
















 Heim
HeimGoogles Gemini 2.5 Flash entwickelt sich zu einem erschwinglichen KI-Kraftpaket
Google ist weiterhin führend im Bereich der künstlichen Intelligenz, wobei sein neuestes Modell Gemini 2.5 Flash großes Interesse weckt. Diese Version konzentriert sich nicht nur auf die Leistung, sondern auch auf die Zugänglichkeit und bietet eine kostengünstige KI-Lösung mit geringer Latenz, die für vielfältige Anwendungen geeignet ist – von hochvolumigen Echtzeit-Interaktionen bis hin zu generativen KI-Aufgaben. Hier erfahren Sie, warum dieses Modell eine bahnbrechende Entwicklung für Entwickler und Unternehmen darstellt.
Wichtige Punkte
Gemini 2.5 Flash legt den Schwerpunkt auf Kosteneffizienz und macht fortschrittliche KI-Funktionen für mehr Nutzer zugänglich.
Es bietet eine außergewöhnlich gute Leistung bei großvolumigen Echtzeit-Anwendungsfällen wie Chatbots und Datenanalysen sowie bei generativen KI-Anwendungen.
Das Modell erweitert die ausgefeilten Schlussfolgerungsfunktionen der Gemini 2.5-Serie.
Es zielt darauf ab, eine Leistung zu bieten, die mit größeren Modellen vergleichbar ist, jedoch mit höherer Geschwindigkeit und zu einem günstigeren Preis.
Es stehen zwei separate Preisstufen für den „denkenden” und den „nicht denkenden” Modus zur Verfügung, die anpassbare Nutzungsoptionen bieten.
Gemini 2.5 Flash verstehen: Ein kostengünstiges KI-Modell
Was ist Gemini 2.5 Flash?
Gemini 2.5 Flash ist das neueste Mitglied der Gemini-KI-Modellfamilie von Google und wurde als vielseitiges „Arbeitstier”-Modell konzipiert.
Es legt den Schwerpunkt auf Erschwinglichkeit und minimale Verzögerungen bei gleichbleibend robuster Leistung. Es eignet sich ideal für Anwendungen mit hohem Datenaufkommen in Echtzeit und ist gut für Chatbots, Analyse-Dashboards und interaktive Tools geeignet. Eine bemerkenswerte Stärke ist die Unterstützung von agentenbasierten Workflows, was Googles Vision für das Modell in autonomen, dynamischen Systemen verdeutlicht. Im Wesentlichen zielt Gemini 2.5 Flash nicht darauf ab, in jeder Leistungskategorie führend zu sein, sondern als praktische, zugängliche KI-Lösung für verschiedene Szenarien zu dienen.
Die Macht der Preisgestaltung: Die verschiedenen Stufen verstehen
Ein wesentliches Unterscheidungsmerkmal von Gemini 2.5 Flash ist sein innovatives Preismodell.
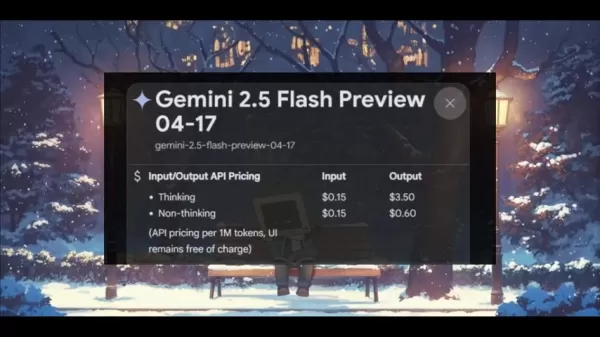
Google bietet zwei unterschiedliche Stufen an: einen „Denkmodus” für komplexe Denkaufgaben zum Preis von 0,15 USD pro Million Eingabetoken und 3,50 USD pro Million Ausgabetoken sowie einen „Nicht-Denkmodus” für einfachere Aufgaben zum Preis von 0,15 USD pro Million Eingabetoken und 0,60 USD pro Million Ausgabetoken. Dieses abgestufte System ermöglicht es Entwicklern, die Kosten an die Anwendungsanforderungen anzupassen, was zu erheblichen Einsparungen führt, insbesondere bei datenintensiven Aufgaben, die nicht für jeden Vorgang ein intensives Denken erfordern.
Anwendungen und Potenzial: Wo Gemini 2.5 Flash glänzt
Die Wirtschaftlichkeit von Gemini 2.5 Flash macht es für zahlreiche Anwendungen attraktiv.
Zu den wichtigsten Bereichen, in denen sich dieses Modell auszeichnet, gehören:
- Chatbots: Ermöglichen interaktive Kundenservice-Erlebnisse zu überschaubaren Kosten.
- Analytics-Dashboards: Kostengünstige Bereitstellung von Echtzeit-Einblicken und Datenvisualisierungen aus großen Datensätzen.
