
















 首页
首页Meta的Llama 3.1是AI代的进步
周二,Meta揭开了其Llama系列大型语言模型(LLMs)的最新成员——Llama 3.1的面纱。该公司自豪地宣称Llama 3.1是首个开源的“前沿模型”,这一术语通常用于指代最先进的人工智能模型。
Llama 3.1有多种规模,但真正引人注目的是其巨型“405B”模型。凭借惊人的4050亿个神经“权重”或参数,它超越了其他著名开源模型,如Nvidia的Nemotron 4、Google的Gemma 2和Mixtral。更引人入胜的是Meta团队在打造这一巨型模型时所做的三个关键决策。
这些决策堪称神经网络工程的杰作,构成了Llama 3.1 405B构建和训练的支柱。它们还建立在Meta在Llama 2中展示的效率提升基础上,展示了减少深度学习总体计算预算的潜力。
首先,Llama 3.1 405B放弃了Google在其闭源Gemini 1.5和Mistral在其Mixtral中使用的“专家混合”方法。这种方法涉及创建不同的神经权重组合,其中一些可以关闭以简化预测。相反,Meta的研究人员坚持使用自Google在2017年引入的经典“仅解码器变换器模型架构”。他们声称这一选择带来了更稳定的训练过程。
其次,为了提升这种简单变换器模型的性能,Meta的团队提出了一种巧妙的多阶段训练方法。众所周知,平衡训练数据量和计算资源会显著影响预测质量。但传统的“扩展定律”,即基于模型规模和数据预测性能的规则,并不一定能反映模型在“下游”任务(如推理测试)中的表现。
因此,Meta开发了自己的扩展定律。他们增加了训练数据和计算资源,通过多次迭代测试不同组合,以查看生成的模型在关键下游任务中的表现。这一细致的过程帮助他们找到了最佳点,从而选择了4050亿个参数作为旗舰模型。最终训练由Meta的Grand Teton AI服务器上的16000个Nvidia H100 GPU芯片提供支持,并采用复杂系统并行运行数据和权重。
第三个创新在于训练后阶段。每次训练结束后,Llama 3.1都会经历一个由人类反馈指导的严格过程,类似于OpenAI和其他公司用来优化模型输出的方法。这包括“监督微调”,模型通过人类偏好学习区分理想和非理想输出。
Meta随后引入了一种名为“直接偏好优化”(DPO)的创新,这是今年由斯坦福大学AI学者开创的一种更高效的强化学习方法。他们还通过展示使用API调用解决的提示示例,训练Llama 3.1使用“工具”,如外部搜索引擎,从而提升其“零样本”工具使用能力。
为了对抗“幻觉”,团队精心挑选了特定训练数据并创建了原创问答对,微调模型以仅回答其知道的内容,并拒绝回答不确定的问题。
在整个开发过程中,Meta研究人员强调简单性,指出高质量数据、规模和直接的方法始终带来最佳结果。尽管他们探索了更复杂的架构和训练方案,但发现增加的复杂性并不足以证明其益处。
Llama 3.1 405B的规模是开源模型的一个里程碑,通常被商业闭源模型所压制。Meta的首席执行官马克·扎克伯格强调了其经济优势,指出开发者运行Llama 3.1 405B的推理成本仅为使用GPT-4o等模型的一半。
扎克伯格还将开源AI视为软件的自然发展,类比Unix从专有系统演变为更先进、安全和广泛的生态系统,这得益于开源开发。
然而,正如ZDNET的Steven Vaughan-Nichols指出的,Meta在Hugging Face上发布的代码缺少一些细节,且代码许可证比典型的开源许可证更严格。因此,尽管Llama 3.1算是开源,但并非完全如此。然而,其训练过程的详细程度令人耳目一新,尤其是当OpenAI和Google等巨头对其闭源模型越来越讳莫如深时。
相关文章
 OpenAI 停用 o3 和 GPT-4.5 大型模型
