
















 首页
首页人工智能将 2D 图像转化为令人惊叹的 3D 照片 - 终极指南
随着人工智能将静态 2D 图像转换为身临其境的 3D 体验,数码摄影领域正在经历一场革命性的变革。这项尖端技术通过算法重建深度和透视,为传统照片注入了新的活力。我们的全面探索揭示了这一创新背后的科学原理、实际应用方法以及将普通图片提升为动态视觉叙事的创造性应用。
要点
通过先进的内绘技术掌握深度感知图像转换。
利用人工智能算法从单张图像生成精确的深度图。
了解视觉缝隙填充机制,实现逼真的 3D 转换。
实现即时生成 3D 照片的即用型 AI 模型。
评估当前人工智能 3D 成像的能力和界限。
发现通过人工智能渲染可实现的各种电影效果。
将个人照片转换为立体艺术品的实用工作流程。
揭开人工智能三维摄影的神秘面纱
什么是人工智能驱动的三维摄影?
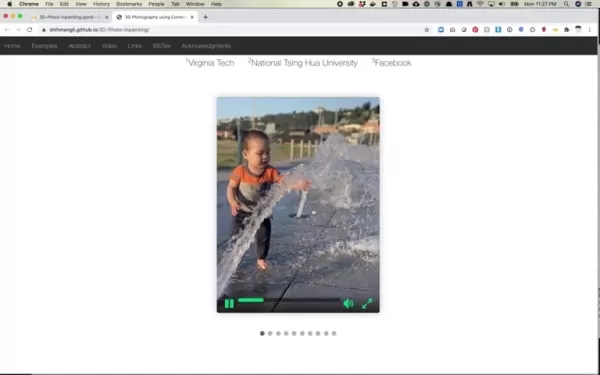
人工智能驱动的三维摄影代表着数字成像的范式转变,传统的平面照片通过智能算法处理获得空间深度。传统照片只能捕捉亮度和色彩信息,缺乏在人类视觉中产生视觉深度感知的维度数据。
这项变革性技术通过几种创新方法实现:
- 深度预测:神经网络通过分析视觉模式来估计物体距离,从而创建像素级深度图。
- 视觉重构:情境感知算法在图像元素之间建立隐藏的空间关系。
- 动态渲染:系统生成多个视角,模拟三维透视变化。
核心技术:情境感知分层深度绘制
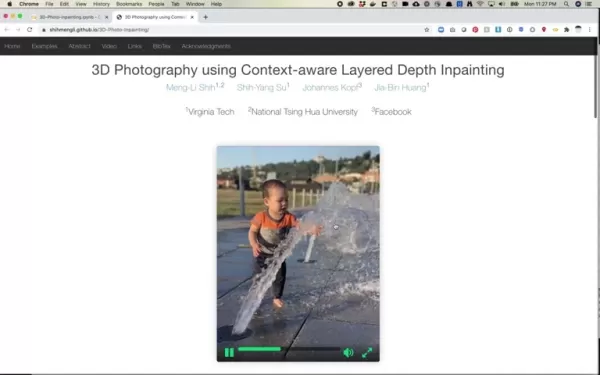
现代 3D 照片转换的革命性在于其集成处理管道:
- 通过卷积神经网络进行场景分析
- 通过训练有素的预测模型进行深度估计
- 多平面图像分割
- 通过几何变换进行视点模拟
- 通过生成式内绘完成视觉缝隙
这种复杂的工作流程可实现各种输出格式,包括深度可视化、动画透视转换和交互式三维视图,使静态图像栩栩如生。
了解深度贴图及其重要性
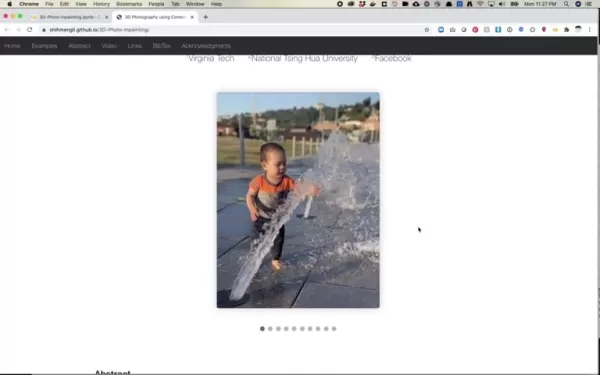
深度贴图通过建立图像元素之间的空间关系,为可信的三维转换奠定基础。高级技术包括
