
















 Heim
HeimGraphenfaltungsnetze revolutionieren das Training in Graphendatenbanken
In unserer zunehmend vernetzten digitalen Landschaft ermöglichen Graphen-Technologien nie dagewesene Einblicke. Graphdatenbanken revolutionieren die Speicherung beziehungsreicher Daten, während Graph Convolutional Networks (GCNs) die Analyse dieser komplexen Verbindungen verändern. Dieser Artikel untersucht die leistungsstarke Schnittmenge dieser Technologien und zeigt, wie datenbankinternes GCN-Training prädiktive Analysen beschleunigt und gleichzeitig die Datenintegrität erhält. Entdecken Sie praktische Implementierungsstrategien, messbare Leistungsvorteile und reale Anwendungen in unserer umfassenden Fallstudie.
Wichtige Punkte
Graphdatenbanken optimieren die Speicher- und Abfrageleistung für vernetzte Datensätze.
GCNs nutzen die Graphentopologie, um die Genauigkeit des maschinellen Lernens über herkömmliche Methoden hinaus zu verbessern.
Durch datenbankinternes Training werden kostspielige Datenübertragungen zwischen Systemen vermieden.
Native Graphenverarbeitung ermöglicht eine kontinuierliche Modellverfeinerung mit neuen Daten.
Die Architektur von TigerGraph unterstützt auf einzigartige Weise skalierbare datenbankinterne GCN-Implementierungen.
Verständnis von Graph Convolutional Networks und Graphdatenbanken
Was ist ein Graph Convolutional Network (GCN)?

Graph Convolutional Networks stellen eine neuronale Architektur dar, die speziell für relationale Datenstrukturen entwickelt wurde. Während herkömmliche neuronale Netze gitterbasierte (Bilder) oder sequenzielle (Text) Eingaben verarbeiten, arbeiten GCNs direkt mit Graphentopologien, wobei sie Verbindungsmuster während des Lernens bewahren und nutzen. Diese Netze aggregieren schrittweise Nachbarschaftsinformationen durch lokalisierte Operationen und generieren anspruchsvolle Knoteneinbettungen, die sowohl intrinsische Attribute als auch kontextuelle Beziehungen kodieren.
Ihre Architektur erweist sich als besonders effektiv für die Analyse sozialer Netzwerke, die Molekularforschung, Empfehlungssysteme und Wissensgraphenanwendungen, bei denen der Beziehungskontext einen erheblichen Einfluss auf die Ergebnisse hat. Durch die iterative Weitergabe von Nachrichten zwischen verbundenen Knoten übertreffen GCNs herkömmliche Algorithmen, indem sie die Netzwerkdynamik höherer Ordnung erfassen und genauere Vorhersagen durch gelernte Repräsentationen anstelle handgefertigter Merkmale liefern.
Was ist eine Graphdatenbank?
Im Gegensatz zu tabellarischen Datenbanken verwenden Graphdatenbanken Knoten-Kanten-Knoten-Strukturen, die reale Beziehungen nativ widerspiegeln. Entitäten werden zu Knoten, während sich ihre Verbindungen als Kanten manifestieren - so entstehen intuitive Datenmodelle, die ein effizientes Traversieren von Beziehungen ohne komplexe Verknüpfungen ermöglichen. Diese Architektur bietet eine überragende Leistung für die Erkennung von Betrug, die Abbildung von Lieferketten, Netzwerkanalysen und Empfehlungsmaschinen, bei denen Beziehungsmuster den Geschäftswert bestimmen.
Durch die explizite Darstellung von Verbindungen können sich Graphdatenbanken organisch weiterentwickeln und neue Beziehungstypen und Schemaänderungen ohne kostspielige Migrationen aufnehmen. Ihre Abfrageeffizienz wächst linear und nicht exponentiell mit der Komplexität der Beziehungen, was sie für moderne vernetzte Datenanwendungen unverzichtbar macht. Fortgeschrittene Systeme wie TigerGraph erweitern diese Fähigkeiten durch Parallelverarbeitung und Echtzeit-Analysefunktionen.
Warum GCNs in einer Graphdatenbank trainieren?
Die Konvergenz von GCN-Training und Graphdatenbank-Operationen schafft mehrere strategische Vorteile: Vereinfachte Datenpipelines beseitigen den Transformations-Overhead, native Graphenoperatoren beschleunigen die Berechnungen und Echtzeit-Updates erhalten die Modellrelevanz - und das alles in einer einheitlichen Umgebung. Diese architektonische Synergie reduziert die Komplexität der Infrastruktur erheblich und verbessert gleichzeitig die Modellleistung bei sich entwickelnden Datensätzen.