作为人工智能领域的领军企业,OpenAI的每一步技术举措都会在业界引发巨大反响。近日,该公司发布了一项重大公告:将从其ChatGPT平台退役两个经典模型——o3和GPT-4.5。 常被称为“人文天才”的 GPT-4.5 将于 6 月 27 日下线,而以硬核推理能力著称的 o3 则将于 8 月 26 日跟进。经典模型的退役引发怀旧之情这一突如其来的消息让许多付费老用户难以接受,社交社区和讨论区很快充
AIGCPanel 2.0.0 重大更新:工作流引擎开启自动化数字人创作的新纪元
AIGCPanel 作为一款强大的本地数字人创作工具,刚刚发布了 2.0.0 版本——被誉为“迄今为止最重大的更新”。 此次核心升级通过工作流引擎和CLI命令行工具,将数字人合成、语音克隆及音视频处理功能有机整合,从而解决了当前AI创作工具分散的问题,实现了从手动组装到自动化生产的转变。1. 核心升级:定义逻辑流程,一键输出AIGCPanel 2.0.0 的突出新功能是工作流引擎:基于节点的组合:
BuzzFeed 推出专注于垃圾应用的 AI 子公司
在面临重大经营危机的背景下,曾经的数字媒体巨头BuzzFeed正启动一项由人工智能驱动的雄心勃勃的自救实验。 在最近举行的SXSW大会上,联合创始人兼首席执行官乔纳·佩雷蒂宣布成立一家名为Branch Office的子公司,旨在通过一系列由人工智能驱动的消费者应用程序,重新定义“软件即内容”的商业模式。核心产品组合:融合网络梗与社交媒体Branch Office 推出了三款核心应用,每款都旨在捕捉
相关专题推荐
图像编辑
OpenAI 停用 o3 和 GPT-4.5 大型模型
作为人工智能领域的领军企业,OpenAI的每一步技术举措都会在业界引发巨大反响。近日,该公司发布了一项重大公告:将从其ChatGPT平台退役两个经典模型——o3和GPT-4.5。 常被称为“人文天才”的 GPT-4.5 将于 6 月 27 日下线,而以硬核推理能力著称的 o3 则将于 8 月 26 日跟进。经典模型的退役引发怀旧之情这一突如其来的消息让许多付费老用户难以接受,社交社区和讨论区很快充
AIGCPanel 2.0.0 重大更新:工作流引擎开启自动化数字人创作的新纪元
AIGCPanel 作为一款强大的本地数字人创作工具,刚刚发布了 2.0.0 版本——被誉为“迄今为止最重大的更新”。 此次核心升级通过工作流引擎和CLI命令行工具,将数字人合成、语音克隆及音视频处理功能有机整合,从而解决了当前AI创作工具分散的问题,实现了从手动组装到自动化生产的转变。1. 核心升级:定义逻辑流程,一键输出AIGCPanel 2.0.0 的突出新功能是工作流引擎:基于节点的组合:
BuzzFeed 推出专注于垃圾应用的 AI 子公司
在面临重大经营危机的背景下,曾经的数字媒体巨头BuzzFeed正启动一项由人工智能驱动的雄心勃勃的自救实验。 在最近举行的SXSW大会上,联合创始人兼首席执行官乔纳·佩雷蒂宣布成立一家名为Branch Office的子公司,旨在通过一系列由人工智能驱动的消费者应用程序,重新定义“软件即内容”的商业模式。核心产品组合:融合网络梗与社交媒体Branch Office 推出了三款核心应用,每款都旨在捕捉
相关专题推荐
图像编辑
 用于短剧故事板的AI艺术生成工具:幻想与都市浪漫题材的角色设计
用于短剧故事板的AI艺术生成工具:幻想与都市浪漫题材的角色设计
2026最新推荐:探索最适合用于短剧故事板制作的AI艺术生成工具。我们精心挑选了众多顶级工具,帮助您创作出引人入胜的幻想角色和都市浪漫角色。您可以对比免费与付费选项,查看实际测试结果,从而找到最适合自己的创意工具。XIX.AI还会每周更新排名并提供专家分析,让您立即开始将故事可视化呈现吧!