- Generative KI: Effiziente Erstellung dynamischer Inhalte und Ausführung kreativer Aufgaben.
- Agentische Workflows: Automatisierung von Vorgängen innerhalb komplexer, selbstgesteuerter Systeme.
Vergleich von Gemini 2.5 Flash mit anderen KI-Modellen
Benchmarking der Leistung von Gemini 2.5 Flash
Benchmark-Tests vergleichen Gemini 2.5 Flash mit Modellen wie OpenAI's O4-mini, Claude 3.7 Sonnet, Grok 3 Beta und DeepSeek R1. Gemini 2.5 Flash kostet 0,15 US-Dollar pro Million Eingabetoken und 0,60 US-Dollar pro Million Ausgabetoken, wobei der „Reasoning”-Modus 3,50 US-Dollar kostet.
Ein Vergleich von KI-Modellen
Gemini 2.5 Flash zeichnet sich durch ein ausgewogenes Verhältnis zwischen Erschwinglichkeit und leistungsfähiger Performance bei verschiedenen Aufgaben aus. Während größere Modelle in bestimmten Bereichen hervorragende Leistungen erbringen, bietet Gemini 2.5 Flash eine kostengünstige Alternative für viele Anwendungen. Seine wettbewerbsfähigen Preise werden eine neue Welle von KI-Diensten und -Software beeinflussen.
Nachfolgend finden Sie eine Leistungsübersicht von Gemini 2.5 Flash im Vergleich zu anderen führenden Modellen:
Benchmark Gemini 2.5 Flash Gemini 2.0 Flash OpenAI o4-mini Claude Sonnet 3.7 Grok 3 Beta DeepSeek R1 Eingabe Preis ($ / 1 Mio. Token) 0,15 0,10 1,10 3,00 3,00 0,55 Ausgabepreis ($ / 1 Mio. Token) 0,60 0,40 4,40 15,00 15,00 2,19 Argumentation (Die letzte Prüfung der Menschheit) 12,1 5,1 14,3 8,9 8,6 8,6 Naturwissenschaften (GPOA Diamond) 78,3 60,1 81,4 78,2 80,2 71,5 Mathematik (Aime 2025) 78,0 27,5 92,7 49,5 77,3 70,0 Mathematik (AIME 2024) 88,0 32,0 93,4 61,3 83,9 79,8 Codegenerierung (LiveCodeBench) 63,5 34,5 70,6 70,6 70,6 64,3
Erste Schritte mit Gemini 2.5 Flash
Zugriff auf Gemini 2.5 Flash in Google AI Studio
Um Gemini 2.5 Flash zu verwenden, besuchen Sie Google AI Studio.
Gemini 2.5 Flash finden Sie in der Dropdown-Liste zur Modellauswahl. Dort können Sie je nach Ihren Aufgabenanforderungen zwischen den Modi „thinking“ (denkend) und „non-thinking“ (nicht denkend) wählen. Google AI Studio bietet außerdem anpassbare Einstellungen wie Temperatursteuerung, Anpassung der strukturierten Ausgabe, Codeausführung und Google-Suchgrundlagen.
Demonstrationen der Codeausführung
Die Demonstration umfasst mehrere Benchmarks, die durch direkte Eingaben in den Google AI-Assistenten ausgeführt wurden und bei denen der Code mithilfe des neuen Modells erfolgreich generiert, ausgegeben und gerendert wurde. Beispiele hierfür sind:
- Eine Sticky-Notes-App: Die KI erstellte schnell ein voll funktionsfähiges, optisch ansprechendes Frontend für die Notizverwaltung.
- Conways Spiel des Lebens: Die KI erhielt die Aufforderung, eine Python-Simulation dieses klassischen zellulären Automaten zu entwickeln.
Gemini 2.5 Flash – Preisdetails
Kostengünstige und skalierbare Preise
Gemini 2.5 Flash bietet ein attraktives Preismodell mit den Optionen „Thinking” und „Non-Thinking”.
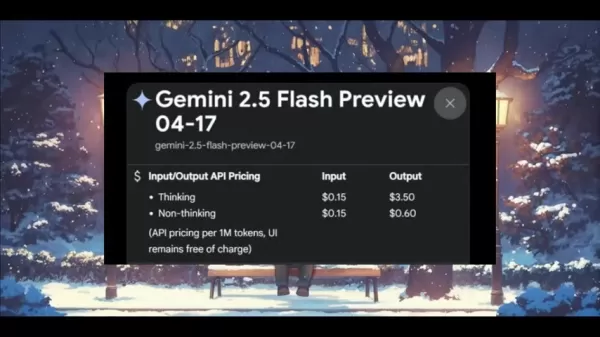
„Thinking”-Aufgaben kosten 0,15 USD pro Million Eingabetoken und 3,50 USD pro Million Ausgabetoken, während der „Non-Thinking”-Modus die Ausgabekosten auf 0,60 USD pro Million Token reduziert. Damit ist Gemini 2.5 Flash eine budgetfreundliche KI-Lösung. Darüber hinaus wurden die Ratenlimits für Entwicklertests auf 500 Anfragen pro Tag erhöht.