- 单眼深度估算:使用训练有素的神经网络进行单图像分析
- 几何重建:透视线和消失点的解释
- 纹理梯度分析:评估整个图像的细节分辨率变化
实用实施指南
设置开发环境
Google Colab 为 3D 照片转换实验提供了一个便捷的平台。基本配置步骤包括
- 在运行时设置中激活 GPU 加速
- 安装核心可视化库
- 配置 Python 依赖项
下载脚本和预训练模型
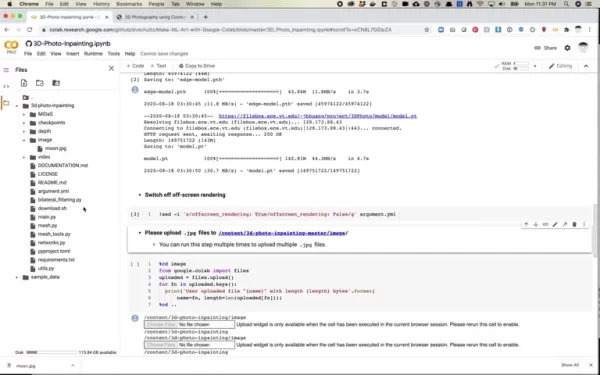
实施过程需要在大量图像数据集上预先训练好的特定人工智能模型。主要组件包括
- 3D 重建神经网络
- 深度预测算法
- 图像着色架构
上传和执行三维转换
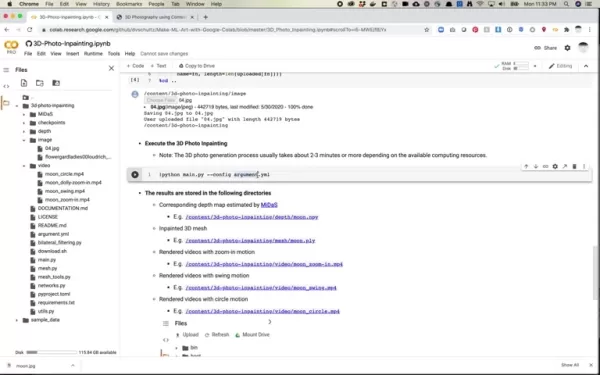
转换过程包括
- 选择最佳源图像(建议使用 JPEG 格式)
- 上传至处理环境
- 执行转换流水线
- 审查和完善输出结果
创建 AI 3D 照片
逐步转换过程
- 图片选择--选择主题清晰、光线充足的照片
- 环境设置--在 Colab 笔记本中配置必要的依赖项
- 模型部署--加载并初始化人工智能处理管道
- 执行转换--运行转换算法
- 输出生成 - 查看并导出 3D 照片
技术考虑因素
性能因素
- GPU 加速可大大缩短处理时间
- 图像分辨率会影响质量和计算时间
- 复杂场景可能需要额外的处理迭代
输出质量优化
- 使用具有良好对比度的高质量源图像
- 确保原始照片有适当的照明
- 选择前景元素清晰的图像
- 避免过多噪音或压缩伪影
AI 3D 照片转换的优势
- 使历史照片或档案照片焕发生机
- 为数字平台创建引人入胜的内容
- 增强视觉叙事能力
- 提供具有成本效益的立体摄影替代方案
目前的局限性
- 反光/镜面表面的深度估计难题
- 在复杂遮挡情况下可能出现伪影
- 计算密集型处理要求
- 视点调整范围有限
常见问题
哪些图像特征能产生最佳效果?
主体分离度高、照明良好且边缘清晰的图像通常能产生最佳的 3D 转换效果。
如何提高处理速度?
利用 GPU 加速和优化源图像分辨率可加快转换速度。
支持哪些文件格式?