 10 个工具
10 个工具
 xix.ai
写作
最适合广播和播客使用的AI脚本编写工具:帮助您创作引人入胜的音频广告
xix.ai
写作
最适合广播和播客使用的AI脚本编写工具:帮助您创作引人入胜的音频广告
在XIX.AI上,发现2026年最适合用于广播和播客制作的AI脚本工具。我们精心挑选的这些高评分工具能够提供强大的功能,帮助您快速制作出引人入胜的音频广告。通过实际测试和每周更新的排名,您可以了解免费选项与付费选项之间的差异。今天就释放您的创造力吧!
10 个工具
xix.ai
商业
最佳 AI 合同审查软件:即时发现法律漏洞与合规风险
在 XIX.AI 上探索 2026 年最佳 AI 合同审查软件。我们精心筛选的顶级榜单汇集了功能强大的工具,能够即时发现法律漏洞和合规风险。通过实际测试和每周更新的排名,对比免费与付费选项。找到能彻底改变游戏规则的解决方案,实现安全、高效的合同分析。立即探索这本权威指南。
10 个工具
xix.ai
动画创作
专为东华设计的AI动漫生成器:可用于创建网络小说角色及漫画头像
探索2026年最适合制作中文动画的人工智能工具。我们精心挑选的顶级列表中包含了各种强大的工具,能够帮助你创建出令人惊叹的网络小说角色和漫画头像。通过实际测试来对比免费选项和付费选项,找到最适合你的创作工具,今天就在XIX.AI上将你的故事变为现实吧。
10 个工具
xix.ai
漫画创作
漫画领域顶尖的AI自动上色工具:零一致性错误地应用平涂色彩
立即访问 XIX.AI,探索 2026 年最优秀的漫画 AI 自动上色工具。我们精心筛选的清单汇集了广受好评、颠覆行业的解决方案,这些工具能以零一致性错误的方式应用平涂色彩,从而大幅提升您的工作效率。通过免费版与付费版的对比分析、实际测试以及每周更新的排行榜,找到最适合您的工具。立即开启您的 AI 优势。
10 个工具
xix.ai
写作
顶尖 AI 角色设定生成器:生成一致的角色动机与致命缺陷
探索2026年最优秀的AI人物设定生成工具,助您塑造鲜活立体的角色。XIX.AI精心筛选的这份清单汇集了广受好评、颠覆传统的工具,能够生成具有内在逻辑的动机和致命缺陷。通过实际测试对比免费与付费选项。立即释放您的叙事潜能。
10 个工具
xix.ai

 评论 (27)
0/500
评论 (27)
0/500
![DavidRodriguez]()
Interessant, dass Meta Llama 3.1 als erstes Open-Source-Modell bezeichnet. Aber wer kann so ein riesiges Modell eigentlich sinnvoll nutzen? Für kleine Unternehmen bestimmt zu teuer im Betrieb. 🧐
![ThomasBaker]()
Wow, Llama 3.1 sounds like a game-changer! Open-source and frontier-level? That’s huge for AI devs. Curious how it stacks up against closed models like GPT-4. 😎
![AlbertThomas]()
O Llama 3.1 é incrível! Adoro que seja de código aberto, é como ter um superpoder no meu arsenal de programação. No começo pode ser um pouco confuso, mas vale a pena experimentar se você gosta de IA! 🚀
![GaryGonzalez]()
ラマ3.1は本当にすごい!オープンソースで使えるのが最高です。最初は少し圧倒されましたが、慣れると便利です。AIに興味があるなら、ぜひ試してみてください!🚀
![AnthonyPerez]()
