
















 Hogar
Hogar
OpenAI y NVIDIA crean el protocolo MRC para transformar las redes de entrenamiento de IA
OpenAI ha anunciado oficialmente una colaboración con cinco líderes del sector —AMD, Broadcom, Intel, Microsoft y NVIDIA— para lanzar el protocolo Multipath Reliable Connection (MRC). Este protocolo de código abierto, publicado a través del Open Compute Project (OCP), está diseñado para hacer frente a la latencia de red y a los fallos que suelen producirse en el entrenamiento de IA a gran escala.
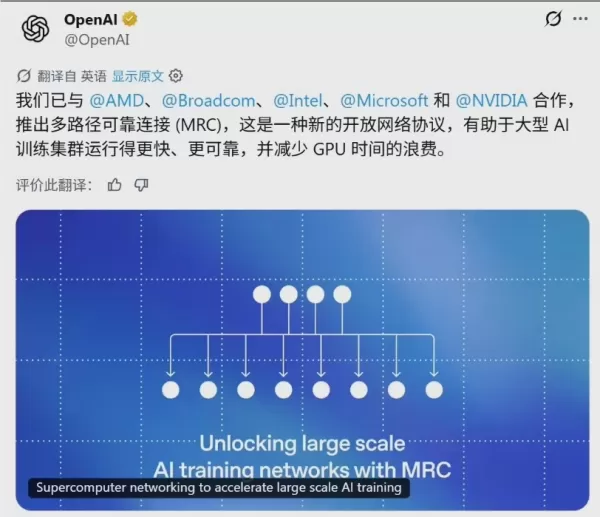
Eliminación del «punto único de fallo»: de la arquitectura de tres niveles a la de dos niveles
En el entrenamiento tradicional de modelos de IA, la congestión de la red o un fallo menor en un único enlace pueden provocar un efecto dominó, lo que obliga a decenas de miles de GPU a permanecer inactivas y da lugar a un importante desperdicio computacional.
Para mejorar de forma fundamental la resiliencia del sistema, el protocolo MRC introduce un diseño de red multiplano. Divide de forma inteligente una única interfaz de 800 Gb/s en múltiples enlaces más pequeños. Esta optimización estructural permite al sistema admitir clústeres masivos de hasta aproximadamente 131 000 GPU utilizando solo dos capas de conmutadores. En comparación con las arquitecturas tradicionales de dos o cuatro niveles, este cambio no solo reduce drásticamente el número de componentes físicos y el consumo de energía, sino que también recorta significativamente los costes de construcción.
Gestión avanzada del tráfico: «dispersión» de paquetes y recuperación a nivel de microsegundos
Más allá de la simplificación arquitectónica, MRC introduce un enfoque novedoso para la distribución del tráfico. Emplea tecnología adaptativa de «spraying» de paquetes, alejándose de la transmisión tradicional de ruta única. Este método descompone los paquetes de tareas y los distribuye a través de cientos de rutas paralelas. Incluso si los paquetes llegan desordenados, el receptor puede reensamblarlos con precisión, previniendo de manera efectiva la congestión localizada en la red central.
Para el control de la red, MRC sustituye los complejos protocolos de enrutamiento dinámico (como BGP) por la tecnología de enrutamiento de origen SRv6. Esto permite al remitente especificar directamente la ruta, mientras que los conmutadores solo realizan un reenvío estático simple. Este diseño reduce drásticamente el tiempo de recuperación de fallos de red de segundos a microsegundos, lo que permite al sistema lograr una «autocuración casi perfecta» ante la inestabilidad de los enlaces.
Validación en el mundo real: el «estabilizador» de la supercomputadora
El protocolo MRC ya se ha implementado en la supercomputadora GB200 de NVIDIA y en la infraestructura en la nube de Oracle. Los datos de las pruebas confirman que, incluso durante escenarios de entrenamiento activos, MRC puede redirigir automáticamente el tráfico para sortear interrupciones —como fluctuaciones repentinas en el enlace o reinicios de conmutadores— garantizando que las tareas de entrenamiento complejas continúen sin interrupciones.
Artículo relacionado
 Claude, la IA experimental de Anthropic, lleva a cabo negociaciones y transacciones en una prueba de comercio electrónico
A medida que la inteligencia artificial avanza rápidamente, Anthropic puso en marcha discretamente el pasado viernes un experimento interno denominado «Project Deal», en el que se ponía de manifiesto
DeepSeek Code, listo para su lanzamiento
A medida que la tecnología de IA avanza a pasos agigantados, DeepSeek se encuentra en un momento decisivo. La empresa de IA ha revelado recientemente que ha conseguido más de 70 000 millones de yuanes
Grok, de Musk: 1,5 billones de parámetros y absorción de código de cursor: ¿un punto de inflexión o un farol?
Elon Musk por fin está dando un paso adelante.En la carrera por la programación de IA, OpenAI y Anthropic están acelerando, mientras que xAI parece quedarse atrás. Musk ha manifestado en numerosas oca
Recomendaciones de temas especiales relacionados
Negocio
Claude, la IA experimental de Anthropic, lleva a cabo negociaciones y transacciones en una prueba de comercio electrónico
A medida que la inteligencia artificial avanza rápidamente, Anthropic puso en marcha discretamente el pasado viernes un experimento interno denominado «Project Deal», en el que se ponía de manifiesto
DeepSeek Code, listo para su lanzamiento
A medida que la tecnología de IA avanza a pasos agigantados, DeepSeek se encuentra en un momento decisivo. La empresa de IA ha revelado recientemente que ha conseguido más de 70 000 millones de yuanes
Grok, de Musk: 1,5 billones de parámetros y absorción de código de cursor: ¿un punto de inflexión o un farol?
Elon Musk por fin está dando un paso adelante.En la carrera por la programación de IA, OpenAI y Anthropic están acelerando, mientras que xAI parece quedarse atrás. Musk ha manifestado en numerosas oca
Recomendaciones de temas especiales relacionados
Negocio
 Las mejores herramientas de selección de personal basadas en IA: filtrar currículos y automatizar la programación de entrevistas con los candidatos
Las mejores herramientas de selección de personal basadas en IA: filtrar currículos y automatizar la programación de entrevistas con los candidatos
Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
 10 herramientas
10 herramientas
 xix.ai
Productividad
Entrenadores personales de bienestar y concentración basados en IA: controla el agotamiento y aumenta tus niveles de energía mental
xix.ai
Productividad
Entrenadores personales de bienestar y concentración basados en IA: controla el agotamiento y aumenta tus niveles de energía mental
Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai
chatbot
Los mejores chatbots románticos con IA: crea relaciones duraderas con personalidades coherentes
Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai
Educación y aprendizaje
Los mejores mentores en ciencia de datos y IA: dominan SQL, Pandas y flujos de trabajo de aprendizaje automático.
Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
10 herramientas
xix.ai
chatbot
Los mejores entrenadores de IA para ligar y conversar: mejora tu carisma social y tu confianza en tiempo real
Descubre los mejores cursos de 2026 sobre coqueteo y conversación con IA en XIX.AI. Nuestra selección, cuidadosamente seleccionada y con las mejores valoraciones, te ayuda a desarrollar tu carisma social y tu confianza en tiempo real. Explora herramientas imprescindibles y revolucionarias con comparativas entre versiones gratuitas y de pago, y clasificaciones que se actualizan semanalmente. Potencia hoy mismo tus habilidades sociales.
10 herramientas
xix.ai
código
Las mejores herramientas de IA para pruebas unitarias automatizadas: genera casos de prueba con Jest, PyTest y JUnit con un solo clic
Descubre las mejores herramientas de IA de 2026 para la automatización de pruebas unitarias. Nuestra selección incluye potentes soluciones revolucionarias que permiten generar casos de prueba para Jest, PyTest y JUnit al instante. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones actualizadas semanalmente en XIX.AI. Aprovecha las ventajas de la IA y aumenta la productividad de tu desarrollo hoy mismo.
10 herramientas
xix.ai