系统目前最可靠的处理格式是 JPEG 图像。
如何解决边缘伪影问题?
使用不同的源图像进行试验,必要时考虑预处理步骤。
新兴功能
神经渲染和生成式人工智能的不断进步将带来更复杂的 3D 转换功能,包括实时处理和增强的视角灵活性。
相关文章
 腾讯旗下“小龙虾”表现远超预期,团队将运力扩大10倍,并致歉及提供补偿
腾讯正式推出全场景AI智能助手“WorkBuddy”,凭借高度集成和低部署门槛,标志着大型模型应用层竞争进入新阶段。该产品在发布当天便引发了业界广泛关注。 用户流量远超预期,导致相关产品腾讯云代码助手(CodeBuddy)出现登录故障及服务不稳定。腾讯云团队随后发布致歉声明,表示技术团队已紧急将容量扩容十倍,目前服务已全面恢复。受影响用户获得了5,000腾讯云代金券作为补偿。业界观察人士将Work
Suno领投方:删除帖子无法填补版权诉讼的漏洞
备受瞩目的AI音乐生成平台Suno正面临一场艰难的版权诉讼,而其领投投资人的坦率言论,可能恰恰为对方提供了他们梦寐以求的证据。 Menlo Ventures(Suno的核心投资者)合伙人C.C. Gong近日删除了一个推文,该推文与公司当前的法律辩护策略直接相悖。在之前的版权诉讼中,Suno的辩护主要依赖“合理使用”的论点,声称AI生成的音乐仅仅是一种“工具”,既不会直接与受版权保护的原创作品竞争
Claude Opus 4.7 正式发布,将可靠性置于智能之上
Anthropic 今年保持着激进的开发节奏,几乎每隔一天就会推出新功能。备受期待的 Claude Opus 4.7 刚刚正式发布,有趣的是,Anthropic 在公告中直言不讳地表示:“这并非我们最强大的模型。” 传闻中更强大的 Claude Mythos Preview 仍处于待命状态。尽管如此,Opus 4.7 依然引发了广泛关注,因为它致力于解决“更可靠”而非“更智能”的问题。基准测试结果
相关专题推荐
漫画创作
腾讯旗下“小龙虾”表现远超预期,团队将运力扩大10倍,并致歉及提供补偿
腾讯正式推出全场景AI智能助手“WorkBuddy”,凭借高度集成和低部署门槛,标志着大型模型应用层竞争进入新阶段。该产品在发布当天便引发了业界广泛关注。 用户流量远超预期,导致相关产品腾讯云代码助手(CodeBuddy)出现登录故障及服务不稳定。腾讯云团队随后发布致歉声明,表示技术团队已紧急将容量扩容十倍,目前服务已全面恢复。受影响用户获得了5,000腾讯云代金券作为补偿。业界观察人士将Work
Suno领投方:删除帖子无法填补版权诉讼的漏洞
备受瞩目的AI音乐生成平台Suno正面临一场艰难的版权诉讼,而其领投投资人的坦率言论,可能恰恰为对方提供了他们梦寐以求的证据。 Menlo Ventures(Suno的核心投资者)合伙人C.C. Gong近日删除了一个推文,该推文与公司当前的法律辩护策略直接相悖。在之前的版权诉讼中,Suno的辩护主要依赖“合理使用”的论点,声称AI生成的音乐仅仅是一种“工具”,既不会直接与受版权保护的原创作品竞争
Claude Opus 4.7 正式发布,将可靠性置于智能之上
Anthropic 今年保持着激进的开发节奏,几乎每隔一天就会推出新功能。备受期待的 Claude Opus 4.7 刚刚正式发布,有趣的是,Anthropic 在公告中直言不讳地表示:“这并非我们最强大的模型。” 传闻中更强大的 Claude Mythos Preview 仍处于待命状态。尽管如此,Opus 4.7 依然引发了广泛关注,因为它致力于解决“更可靠”而非“更智能”的问题。基准测试结果
相关专题推荐
漫画创作
 少年漫画顶级AI生成器:打造高能动作场面与特效
少年漫画顶级AI生成器:打造高能动作场面与特效
在 XIX.AI 探索 2026 年最优秀的少年漫画 AI 生成工具。我们精心筛选的这份高评分清单汇集了强大的工具,助您创作充满张力的动作场面和动态能量特效。通过实际测试对比免费与付费选项。释放您的创作潜能,立即开始创作史诗级漫画吧!