Abwägen der Vor- und Nachteile von Gemini 2.5 Flash
Vorteile
Hohe Kosteneffizienz
Hervorragend geeignet für Anwendungen mit hohem Volumen und Echtzeitanwendungen
Baut auf den Schlussfolgerungsfähigkeiten der Gemini 2.5-Serie auf
Bietet flexible Preisstufen
Nachteile
Übertreffen möglicherweise nicht alle Benchmarks größerer Modelle
Die Leistung variiert je nach Arbeitslast, was sowohl ein Nachteil als auch ein Vorteil sein kann
Auf 500 Anfragen in der kostenlosen Stufe beschränkt
Ideale Anwendungsfälle für Gemini 2.5 Flash
Anwendungen mit hohem Datenvolumen und Echtzeitanforderungen
Gemini 2.5 Flash eignet sich besonders für Anwendungen, die schnelle Antworten und einen hohen Durchsatz erfordern. Dank seiner geringen Latenz und seines günstigen Preises ist es ideal für die Verarbeitung zahlreicher gleichzeitiger Benutzer oder großer Datenströme.
Chatbots und dialogorientierte KI
Dieses Modell bietet einen budgetfreundlichen Ansatz für die Erstellung interaktiver und ansprechender Chatbot-Erlebnisse und ermöglicht skalierbare Kundendienst- und Supportlösungen.
Workflow-Automatisierung
Die Geschwindigkeit und Effizienz von Gemini machen es zu einer überzeugenden Option für die Automatisierung von Routineaufgaben und helfen Unternehmen dabei, ihre Abläufe zu optimieren, manuelle Arbeit zu reduzieren und die Produktivität zu steigern.
Häufig gestellte Fragen zu Gemini 2.5 Flash
Was sind die wichtigsten Vorteile der Verwendung von Gemini 2.5 Flash?
Gemini 2.5 Flash kombiniert Kosteneffizienz, geringe Latenz und solide Leistung, insbesondere für Anwendungen mit hohem Datenaufkommen und Echtzeitanwendungen. Dank der flexiblen Preisgestaltung können Entwickler ihre KI-Ausgaben effektiv verwalten.
Für welche Art von Anwendungen eignet sich Gemini 2.5 Flash am besten?
Dieses Modell eignet sich ideal für Chatbots, Analyse-Dashboards, agentenbasierte Workflows und andere Anwendungen, die schnelle Antworten und eine effiziente Verarbeitung großer Datensätze erfordern.
Wie funktioniert die Preisgestaltung für Gemini 2.5 Flash?
Gemini 2.5 Flash bietet zwei Preisstufen: einen „Denkmodus” für komplexe Schlussfolgerungen und einen „Nicht-Denkmodus” für einfachere Aufgaben, jeweils mit separaten Eingabe- und Ausgabetoken-Raten. Google AI Studio enthält außerdem anpassbare Einstellungen wie Temperaturkontrolle, strukturierte Ausgabe, Codeausführung und Google-Suchgrundlagen.
Verwandte Fragen
Wie schneidet Gemini 2.5 Flash im Vergleich zu anderen KI-Modellen wie Gemini 2.5 Pro oder den Angeboten von OpenAI ab?
Gemini 2.5 Flash ist als kostengünstige Alternative positioniert, die eine mit größeren Modellen vergleichbare Qualität bietet, jedoch mit höherer Geschwindigkeit und geringeren Kosten. Auch wenn es nicht in jeder Benchmark führend ist, macht es seine Preisgestaltung für viele praktische Anwendungen attraktiv.
Was sind die Einschränkungen von Gemini 2.5 Flash?
Das Modell ist möglicherweise nicht die beste Wahl für Aufgaben, die höchste Genauigkeit oder fortgeschrittene Schlussfolgerungen erfordern. Entwickler sollten die spezifischen Anforderungen ihrer Anwendung bewerten, wenn sie zwischen Gemini 2.5 Flash und anderen Modellen wählen. Lesen Sie immer die Nutzungsbedingungen und Verhaltenskodizes, um eine optimale Nutzung sicherzustellen.
Wie kann ich mich über die neuesten KI-Nachrichten und -Entwicklungen, einschließlich Updates zur Gemini-Modellfamilie, auf dem Laufenden halten?
Abonnieren Sie Branchen-Newsletter, folgen Sie KI-Forschungsorganisationen und -Experten in den sozialen Medien und besuchen Sie regelmäßig die offizielle Website von Google AI, um Neuigkeiten und Updates zu erhalten. Der Bereich der KI entwickelt sich rasant weiter und bietet spannende Möglichkeiten zur Mitwirkung.