 comentario (0)
0/500
comentario (0)
0/500
OpenAI ha anunciado oficialmente una colaboración con cinco líderes del sector —AMD, Broadcom, Intel, Microsoft y NVIDIA— para lanzar el protocolo Multipath Reliable Connection (MRC). Este protocolo de código abierto, publicado a través del Open Compute Project (OCP), está diseñado para hacer frente a la latencia de red y a los fallos que suelen producirse en el entrenamiento de IA a gran escala.
Eliminación del «punto único de fallo»: de la arquitectura de tres niveles a la de dos niveles
En el entrenamiento tradicional de modelos de IA, la congestión de la red o un fallo menor en un único enlace pueden provocar un efecto dominó, lo que obliga a decenas de miles de GPU a permanecer inactivas y da lugar a un importante desperdicio computacional.
Para mejorar de forma fundamental la resiliencia del sistema, el protocolo MRC introduce un diseño de red multiplano. Divide de forma inteligente una única interfaz de 800 Gb/s en múltiples enlaces más pequeños. Esta optimización estructural permite al sistema admitir clústeres masivos de hasta aproximadamente 131 000 GPU utilizando solo dos capas de conmutadores. En comparación con las arquitecturas tradicionales de dos o cuatro niveles, este cambio no solo reduce drásticamente el número de componentes físicos y el consumo de energía, sino que también recorta significativamente los costes de construcción.
Gestión avanzada del tráfico: «dispersión» de paquetes y recuperación a nivel de microsegundos
Más allá de la simplificación arquitectónica, MRC introduce un enfoque novedoso para la distribución del tráfico. Emplea tecnología adaptativa de «spraying» de paquetes, alejándose de la transmisión tradicional de ruta única. Este método descompone los paquetes de tareas y los distribuye a través de cientos de rutas paralelas. Incluso si los paquetes llegan desordenados, el receptor puede reensamblarlos con precisión, previniendo de manera efectiva la congestión localizada en la red central.
Para el control de la red, MRC sustituye los complejos protocolos de enrutamiento dinámico (como BGP) por la tecnología de enrutamiento de origen SRv6. Esto permite al remitente especificar directamente la ruta, mientras que los conmutadores solo realizan un reenvío estático simple. Este diseño reduce drásticamente el tiempo de recuperación de fallos de red de segundos a microsegundos, lo que permite al sistema lograr una «autocuración casi perfecta» ante la inestabilidad de los enlaces.
Validación en el mundo real: el «estabilizador» de la supercomputadora
El protocolo MRC ya se ha implementado en la supercomputadora GB200 de NVIDIA y en la infraestructura en la nube de Oracle. Los datos de las pruebas confirman que, incluso durante escenarios de entrenamiento activos, MRC puede redirigir automáticamente el tráfico para sortear interrupciones —como fluctuaciones repentinas en el enlace o reinicios de conmutadores— garantizando que las tareas de entrenamiento complejas continúen sin interrupciones.