 15 个工具
15 个工具
 xix.ai
商业
最佳 AI 费用追踪工具:扫描收据并自动分类企业开支
xix.ai
商业
最佳 AI 费用追踪工具:扫描收据并自动分类企业开支
2026年最新最佳AI报销管理工具:广受好评的解决方案,可自动扫描收据并分类企业支出。探索这些功能强大、颠覆传统的解决方案,助您轻松管理报销、精准追踪财务并简化合规流程。我们精心整理并每周更新的免费与付费选项对比指南,助您找到最适合的工具。通过XIX.AI的专家精选,释放您的AI优势。
10 个工具
xix.ai
商业
最佳人工智能招聘工具:筛选简历并自动安排候选人面试
在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
10 个工具
xix.ai
生产率
AI个人健康与专注力教练:缓解倦怠,提升精神能量
立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai
聊天机器人
备受好评的AI浪漫聊天机器人:凭借稳定的个性建立长期关系
探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai
教育与学习
最佳AI数据科学导师:精通SQL、Pandas及机器学习工作流程
探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai

 评论 (3)
0/500
评论 (3)
0/500
![BruceMiller]()
Cette technique de conversion 2D vers 3D est fascinante ! Je me demande si elle peut s'appliquer aux vieilles photos de famille... Ce serait génial de voir les portraits de mes grands-parents prendre vie de cette manière. Par contre, je me pose des questions sur les coûts et la facilité d'accès pour le grand public — est-ce que cette technologie va rester cantonnée aux professionnels ? 😌
![AlbertJackson]()
Das ist ja mal krass! Die Idee, alte Fotos plötzlich räumlich zu erleben, finde ich total faszinierend. Aber ich frage mich auch, was das für die Privatsphäre bedeutet. Wenn jeder einfach irgendein 2D-Bild in 3D verwandeln kann... irgendwie unheimlich, oder? 😅 Trotzdem, die Technik ist beeindruckend!
![TerryGonzalez]()
这简直是魔法啊!我用旧照片试了一下效果,从2D变3D的过程让家里老人惊呼连连。不过生成的3D照片在移动时会有些小瑕疵,不知道是不是我操作的问题?期待技术再进步些 🚀
随着人工智能将静态 2D 图像转换为身临其境的 3D 体验,数码摄影领域正在经历一场革命性的变革。这项尖端技术通过算法重建深度和透视,为传统照片注入了新的活力。我们的全面探索揭示了这一创新背后的科学原理、实际应用方法以及将普通图片提升为动态视觉叙事的创造性应用。
要点
通过先进的内绘技术掌握深度感知图像转换。
利用人工智能算法从单张图像生成精确的深度图。
了解视觉缝隙填充机制,实现逼真的 3D 转换。
实现即时生成 3D 照片的即用型 AI 模型。
评估当前人工智能 3D 成像的能力和界限。
发现通过人工智能渲染可实现的各种电影效果。
将个人照片转换为立体艺术品的实用工作流程。
揭开人工智能三维摄影的神秘面纱
什么是人工智能驱动的三维摄影?
