
















 首頁
首頁Unsloth Studio 正式推出,成為首個本地視覺大型語言模型微調平台,將 VRAM 使用量降低 70%
知名的高效能微調函式庫 Unsloth AI 已正式推出Unsloth Studio。這個開源且無需編碼的視覺化介面,旨在大幅降低軟體工程師微調大型語言模型(LLMs)的門檻,讓開發者能完全避開複雜的 CUDA 環境設定及高昂的硬體成本。
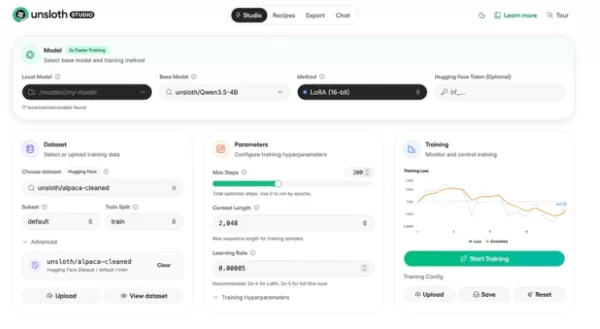
Unsloth Studio 的底層技術採用以 Triton 編寫的自訂反向傳播核心,相較於標準微調框架實現了質的飛躍:
訓練速度倍增:微調效率最高可提升兩倍。
記憶體使用量減少 70%:在不犧牲模型精準度的前提下,大幅降低對 GPU 記憶體的依賴。
支援消費級 GPU:開發者現在可以在單張消費級 GPU(如 RTX 4090 或 5090)上微調參數規模介於 80 億至 700 億之間的模型(例如 Llama3.3 和 DeepSeek-R1),而過去這類任務需要多 GPU 叢集才能完成。
此平台將資料準備、訓練與部署的完整生命週期整合至直觀的網頁介面中:
視覺化資料配方:採用節點式工作流程,支援自動匯入 PDF 和 JSONL 等多種格式,並可利用 NVIDIA DataDesigner 將非結構化文件轉化為結構化指令資料集。
強化學習支援:內建 GRPO(群組相對策略優化)支援。這項源自 DeepSeek-R1 的技術,讓使用者能在本地硬體上訓練具備多步驟邏輯推理能力的 AI,無需額外的「批評模型」。
一鍵匯出與部署:支援匯出為 GGUF、vLLM 或 Ollama 格式,無縫銜接訓練檢查點與生產推論環境。
隨著 Unsloth Studio 的發布,大型模型微調正從依賴昂貴的雲端 SaaS 服務,轉向更私密且具成本效益的本地開發模式。它不僅能立即相容於 Llama 4 和 Qwen 系列,更提供強大的工具,讓企業能完全自主地進行客製化模型開發。
技術詳情:https://unsloth.ai/docs/new/studio
相關文章
 一項人類學研究指出,經過潤飾的人工智慧產出內容會削弱人類的思考能力
當你看到人工智慧瞬間產出一段結構完善、邏輯清晰的程式碼或文件時,是否會不假思索地選擇相信它?根據AIbase 的報導,領先的人工智慧公司Anthropic最近發布了一份名為《AI 流暢度指數》的研究報告。 在分析了近 10,000 份匿名Claude對話樣本後,這項研究揭露了一個令人擔憂的趨勢:AI 產出的內容看起來越是精緻,使用者就越不願意去查證事實。報告揭示,當Claude產出小型應用程式、網
英國各政府部門就人工智慧資料中心的能源需求產生分歧
英國政府正面臨一項重大挑戰:在推動清潔能源的同時,力求成為人工智慧領域的全球領導者。然而,負責這些目標的各部會之間卻顯現出嚴重的分歧。 科學、創新與技術部(DSIT)與能源安全及淨零部(DESNZ)對於人工智慧資料中心的未來電力需求,持著截然不同的預測。DSIT預測,到2030年,人工智慧資料中心將需要6吉瓦的電力;而DESNZ的估計則不到該數字的十分之一。 這項差距引起了非營利組織「Foxglo
中國網絡空間管理局規定,人工智慧生成及虛構的短影片必須標註
中國網絡信息辦公室已推出一項全面計劃,旨在規範短視頻內容標註,要求各平台提供六項必備標籤——包括「AI生成內容」——這標誌著短視頻治理進入了強制透明化的新時代。為解決內容來源不明及難以區分事實與虛構等問題,監管機構在先前與抖音、快手、騰訊及百度等主要平台進行的試點計畫基礎上,現已將內容標註列為短影片發布流程中的強制步驟。 發布者必須從六個選項中選擇其一:「虛構戲劇化」、「AI生成」、「含行銷資訊」
相關專題推薦
漫畫創作
一項人類學研究指出,經過潤飾的人工智慧產出內容會削弱人類的思考能力
當你看到人工智慧瞬間產出一段結構完善、邏輯清晰的程式碼或文件時,是否會不假思索地選擇相信它?根據AIbase 的報導,領先的人工智慧公司Anthropic最近發布了一份名為《AI 流暢度指數》的研究報告。 在分析了近 10,000 份匿名Claude對話樣本後,這項研究揭露了一個令人擔憂的趨勢:AI 產出的內容看起來越是精緻,使用者就越不願意去查證事實。報告揭示,當Claude產出小型應用程式、網
