
















 Lar
LarPDFMerse
Extração de Dados de PDF para Formatos Estruturados


O que é o Ryter Pro? Ryter Pro É uma ferramenta de humanização de IA que transforma textos gerados por IA a partir de plataformas como ChatGPT e GPT-4 em conteúdo natural, semelhante ao humano. Isso t
Já se perguntou o que é o LimeBlock? Bem, deixe -me dividir para você. LimeBlock é esse widget bacana de chatbot ai projetado para facilitar sua vida. Com apenas 3 linhas de código, você pode permitir que seus usuários façam páginas, fazer solicitações de API e
Já se perguntou como você poderia explorar os vastos recursos da Internet com apenas alguns cliques? É aí que Singleapi entra em jogo. Essa ferramenta bacana, alimentada pelos recursos robustos do GPT-4, transforma qualquer site em um tesouro de dados, del
Já se perguntou como otimizar seu trabalho como engenheiro rápido ou trabalhador digital? Entre GeneratedBy, uma plataforma que muda o jogo projetada para revolucionar como você cria, testam e compartilham prompts gerados pela IA. É como ter um assistente pessoal para sua IA precisa, tornando todo o processo não apenas EAS

Enix não é apenas mais um assistente de IA; É um divisor de águas para as empresas que desejam aumentar seu marketing, análise e produção criativa. Pense nisso como seu kit de ferramentas pessoal, onde você pode criar e adaptar os agentes da IA para atender às suas necessidades específicas. É tudo
Informações sobre o produto
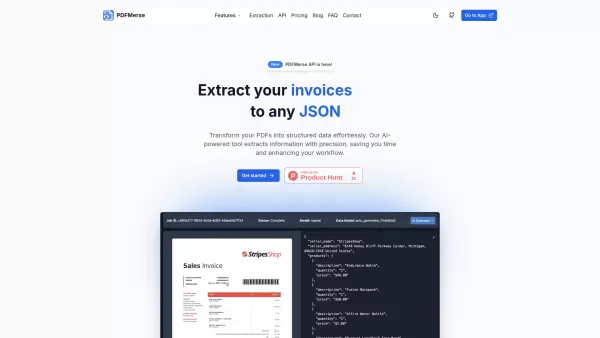
Já se viu olhando para uma pilha de PDFs, desejando que houvesse uma varinha mágica para retirar todos esses dados para algo que você realmente pode usar? Entre no PDFMERSE, seu novo melhor amigo no mundo do processamento de documentos. Essa ferramenta movida a IA é como um assistente que pode peneirar os PDFs de todos os tipos-se são digitados, manuscritos ou em vários idiomas-e transformá-los em dados bem estruturados. E a melhor parte? Ele vem com uma API, para que você possa tecem -a perfeitamente em seus sistemas existentes.
Como aproveitar o poder do PDFMERSE?
Usar PDFMerse é uma brisa. Basta enviar seus PDFs e informar a ferramenta exatamente quais dados você está buscando. A IA faz o que faz, criando automaticamente um modelo de dados que atenda às suas necessidades como uma luva. É como ter um assistente pessoal que é realmente bom em ler e organizar.
O que faz o PDFMerse se destacar?
Extração de dados automatizada
Diga adeus à entrada manual de dados. O PDFMERSE automatiza o processo de extração, economizando tempo e reduzindo erros.
Suporte multilanguage
Independentemente do idioma do seu documento, o PDFMERSE pode lidar com isso, tornando -o uma solução global para suas necessidades de dados.
Reconhecimento de texto manuscrito
Tem uma pilha de notas ou formulários manuscritos? Sem problemas. O PDFMERSE pode decifrar esses rabiscos e transformá -los em dados utilizáveis.
Saída estruturada em que você pode confiar
A ferramenta garante a saída estruturada, garantindo que os dados que você obtém não sejam apenas extraídos, mas organizados de uma maneira que esteja pronta para uso.
Onde o PDFMerse pode fazer a diferença?
Análise financeira
Extraia os dados da fatura com rapidez e precisão para otimizar seus processos de análise financeira.
Processamento de documentos legais
Automatize a entrada de dados de documentos legais, facilitando muito a conformidade e o gerenciamento de casos.
Conformidade com a saúde
Processar registros médicos com eficiência para atender aos requisitos de conformidade sem suar.
Perguntas freqüentes sobre PDFMerse
- Que tipos de PDFs podem processar PDFMERSE?
- O PDFMERSE pode lidar com uma ampla gama de PDFs, incluindo documentos digitados, manuscritos e multilíngues.
- Quão precisa é a extração de dados?
- A precisão da extração de dados do PDFMERSE é alta, graças aos seus algoritmos AI avançados.
- Meus dados são seguros com o PDFMERSE?
- Sim, o PDFMERSE leva a segurança de dados a sério, garantindo que seus documentos e dados extraídos sejam protegidos.
Precisa de ajuda ou tem perguntas? Largue uma linha para a equipe de suporte do PDFMERSE em [email protegido] . Para mais maneiras de entrar em contato, consulte a página de contato .
Curioso sobre a empresa por trás do PDFMERSE? É simplesmente PDFMERSE, dedicado a facilitar a vida de processamento de documentos.
Quer saber mais sobre preços? Vá para a página de preços deles para encontrar o plano que atenda às suas necessidades.
Mantenha -se atualizado com o PDFMERSE no Twitter ou mergulhe no lado técnico das coisas em sua página do Github .
Screenshot PDFMerse

