python system that lets you interact with your PDFs using Gemini API's advanced language capabilities, Langchain's seamless framework, and Chroma DB's efficient vector storage. Discover how to extract actionable insights from complex documents through natural dialogue.
Key Points
Develop an interactive Python application for PDF document queries
Implement Gemini API for sophisticated natural language processing
Configure Langchain for optimized large language model workflows
Integrate Chroma DB for high-performance document indexing
Practical implementation using financial report analysis
Complete source code and resource materials provided
Building a PDF Chatbot with Gemini API, Langchain, and Chroma DB
The Power of RAG and LLMs for PDF Interaction
Retrieval-Augmented Generation combines external data retrieval with language model intelligence. Our system uses Gemini API's advanced reasoning capabilities while dynamically referencing PDF content through Chroma DB's vector search. This architecture delivers precise answers without requiring full model retraining.
Langchain serves as the orchestration layer, simplifying complex LLM operations and pipeline management. Chroma DB enables semantic search by converting document contents into numerical embeddings, allowing rapid identification of relevant passages.
Project Overview: Chatting with Best Buy's 2023 Financial Report
We'll implement a practical financial analysis tool using Best Buy's annual report. This demonstrates how specialized business documents can become interactive knowledge bases.
The complete implementation package includes all necessary components for adaptation to other document types and use cases.
The Payoff: Asking Targeted Questions and Getting Accurate Answers
The system demonstrates impressive precision extracting financial metrics, like retrieving exact net earnings figures through natural language queries.
Contextual understanding from document retrieval combined with Gemini's language mastery produces reliable, relevant responses.
Setting Up Your Development Environment
Creating a Virtual Environment
Isolate project dependencies with a dedicated virtual environment:
1. Initialize environment: python3 -m venv venv
2. Activate:
- macOS/Linux:
source venv/bin/activate - Windows:
venvScriptsactivate
Obtaining a Gemini API Key
Secure your API credentials through Google AI Studio:
- Visit ai.google.dev
- Follow authentication workflow
- Create or select project
- Generate and securely store API key
Installing Required Dependencies
Install critical packages within activated environment:
pip install langchain chromadb pypdf sentence-transformers google-generativeaiCoding the PDF Chatbot
Importing Libraries and Setting Up API Key
Key imports include ChromaDB components and document processing utilities. Configure Gemini API authentication with your secured key.
Loading the PDF Document
Initialize PDF processor and create document collection by:
- Configuring file loader paths
- Extracting document contents
- Storing processed data
Embedding setup
Configure text segmentation for optimal processing:
- Set chunk size (1000 tokens)
- Define overlap (100 tokens)
- Balance processing efficiency with context preservation
Pros and Cons of Conversational PDF
Pros
Rapid Implementation: Modular components accelerate development
Advanced Comprehension: Gemini delivers nuanced understanding
Optimized Storage: Chroma enables efficient data retrieval
Cons
Response Accuracy: Dependent on prompt quality
System Requirements: Document processing demands resources
Scale Limitations: Current document capacity constraints
Key Features of PDF Chatbot
Feature Breakdown
The system delivers:
- Natural PDF content interaction
- Precise question answering
- Flexible architecture for customization
- Scalable document processing
Potential Use Cases
Potential PDF application cases
Adaptable solution for multiple domains:
- Financial Analysis: Automated report interpretation
- Academic Research: Literature review acceleration
- Educational Support: Interactive learning materials
- Legal Review: Contract analysis assistant
FAQ
What is a RAG-based System?
A hybrid architecture combining knowledge retrieval with generative AI capabilities.
What kind of document can be fed to it?
Current implementation optimized for PDFs with adaptable architecture.
Related Questions
Can I apply this to other document types?
The framework supports extension to additional formats through Langchain's document loader ecosystem. Transitioning to DOCX, CSV or other types requires:
- Appropriate format-specific loader
- Content structure considerations
- Potential embedding adjustments
How can I improve the answer accuracy?
Enhancements through:
- Strategic text segmentation
- Specialized embedding models
- Advanced prompt engineering
- Combined search methodologies