英國各政府部門就人工智慧資料中心的能源需求產生分歧
英國政府正面臨一項重大挑戰:在推動清潔能源的同時,力求成為人工智慧領域的全球領導者。然而,負責這些目標的各部會之間卻顯現出嚴重的分歧。 科學、創新與技術部(DSIT)與能源安全及淨零部(DESNZ)對於人工智慧資料中心的未來電力需求,持著截然不同的預測。DSIT預測,到2030年,人工智慧資料中心將需要6吉瓦的電力;而DESNZ的估計則不到該數字的十分之一。 這項差距引起了非營利組織「Foxglo
中國網絡空間管理局規定,人工智慧生成及虛構的短影片必須標註
中國網絡信息辦公室已推出一項全面計劃,旨在規範短視頻內容標註,要求各平台提供六項必備標籤——包括「AI生成內容」——這標誌著短視頻治理進入了強制透明化的新時代。為解決內容來源不明及難以區分事實與虛構等問題,監管機構在先前與抖音、快手、騰訊及百度等主要平台進行的試點計畫基礎上,現已將內容標註列為短影片發布流程中的強制步驟。 發布者必須從六個選項中選擇其一:「虛構戲劇化」、「AI生成」、「含行銷資訊」
相關專題推薦
漫畫創作
 漫畫頂尖 AI 自動上色工具:零一致性錯誤地套用平面色彩
漫畫頂尖 AI 自動上色工具:零一致性錯誤地套用平面色彩
立即前往 XIX.AI,探索 2026 年最優秀的漫畫 AI 自動上色工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的解決方案,這些工具能以零一致性錯誤的方式套用平面色彩,大幅提升您的工作效率。透過免費與付費版本的比較、實際測試結果,以及每週更新的排行榜,找到最適合您的工具。立即解鎖您的 AI 優勢。
 10 個工具
10 個工具
 xix.ai
寫作
頂尖 AI 角色設定生成工具:創造一致的角色動機與致命弱點
xix.ai
寫作
頂尖 AI 角色設定生成工具:創造一致的角色動機與致命弱點
探索 2026 年最優秀的 AI 角色設定生成工具,打造立體鮮明的角色。XIX.AI 精心整理的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具能生成一貫的動機與致命缺陷。透過實際測試,比較免費與付費選項的差異。立即釋放您的說故事潛能。
10 個工具
xix.ai
商業
頂尖 AI 定價優化軟體:追蹤競爭對手並自動調整商店價格
立即在 XIX.AI 探索 2026 年最佳 AI 定價優化軟體。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具不僅能追蹤競爭對手,還能自動調整您的商店價格,以實現利潤最大化。透過實際測試,比較免費與付費方案的差異。立即掌握您的定價優勢。
10 個工具
xix.ai
代碼
最佳 AI 程式碼審查工具:自動化確保程式碼整潔度,並重構舊版儲存庫檔案
立即在 XIX.AI 探索 2026 年最佳 AI 程式碼審查工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,可自動確保程式碼符合規範,並重構舊版儲存庫檔案。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即掌握您的 AI 競爭優勢。
10 個工具
xix.ai
文字轉語音
專為閱讀障礙設計的頂尖 AI 語音合成應用程式:協助學生提升學習與閱讀效率
探索 2026 年最新精選、專為閱讀障礙者設計的頂級 AI 語音合成(TTS)應用程式。我們的專家評比將免費與付費工具進行對照,重點介紹能提升閱讀效率與學習成效的強大功能。發掘這些必試且能帶來革命性改變的解決方案,釋放學生的潛能。立即前往 XIX.AI 展開您的探索之旅。
10 個工具
xix.ai
漫畫創作
少年漫畫頂尖 AI 生成器:打造高張力動作場面與能量特效
立即前往 XIX.AI,探索 2026 年最優秀的少年漫畫 AI 生成工具。我們精心挑選的頂級清單,匯集了能打造高張力動作場面與動態能量特效的強大工具。透過實際測試,比較免費與付費選項的差異。釋放您的創作潛能,今天就開始打造史詩級漫畫吧!
15 個工具
xix.ai