人工智能驱动的三维摄影代表着数字成像的范式转变,传统的平面照片通过智能算法处理获得空间深度。传统照片只能捕捉亮度和色彩信息,缺乏在人类视觉中产生视觉深度感知的维度数据。
这项变革性技术通过几种创新方法实现:
- 深度预测:神经网络通过分析视觉模式来估计物体距离,从而创建像素级深度图。
- 视觉重构:情境感知算法在图像元素之间建立隐藏的空间关系。
- 动态渲染:系统生成多个视角,模拟三维透视变化。
核心技术:情境感知分层深度绘制
现代 3D 照片转换的革命性在于其集成处理管道:
- 通过卷积神经网络进行场景分析
- 通过训练有素的预测模型进行深度估计
- 多平面图像分割
- 通过几何变换进行视点模拟
- 通过生成式内绘完成视觉缝隙
这种复杂的工作流程可实现各种输出格式,包括深度可视化、动画透视转换和交互式三维视图,使静态图像栩栩如生。
了解深度贴图及其重要性
深度贴图通过建立图像元素之间的空间关系,为可信的三维转换奠定基础。高级技术包括
- 单眼深度估算:使用训练有素的神经网络进行单图像分析
- 几何重建:透视线和消失点的解释
- 纹理梯度分析:评估整个图像的细节分辨率变化
实用实施指南
设置开发环境
Google Colab 为 3D 照片转换实验提供了一个便捷的平台。基本配置步骤包括
- 在运行时设置中激活 GPU 加速
- 安装核心可视化库
- 配置 Python 依赖项
下载脚本和预训练模型
实施过程需要在大量图像数据集上预先训练好的特定人工智能模型。主要组件包括
- 3D 重建神经网络
- 深度预测算法
- 图像着色架构
上传和执行三维转换
转换过程包括
- 选择最佳源图像(建议使用 JPEG 格式)
- 上传至处理环境
- 执行转换流水线
- 审查和完善输出结果
创建 AI 3D 照片
逐步转换过程
- 图片选择--选择主题清晰、光线充足的照片
- 环境设置--在 Colab 笔记本中配置必要的依赖项
- 模型部署--加载并初始化人工智能处理管道
- 执行转换--运行转换算法
- 输出生成 - 查看并导出 3D 照片
技术考虑因素
性能因素
- GPU 加速可大大缩短处理时间
- 图像分辨率会影响质量和计算时间
- 复杂场景可能需要额外的处理迭代
输出质量优化
- 使用具有良好对比度的高质量源图像
- 确保原始照片有适当的照明
- 选择前景元素清晰的图像
- 避免过多噪音或压缩伪影
AI 3D 照片转换的优势
- 使历史照片或档案照片焕发生机
- 为数字平台创建引人入胜的内容
- 增强视觉叙事能力
- 提供具有成本效益的立体摄影替代方案
目前的局限性
- 反光/镜面表面的深度估计难题
- 在复杂遮挡情况下可能出现伪影
- 计算密集型处理要求
- 视点调整范围有限
常见问题
哪些图像特征能产生最佳效果?
主体分离度高、照明良好且边缘清晰的图像通常能产生最佳的 3D 转换效果。
如何提高处理速度?
利用 GPU 加速和优化源图像分辨率可加快转换速度。
支持哪些文件格式?
系统目前最可靠的处理格式是 JPEG 图像。
如何解决边缘伪影问题?
使用不同的源图像进行试验,必要时考虑预处理步骤。
新兴功能
神经渲染和生成式人工智能的不断进步将带来更复杂的 3D 转换功能,包括实时处理和增强的视角灵活性。










 腾讯旗下“小龙虾”表现远超预期,团队将运力扩大10倍,并致歉及提供补偿
腾讯正式推出全场景AI智能助手“WorkBuddy”,凭借高度集成和低部署门槛,标志着大型模型应用层竞争进入新阶段。该产品在发布当天便引发了业界广泛关注。 用户流量远超预期,导致相关产品腾讯云代码助手(CodeBuddy)出现登录故障及服务不稳定。腾讯云团队随后发布致歉声明,表示技术团队已紧急将容量扩容十倍,目前服务已全面恢复。受影响用户获得了5,000腾讯云代金券作为补偿。业界观察人士将Work
腾讯旗下“小龙虾”表现远超预期,团队将运力扩大10倍,并致歉及提供补偿
腾讯正式推出全场景AI智能助手“WorkBuddy”,凭借高度集成和低部署门槛,标志着大型模型应用层竞争进入新阶段。该产品在发布当天便引发了业界广泛关注。 用户流量远超预期,导致相关产品腾讯云代码助手(CodeBuddy)出现登录故障及服务不稳定。腾讯云团队随后发布致歉声明,表示技术团队已紧急将容量扩容十倍,目前服务已全面恢复。受影响用户获得了5,000腾讯云代金券作为补偿。业界观察人士将Work
 Suno领投方:删除帖子无法填补版权诉讼的漏洞
备受瞩目的AI音乐生成平台Suno正面临一场艰难的版权诉讼,而其领投投资人的坦率言论,可能恰恰为对方提供了他们梦寐以求的证据。 Menlo Ventures(Suno的核心投资者)合伙人C.C. Gong近日删除了一个推文,该推文与公司当前的法律辩护策略直接相悖。在之前的版权诉讼中,Suno的辩护主要依赖“合理使用”的论点,声称AI生成的音乐仅仅是一种“工具”,既不会直接与受版权保护的原创作品竞争