Hauptvorteile des Trainings von GCNs innerhalb einer Graphendatenbank
Reduzierte Datenverschiebung
Herkömmliche Analysearchitekturen leiden unter kostspieligen Extraktions-, Transformations- und Ladevorgängen zwischen Speicher- und Rechenumgebungen. Das datenbankinterne Training beseitigt diese Engpässe, indem Petabytes von Graphdaten in der Datenbank verbleiben und die Berechnungen dort stattfinden, wo die Informationen vorhanden sind, anstatt sie über Netzwerke zu übertragen.
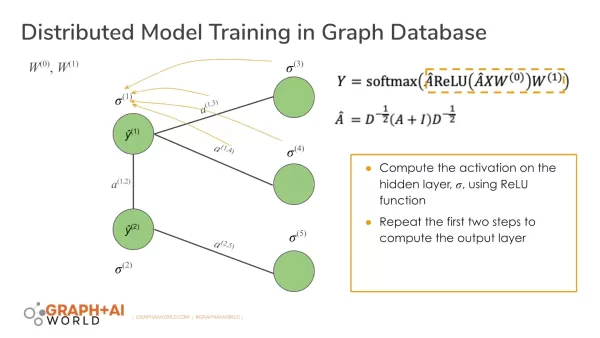
Diese lokalisierte Verarbeitung reduziert die Latenzzeit um Größenordnungen und minimiert gleichzeitig die Speicherduplizierung - ein entscheidender Vorteil beim Training von umfangreichen Wissensgraphen oder dynamischen sozialen Netzwerken, bei denen Terabytes miteinander verbunden sein können.
Verbesserte Leistung
Graphdatenbanken implementieren spezielle Indizes und Traversal-Algorithmen, die für Verbindungsmuster optimiert sind, die von herkömmlichen Indizes nur unzureichend unterstützt werden. Durch die Nutzung dieser nativen Optimierungen während des Trainings erreichen GCNs einen überragenden Durchsatz - besonders vorteilhaft bei der Ausführung der für das Graphenlernen grundlegenden Nachbarschaftsaggregationsschritte. Verteilte Graphenarchitekturen skalieren diese Vorteile weiter horizontal.
Modellaktualisierungen in Echtzeit
Dynamische Umgebungen erfordern Modelle, die sich zusammen mit ihren Datenquellen weiterentwickeln. Datenbankinterne Trainingspipelines ermöglichen kontinuierliche Lernworkflows, bei denen neue Knoten, Kanten und Attribute automatisch und ohne komplette Neuausbildung integriert werden. Dies ist von unschätzbarem Wert für die Finanzüberwachung, IoT-Netzwerke und Empfehlungssysteme, bei denen sich die Konzeptabweichung auf die Modellgültigkeit auswirkt.
Vereinfachte Infrastruktur
Die Aufrechterhaltung separater Analyse- und Betriebssysteme führt zu architektonischer Komplexität und Synchronisierungsproblemen. Integrierte Plattformen konsolidieren Graphenspeicherung, -verarbeitung und maschinelles Lernen und reduzieren so den administrativen Aufwand bei gleichzeitiger Verbesserung der Ressourcennutzung durch gemeinsam genutzte Rechenressourcen.
Training von GCNs innerhalb von TigerGraph
Datenspeicherung und Graphenerstellung
TigerGraphs Schema-First-Ansatz stellt die korrekte Modellierung von Domänenbeziehungen vor der Aufnahme sicher. Flexible Definitionen von Knoten und Kanten ermöglichen die Modellierung komplexer Eigenschaftsgraphen - sei es die Modellierung biomedizinischer Interaktionen, von Lieferkettennetzwerken oder digitalen Zwillingen.
GCN-Implementierung
TigerGraphs Turing-komplette GSQL-Sprache unterstützt die Implementierung anspruchsvoller neuronaler Architekturen, einschließlich Aufmerksamkeitsmechanismen und Sampling-Strategien - und das alles unter Nutzung der optimierten Speicher- und Parallelverarbeitungsfunktionen der Datenbank.
Training und Vorhersage
Die verteilte Abfrage-Engine verarbeitet sowohl Batch- als auch Streaming-Graph-Aktualisierungen und ermöglicht so alles von der Offline-Modellentwicklung bis hin zu Online-Lernszenarien. Produktionseinsätze profitieren von TigerGraphs Hochverfügbarkeitsfunktionen, während die Latenzzeit im Millisekundenbereich bleibt.