¡Llama 3.1 es una bestia! Me encanta que sea de código abierto, es como tener un superpoder en mi arsenal de programación. Al principio puede ser un poco abrumador, pero definitivamente vale la pena probarlo si te interesa la IA! 🚀
![JustinAnderson]()
¡Llama 3.1 de Meta es una maravilla! Me sorprende cómo están empujando los límites con la IA de código abierto. El rendimiento es genial, pero desearía que hubiera más documentación para principiantes. De todas formas, ¡es una herramienta que hay que probar! 💪
周二,Meta揭开了其Llama系列大型语言模型(LLMs)的最新成员——Llama 3.1的面纱。该公司自豪地宣称Llama 3.1是首个开源的“前沿模型”,这一术语通常用于指代最先进的人工智能模型。
Llama 3.1有多种规模,但真正引人注目的是其巨型“405B”模型。凭借惊人的4050亿个神经“权重”或参数,它超越了其他著名开源模型,如Nvidia的Nemotron 4、Google的Gemma 2和Mixtral。更引人入胜的是Meta团队在打造这一巨型模型时所做的三个关键决策。
这些决策堪称神经网络工程的杰作,构成了Llama 3.1 405B构建和训练的支柱。它们还建立在Meta在Llama 2中展示的效率提升基础上,展示了减少深度学习总体计算预算的潜力。
首先,Llama 3.1 405B放弃了Google在其闭源Gemini 1.5和Mistral在其Mixtral中使用的“专家混合”方法。这种方法涉及创建不同的神经权重组合,其中一些可以关闭以简化预测。相反,Meta的研究人员坚持使用自Google在2017年引入的经典“仅解码器变换器模型架构”。他们声称这一选择带来了更稳定的训练过程。
其次,为了提升这种简单变换器模型的性能,Meta的团队提出了一种巧妙的多阶段训练方法。众所周知,平衡训练数据量和计算资源会显著影响预测质量。但传统的“扩展定律”,即基于模型规模和数据预测性能的规则,并不一定能反映模型在“下游”任务(如推理测试)中的表现。
因此,Meta开发了自己的扩展定律。他们增加了训练数据和计算资源,通过多次迭代测试不同组合,以查看生成的模型在关键下游任务中的表现。这一细致的过程帮助他们找到了最佳点,从而选择了4050亿个参数作为旗舰模型。最终训练由Meta的Grand Teton AI服务器上的16000个Nvidia H100 GPU芯片提供支持,并采用复杂系统并行运行数据和权重。
第三个创新在于训练后阶段。每次训练结束后,Llama 3.1都会经历一个由人类反馈指导的严格过程,类似于OpenAI和其他公司用来优化模型输出的方法。这包括“监督微调”,模型通过人类偏好学习区分理想和非理想输出。
Meta随后引入了一种名为“直接偏好优化”(DPO)的创新,这是今年由斯坦福大学AI学者开创的一种更高效的强化学习方法。他们还通过展示使用API调用解决的提示示例,训练Llama 3.1使用“工具”,如外部搜索引擎,从而提升其“零样本”工具使用能力。
为了对抗“幻觉”,团队精心挑选了特定训练数据并创建了原创问答对,微调模型以仅回答其知道的内容,并拒绝回答不确定的问题。
在整个开发过程中,Meta研究人员强调简单性,指出高质量数据、规模和直接的方法始终带来最佳结果。尽管他们探索了更复杂的架构和训练方案,但发现增加的复杂性并不足以证明其益处。
Llama 3.1 405B的规模是开源模型的一个里程碑,通常被商业闭源模型所压制。Meta的首席执行官马克·扎克伯格强调了其经济优势,指出开发者运行Llama 3.1 405B的推理成本仅为使用GPT-4o等模型的一半。
扎克伯格还将开源AI视为软件的自然发展,类比Unix从专有系统演变为更先进、安全和广泛的生态系统,这得益于开源开发。