 Claude, la IA experimental de Anthropic, lleva a cabo negociaciones y transacciones en una prueba de comercio electrónico
A medida que la inteligencia artificial avanza rápidamente, Anthropic puso en marcha discretamente el pasado viernes un experimento interno denominado «Project Deal», en el que se ponía de manifiesto
Claude, la IA experimental de Anthropic, lleva a cabo negociaciones y transacciones en una prueba de comercio electrónico
A medida que la inteligencia artificial avanza rápidamente, Anthropic puso en marcha discretamente el pasado viernes un experimento interno denominado «Project Deal», en el que se ponía de manifiesto
 DeepSeek Code, listo para su lanzamiento
A medida que la tecnología de IA avanza a pasos agigantados, DeepSeek se encuentra en un momento decisivo. La empresa de IA ha revelado recientemente que ha conseguido más de 70 000 millones de yuanes
DeepSeek Code, listo para su lanzamiento
A medida que la tecnología de IA avanza a pasos agigantados, DeepSeek se encuentra en un momento decisivo. La empresa de IA ha revelado recientemente que ha conseguido más de 70 000 millones de yuanes
 Grok, de Musk: 1,5 billones de parámetros y absorción de código de cursor: ¿un punto de inflexión o un farol?
Elon Musk por fin está dando un paso adelante.En la carrera por la programación de IA, OpenAI y Anthropic están acelerando, mientras que xAI parece quedarse atrás. Musk ha manifestado en numerosas oca
Grok, de Musk: 1,5 billones de parámetros y absorción de código de cursor: ¿un punto de inflexión o un farol?
Elon Musk por fin está dando un paso adelante.En la carrera por la programación de IA, OpenAI y Anthropic están acelerando, mientras que xAI parece quedarse atrás. Musk ha manifestado en numerosas oca

Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai

Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai

Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai

Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
10 herramientas
xix.ai

Descubre los mejores cursos de 2026 sobre coqueteo y conversación con IA en XIX.AI. Nuestra selección, cuidadosamente seleccionada y con las mejores valoraciones, te ayuda a desarrollar tu carisma social y tu confianza en tiempo real. Explora herramientas imprescindibles y revolucionarias con comparativas entre versiones gratuitas y de pago, y clasificaciones que se actualizan semanalmente. Potencia hoy mismo tus habilidades sociales.
10 herramientas
xix.ai

Descubre las mejores herramientas de IA de 2026 para la automatización de pruebas unitarias. Nuestra selección incluye potentes soluciones revolucionarias que permiten generar casos de prueba para Jest, PyTest y JUnit al instante. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones actualizadas semanalmente en XIX.AI. Aprovecha las ventajas de la IA y aumenta la productividad de tu desarrollo hoy mismo.
10 herramientas
xix.ai