FAQ
Welche Arten von Daten sind für GCNs in Graphdatenbanken geeignet?
GCNs bieten einen außergewöhnlichen Wert für Empfehlungssysteme, biologische Netzwerke, Cybersicherheitsgraphen und andere Bereiche, in denen Beziehungen prädiktive Signale enthalten, die mit traditionellem Feature Engineering nur schwer zu erfassen sind.
Was sind die Herausforderungen beim Training von GCNs innerhalb einer Graphdatenbank?
Eine wirksame Implementierung erfordert die Verbindung von Graphalgorithmen mit Fachwissen über neuronale Architektur. Die Ressourcenplanung wird entscheidend, wenn man mit Milliarden von Graphen zu tun hat - obwohl verteilte Architekturen diese Probleme entschärfen.
Was sind die Vorteile der Verwendung von TigerGraph für das Training von GCNs?
TigerGraphs parallele Verarbeitungsarchitektur bietet lineare Skalierbarkeit unter Beibehaltung von ACID-Garantien und unterstützt sowohl transaktionale als auch analytische Workloads auf massiven Graphen.
Verwandte Fragen
Wie sind die GCNs im Vergleich zu anderen graphbasierten maschinellen Lerntechniken?
Im Gegensatz zu flachen Einbettungen oder manuell erstellten Merkmalen lernen GCNs adaptive Repräsentationen, die sowohl auf lokale als auch auf globale Graphenstrukturen abgestimmt sind - und erreichen durch automatisiertes Merkmallernen oft eine höhere Genauigkeit.
Was ist die Zukunft von GCNs und Graphdatenbanken?
Die Konvergenz von Graphdatenbanken und differenzierbarer Programmierung verspricht transformative Anwendungen - von der Betrugserkennung in Echtzeit bis zur automatisierten wissenschaftlichen Entdeckung - wenn diese Technologien ausgereift sind.
Verwandter Artikel
 Snowflake investiert über 600 Millionen Dollar in maßgeschneiderte AWS-Chips für den Ausbau der KI im Unternehmensbereich
Snowflake, der Cloud-Datenriese, hat Pläne bekannt gegeben, in den nächsten sechs Jahren über 600 Millionen US-Dollar in den Erwerb von CPUs und KI-Beschleunigern der Graviton-Serie zu investieren, di
China Telecom investiert in Mianbi Intelligence und erhöht das Kapital für LLM und Dateninfrastruktur auf 713.000 Yuan
Das „Nationalteam“ und die führende Persönlichkeit der Tsinghua-Universität im Bereich der großen Modelle vertiefen ihre strategische Zusammenarbeit. Am 1. März 2026 unterzog sich die Beijing Mianbi I
Die Taotian Group treibt ihre KI-orientierte Umstrukturierung voran und gewährt Praktikanten kostenlose Token-Kontingente
Die TaoTian Group hat kürzlich den „AI Productivity Plan“ eingeführt, der darauf abzielt, die Integration von KI-Technologie in E-Commerce-Abläufe und F&E-Workflows durch die Zuweisung von Ressourcen
Empfehlungen zu verwandten Spezialthemen
Schreiben
Snowflake investiert über 600 Millionen Dollar in maßgeschneiderte AWS-Chips für den Ausbau der KI im Unternehmensbereich
Snowflake, der Cloud-Datenriese, hat Pläne bekannt gegeben, in den nächsten sechs Jahren über 600 Millionen US-Dollar in den Erwerb von CPUs und KI-Beschleunigern der Graviton-Serie zu investieren, di
China Telecom investiert in Mianbi Intelligence und erhöht das Kapital für LLM und Dateninfrastruktur auf 713.000 Yuan
Das „Nationalteam“ und die führende Persönlichkeit der Tsinghua-Universität im Bereich der großen Modelle vertiefen ihre strategische Zusammenarbeit. Am 1. März 2026 unterzog sich die Beijing Mianbi I
Die Taotian Group treibt ihre KI-orientierte Umstrukturierung voran und gewährt Praktikanten kostenlose Token-Kontingente
Die TaoTian Group hat kürzlich den „AI Productivity Plan“ eingeführt, der darauf abzielt, die Integration von KI-Technologie in E-Commerce-Abläufe und F&E-Workflows durch die Zuweisung von Ressourcen
Empfehlungen zu verwandten Spezialthemen
Schreiben
 Die besten KI-Assistenten für Xianxia und Wuxia: Verfassen Sie epische Kultivierungsgeschichten und Kampfkunst-Choreografien
Die besten KI-Assistenten für Xianxia und Wuxia: Verfassen Sie epische Kultivierungsgeschichten und Kampfkunst-Choreografien
Entdecken Sie die besten KI-Assistenten des Jahres 2026 für das Verfassen epischer Xianxia- und Wuxia-Geschichten. Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, mit denen Sie den Fortschritt der Kultivierung und die Choreografie von Kampfkünsten meistern können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit dem Schreiben!
