
















 Heim
HeimPoplarML - Deploy Models to Production
PoplarML: Einfache Bereitstellung von ML-Modellen


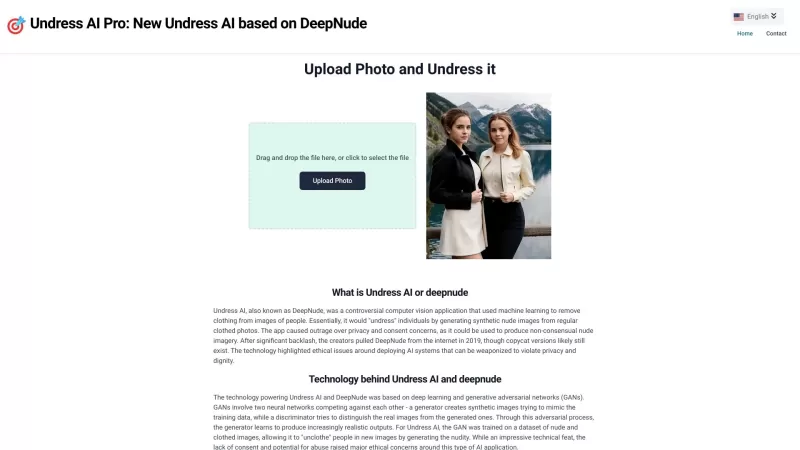
Das Ausziehen von AI Pro, das oft als DeepNude bezeichnet wird, ist ein sehr umstrittenes Werkzeug, das die Debatte aufgeregt hat. Es verwendet hoch entwickelte Algorithmen für maschinelles Lernen, um Kleidung digital aus Bildern von Menschen zu entfernen. Es ist ein wildes Konzept, nicht wahr? Aber le
Haben Sie sich jemals gefragt, was Deepseek AI in der überfüllten Welt der KI -Technologie hervorhebt? Lassen Sie mich Ihnen sagen, Deepseek Ai ist nicht nur ein anderer Spieler im Spiel. Es ist der führende Anbieter fortgeschrittener KI -Sprachmodelle und Enterprise -Lösungen. Was setzt sie APA