Verwandter Artikel
 Richtlinie zur obligatorischen KI-Suche führt zu Nutzerabwanderung, DuckDuckGo verzeichnet Nutzeranstieg
Nachdem Google auf seiner I/O-Konferenz 2026 eine umfassende KI-Umgestaltung seiner Suchmaschine angekündigt hatte, suchten viele Nutzer nach besser kontrollierbaren Alternativen, da es keine einfache
Xiaohongshu strukturiert sich neu: Conan wird zum Präsidenten ernannt, die Hauptabteilung für KI „Dots“ und die Auslandsabteilung „Rednote“ werden gegründet
Am 30. April versandte Xiaohongshu ein internes Memo an alle Mitarbeiter, in dem die Einführung einer neuen organisatorischen Umstrukturierung angekündigt wurde. Im Mittelpunkt dieser Veränderung steh
Tencent-Spiel „Xiaolongxia“ übertrifft alle Erwartungen, das Team verzehnfacht seine Kapazitäten, entschuldigt sich und leistet Entschädigung
Tencent hat offiziell „WorkBuddy“ eingeführt, einen KI-Agenten für alle Anwendungsszenarien, der mit seiner hohen Integrationsfähigkeit und niedrigen Einführungshürde eine neue Phase im Wettlauf um di
Empfehlungen zu verwandten Spezialthemen
Text-zu-Sprache
Richtlinie zur obligatorischen KI-Suche führt zu Nutzerabwanderung, DuckDuckGo verzeichnet Nutzeranstieg
Nachdem Google auf seiner I/O-Konferenz 2026 eine umfassende KI-Umgestaltung seiner Suchmaschine angekündigt hatte, suchten viele Nutzer nach besser kontrollierbaren Alternativen, da es keine einfache
Xiaohongshu strukturiert sich neu: Conan wird zum Präsidenten ernannt, die Hauptabteilung für KI „Dots“ und die Auslandsabteilung „Rednote“ werden gegründet
Am 30. April versandte Xiaohongshu ein internes Memo an alle Mitarbeiter, in dem die Einführung einer neuen organisatorischen Umstrukturierung angekündigt wurde. Im Mittelpunkt dieser Veränderung steh
Tencent-Spiel „Xiaolongxia“ übertrifft alle Erwartungen, das Team verzehnfacht seine Kapazitäten, entschuldigt sich und leistet Entschädigung
Tencent hat offiziell „WorkBuddy“ eingeführt, einen KI-Agenten für alle Anwendungsszenarien, der mit seiner hohen Integrationsfähigkeit und niedrigen Einführungshürde eine neue Phase im Wettlauf um di
Empfehlungen zu verwandten Spezialthemen
Text-zu-Sprache
 Die besten KI-Sprachausgabe-Apps für Legasthenie: Unterstützung für das Lernen und effizienteres Lesen bei Schülern
Die besten KI-Sprachausgabe-Apps für Legasthenie: Unterstützung für das Lernen und effizienteres Lesen bei Schülern
Entdecken Sie die besten KI-TTS-Apps des Jahres 2026, die speziell zur Unterstützung bei Legasthenie ausgewählt wurden. In unseren Experten-Rankings vergleichen wir kostenlose und kostenpflichtige Tools und stellen leistungsstarke Funktionen für mehr Leseeffizienz und besseren Lernerfolg vor. Entdecken Sie bahnbrechende Lösungen, die Sie unbedingt ausprobieren sollten, um das Potenzial Ihrer Schüler voll auszuschöpfen. Beginnen Sie Ihre Reise bei XIX.AI.
 10 Tools
10 Tools
 xix.ai
Comic-Erstellung
Die besten KI-Generatoren für Shonen-Manga: Erstelle actiongeladene Sequenzen und dynamische Effekte
xix.ai
Comic-Erstellung
Die besten KI-Generatoren für Shonen-Manga: Erstelle actiongeladene Sequenzen und dynamische Effekte
Entdecken Sie bei XIX.AI die besten KI-Generatoren für Shonen-Manga des Jahres 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools zur Erstellung actiongeladener Sequenzen und dynamischer Energieeffekte. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit der Gestaltung epischer Manga!
15 Tools
xix.ai
Geschäft
Die besten KI-basierten Spesenabrechnungsprogramme: Quittungen scannen und Geschäftsausgaben automatisch kategorisieren
Die besten KI-basierten Spesenmanager 2026: Erstklassige Tools zum Scannen von Belegen und zur automatischen Kategorisierung von Unternehmensausgaben. Entdecken Sie leistungsstarke, bahnbrechende Lösungen für müheloses Spesenmanagement, präzise Finanzüberwachung und optimierte Compliance. Unser sorgfältig zusammengestellter, wöchentlich aktualisierter Vergleich zwischen kostenlosen und kostenpflichtigen Optionen hilft Ihnen dabei, die perfekte Lösung zu finden. Nutzen Sie Ihren KI-Vorteil mit den Expertenempfehlungen von XIX.AI.