 10 Tools
10 Tools
 xix.ai
Code
AI-Mobilanwendungsentwicklungstools: Erstellen Sie plattformübergreifenden Flutter- und React Native-Code auf Basis von Eingaben.
xix.ai
Code
AI-Mobilanwendungsentwicklungstools: Erstellen Sie plattformübergreifenden Flutter- und React Native-Code auf Basis von Eingaben.
Entdecken Sie die besten AI-Programmierwerkzeuge für mobile Anwendungen im Jahr 2026 – geeignet für Flutter und React Native. Unsere sorgfältig ausgewählte, hochbewertete Liste bietet leistungsstarke Lösungen, die es ermöglichen, plattformübergreifenden Code auf Basis von Vorgaben zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand realer Tests – beschleunigen Sie Ihre Entwicklung und erstellen Sie bessere Anwendungen. Erfahren Sie mehr über die Rangliste auf XIX.AI!
10 Tools
xix.ai
Code
Die besten KI-Generatoren für Chrome-Erweiterungen: Erstellen Sie individuelle Browser-Erweiterungen ganz ohne Programmierkenntnisse
Entdecken Sie die besten KI-Generatoren für Chrome-Erweiterungen des Jahres 2026 auf XIX.AI. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, unverzichtbare Tools, mit denen Sie ganz ohne Programmierkenntnisse individuelle Browser-Erweiterungen erstellen können. Vergleichen Sie kostenlose und kostenpflichtige Optionen, sehen Sie sich Praxistests an und steigern Sie Ihre Produktivität. Entdecken Sie die aktuellen Rankings und finden Sie noch heute das perfekte Tool für sich!
10 Tools
xix.ai
Text-zu-Sprache
Die beste künstliche Intelligenz für mehrsprachige TTS-Technologie: Erzeugung authentischer Sprache mit Muttersprachakzent in über 50 Sprachen
Entdecken Sie die besten KI-basierten, mehrsprachigen TTS-Tools von 2026 – sie ermöglichen eine authentische Aussprache in natürlicher Muttersprachentonart in über 50 Sprachen. Erfahren Sie mehr über unsere hochrangig bewerteten und sorgfältig ausgewählten Tools, inklusive Vergleichen zwischen kostenlosen und kostenpflichtigen Varianten sowie Ergebnissen aus realen Tests. Finden Sie das perfekte Tool für Ihre Bedürfnisse auf XIX.AI und öffnen Sie so neue Möglichkeiten für die globale Kommunikation – noch heute!
10 Tools
xix.ai
Besprechungsassistent
Die besten AI-Tools für die Automatisierung von Besprechungen – für eine schlauere und schnellere Zusammenarbeit
Entdecken Sie die besten und am meisten bewerteten AI-Tools für die Automatisierung von Besprechungen im Jahr 2026 – sie ermöglichen eine intelligente und schnellere Zusammenarbeit. Unsere sorgfältig ausgewählte Liste bietet leistungsstarke Lösungen, mit denen Sie Notizen, Zusammenfassungen und Aufgaben automatisch erstellen können. Vergleichen Sie kostenlose und bezahlte Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings – so steigern Sie die Produktivität Ihres Teams. Entdecken Sie die besten Tools jetzt bei XIX.AI.
10 Tools
xix.ai
Prompt
KI-Vorgaben für Infrastructure-as-Code: Terraform- und Docker-Konfigurationen sicher bereitstellen
Entdecken Sie die aktuellsten und am besten bewerteten KI-Prompts für Infrastructure-as-Code aus dem Jahr 2026. Die von XIX.AI zusammengestellte Auswahl hilft Ihnen dabei, Terraform- und Docker-Konfigurationen sicher bereitzustellen, Cloud-Setups zu automatisieren und die DevOps-Produktivität zu steigern. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entdecken Sie die Möglichkeiten jetzt und sichern Sie sich Ihren KI-Vorteil.
10 Tools
xix.ai

 Kommentare (4)
Kommentare (4)
![EricAllen]()
Graph-Datenbanken sind ja schon länger im Gespräch, aber dass jetzt auch noch GCNs dazukommen... das wird echt spannend! 😅 Ich frage mich, ob das in der Praxis schon stabil läuft oder ob da noch viel Forschungsarbeit nötig ist. Die Kombination klingt auf jeden Fall nach einem mächtigen Werkzeug für Netzwerkanalysen oder Empfehlungssysteme.