Haben Sie sich jemals gefragt, wie es wäre, eine digitale Version von sich selbst oder jemand anderem zu erstellen? Dort kommt Meshcapade mich ins Spiel-eine modernste Plattform, auf der Sie unglaublich lebensechte 3D-digitale Menschen herstellen können. Ob Sie ein paar Fotos haben, Som
Was ist „GPT OSS“? GPT OSS markiert einen transformativen Schritt zur breiten Verfügbarkeit fortschrittlicher KI und wurde am 5. August 2025 von OpenAI eingeführt. Diese Open-Source-Familie umfasst zw
Haben Sie sich jemals gefragt, wie unterschiedliche KI -Modelle gegeneinander stapeln? Geben Sie Rivalen, eine schlanke Webanwendung, ein, damit Sie tief in die Welt der KI -Vergleiche eintauchen können. Es ist, als hätten Sie einen Sitz in der ersten Reihe zu einem Showdown zwischen GPT-4O, Claude 3.7 und GROK-3, wo Sie sehen können
PoplarML - Deploy Models to Production Produktinformationen
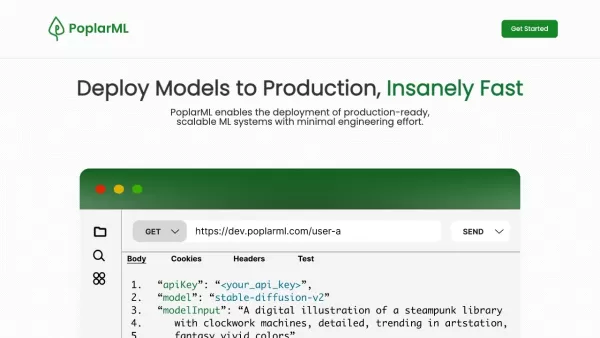
PoplarML ist eine bahnbrechende Neuerung für alle, die jemals mit der Bereitstellung von Machine-Learning-Modellen in der Produktion zu kämpfen hatten. Diese Plattform beseitigt die Komplexität und macht es zum Kinderspiel, Ihre Modelle mit nur wenigen Klicks auf einer Flotte von GPUs zum Laufen zu bringen. Egal, ob Sie mit Tensorflow, Pytorch oder JAX arbeiten, PoplarML hat die passende Lösung für Sie. Und das Beste daran? Sie können Ihre Modelle in Echtzeit über einen einfachen REST-API-Endpunkt nutzen. Das ist wie eine Superkraft für Ihre ML-Projekte!
So starten Sie mit PoplarML
Sind Sie bereit, loszulegen? So können Sie PoplarML nutzen:
- Anmelden: Besuchen Sie die Website und erstellen Sie ein Konto. Das geht schnell und einfach, und schon können Sie loslegen.
- Stellen Sie Ihre Modelle bereit: Verwenden Sie das von PoplarML bereitgestellte CLI-Tool, um Ihre ML-Modelle auf deren GPU-Flotte bereitzustellen. Sie kümmern sich um die Skalierung, sodass Sie sich um nichts kümmern müssen.
- Echtzeit-Vorhersagen: Sobald Ihr Modell bereitgestellt ist, können Sie es über eine REST-API für sofortige Vorhersagen aufrufen. Kein Warten mehr!
- Verwenden Sie jedes beliebige Framework: Egal, ob Sie Tensorflow, Pytorch oder JAX verwenden, PoplarML unterstützt alles. Bringen Sie einfach Ihr Modell mit, den Rest erledigt PoplarML.
Kernfunktionen von PoplarML
- Nahtlose Bereitstellung: Stellen Sie Ihre ML-Modelle mühelos mit dem CLI-Tool auf einer Flotte von GPUs bereit.
- Echtzeit-Inferenz: Erhalten Sie sofortige Vorhersagen, indem Sie Ihr Modell über einen REST-API-Endpunkt aufrufen.
- Framework-unabhängig: Unterstützt Tensorflow, Pytorch und JAX, sodass Sie nicht an ein Framework gebunden sind.
Anwendungsfälle für PoplarML
- Produktionsbereitstellung: Perfekt, um Ihre ML-Modelle schnell in Produktionsumgebungen zu integrieren.
- Einfache Skalierung: Skalieren Sie Ihre ML-Systeme ohne großen Aufwand dank minimalem Engineering-Aufwand.
- Echtzeit-Einblicke: Ermöglichen Sie Echtzeit-Inferenz für Ihre bereitgestellten Modelle und machen Sie Ihre Anwendungen reaktionsschneller.
- Framework-Flexibilität: Unterstützt eine Vielzahl von ML-Frameworks, sodass Sie das verwenden können, womit Sie sich am wohlsten fühlen.
FAQ
- Was ist PoplarML?
- PoplarML ist eine Plattform, die die Bereitstellung von Machine-Learning-Modellen in der Produktion vereinfacht, mehrere Frameworks unterstützt und Echtzeit-Inferenzen ermöglicht.
- Wie verwende ich PoplarML?
- Registrieren Sie sich auf der Website, verwenden Sie das CLI-Tool, um Ihre Modelle bereitzustellen, und nutzen Sie dann die REST-API für Echtzeitvorhersagen.
- Was sind die Kernfunktionen von PoplarML?
- Nahtlose Bereitstellung auf GPUs, Echtzeit-Inferenz über die REST-API und Unterstützung für Tensorflow, Pytorch und JAX.
- Was sind die Anwendungsfälle für PoplarML?
- Ideal für die Bereitstellung von Modellen in der Produktion, die Skalierung von ML-Systemen, die Ermöglichung von Echtzeit-Inferenzen und die Unterstützung verschiedener ML-Frameworks.
Benötigen Sie Hilfe? Sie erreichen den Kundensupport von PoplarML unter [email protected]. Weitere Kontaktmöglichkeiten finden Sie auf der Kontaktseite.
Bleiben Sie über die neuesten Entwicklungen bei PoplarML auf dem Laufenden, indem Sie ihnen auf Twitter folgen.
PoplarML - Deploy Models to Production Screenshot



Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
 10 Tools
10 Tools
 xix.ai
xix.ai

Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai

Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai

Entdecken Sie die neuesten, hochbewerteten KI-Tools von 2026 für den automatisierten Unit-Testing-Prozess. Unsere sorgfältig ausgewählten Lösungen bieten leistungsstarke und bahnbrechende Funktionen, um sofort Jest-, PyTest- und JUnit-Testfälle zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings auf XIX.AI. Entfalten Sie Ihr KI-Potenzial und steigern Sie noch heute die Produktivität Ihrer Entwicklungstätigkeit.
10 Tools
xix.ai

Entdecken Sie bei XIX.AI die besten KI-Tools zur Datenvisualisierung für 2026. Unsere sorgfältig zusammengestellte Auswahl der besten Tools hilft Ihnen dabei, leistungsstarke, interaktive BI-Dashboards sofort aus Rohdaten automatisch zu erstellen. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Schöpfen Sie noch heute das Potenzial Ihrer Daten aus.
10 Tools
xix.ai