Descubra os melhores construtores de consultas AI NoSQL de 2026 em XIX.AI. Nossa seleção cuidadosamente elaborada e altamente avaliada ajuda você a extrair dados em formato JSON e MongoDB sem necessidade de programação. Compare ferramentas gratuitas com pagas, veja resultados de testes reais e aumente sua produtividade imediatamente. Explore as classificações e aproveite todas as vantagens que isso pode lhe oferecer.
 10 ferramentas
10 ferramentas
 xix.ai
xix.ai

2026 Mais recente: Descubra os melhores ferramentas de IA para scraping da web, crawling e extração de dados API. Nossa lista selecionada contém soluções poderosas e altamente avaliadas para a coleta automática de dados, testadas no mundo real e atualizadas semanalmente. Compare as opções gratuitas com as pagas para encontrar a que melhor se adapta às suas necessidades. Desfrute de fluxos de trabalho eficientes com as classificações especializadas da XIX.AI. Explore agora e extraia dados de forma mais inteligente.
10 ferramentas
xix.ai

Descubra as plataformas de extração de dados com IA mais bem avaliadas de 2026 para um fluxo de trabalho completo e sem interrupções. Compare opções gratuitas e pagas, bem como o desempenho na prática, com os rankings selecionados e atualizados semanalmente pela XIX.AI. Encontre a sua solução definitiva para coleta de dados!
10 ferramentas
xix.ai

Explore as soluções de rastreamento da web com IA mais bem avaliadas para 2026. Esta lista selecionada pela XIX.AI apresenta ferramentas poderosas e revolucionárias para a coleta de dados em grande escala. Compare opções gratuitas e pagas com nossos rankings atualizados semanalmente e testes práticos para encontrar a opção ideal para você e automatizar seu fluxo de trabalho de dados. Descubra hoje mesmo sua vantagem com IA.
10 ferramentas
xix.ai

Descubra as melhores ferramentas de IA para extração de dados estruturados e análise da web em nosso ranking selecionado de 2026. Na XIX.AI, oferecemos comparações detalhadas, testes de desempenho em condições reais e seleções das melhores ferramentas, atualizadas semanalmente. Explore agora para encontrar a ferramenta perfeita e aproveitar ao máximo sua vantagem em IA para fluxos de trabalho automatizados de dados.
10 ferramentas
xix.ai



Just tried PDFMerse and wow, it's a game-changer! ✨ Finally a tool that actually understands messy PDFs without needing a PhD in formatting. The AI extraction feels eerily accurate – almost too good? Hope they don't start charging wizard-level prices though 🧙♂️
PDFMerse é um salva-vidas! É mágico como ele extrai dados dos PDFs para formatos utilizáveis. Só queria que fosse um pouco mais rápido, mas ainda assim, é um mago no meu livro! 🪄📚
PDFMerseは本当に便利です!PDFからデータを抽出するのが魔法のようです。もう少し速ければ完璧なんですけどね。それでも、私の本には魔法使いとして載っていますよ!🪄📚
PDFMerse es un salvavidas! Es mágico cómo saca datos de los PDFs a formatos utilizables. Ojalá fuera un poco más rápido, pero aún así, es un mago en mi libro! 🪄📚
PDFMerse is a lifesaver! It's like magic how it pulls data from PDFs into usable formats. Only wish it was a bit faster, but hey, it's still a wizard in my book! 🪄📚