 評論 (0)
0/500
評論 (0)
0/500
知名的高效能微調函式庫 Unsloth AI 已正式推出Unsloth Studio。這個開源且無需編碼的視覺化介面,旨在大幅降低軟體工程師微調大型語言模型(LLMs)的門檻,讓開發者能完全避開複雜的 CUDA 環境設定及高昂的硬體成本。
Unsloth Studio 的底層技術採用以 Triton 編寫的自訂反向傳播核心,相較於標準微調框架實現了質的飛躍:
訓練速度倍增:微調效率最高可提升兩倍。
記憶體使用量減少 70%:在不犧牲模型精準度的前提下,大幅降低對 GPU 記憶體的依賴。
支援消費級 GPU:開發者現在可以在單張消費級 GPU(如 RTX 4090 或 5090)上微調參數規模介於 80 億至 700 億之間的模型(例如 Llama3.3 和 DeepSeek-R1),而過去這類任務需要多 GPU 叢集才能完成。
此平台將資料準備、訓練與部署的完整生命週期整合至直觀的網頁介面中:
視覺化資料配方:採用節點式工作流程,支援自動匯入 PDF 和 JSONL 等多種格式,並可利用 NVIDIA DataDesigner 將非結構化文件轉化為結構化指令資料集。
強化學習支援:內建 GRPO(群組相對策略優化)支援。這項源自 DeepSeek-R1 的技術,讓使用者能在本地硬體上訓練具備多步驟邏輯推理能力的 AI,無需額外的「批評模型」。
一鍵匯出與部署:支援匯出為 GGUF、vLLM 或 Ollama 格式,無縫銜接訓練檢查點與生產推論環境。
隨著 Unsloth Studio 的發布,大型模型微調正從依賴昂貴的雲端 SaaS 服務,轉向更私密且具成本效益的本地開發模式。它不僅能立即相容於 Llama 4 和 Qwen 系列,更提供強大的工具,讓企業能完全自主地進行客製化模型開發。
技術詳情:https://unsloth.ai/docs/new/studio