 China Telecom Invests in Mianbi Intelligence, Raises Capital to 713,000 Yuan for LLM & Data Infra
The "national team" and the leading figure from Tsinghua University in the large model space are deepening their strategic alignment. On March 1, 2026, according to the latest business registration data from Qichacha, Beijing Mianbi Intelligent Techn
China Telecom Invests in Mianbi Intelligence, Raises Capital to 713,000 Yuan for LLM & Data Infra
The "national team" and the leading figure from Tsinghua University in the large model space are deepening their strategic alignment. On March 1, 2026, according to the latest business registration data from Qichacha, Beijing Mianbi Intelligent Techn
 Taotian Group Accelerates AI-Native Restructuring, Grants Interns Free Token Quotas
TaoTian Group recently introduced the "AI Productivity Plan," designed to accelerate the integration of AI technology into e-commerce operations and R&D workflows through resource allocation and tool subsidies. The program is now available to all int
Taotian Group Accelerates AI-Native Restructuring, Grants Interns Free Token Quotas
TaoTian Group recently introduced the "AI Productivity Plan," designed to accelerate the integration of AI technology into e-commerce operations and R&D workflows through resource allocation and tool subsidies. The program is now available to all int
 Glean targets enterprise AI infrastructure in land grab
The race to dominate enterprise AI is accelerating. Microsoft is embedding Copilot into Office, Google is integrating Gemini into Workspace, and both OpenAI and Anthropic are selling directly to corporations. Meanwhile, nearly every SaaS vendor now i
Glean targets enterprise AI infrastructure in land grab
The race to dominate enterprise AI is accelerating. Microsoft is embedding Copilot into Office, Google is integrating Gemini into Workspace, and both OpenAI and Anthropic are selling directly to corporations. Meanwhile, nearly every SaaS vendor now i

Discover the 2026 best AI assistants for crafting epic xianxia & wuxia tales. XIX.AI's curated list features top-rated, game-changing tools to master cultivation progression and martial arts choreography. Compare free vs paid options with real-world tests. Unlock your creative potential and start writing today!
10 tools
xix.ai

Discover the 2026 best AI mobile app coding tools for Flutter & React Native. Our curated, top-rated list features powerful, game-changing solutions that generate cross-platform code from prompts. Compare free vs paid options with real-world tests. Unlock faster development and build better apps. Explore the rankings on XIX.AI now!
10 tools
xix.ai

Discover the 2026 best AI Chrome extension generators on XIX.AI. Our curated list features top-rated, must-try tools that let you create custom browser add-ons with zero coding. Compare free vs paid options, see real-world tests, and unlock your productivity. Explore the latest rankings and find your perfect tool today!
10 tools
xix.ai

Discover the 2026 best AI multilingual TTS tools for authentic native-accent speech in 50+ languages. Explore our top-rated, curated rankings with free vs paid comparisons and real-world tests. Find your perfect voice tool on XIX.AI and unlock global communication today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI meeting automation tools for smarter, faster collaboration. Our curated list features powerful, game-changing solutions to automate notes, summaries, and action items. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock peak team productivity. Explore the best picks now at XIX.AI.
10 tools
xix.ai

Discover the 2026 latest top-rated AI prompts for Infrastructure-as-Code. XIX.AI's curated selection helps you safely deploy Terraform & Docker configurations, automate cloud setups, and boost DevOps productivity. Compare free vs paid options with real-world tests. Explore now and unlock your AI edge.
10 tools
xix.ai

Интересно, но не слишком ли много технологий для простой задачи? 🤔 Мой знакомый разработчйк уже месяц говорит только о RAG, хотя пока не видел реальных проектов. Кто-нибудь пробовал подключить Gemini к PDF с русской кодировкой? Могут быть проблемы с кириллицей, как в прошлый раз с OpenAI API. Читал о такой системе в блоге, но там была большая задержка при обработке - вы как думаете?
Die Kombination von RAG mit Gemini API klingt vielversprechend! Ist das System leicht genug für lokale Deployment? 🤔 Der Datenschutz wäre dann ein großer Pluspunkt gegenüber Cloud-Lösungen.