10 Tools
xix.ai
Geschäft
Die besten KI-Tools für die Personalbeschaffung: Lebensläufe prüfen und die Terminplanung für Vorstellungsgespräche automatisieren
Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai
Produktivität
KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai
Chatbot
Die besten KI-basierten Romantik-Chatbots: Bauen Sie langfristige Beziehungen mit beständiger Persönlichkeit auf
Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai

 Kommentare (2)
Kommentare (2)
![AndrewAllen]()
C'est impressionnant de voir Google rendre l'IA aussi abordable ! 😮 Mais est-ce que cette accessibilité va accélérer l'adoption ou simplement créer plus de dépendance envers leurs écosystèmes ? J'aimerais savoir comment ça se compare aux modèles open-source.
![NicholasLewis]()
Finalmente um modelo mais barato! Fico feliz de ver grandes empresas priorizando acessibilidade, não apenas PURE performance. Ainda sim, será que isso de fato abre portas para desenvolvedores independentes, ou é apenas uma jogada para dominar ainda mais o mercado? Só espero que eles continuem melhorando a privacidade também.😅
Google ist weiterhin führend im Bereich der künstlichen Intelligenz, wobei sein neuestes Modell Gemini 2.5 Flash großes Interesse weckt. Diese Version konzentriert sich nicht nur auf die Leistung, sondern auch auf die Zugänglichkeit und bietet eine kostengünstige KI-Lösung mit geringer Latenz, die für vielfältige Anwendungen geeignet ist – von hochvolumigen Echtzeit-Interaktionen bis hin zu generativen KI-Aufgaben. Hier erfahren Sie, warum dieses Modell eine bahnbrechende Entwicklung für Entwickler und Unternehmen darstellt.
Wichtige Punkte
Gemini 2.5 Flash legt den Schwerpunkt auf Kosteneffizienz und macht fortschrittliche KI-Funktionen für mehr Nutzer zugänglich.
Es bietet eine außergewöhnlich gute Leistung bei großvolumigen Echtzeit-Anwendungsfällen wie Chatbots und Datenanalysen sowie bei generativen KI-Anwendungen.
Das Modell erweitert die ausgefeilten Schlussfolgerungsfunktionen der Gemini 2.5-Serie.
Es zielt darauf ab, eine Leistung zu bieten, die mit größeren Modellen vergleichbar ist, jedoch mit höherer Geschwindigkeit und zu einem günstigeren Preis.
Es stehen zwei separate Preisstufen für den „denkenden” und den „nicht denkenden” Modus zur Verfügung, die anpassbare Nutzungsoptionen bieten.
Gemini 2.5 Flash verstehen: Ein kostengünstiges KI-Modell
Was ist Gemini 2.5 Flash?
Gemini 2.5 Flash ist das neueste Mitglied der Gemini-KI-Modellfamilie von Google und wurde als vielseitiges „Arbeitstier”-Modell konzipiert.
Es legt den Schwerpunkt auf Erschwinglichkeit und minimale Verzögerungen bei gleichbleibend robuster Leistung. Es eignet sich ideal für Anwendungen mit hohem Datenaufkommen in Echtzeit und ist gut für Chatbots, Analyse-Dashboards und interaktive Tools geeignet. Eine bemerkenswerte Stärke ist die Unterstützung von agentenbasierten Workflows, was Googles Vision für das Modell in autonomen, dynamischen Systemen verdeutlicht. Im Wesentlichen zielt Gemini 2.5 Flash nicht darauf ab, in jeder Leistungskategorie führend zu sein, sondern als praktische, zugängliche KI-Lösung für verschiedene Szenarien zu dienen.
Die Macht der Preisgestaltung: Die verschiedenen Stufen verstehen
Ein wesentliches Unterscheidungsmerkmal von Gemini 2.5 Flash ist sein innovatives Preismodell.
Google bietet zwei unterschiedliche Stufen an: einen „Denkmodus” für komplexe Denkaufgaben zum Preis von 0,15 USD pro Million Eingabetoken und 3,50 USD pro Million Ausgabetoken sowie einen „Nicht-Denkmodus” für einfachere Aufgaben zum Preis von 0,15 USD pro Million Eingabetoken und 0,60 USD pro Million Ausgabetoken. Dieses abgestufte System ermöglicht es Entwicklern, die Kosten an die Anwendungsanforderungen anzupassen, was zu erheblichen Einsparungen führt, insbesondere bei datenintensiven Aufgaben, die nicht für jeden Vorgang ein intensives Denken erfordern.