Suno领投方:删除帖子无法填补版权诉讼的漏洞
备受瞩目的AI音乐生成平台Suno正面临一场艰难的版权诉讼,而其领投投资人的坦率言论,可能恰恰为对方提供了他们梦寐以求的证据。 Menlo Ventures(Suno的核心投资者)合伙人C.C. Gong近日删除了一个推文,该推文与公司当前的法律辩护策略直接相悖。在之前的版权诉讼中,Suno的辩护主要依赖“合理使用”的论点,声称AI生成的音乐仅仅是一种“工具”,既不会直接与受版权保护的原创作品竞争
 Claude Opus 4.7 正式发布,将可靠性置于智能之上
Anthropic 今年保持着激进的开发节奏,几乎每隔一天就会推出新功能。备受期待的 Claude Opus 4.7 刚刚正式发布,有趣的是,Anthropic 在公告中直言不讳地表示:“这并非我们最强大的模型。” 传闻中更强大的 Claude Mythos Preview 仍处于待命状态。尽管如此,Opus 4.7 依然引发了广泛关注,因为它致力于解决“更可靠”而非“更智能”的问题。基准测试结果
Claude Opus 4.7 正式发布,将可靠性置于智能之上
Anthropic 今年保持着激进的开发节奏,几乎每隔一天就会推出新功能。备受期待的 Claude Opus 4.7 刚刚正式发布,有趣的是,Anthropic 在公告中直言不讳地表示:“这并非我们最强大的模型。” 传闻中更强大的 Claude Mythos Preview 仍处于待命状态。尽管如此,Opus 4.7 依然引发了广泛关注,因为它致力于解决“更可靠”而非“更智能”的问题。基准测试结果

在 XIX.AI 探索 2026 年最优秀的少年漫画 AI 生成工具。我们精心筛选的这份高评分清单汇集了强大的工具,助您创作充满张力的动作场面和动态能量特效。通过实际测试对比免费与付费选项。释放您的创作潜能,立即开始创作史诗级漫画吧!
15 个工具
xix.ai

2026年最新最佳AI报销管理工具:广受好评的解决方案,可自动扫描收据并分类企业支出。探索这些功能强大、颠覆传统的解决方案,助您轻松管理报销、精准追踪财务并简化合规流程。我们精心整理并每周更新的免费与付费选项对比指南,助您找到最适合的工具。通过XIX.AI的专家精选,释放您的AI优势。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
10 个工具
xix.ai

立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai

探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai

探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai

Cette technique de conversion 2D vers 3D est fascinante ! Je me demande si elle peut s'appliquer aux vieilles photos de famille... Ce serait génial de voir les portraits de mes grands-parents prendre vie de cette manière. Par contre, je me pose des questions sur les coûts et la facilité d'accès pour le grand public — est-ce que cette technologie va rester cantonnée aux professionnels ? 😌
Das ist ja mal krass! Die Idee, alte Fotos plötzlich räumlich zu erleben, finde ich total faszinierend. Aber ich frage mich auch, was das für die Privatsphäre bedeutet. Wenn jeder einfach irgendein 2D-Bild in 3D verwandeln kann... irgendwie unheimlich, oder? 😅 Trotzdem, die Technik ist beeindruckend!
这简直是魔法啊!我用旧照片试了一下效果,从2D变3D的过程让家里老人惊呼连连。不过生成的3D照片在移动时会有些小瑕疵,不知道是不是我操作的问题?期待技术再进步些 🚀