 一項人類學研究指出,經過潤飾的人工智慧產出內容會削弱人類的思考能力
當你看到人工智慧瞬間產出一段結構完善、邏輯清晰的程式碼或文件時,是否會不假思索地選擇相信它?根據AIbase 的報導,領先的人工智慧公司Anthropic最近發布了一份名為《AI 流暢度指數》的研究報告。 在分析了近 10,000 份匿名Claude對話樣本後,這項研究揭露了一個令人擔憂的趨勢:AI 產出的內容看起來越是精緻,使用者就越不願意去查證事實。報告揭示,當Claude產出小型應用程式、網
一項人類學研究指出,經過潤飾的人工智慧產出內容會削弱人類的思考能力
當你看到人工智慧瞬間產出一段結構完善、邏輯清晰的程式碼或文件時,是否會不假思索地選擇相信它?根據AIbase 的報導,領先的人工智慧公司Anthropic最近發布了一份名為《AI 流暢度指數》的研究報告。 在分析了近 10,000 份匿名Claude對話樣本後,這項研究揭露了一個令人擔憂的趨勢:AI 產出的內容看起來越是精緻,使用者就越不願意去查證事實。報告揭示,當Claude產出小型應用程式、網
 英國各政府部門就人工智慧資料中心的能源需求產生分歧
英國政府正面臨一項重大挑戰:在推動清潔能源的同時,力求成為人工智慧領域的全球領導者。然而,負責這些目標的各部會之間卻顯現出嚴重的分歧。 科學、創新與技術部(DSIT)與能源安全及淨零部(DESNZ)對於人工智慧資料中心的未來電力需求,持著截然不同的預測。DSIT預測,到2030年,人工智慧資料中心將需要6吉瓦的電力;而DESNZ的估計則不到該數字的十分之一。 這項差距引起了非營利組織「Foxglo
英國各政府部門就人工智慧資料中心的能源需求產生分歧
英國政府正面臨一項重大挑戰:在推動清潔能源的同時,力求成為人工智慧領域的全球領導者。然而,負責這些目標的各部會之間卻顯現出嚴重的分歧。 科學、創新與技術部(DSIT)與能源安全及淨零部(DESNZ)對於人工智慧資料中心的未來電力需求,持著截然不同的預測。DSIT預測,到2030年,人工智慧資料中心將需要6吉瓦的電力;而DESNZ的估計則不到該數字的十分之一。 這項差距引起了非營利組織「Foxglo
 中國網絡空間管理局規定,人工智慧生成及虛構的短影片必須標註
中國網絡信息辦公室已推出一項全面計劃,旨在規範短視頻內容標註,要求各平台提供六項必備標籤——包括「AI生成內容」——這標誌著短視頻治理進入了強制透明化的新時代。為解決內容來源不明及難以區分事實與虛構等問題,監管機構在先前與抖音、快手、騰訊及百度等主要平台進行的試點計畫基礎上,現已將內容標註列為短影片發布流程中的強制步驟。 發布者必須從六個選項中選擇其一:「虛構戲劇化」、「AI生成」、「含行銷資訊」
中國網絡空間管理局規定,人工智慧生成及虛構的短影片必須標註
中國網絡信息辦公室已推出一項全面計劃,旨在規範短視頻內容標註,要求各平台提供六項必備標籤——包括「AI生成內容」——這標誌著短視頻治理進入了強制透明化的新時代。為解決內容來源不明及難以區分事實與虛構等問題,監管機構在先前與抖音、快手、騰訊及百度等主要平台進行的試點計畫基礎上,現已將內容標註列為短影片發布流程中的強制步驟。 發布者必須從六個選項中選擇其一:「虛構戲劇化」、「AI生成」、「含行銷資訊」

立即前往 XIX.AI,探索 2026 年最優秀的漫畫 AI 自動上色工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的解決方案,這些工具能以零一致性錯誤的方式套用平面色彩,大幅提升您的工作效率。透過免費與付費版本的比較、實際測試結果,以及每週更新的排行榜,找到最適合您的工具。立即解鎖您的 AI 優勢。
10 個工具
xix.ai

探索 2026 年最優秀的 AI 角色設定生成工具,打造立體鮮明的角色。XIX.AI 精心整理的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具能生成一貫的動機與致命缺陷。透過實際測試,比較免費與付費選項的差異。立即釋放您的說故事潛能。
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 定價優化軟體。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具不僅能追蹤競爭對手,還能自動調整您的商店價格,以實現利潤最大化。透過實際測試,比較免費與付費方案的差異。立即掌握您的定價優勢。
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 程式碼審查工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,可自動確保程式碼符合規範,並重構舊版儲存庫檔案。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即掌握您的 AI 競爭優勢。
10 個工具
xix.ai

探索 2026 年最新精選、專為閱讀障礙者設計的頂級 AI 語音合成(TTS)應用程式。我們的專家評比將免費與付費工具進行對照,重點介紹能提升閱讀效率與學習成效的強大功能。發掘這些必試且能帶來革命性改變的解決方案,釋放學生的潛能。立即前往 XIX.AI 展開您的探索之旅。
10 個工具
xix.ai

立即前往 XIX.AI,探索 2026 年最優秀的少年漫畫 AI 生成工具。我們精心挑選的頂級清單,匯集了能打造高張力動作場面與動態能量特效的強大工具。透過實際測試,比較免費與付費選項的差異。釋放您的創作潛能,今天就開始打造史詩級漫畫吧!
15 個工具
xix.ai