Anwendungen und Potenzial: Wo Gemini 2.5 Flash glänzt
Die Wirtschaftlichkeit von Gemini 2.5 Flash macht es für zahlreiche Anwendungen attraktiv.
Zu den wichtigsten Bereichen, in denen sich dieses Modell auszeichnet, gehören:
- Chatbots: Ermöglichen interaktive Kundenservice-Erlebnisse zu überschaubaren Kosten.
- Analytics-Dashboards: Kostengünstige Bereitstellung von Echtzeit-Einblicken und Datenvisualisierungen aus großen Datensätzen.
- Generative KI: Effiziente Erstellung dynamischer Inhalte und Ausführung kreativer Aufgaben.
- Agentische Workflows: Automatisierung von Vorgängen innerhalb komplexer, selbstgesteuerter Systeme.
Vergleich von Gemini 2.5 Flash mit anderen KI-Modellen
Benchmarking der Leistung von Gemini 2.5 Flash
Benchmark-Tests vergleichen Gemini 2.5 Flash mit Modellen wie OpenAI's O4-mini, Claude 3.7 Sonnet, Grok 3 Beta und DeepSeek R1. Gemini 2.5 Flash kostet 0,15 US-Dollar pro Million Eingabetoken und 0,60 US-Dollar pro Million Ausgabetoken, wobei der „Reasoning”-Modus 3,50 US-Dollar kostet.
Ein Vergleich von KI-Modellen
Gemini 2.5 Flash zeichnet sich durch ein ausgewogenes Verhältnis zwischen Erschwinglichkeit und leistungsfähiger Performance bei verschiedenen Aufgaben aus. Während größere Modelle in bestimmten Bereichen hervorragende Leistungen erbringen, bietet Gemini 2.5 Flash eine kostengünstige Alternative für viele Anwendungen. Seine wettbewerbsfähigen Preise werden eine neue Welle von KI-Diensten und -Software beeinflussen.
Nachfolgend finden Sie eine Leistungsübersicht von Gemini 2.5 Flash im Vergleich zu anderen führenden Modellen:
| Benchmark | Gemini 2.5 Flash | Gemini 2.0 Flash | OpenAI o4-mini | Claude Sonnet 3.7 | Grok 3 Beta | DeepSeek R1 |
|---|---|---|---|---|---|---|
| Eingabe Preis ($ / 1 Mio. Token) | 0,15 | 0,10 | 1,10 | 3,00 | 3,00 | 0,55 |
| Ausgabepreis ($ / 1 Mio. Token) | 0,60 | 0,40 | 4,40 | 15,00 | 15,00 | 2,19 |
| Argumentation (Die letzte Prüfung der Menschheit) | 12,1 | 5,1 | 14,3 | 8,9 | 8,6 | 8,6 |
| Naturwissenschaften (GPOA Diamond) | 78,3 | 60,1 | 81,4 | 78,2 | 80,2 | 71,5 |
| Mathematik (Aime 2025) | 78,0 | 27,5 | 92,7 | 49,5 | 77,3 | 70,0 |
| Mathematik (AIME 2024) | 88,0 | 32,0 | 93,4 | 61,3 | 83,9 | 79,8 |
| Codegenerierung (LiveCodeBench) | 63,5 | 34,5 | 70,6 | 70,6 | 70,6 | 64,3 |
Erste Schritte mit Gemini 2.5 Flash
Zugriff auf Gemini 2.5 Flash in Google AI Studio
Um Gemini 2.5 Flash zu verwenden, besuchen Sie Google AI Studio.
Gemini 2.5 Flash finden Sie in der Dropdown-Liste zur Modellauswahl. Dort können Sie je nach Ihren Aufgabenanforderungen zwischen den Modi „thinking“ (denkend) und „non-thinking“ (nicht denkend) wählen. Google AI Studio bietet außerdem anpassbare Einstellungen wie Temperatursteuerung, Anpassung der strukturierten Ausgabe, Codeausführung und Google-Suchgrundlagen.
Demonstrationen der Codeausführung
Die Demonstration umfasst mehrere Benchmarks, die durch direkte Eingaben in den Google AI-Assistenten ausgeführt wurden und bei denen der Code mithilfe des neuen Modells erfolgreich generiert, ausgegeben und gerendert wurde. Beispiele hierfür sind:
- Eine Sticky-Notes-App: Die KI erstellte schnell ein voll funktionsfähiges, optisch ansprechendes Frontend für die Notizverwaltung.
- Conways Spiel des Lebens: Die KI erhielt die Aufforderung, eine Python-Simulation dieses klassischen zellulären Automaten zu entwickeln.
Gemini 2.5 Flash – Preisdetails
Kostengünstige und skalierbare Preise
Gemini 2.5 Flash bietet ein attraktives Preismodell mit den Optionen „Thinking” und „Non-Thinking”.