然而,正如ZDNET的Steven Vaughan-Nichols指出的,Meta在Hugging Face上发布的代码缺少一些细节,且代码许可证比典型的开源许可证更严格。因此,尽管Llama 3.1算是开源,但并非完全如此。然而,其训练过程的详细程度令人耳目一新,尤其是当OpenAI和Google等巨头对其闭源模型越来越讳莫如深时。










 OpenAI 停用 o3 和 GPT-4.5 大型模型
作为人工智能领域的领军企业,OpenAI的每一步技术举措都会在业界引发巨大反响。近日,该公司发布了一项重大公告:将从其ChatGPT平台退役两个经典模型——o3和GPT-4.5。 常被称为“人文天才”的 GPT-4.5 将于 6 月 27 日下线,而以硬核推理能力著称的 o3 则将于 8 月 26 日跟进。经典模型的退役引发怀旧之情这一突如其来的消息让许多付费老用户难以接受,社交社区和讨论区很快充
OpenAI 停用 o3 和 GPT-4.5 大型模型
作为人工智能领域的领军企业,OpenAI的每一步技术举措都会在业界引发巨大反响。近日,该公司发布了一项重大公告:将从其ChatGPT平台退役两个经典模型——o3和GPT-4.5。 常被称为“人文天才”的 GPT-4.5 将于 6 月 27 日下线,而以硬核推理能力著称的 o3 则将于 8 月 26 日跟进。经典模型的退役引发怀旧之情这一突如其来的消息让许多付费老用户难以接受,社交社区和讨论区很快充
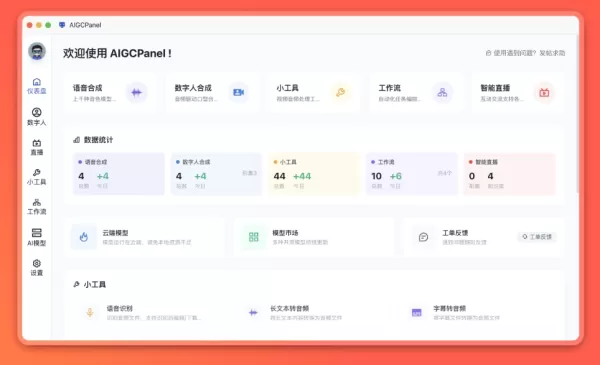 AIGCPanel 2.0.0 重大更新:工作流引擎开启自动化数字人创作的新纪元
AIGCPanel 作为一款强大的本地数字人创作工具,刚刚发布了 2.0.0 版本——被誉为“迄今为止最重大的更新”。 此次核心升级通过工作流引擎和CLI命令行工具,将数字人合成、语音克隆及音视频处理功能有机整合,从而解决了当前AI创作工具分散的问题,实现了从手动组装到自动化生产的转变。1. 核心升级:定义逻辑流程,一键输出AIGCPanel 2.0.0 的突出新功能是工作流引擎:基于节点的组合:
AIGCPanel 2.0.0 重大更新:工作流引擎开启自动化数字人创作的新纪元
AIGCPanel 作为一款强大的本地数字人创作工具,刚刚发布了 2.0.0 版本——被誉为“迄今为止最重大的更新”。 此次核心升级通过工作流引擎和CLI命令行工具,将数字人合成、语音克隆及音视频处理功能有机整合,从而解决了当前AI创作工具分散的问题,实现了从手动组装到自动化生产的转变。1. 核心升级:定义逻辑流程,一键输出AIGCPanel 2.0.0 的突出新功能是工作流引擎:基于节点的组合:
 BuzzFeed 推出专注于垃圾应用的 AI 子公司
在面临重大经营危机的背景下,曾经的数字媒体巨头BuzzFeed正启动一项由人工智能驱动的雄心勃勃的自救实验。 在最近举行的SXSW大会上,联合创始人兼首席执行官乔纳·佩雷蒂宣布成立一家名为Branch Office的子公司,旨在通过一系列由人工智能驱动的消费者应用程序,重新定义“软件即内容”的商业模式。核心产品组合:融合网络梗与社交媒体Branch Office 推出了三款核心应用,每款都旨在捕捉
BuzzFeed 推出专注于垃圾应用的 AI 子公司
在面临重大经营危机的背景下,曾经的数字媒体巨头BuzzFeed正启动一项由人工智能驱动的雄心勃勃的自救实验。 在最近举行的SXSW大会上,联合创始人兼首席执行官乔纳·佩雷蒂宣布成立一家名为Branch Office的子公司,旨在通过一系列由人工智能驱动的消费者应用程序,重新定义“软件即内容”的商业模式。核心产品组合:融合网络梗与社交媒体Branch Office 推出了三款核心应用,每款都旨在捕捉

2026最新推荐:探索最适合用于短剧故事板制作的AI艺术生成工具。我们精心挑选了众多顶级工具,帮助您创作出引人入胜的幻想角色和都市浪漫角色。您可以对比免费与付费选项,查看实际测试结果,从而找到最适合自己的创意工具。XIX.AI还会每周更新排名并提供专家分析,让您立即开始将故事可视化呈现吧!