![GregoryAdams]()
이 기사가 요즘 뜨는 GNN에 대한 이야기네요. 제 전공 외에서는 '그래프'하면 차트(chart)를 떠올리던 친구들이 많아서, '인사이트를 발견하는 방식 자체를 바꾼다'는 설명이 와닿아요. 실제로 추천 시스템에서 얼마나 효과가 좋은지 궁금하네요. 기술 발전 속도에 조금 뒤쳐지는 느낌? 😅
![WilliamMiller]()
Finalmente algo que explica GCN de forma clara! Sempre tive dificuldade em entender como redes neurais aplicam em dados relacionais. Alguém já testou isso com dados de redes sociais? Será que detecta comunidades fake? 🤔
![RogerSanchez]()
이런 기술 발전이 실제 업계에서 어떻게 적용될지 상상을 해보니 정말 흥미롭네요. 특히 소셜 네트워크나 추천 시스템에서 어떤 변화를 가져올지 궁금해요. 근데 데이터 프라이버시 문제는 어떻게 해결할까요? 🤔
In unserer zunehmend vernetzten digitalen Landschaft ermöglichen Graphen-Technologien nie dagewesene Einblicke. Graphdatenbanken revolutionieren die Speicherung beziehungsreicher Daten, während Graph Convolutional Networks (GCNs) die Analyse dieser komplexen Verbindungen verändern. Dieser Artikel untersucht die leistungsstarke Schnittmenge dieser Technologien und zeigt, wie datenbankinternes GCN-Training prädiktive Analysen beschleunigt und gleichzeitig die Datenintegrität erhält. Entdecken Sie praktische Implementierungsstrategien, messbare Leistungsvorteile und reale Anwendungen in unserer umfassenden Fallstudie.
Wichtige Punkte
Graphdatenbanken optimieren die Speicher- und Abfrageleistung für vernetzte Datensätze.
GCNs nutzen die Graphentopologie, um die Genauigkeit des maschinellen Lernens über herkömmliche Methoden hinaus zu verbessern.
Durch datenbankinternes Training werden kostspielige Datenübertragungen zwischen Systemen vermieden.
Native Graphenverarbeitung ermöglicht eine kontinuierliche Modellverfeinerung mit neuen Daten.
Die Architektur von TigerGraph unterstützt auf einzigartige Weise skalierbare datenbankinterne GCN-Implementierungen.
Verständnis von Graph Convolutional Networks und Graphdatenbanken
Was ist ein Graph Convolutional Network (GCN)?
Graph Convolutional Networks stellen eine neuronale Architektur dar, die speziell für relationale Datenstrukturen entwickelt wurde. Während herkömmliche neuronale Netze gitterbasierte (Bilder) oder sequenzielle (Text) Eingaben verarbeiten, arbeiten GCNs direkt mit Graphentopologien, wobei sie Verbindungsmuster während des Lernens bewahren und nutzen. Diese Netze aggregieren schrittweise Nachbarschaftsinformationen durch lokalisierte Operationen und generieren anspruchsvolle Knoteneinbettungen, die sowohl intrinsische Attribute als auch kontextuelle Beziehungen kodieren.
Ihre Architektur erweist sich als besonders effektiv für die Analyse sozialer Netzwerke, die Molekularforschung, Empfehlungssysteme und Wissensgraphenanwendungen, bei denen der Beziehungskontext einen erheblichen Einfluss auf die Ergebnisse hat. Durch die iterative Weitergabe von Nachrichten zwischen verbundenen Knoten übertreffen GCNs herkömmliche Algorithmen, indem sie die Netzwerkdynamik höherer Ordnung erfassen und genauere Vorhersagen durch gelernte Repräsentationen anstelle handgefertigter Merkmale liefern.
Was ist eine Graphdatenbank?
Im Gegensatz zu tabellarischen Datenbanken verwenden Graphdatenbanken Knoten-Kanten-Knoten-Strukturen, die reale Beziehungen nativ widerspiegeln. Entitäten werden zu Knoten, während sich ihre Verbindungen als Kanten manifestieren - so entstehen intuitive Datenmodelle, die ein effizientes Traversieren von Beziehungen ohne komplexe Verknüpfungen ermöglichen. Diese Architektur bietet eine überragende Leistung für die Erkennung von Betrug, die Abbildung von Lieferketten, Netzwerkanalysen und Empfehlungsmaschinen, bei denen Beziehungsmuster den Geschäftswert bestimmen.