„Thinking”-Aufgaben kosten 0,15 USD pro Million Eingabetoken und 3,50 USD pro Million Ausgabetoken, während der „Non-Thinking”-Modus die Ausgabekosten auf 0,60 USD pro Million Token reduziert. Damit ist Gemini 2.5 Flash eine budgetfreundliche KI-Lösung. Darüber hinaus wurden die Ratenlimits für Entwicklertests auf 500 Anfragen pro Tag erhöht.
Abwägen der Vor- und Nachteile von Gemini 2.5 Flash
Vorteile
Hohe Kosteneffizienz
Hervorragend geeignet für Anwendungen mit hohem Volumen und Echtzeitanwendungen
Baut auf den Schlussfolgerungsfähigkeiten der Gemini 2.5-Serie auf
Bietet flexible Preisstufen
Nachteile
Übertreffen möglicherweise nicht alle Benchmarks größerer Modelle
Die Leistung variiert je nach Arbeitslast, was sowohl ein Nachteil als auch ein Vorteil sein kann
Auf 500 Anfragen in der kostenlosen Stufe beschränkt
Ideale Anwendungsfälle für Gemini 2.5 Flash
Anwendungen mit hohem Datenvolumen und Echtzeitanforderungen
Gemini 2.5 Flash eignet sich besonders für Anwendungen, die schnelle Antworten und einen hohen Durchsatz erfordern. Dank seiner geringen Latenz und seines günstigen Preises ist es ideal für die Verarbeitung zahlreicher gleichzeitiger Benutzer oder großer Datenströme.
Chatbots und dialogorientierte KI
Dieses Modell bietet einen budgetfreundlichen Ansatz für die Erstellung interaktiver und ansprechender Chatbot-Erlebnisse und ermöglicht skalierbare Kundendienst- und Supportlösungen.
Workflow-Automatisierung
Die Geschwindigkeit und Effizienz von Gemini machen es zu einer überzeugenden Option für die Automatisierung von Routineaufgaben und helfen Unternehmen dabei, ihre Abläufe zu optimieren, manuelle Arbeit zu reduzieren und die Produktivität zu steigern.
Häufig gestellte Fragen zu Gemini 2.5 Flash
Was sind die wichtigsten Vorteile der Verwendung von Gemini 2.5 Flash?
Gemini 2.5 Flash kombiniert Kosteneffizienz, geringe Latenz und solide Leistung, insbesondere für Anwendungen mit hohem Datenaufkommen und Echtzeitanwendungen. Dank der flexiblen Preisgestaltung können Entwickler ihre KI-Ausgaben effektiv verwalten.
Für welche Art von Anwendungen eignet sich Gemini 2.5 Flash am besten?
Dieses Modell eignet sich ideal für Chatbots, Analyse-Dashboards, agentenbasierte Workflows und andere Anwendungen, die schnelle Antworten und eine effiziente Verarbeitung großer Datensätze erfordern.
Wie funktioniert die Preisgestaltung für Gemini 2.5 Flash?
Gemini 2.5 Flash bietet zwei Preisstufen: einen „Denkmodus” für komplexe Schlussfolgerungen und einen „Nicht-Denkmodus” für einfachere Aufgaben, jeweils mit separaten Eingabe- und Ausgabetoken-Raten. Google AI Studio enthält außerdem anpassbare Einstellungen wie Temperaturkontrolle, strukturierte Ausgabe, Codeausführung und Google-Suchgrundlagen.
Verwandte Fragen
Wie schneidet Gemini 2.5 Flash im Vergleich zu anderen KI-Modellen wie Gemini 2.5 Pro oder den Angeboten von OpenAI ab?
Gemini 2.5 Flash ist als kostengünstige Alternative positioniert, die eine mit größeren Modellen vergleichbare Qualität bietet, jedoch mit höherer Geschwindigkeit und geringeren Kosten. Auch wenn es nicht in jeder Benchmark führend ist, macht es seine Preisgestaltung für viele praktische Anwendungen attraktiv.
Was sind die Einschränkungen von Gemini 2.5 Flash?
Das Modell ist möglicherweise nicht die beste Wahl für Aufgaben, die höchste Genauigkeit oder fortgeschrittene Schlussfolgerungen erfordern. Entwickler sollten die spezifischen Anforderungen ihrer Anwendung bewerten, wenn sie zwischen Gemini 2.5 Flash und anderen Modellen wählen. Lesen Sie immer die Nutzungsbedingungen und Verhaltenskodizes, um eine optimale Nutzung sicherzustellen.
Wie kann ich mich über die neuesten KI-Nachrichten und -Entwicklungen, einschließlich Updates zur Gemini-Modellfamilie, auf dem Laufenden halten?
Abonnieren Sie Branchen-Newsletter, folgen Sie KI-Forschungsorganisationen und -Experten in den sozialen Medien und besuchen Sie regelmäßig die offizielle Website von Google AI, um Neuigkeiten und Updates zu erhalten. Der Bereich der KI entwickelt sich rasant weiter und bietet spannende Möglichkeiten zur Mitwirkung.