10 个工具
xix.ai

在XIX.AI上,发现2026年最适合用于广播和播客制作的AI脚本工具。我们精心挑选的这些高评分工具能够提供强大的功能,帮助您快速制作出引人入胜的音频广告。通过实际测试和每周更新的排名,您可以了解免费选项与付费选项之间的差异。今天就释放您的创造力吧!
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最佳 AI 合同审查软件。我们精心筛选的顶级榜单汇集了功能强大的工具,能够即时发现法律漏洞和合规风险。通过实际测试和每周更新的排名,对比免费与付费选项。找到能彻底改变游戏规则的解决方案,实现安全、高效的合同分析。立即探索这本权威指南。
10 个工具
xix.ai

探索2026年最适合制作中文动画的人工智能工具。我们精心挑选的顶级列表中包含了各种强大的工具,能够帮助你创建出令人惊叹的网络小说角色和漫画头像。通过实际测试来对比免费选项和付费选项,找到最适合你的创作工具,今天就在XIX.AI上将你的故事变为现实吧。
10 个工具
xix.ai

立即访问 XIX.AI,探索 2026 年最优秀的漫画 AI 自动上色工具。我们精心筛选的清单汇集了广受好评、颠覆行业的解决方案,这些工具能以零一致性错误的方式应用平涂色彩,从而大幅提升您的工作效率。通过免费版与付费版的对比分析、实际测试以及每周更新的排行榜,找到最适合您的工具。立即开启您的 AI 优势。
10 个工具
xix.ai

探索2026年最优秀的AI人物设定生成工具,助您塑造鲜活立体的角色。XIX.AI精心筛选的这份清单汇集了广受好评、颠覆传统的工具,能够生成具有内在逻辑的动机和致命缺陷。通过实际测试对比免费与付费选项。立即释放您的叙事潜能。
10 个工具
xix.ai

Interessant, dass Meta Llama 3.1 als erstes Open-Source-Modell bezeichnet. Aber wer kann so ein riesiges Modell eigentlich sinnvoll nutzen? Für kleine Unternehmen bestimmt zu teuer im Betrieb. 🧐
Wow, Llama 3.1 sounds like a game-changer! Open-source and frontier-level? That’s huge for AI devs. Curious how it stacks up against closed models like GPT-4. 😎
O Llama 3.1 é incrível! Adoro que seja de código aberto, é como ter um superpoder no meu arsenal de programação. No começo pode ser um pouco confuso, mas vale a pena experimentar se você gosta de IA! 🚀
ラマ3.1は本当にすごい!オープンソースで使えるのが最高です。最初は少し圧倒されましたが、慣れると便利です。AIに興味があるなら、ぜひ試してみてください!🚀
¡Llama 3.1 es una bestia! Me encanta que sea de código abierto, es como tener un superpoder en mi arsenal de programación. Al principio puede ser un poco abrumador, pero definitivamente vale la pena probarlo si te interesa la IA! 🚀
¡Llama 3.1 de Meta es una maravilla! Me sorprende cómo están empujando los límites con la IA de código abierto. El rendimiento es genial, pero desearía que hubiera más documentación para principiantes. De todas formas, ¡es una herramienta que hay que probar! 💪