Durch die explizite Darstellung von Verbindungen können sich Graphdatenbanken organisch weiterentwickeln und neue Beziehungstypen und Schemaänderungen ohne kostspielige Migrationen aufnehmen. Ihre Abfrageeffizienz wächst linear und nicht exponentiell mit der Komplexität der Beziehungen, was sie für moderne vernetzte Datenanwendungen unverzichtbar macht. Fortgeschrittene Systeme wie TigerGraph erweitern diese Fähigkeiten durch Parallelverarbeitung und Echtzeit-Analysefunktionen.
Warum GCNs in einer Graphdatenbank trainieren?
Die Konvergenz von GCN-Training und Graphdatenbank-Operationen schafft mehrere strategische Vorteile: Vereinfachte Datenpipelines beseitigen den Transformations-Overhead, native Graphenoperatoren beschleunigen die Berechnungen und Echtzeit-Updates erhalten die Modellrelevanz - und das alles in einer einheitlichen Umgebung. Diese architektonische Synergie reduziert die Komplexität der Infrastruktur erheblich und verbessert gleichzeitig die Modellleistung bei sich entwickelnden Datensätzen.
Hauptvorteile des Trainings von GCNs innerhalb einer Graphendatenbank
Reduzierte Datenverschiebung
Herkömmliche Analysearchitekturen leiden unter kostspieligen Extraktions-, Transformations- und Ladevorgängen zwischen Speicher- und Rechenumgebungen. Das datenbankinterne Training beseitigt diese Engpässe, indem Petabytes von Graphdaten in der Datenbank verbleiben und die Berechnungen dort stattfinden, wo die Informationen vorhanden sind, anstatt sie über Netzwerke zu übertragen.
Diese lokalisierte Verarbeitung reduziert die Latenzzeit um Größenordnungen und minimiert gleichzeitig die Speicherduplizierung - ein entscheidender Vorteil beim Training von umfangreichen Wissensgraphen oder dynamischen sozialen Netzwerken, bei denen Terabytes miteinander verbunden sein können.
Verbesserte Leistung
Graphdatenbanken implementieren spezielle Indizes und Traversal-Algorithmen, die für Verbindungsmuster optimiert sind, die von herkömmlichen Indizes nur unzureichend unterstützt werden. Durch die Nutzung dieser nativen Optimierungen während des Trainings erreichen GCNs einen überragenden Durchsatz - besonders vorteilhaft bei der Ausführung der für das Graphenlernen grundlegenden Nachbarschaftsaggregationsschritte. Verteilte Graphenarchitekturen skalieren diese Vorteile weiter horizontal.
Modellaktualisierungen in Echtzeit
Dynamische Umgebungen erfordern Modelle, die sich zusammen mit ihren Datenquellen weiterentwickeln. Datenbankinterne Trainingspipelines ermöglichen kontinuierliche Lernworkflows, bei denen neue Knoten, Kanten und Attribute automatisch und ohne komplette Neuausbildung integriert werden. Dies ist von unschätzbarem Wert für die Finanzüberwachung, IoT-Netzwerke und Empfehlungssysteme, bei denen sich die Konzeptabweichung auf die Modellgültigkeit auswirkt.
Vereinfachte Infrastruktur
Die Aufrechterhaltung separater Analyse- und Betriebssysteme führt zu architektonischer Komplexität und Synchronisierungsproblemen. Integrierte Plattformen konsolidieren Graphenspeicherung, -verarbeitung und maschinelles Lernen und reduzieren so den administrativen Aufwand bei gleichzeitiger Verbesserung der Ressourcennutzung durch gemeinsam genutzte Rechenressourcen.
Training von GCNs innerhalb von TigerGraph
Datenspeicherung und Graphenerstellung
TigerGraphs Schema-First-Ansatz stellt die korrekte Modellierung von Domänenbeziehungen vor der Aufnahme sicher. Flexible Definitionen von Knoten und Kanten ermöglichen die Modellierung komplexer Eigenschaftsgraphen - sei es die Modellierung biomedizinischer Interaktionen, von Lieferkettennetzwerken oder digitalen Zwillingen.
GCN-Implementierung
TigerGraphs Turing-komplette GSQL-Sprache unterstützt die Implementierung anspruchsvoller neuronaler Architekturen, einschließlich Aufmerksamkeitsmechanismen und Sampling-Strategien - und das alles unter Nutzung der optimierten Speicher- und Parallelverarbeitungsfunktionen der Datenbank.