 Richtlinie zur obligatorischen KI-Suche führt zu Nutzerabwanderung, DuckDuckGo verzeichnet Nutzeranstieg
Nachdem Google auf seiner I/O-Konferenz 2026 eine umfassende KI-Umgestaltung seiner Suchmaschine angekündigt hatte, suchten viele Nutzer nach besser kontrollierbaren Alternativen, da es keine einfache
Richtlinie zur obligatorischen KI-Suche führt zu Nutzerabwanderung, DuckDuckGo verzeichnet Nutzeranstieg
Nachdem Google auf seiner I/O-Konferenz 2026 eine umfassende KI-Umgestaltung seiner Suchmaschine angekündigt hatte, suchten viele Nutzer nach besser kontrollierbaren Alternativen, da es keine einfache
 Xiaohongshu strukturiert sich neu: Conan wird zum Präsidenten ernannt, die Hauptabteilung für KI „Dots“ und die Auslandsabteilung „Rednote“ werden gegründet
Am 30. April versandte Xiaohongshu ein internes Memo an alle Mitarbeiter, in dem die Einführung einer neuen organisatorischen Umstrukturierung angekündigt wurde. Im Mittelpunkt dieser Veränderung steh
Xiaohongshu strukturiert sich neu: Conan wird zum Präsidenten ernannt, die Hauptabteilung für KI „Dots“ und die Auslandsabteilung „Rednote“ werden gegründet
Am 30. April versandte Xiaohongshu ein internes Memo an alle Mitarbeiter, in dem die Einführung einer neuen organisatorischen Umstrukturierung angekündigt wurde. Im Mittelpunkt dieser Veränderung steh
 Tencent-Spiel „Xiaolongxia“ übertrifft alle Erwartungen, das Team verzehnfacht seine Kapazitäten, entschuldigt sich und leistet Entschädigung
Tencent hat offiziell „WorkBuddy“ eingeführt, einen KI-Agenten für alle Anwendungsszenarien, der mit seiner hohen Integrationsfähigkeit und niedrigen Einführungshürde eine neue Phase im Wettlauf um di
Tencent-Spiel „Xiaolongxia“ übertrifft alle Erwartungen, das Team verzehnfacht seine Kapazitäten, entschuldigt sich und leistet Entschädigung
Tencent hat offiziell „WorkBuddy“ eingeführt, einen KI-Agenten für alle Anwendungsszenarien, der mit seiner hohen Integrationsfähigkeit und niedrigen Einführungshürde eine neue Phase im Wettlauf um di

Entdecken Sie die besten KI-TTS-Apps des Jahres 2026, die speziell zur Unterstützung bei Legasthenie ausgewählt wurden. In unseren Experten-Rankings vergleichen wir kostenlose und kostenpflichtige Tools und stellen leistungsstarke Funktionen für mehr Leseeffizienz und besseren Lernerfolg vor. Entdecken Sie bahnbrechende Lösungen, die Sie unbedingt ausprobieren sollten, um das Potenzial Ihrer Schüler voll auszuschöpfen. Beginnen Sie Ihre Reise bei XIX.AI.
10 Tools
xix.ai

Entdecken Sie bei XIX.AI die besten KI-Generatoren für Shonen-Manga des Jahres 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools zur Erstellung actiongeladener Sequenzen und dynamischer Energieeffekte. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit der Gestaltung epischer Manga!
15 Tools
xix.ai

Die besten KI-basierten Spesenmanager 2026: Erstklassige Tools zum Scannen von Belegen und zur automatischen Kategorisierung von Unternehmensausgaben. Entdecken Sie leistungsstarke, bahnbrechende Lösungen für müheloses Spesenmanagement, präzise Finanzüberwachung und optimierte Compliance. Unser sorgfältig zusammengestellter, wöchentlich aktualisierter Vergleich zwischen kostenlosen und kostenpflichtigen Optionen hilft Ihnen dabei, die perfekte Lösung zu finden. Nutzen Sie Ihren KI-Vorteil mit den Expertenempfehlungen von XIX.AI.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai

Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai

C'est impressionnant de voir Google rendre l'IA aussi abordable ! 😮 Mais est-ce que cette accessibilité va accélérer l'adoption ou simplement créer plus de dépendance envers leurs écosystèmes ? J'aimerais savoir comment ça se compare aux modèles open-source.
Finalmente um modelo mais barato! Fico feliz de ver grandes empresas priorizando acessibilidade, não apenas PURE performance. Ainda sim, será que isso de fato abre portas para desenvolvedores independentes, ou é apenas uma jogada para dominar ainda mais o mercado? Só espero que eles continuem melhorando a privacidade também.😅