Training und Vorhersage
Die verteilte Abfrage-Engine verarbeitet sowohl Batch- als auch Streaming-Graph-Aktualisierungen und ermöglicht so alles von der Offline-Modellentwicklung bis hin zu Online-Lernszenarien. Produktionseinsätze profitieren von TigerGraphs Hochverfügbarkeitsfunktionen, während die Latenzzeit im Millisekundenbereich bleibt.
FAQ
Welche Arten von Daten sind für GCNs in Graphdatenbanken geeignet?
GCNs bieten einen außergewöhnlichen Wert für Empfehlungssysteme, biologische Netzwerke, Cybersicherheitsgraphen und andere Bereiche, in denen Beziehungen prädiktive Signale enthalten, die mit traditionellem Feature Engineering nur schwer zu erfassen sind.
Was sind die Herausforderungen beim Training von GCNs innerhalb einer Graphdatenbank?
Eine wirksame Implementierung erfordert die Verbindung von Graphalgorithmen mit Fachwissen über neuronale Architektur. Die Ressourcenplanung wird entscheidend, wenn man mit Milliarden von Graphen zu tun hat - obwohl verteilte Architekturen diese Probleme entschärfen.
Was sind die Vorteile der Verwendung von TigerGraph für das Training von GCNs?
TigerGraphs parallele Verarbeitungsarchitektur bietet lineare Skalierbarkeit unter Beibehaltung von ACID-Garantien und unterstützt sowohl transaktionale als auch analytische Workloads auf massiven Graphen.
Verwandte Fragen
Wie sind die GCNs im Vergleich zu anderen graphbasierten maschinellen Lerntechniken?
Im Gegensatz zu flachen Einbettungen oder manuell erstellten Merkmalen lernen GCNs adaptive Repräsentationen, die sowohl auf lokale als auch auf globale Graphenstrukturen abgestimmt sind - und erreichen durch automatisiertes Merkmallernen oft eine höhere Genauigkeit.
Was ist die Zukunft von GCNs und Graphdatenbanken?
Die Konvergenz von Graphdatenbanken und differenzierbarer Programmierung verspricht transformative Anwendungen - von der Betrugserkennung in Echtzeit bis zur automatisierten wissenschaftlichen Entdeckung - wenn diese Technologien ausgereift sind.










 Snowflake investiert über 600 Millionen Dollar in maßgeschneiderte AWS-Chips für den Ausbau der KI im Unternehmensbereich
Snowflake, der Cloud-Datenriese, hat Pläne bekannt gegeben, in den nächsten sechs Jahren über 600 Millionen US-Dollar in den Erwerb von CPUs und KI-Beschleunigern der Graviton-Serie zu investieren, di
Snowflake investiert über 600 Millionen Dollar in maßgeschneiderte AWS-Chips für den Ausbau der KI im Unternehmensbereich
Snowflake, der Cloud-Datenriese, hat Pläne bekannt gegeben, in den nächsten sechs Jahren über 600 Millionen US-Dollar in den Erwerb von CPUs und KI-Beschleunigern der Graviton-Serie zu investieren, di
 China Telecom investiert in Mianbi Intelligence und erhöht das Kapital für LLM und Dateninfrastruktur auf 713.000 Yuan
Das „Nationalteam“ und die führende Persönlichkeit der Tsinghua-Universität im Bereich der großen Modelle vertiefen ihre strategische Zusammenarbeit. Am 1. März 2026 unterzog sich die Beijing Mianbi I
China Telecom investiert in Mianbi Intelligence und erhöht das Kapital für LLM und Dateninfrastruktur auf 713.000 Yuan
Das „Nationalteam“ und die führende Persönlichkeit der Tsinghua-Universität im Bereich der großen Modelle vertiefen ihre strategische Zusammenarbeit. Am 1. März 2026 unterzog sich die Beijing Mianbi I
 Die Taotian Group treibt ihre KI-orientierte Umstrukturierung voran und gewährt Praktikanten kostenlose Token-Kontingente
Die TaoTian Group hat kürzlich den „AI Productivity Plan“ eingeführt, der darauf abzielt, die Integration von KI-Technologie in E-Commerce-Abläufe und F&E-Workflows durch die Zuweisung von Ressourcen
Die Taotian Group treibt ihre KI-orientierte Umstrukturierung voran und gewährt Praktikanten kostenlose Token-Kontingente
Die TaoTian Group hat kürzlich den „AI Productivity Plan“ eingeführt, der darauf abzielt, die Integration von KI-Technologie in E-Commerce-Abläufe und F&E-Workflows durch die Zuweisung von Ressourcen

Entdecken Sie die besten KI-Assistenten des Jahres 2026 für das Verfassen epischer Xianxia- und Wuxia-Geschichten. Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, mit denen Sie den Fortschritt der Kultivierung und die Choreografie von Kampfkünsten meistern können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit dem Schreiben!
10 Tools
xix.ai

Entdecken Sie die besten AI-Programmierwerkzeuge für mobile Anwendungen im Jahr 2026 – geeignet für Flutter und React Native. Unsere sorgfältig ausgewählte, hochbewertete Liste bietet leistungsstarke Lösungen, die es ermöglichen, plattformübergreifenden Code auf Basis von Vorgaben zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand realer Tests – beschleunigen Sie Ihre Entwicklung und erstellen Sie bessere Anwendungen. Erfahren Sie mehr über die Rangliste auf XIX.AI!
10 Tools
xix.ai

Entdecken Sie die besten KI-Generatoren für Chrome-Erweiterungen des Jahres 2026 auf XIX.AI. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, unverzichtbare Tools, mit denen Sie ganz ohne Programmierkenntnisse individuelle Browser-Erweiterungen erstellen können. Vergleichen Sie kostenlose und kostenpflichtige Optionen, sehen Sie sich Praxistests an und steigern Sie Ihre Produktivität. Entdecken Sie die aktuellen Rankings und finden Sie noch heute das perfekte Tool für sich!
10 Tools
xix.ai

Entdecken Sie die besten KI-basierten, mehrsprachigen TTS-Tools von 2026 – sie ermöglichen eine authentische Aussprache in natürlicher Muttersprachentonart in über 50 Sprachen. Erfahren Sie mehr über unsere hochrangig bewerteten und sorgfältig ausgewählten Tools, inklusive Vergleichen zwischen kostenlosen und kostenpflichtigen Varianten sowie Ergebnissen aus realen Tests. Finden Sie das perfekte Tool für Ihre Bedürfnisse auf XIX.AI und öffnen Sie so neue Möglichkeiten für die globale Kommunikation – noch heute!
10 Tools
xix.ai

Entdecken Sie die besten und am meisten bewerteten AI-Tools für die Automatisierung von Besprechungen im Jahr 2026 – sie ermöglichen eine intelligente und schnellere Zusammenarbeit. Unsere sorgfältig ausgewählte Liste bietet leistungsstarke Lösungen, mit denen Sie Notizen, Zusammenfassungen und Aufgaben automatisch erstellen können. Vergleichen Sie kostenlose und bezahlte Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings – so steigern Sie die Produktivität Ihres Teams. Entdecken Sie die besten Tools jetzt bei XIX.AI.
10 Tools
xix.ai

Entdecken Sie die aktuellsten und am besten bewerteten KI-Prompts für Infrastructure-as-Code aus dem Jahr 2026. Die von XIX.AI zusammengestellte Auswahl hilft Ihnen dabei, Terraform- und Docker-Konfigurationen sicher bereitzustellen, Cloud-Setups zu automatisieren und die DevOps-Produktivität zu steigern. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entdecken Sie die Möglichkeiten jetzt und sichern Sie sich Ihren KI-Vorteil.
10 Tools
xix.ai

Graph-Datenbanken sind ja schon länger im Gespräch, aber dass jetzt auch noch GCNs dazukommen... das wird echt spannend! 😅 Ich frage mich, ob das in der Praxis schon stabil läuft oder ob da noch viel Forschungsarbeit nötig ist. Die Kombination klingt auf jeden Fall nach einem mächtigen Werkzeug für Netzwerkanalysen oder Empfehlungssysteme.
이 기사가 요즘 뜨는 GNN에 대한 이야기네요. 제 전공 외에서는 '그래프'하면 차트(chart)를 떠올리던 친구들이 많아서, '인사이트를 발견하는 방식 자체를 바꾼다'는 설명이 와닿아요. 실제로 추천 시스템에서 얼마나 효과가 좋은지 궁금하네요. 기술 발전 속도에 조금 뒤쳐지는 느낌? 😅
Finalmente algo que explica GCN de forma clara! Sempre tive dificuldade em entender como redes neurais aplicam em dados relacionais. Alguém já testou isso com dados de redes sociais? Será que detecta comunidades fake? 🤔
이런 기술 발전이 실제 업계에서 어떻게 적용될지 상상을 해보니 정말 흥미롭네요. 특히 소셜 네트워크나 추천 시스템에서 어떤 변화를 가져올지 궁금해요. 근데 데이터 프라이버시 문제는 어떻게 해결할까요? 🤔













